
一,数据模型与ORM
1,数据模型
数据模型,即Model,也就是MVT中的M,用于定义项目中的实体及其关系,
- 每个模型都是一个 Python 的类,这些类继承
django.db.models.Model - 一个模型类对应一张数据表
- 模型类的每个属性都相当于一个数据库的字段
- Django 提供了一系列
API来操作数据表
一个例子:
class Image(models.Model):
user = models.ForeignKey(User,
related_name='images_created',
on_delete=models.CASCADE)
title = models.CharField(max_length=200)
slug = models.SlugField(max_length=200)
url = models.URLField()
image = models.ImageField(upload_to='images/%Y/%m/%d/')
description = models.TextField(blank=True)
created = models.DateField(auto_now_add=True,
db_index=True)
users_like = models.ManyToManyField(settings.AUTH_USER_MODEL,
related_name='images_liked',
blank=True)
total_likes = models.PositiveIntegerField(db_index=True,
default=0)
2,ORM
仅仅有数据模型是操作不了数据库的,这就需要用到ORM(对象关系映射)框架。ORM框架是面向对象语言中用于不同系统间的数据转换的技术,它通过操作与实际目标数据库相对应的虚拟对象数据库实现数据操作,而这个虚拟对象数据库就是模型,也就是说模型本身就是ORM的一个具体实现。
ORM功能的实现需要四个步骤:
- 配置数据库
- 创建数据模型
- 通过模型创建实际目标数据表
- 使用模型API
3,数据迁移
其中的第三步”通过模型创建实际目标数据表“的过程称为数据迁移。
数据迁移分为两个步骤:
- 使用
makemigrations命令产生用于创建数据表的脚本文件 - 使用
migrate命令据脚本文件创建实际数据表
这样一来,就通过模型产生了实际的数据表了。
如果模型有更新,就再依次执行上面两条命令就行。
4,QuerySet
第四步”使用模型API“才是在代码中实现数据操作的直接步骤。
这是一个例子:
images = Image.objects.all()
django 通过给 Model 增加一个 objects 属性来提供数据操作的API,这里调用了all()方法获取所有数据,它返回了一个QuerySet对象,当我们在程序的某处用到image即这个QuerySet对象时,它才会去DB中获取数据,比如:
return render(request, 'images_list.html', {'images': images})
也就是说,执行上面那条查询语句是不会立即获得数据库数据。这种需要时才间接获取数据的设计是为了避免不必要的数据库操作请求。这种特性使得QuerySet对象是一个懒加载的对象。
一般情况下,一旦当通过QuerySet对象获取到数据,这个数据会被缓存下来,就能在多处获取这些数据的不同部分,这对减少数据库操作请求非常有用。
二,数据表关系
这里主要是针对传统关系型数据库TRDB而言的。
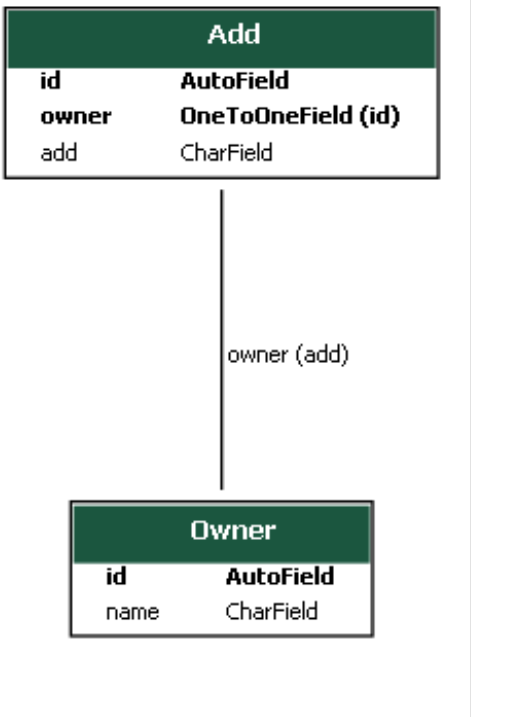
1,一对一
一对一关系存在于两张表中。
如果对于表A中的某一行数据,表B中必须有一行与之联系, 反之亦然, 则称表A与表B具有一对一联系。

使用OneToOneField字段:
class Owner(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=30)
class Add(models.Model):
id = models.AutoField(primary_key=True)
add = models.CharField(max_length=6)
owner = models.OneToOneField(Owner, on_delete=models.CASCADE)
2,一对多
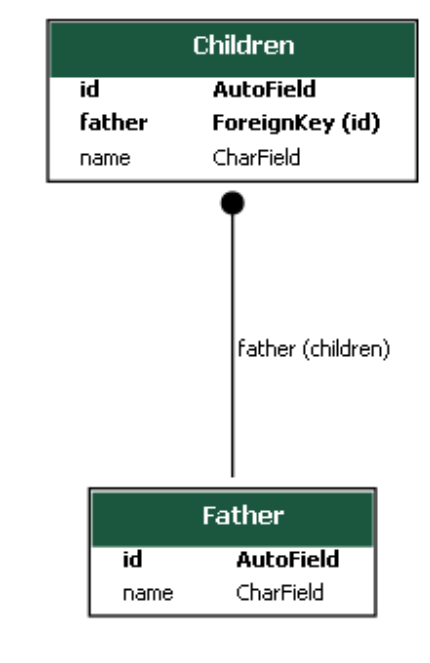
一对多关系存在于两张及以上数量的表中。
如果对于数据表中的每一行数据, 数据表B中有多行与之联系, 反之,对于表B中的每一行, 表A只有一行与之联系, 则称表A与表B有一对多联系。

使用ForeignKey字段:
class Father(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=30)
class Children(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=6)
father = models.ForeignKey(Father, on_delete=models.CASCADE)
3,多对多
多对多关系存在于两张及以上数量的表中。
如果对于表A中的每一行, 表B中有多行与之联系, 反之,对于表B中的每一行, 表A中也有多行与之联系, 则称表A与表B具有多对多联系。

使用ManyToManyField字段:
class Masterpiece(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
class Actor(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=30)
masterpiece = models.ManyToManyField(Masterpiece)

三,简单数据表操作
1,单表操作
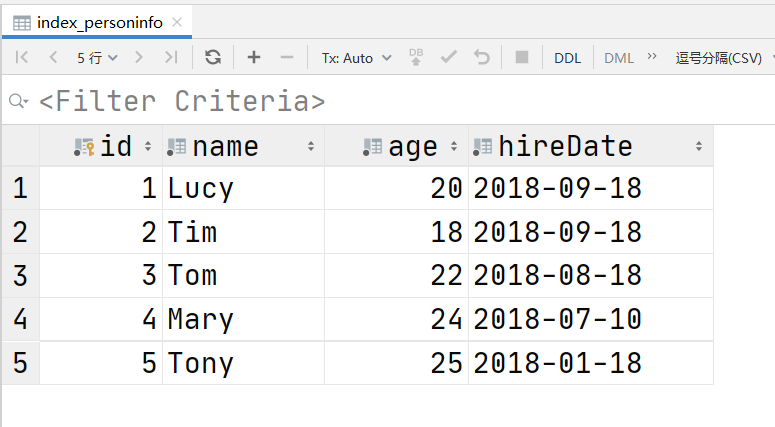
使用模型创建数据表并添加实验数据:
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
hireDate = models.DateField()
def __str__(self):
return self.name
class Meta:
verbose_name = '人员信息'
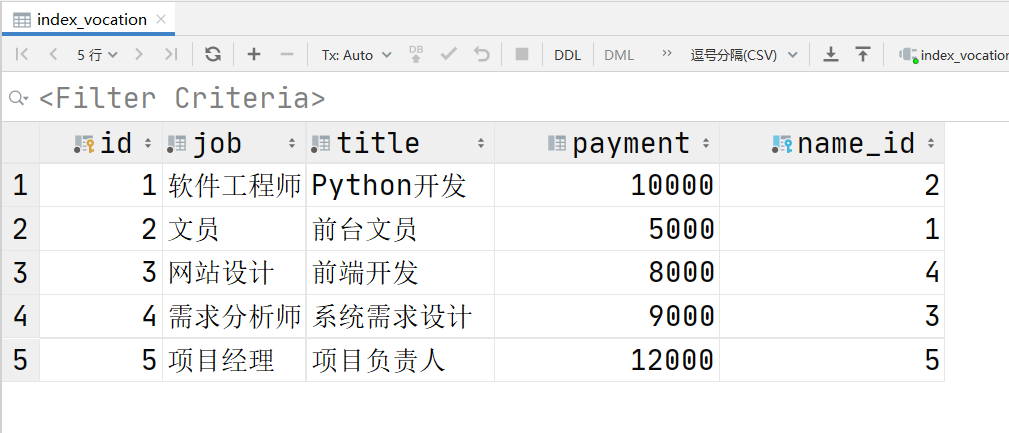
class Vocation(models.Model):
id = models.AutoField(primary_key=True)
job = models.CharField(max_length=20)
title = models.CharField(max_length=20)
payment = models.IntegerField(null=True, blank=True)
name = models.ForeignKey(PersonInfo, on_delete=models.CASCADE, related_name='personinfo')
def __str__(self):
return str(self.id)
class Meta:
verbose_name = '职业信息'
1,增加数据
1,实例化后,单独传入属性进行数据创建
>>> from index.models import *
>>> v = Vocation()
>>> v.job = '测试工程师'
>>> v.title = '系统测试'
>>> v.payment = 0
>>> v.name_id = 3
>>> v.save()
>>> v
<Vocation: 6>
>>> v.job
'测试工程师'
2,实例化时直接传入属性进行数据创建
>>> v = Vocation(job='测试工程师', title='系统测试', payment=0, name_id=3)
>>> v.save()
>>> v
<Vocation: 7>
>>> v.job
'测试工程师'
3,使用create()方法直接传入属性进行数据创建
>>> v = Vocation.objects.create(job='测试工程师', title='系统测试', payment=0, name_id=3)
>>> v
<Vocation: 8>
>>> v.job
'测试工程师'
4,使用create()方法传入字典格式的属性进行数据创建
>>> d = {'job':'测试工程师', 'title':'系统测试', 'payment':0, 'name_id':3}
>>> v = Vocation.objects.create(**d)
>>> v
<Vocation: 9>
>>> v.job
'测试工程师'
5,使用get_or_create()方法避免数据重复插入
>>> d = dict(job='测试工程师', title='系统测试', payment=0, name_id=3)
>>> v = Vocation.objects.get_or_create(**d)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "F:\PythonProjects\web\django-yingyongkaifashizhan\MyDjango\venv\lib\site-packages\django\db\model
s\manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "F:\PythonProjects\web\django-yingyongkaifashizhan\MyDjango\venv\lib\site-packages\django\db\model
s\query.py", line 538, in get_or_create
return self.get(**kwargs), False
File "F:\PythonProjects\web\django-yingyongkaifashizhan\MyDjango\venv\lib\site-packages\django\db\model
s\query.py", line 412, in get
(self.model._meta.object_name, num)
index.models.Vocation.MultipleObjectsReturned: get() returned more than one Vocation -- it returned 4!
>>> d = {'job':'鼓励员', 'title':'喊加油', 'payment':0, 'name_id':4}
>>> Vocation.objects.get_or_create(**d)
(<Vocation: 10>, True)
6,使用update_or_create()方法更新或创建
>>> d = {'job':'软件工程师', 'title':'Java开发', 'payment':10000, 'name_id':3}
>>> v = Vocation.objects.update_or_create(**d)
>>> v
(<Vocation: 11>, True)
>>> v = Vocation.objects.update_or_create(**d, defaults={'title':'Go开发'})
>>> v[0].title
'Go开发'
7,使用bulk_create()方法批量插入
>>> v1 = Vocation(job='财务', title='会计', payment=0, name_id=1)
>>> v2 = Vocation(job='财务', title='出纳', payment=0, name_id=1)
>>> v_list = [v1, v2]
>>> Vocation.objects.bulk_create(v_list)
2,删除数据
链式使用.delete()方法
3,修改数据
1,获取实例,修改属性
>>> v = Vocation.objects.get(id=6)
>>> v.payment
0
>>> v.payment = 2333
>>> v.payment
2333
>>> v.save()
2,修改单条或多条数据——.filter().update()
>>> v = Vocation.objects.filter(id=7).update(payment=2333)
>
>>> v = Vocation.objects.filter(payment=0).update(payment=666)
3,使用bulk_update()方法批量修改
4,查询数据
1,使用all()方法获取所有数据
>>> vs = Vocation.objects.all()
>>> vs
<QuerySet [<Vocation: 1>, <Vocation: 2>, <Vocation: 3>, <Vocation: 4>]><QuerySet [<Vocation: 1>, <Vocation: 2>, <Vocation: 3>, <Vocation: 4>, <Vocation: 5>, <Vocation: 6>, <Voc
ation: 7>, <Vocation: 8>, <Vocation: 9>, <Vocation: 10>, <Vocation: 11>, <Vocation: 12>, <Vocation: 13>]>>>> type(vs)
<class 'django.db.models.query.QuerySet'>
>>> vs[0].job
'软件工程师'
>>> for i in vs:
... print(i.job)
...
软件工程师
文员
网站设计
需求分析师
项目经理
测试工程师
测试工程师
测试工程师
测试工程师
鼓励员
软件工程师
财务
财务
2,使用all()方法获取前四条数据
>>> vs = Vocation.objects.all()[:4]
>>> vs
<QuerySet [<Vocation: 1>, <Vocation: 2>, <Vocation: 3>, <Vocation: 4>]>
>>> type(vs)
<class 'django.db.models.query.QuerySet'>
>>> vs[3].job
'需求分析师'
3,使用get()方法查询某字段
>>> v = Vocation.objects.get(id=2)
>>> v
<Vocation: 2>
>>> type(v)
<class 'index.models.Vocation'>
>>> v.job
'文员'
4,使用filter过滤字段
>>> v = Vocation.objects.filter(title='系统测试')
>>> v
<QuerySet [<Vocation: 6>, <Vocation: 7>, <Vocation: 8>, <Vocation: 9>]>
>>> type(v)
<class 'django.db.models.query.QuerySet'>
>>> v[0].job
'测试工程师'
>>> v = Vocation.objects.filter(payment__lt=8000)
>>> v
<QuerySet [<Vocation: 2>, <Vocation: 6>, <Vocation: 7>, <Vocation: 8>, <Vocation: 9>, <Vocation: 10>, <Vocation: 12>, <Vocation: 13>]>
>>> for i in v:
... print(i.title)
...
前台文员
系统测试
系统测试
系统测试
系统测试
喊加油
会计
出纳
AND:
>>> v = Vocation.objects.filter(payment__lt=8000, title='前台文员')
>>> v
<QuerySet [<Vocation: 2>]>
>>> v[0].payment
5000
>>> v[0].name_id
1
OR:
>>> from django.db.models import Q
>>> v = Vocation.objects.filter(Q(payment__lt=9000) | Q(title='前台文员'))
>>> v
<QuerySet [<Vocation: 2>, <Vocation: 3>, <Vocation: 6>, <Vocation: 7>, <Vocation: 8>, <Vocation: 9>, <Voc
ation: 10>, <Vocation: 12>, <Vocation: 13>]>
NOT:
>>> v = Vocation.objects.filter(~Q(payment__lt=8000))
>>> v
<QuerySet [<Vocation: 1>, <Vocation: 3>, <Vocation: 4>, <Vocation: 5>, <Vocation: 11>]>
>>> for i in v:
... print(str(i.title) + str(i.payment))
...
Python开发10000
前端开发8000
系统需求设计9000
项目负责人12000
Go开发10000
使用exclude()方法实现NOT:
>>> v = Vocation.objects.exclude(payment__lt=7000)
>>> v
<QuerySet [<Vocation: 1>, <Vocation: 3>, <Vocation: 4>, <Vocation: 5>, <Vocation: 11>]>
5,使用values()方法获取某个字段所有值
>>> v = Vocation.objects.values('payment')
>>> v
<QuerySet [{'payment': 10000}, {'payment': 5000}, {'payment': 8000}, {'payment': 9000}, {'payment': 12000
}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 10000}, {'
payment': 0}, {'payment': 0}]>
>>> v[0]['payment']
10000
>>> v = Vocation.objects.values('payment').filter(id__gt=5)
>>> v
<QuerySet [{'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 10
000}, {'payment': 0}, {'payment': 0}]>
6,使用values_list()方法索取某个字段所有值
>>> v = Vocation.objects.values_list('title')[:6]
>>> v
<QuerySet [('Python开发',), ('前台文员',), ('前端开发',), ('系统需求设计',), ('项目负责人',), ('系统测试',)]>
7,使用count()方法统计查询结果数量
>>> v = Vocation.objects.filter(payment__lt=8000)
>>> v.count()
8
8,使用distinct()方法去重查询
>>> count = Vocation.objects.values('job').distinct().count()
>>> count
8
9,使用order_by()方法由某字段对查询结果排序
>>> v = Vocation.objects.values('payment').order_by('payment')
>>> v
<QuerySet [{'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}
, {'payment': 0}, {'payment': 5000}, {'payment': 8000}, {'payment': 9000}, {'payment': 10000}, {'payment'
: 10000}, {'payment': 12000}]>
>>> v = Vocation.objects.values('payment').order_by('-payment')
>>> v
<QuerySet [{'payment': 12000}, {'payment': 10000}, {'payment': 10000}, {'payment': 9000}, {'payment': 800
0}, {'payment': 5000}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'payment': 0}, {'
payment': 0}, {'payment': 0}]>
>>>
2,多表操作
1,一对一
from django.db import models
class Place(models.Model):
name = models.CharField(max_length=50)
address = models.CharField(max_length=80)
def __str__(self):
return "%s the place" % self.name
class Restaurant(models.Model):
place = models.OneToOneField(Place,
on_delete=models.CASCADE,
primary_key=True,
)
serves_hot_dogs = models.BooleanField(default=False)
serves_pizza = models.BooleanField(default=False)
def __str__(self):
return "%s the restaurant" % self.place.name
class Waiter(models.Model):
restaurant = models.ForeignKey(Restaurant,
on_delete=models.CASCADE)
name = models.CharField(max_length=50)
def __str__(self):
return "%s the waiter at %s" % (self.name, self.restaurant)
数据迁移后产生如下三张表:
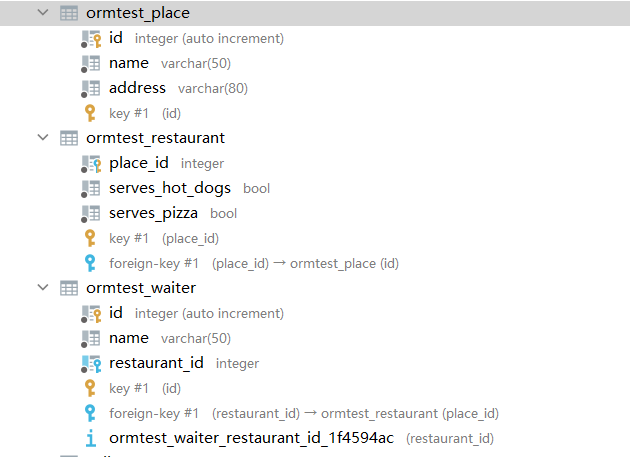
- 表名都是
app名_模型名小写格式 - 模型的外键字段为
外键模型小写名_id格式
1,创建地点
直接添加参数实例化对象并保存:
>>> from ormtest.models import *
>>> p1 = Place(name='Demon Dogs', address='944 W. Fullerton')
>>> p1.save()
>>> p2 = Place(name='Ace Hardware', address='1013 N. Ashland')
>>> p2.save()
2,创建餐厅
传递”父对象(即被关联对象)“作为”子对象“主键,直接添加参数实例化对象并保存:
>>> r = Restaurant(place=p1, serves_hot_dogs=True, serves_pizza=False)
>>> r.save()
3,获取餐厅所在地
通过”子对象“访问”父对象“,得到”父对象“__str__()返回的内容:
>>> r.place
<Place: Demon Dogs the place>
4,地点访问关联的餐厅(如果有的话)
通过”父对象“访问”子对象“,得到”子对象“__str__()返回的内容:
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
5,重置餐厅关联的地址
直接使用赋值符号来设置并保存:
>>> r.place = p2
>>> r.save()
>>> p2.restaurant
<Restaurant: Ace Hardware the restaurant>
>>> r.place
<Place: Ace Hardware the place>
6,重置地址关联的餐厅
直接使用赋值符号来设置并保存:
>>> p1.restaurant = r
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
7,获取所有地点
>>> Place.objects.order_by('name')
<QuerySet [<Place: Ace Hardware the place>, <Place: Demon Dogs the place>]>
8,获取所有餐厅
>>> Restaurant.objects.all()
<QuerySet [<Restaurant: Demon Dogs the restaurant>, <Restaurant: Ace Hardware the restaurant>]>
9,查询某地点
可直接get()查询单条数据,或使用跨域查询:
>>> Restaurant.objects.get(place__pk=1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.filter(place__name__startswith="Demon")
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>
>>> Restaurant.objects.exclude(place__address__contains="Ashland")
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>
10,查询某餐厅
可直接get()查询单条数据,或使用反向查询:
>>> Place.objects.get(pk=1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place=p1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant=r)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place__name__startswith="Demon")
<Place: Demon Dogs the place>
11,新增服务员
除了实例化模型对象创建数据外,还可使用create()方法:
>>> w1 = r.waiter_set.create(name='Joe Dannel')
>>> w2 = r.waiter_set.create(name='Joe James')
>>> w3 = r.waiter_set.create(name='John James')
>>> w3
<Waiter: John James the waiter at Demon Dogs the restaurant>
12,查询服务员:
>>> Waiter.objects.filter(restaurant__place=p1)
<QuerySet [<Waiter: Joe the waiter at Demon Dogs the restaurant>]>
>>> Waiter.objects.filter(restaurant__place__name__startswith="Demon")
<QuerySet [<Waiter: Joe the waiter at Demon Dogs the restaurant>]>
2,一对多
from django.db import models
class Reporter(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
email = models.EmailField()
def __str__(self):
return "%s %s" % (self.first_name, self.last_name)
class Article(models.Model):
headline = models.CharField(max_length=100)
pub_date = models.DateField()
reporter = models.ForeignKey(Reporter, on_delete=models.CASCADE)
def __str__(self):
return self.headline
class Meta:
ordering = ['headline']
1,创建一些 Reporters:
>>> r = Reporter(first_name='John', last_name='Smith', email='john@example.com')
>>> r.save()
>>> r2 = Reporter(first_name='Paul', last_name='Jones', email='paul@example.com')
>>> r2.save()
2,创建一个 Article:
>>> from datetime import date
>>> a = Article(id=None, headline="This is a test", pub_date=date(2005, 7, 27), reporter=r)
>>> a.save()
>>> a.reporter.id
1
>>> a.reporter
<Reporter: John Smith>
3,Article 对象可以访问与它们相关联的 Reporter 对象:
>>> r = a.reporter
4,通过 Reporter 对象来创建一个 Article
>>> new_article = r.article_set.create(headline="John's second story", pub_date=date(2005, 7, 29))
>>> new_article
<Article: John's second story>
>>> new_article.reporter
<Reporter: John Smith>
>>> new_article.reporter.id
1
5,对于相关查询,你可以提供主键值或显式传递相关对象:
>>> Article.objects.filter(reporter__pk=1)
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>> Article.objects.filter(reporter=1)
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>> Article.objects.filter(reporter=r)
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>> Article.objects.filter(reporter__in=[1,2]).distinct()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>
>>> Article.objects.filter(reporter__in=[r,r2]).distinct()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>
6,也可以使用查询集而不是实例的文字列表:
>>> Article.objects.filter(reporter__in=Reporter.objects.filter(first_name='John')).distinct()
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
7,反向查询
>>> Reporter.objects.filter(article__pk=1)
<QuerySet [<Reporter: John Smith>]>
>>> Reporter.objects.filter(article=1)
<QuerySet [<Reporter: John Smith>]>
>>> Reporter.objects.filter(article=a)
<QuerySet [<Reporter: John Smith>]>
>>> Reporter.objects.filter(article__headline__startswith='This')
<QuerySet [<Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>]>
>>> Reporter.objects.filter(article__headline__startswith='This').distinct()
<QuerySet [<Reporter: John Smith>]>
8,反向查询的计数与 distinct() :
>>> Reporter.objects.filter(article__headline__startswith='This').count()
3
>>> Reporter.objects.filter(article__headline__startswith='This').distinct().count()
1
9,如果删除了一个reporter,它的articles将被删除(假设使用设置了 CASCADE )
>>> Article.objects.all()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>
>>> Reporter.objects.order_by('first_name')
<QuerySet [<Reporter: John Smith>, <Reporter: Paul Jones>]>
>>> r2.delete()
>>> Article.objects.all()
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>> Reporter.objects.order_by('first_name')
<QuerySet [<Reporter: John Smith>]>
10,可以在查询中使用JOIN进行删除:
>>> Reporter.objects.filter(article__headline__startswith='This').delete()
>>> Reporter.objects.all()
<QuerySet []>
>>> Article.objects.all()
<QuerySet []>
3,多对多
from django.db import models
class Publication(models.Model):
title = models.CharField(max_length=30)
class Meta:
ordering = ['title']
def __str__(self):
return self.title
class Article(models.Model):
headline = models.CharField(max_length=100)
publications = models.ManyToManyField(Publication)
class Meta:
ordering = ['headline']
def __str__(self):
return self.headline
1,创建几个Publication:
>>> p1 = Publication(title='The Python Journal')
>>> p1.save()
>>> p2 = Publication(title='Science News')
>>> p2.save()
>>> p3 = Publication(title='Science Weekly')
>>> p3.save()
2,创建一个Article:
>>> a1 = Article(headline='Django lets you build Web apps easily')
>>> a1.save()
3,用一个 Publication来关联Article:
>>> a1.publications.add(p1)
4,创建另一个Article,并且设置它的Publications
>>> a2 = Article(headline='NASA uses Python')
>>> a2.save()
>>> a2.publications.add(p1, p2)
>>> a2.publications.add(p3)
>>> new_publication = a2.publications.create(title='Highlights for Children')
5,Article 对象可以访问与它们相关的 Publication 对象:
>>> a1.publications.all()
<QuerySet [<Publication: The Python Journal>]>
>>> a2.publications.all()
<QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>
6,Publication 对象可以访问于它们相关的 Article 对象:
>>> p2.article_set.all()
<QuerySet [<Article: NASA uses Python>]>
>>> p1.article_set.all()
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Publication.objects.get(id=4).article_set.all()
<QuerySet [<Article: NASA uses Python>]>
7,查询多对多关联:
>>> Article.objects.filter(publications__id=1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications__pk=1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications=1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications=p1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications__title__startswith="Science")
<QuerySet [<Article: NASA uses Python>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications__title__startswith="Science").distinct()
<QuerySet [<Article: NASA uses Python>]>
>>> Article.objects.filter(publications__title__startswith="Science").count()
2
>>> Article.objects.filter(publications__title__startswith="Science").distinct().count()
1
>>> Article.objects.filter(publications__in=[1,2]).distinct()
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications__in=[p1,p2]).distinct()
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
8,反向m2m查询:
>>> Publication.objects.filter(id=1)
<QuerySet [<Publication: The Python Journal>]>
>>> Publication.objects.filter(pk=1)
<QuerySet [<Publication: The Python Journal>]>
>>> Publication.objects.filter(article__headline__startswith="NASA")
<QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>
>>> Publication.objects.filter(article__id=1)
<QuerySet [<Publication: The Python Journal>]>
>>> Publication.objects.filter(article__pk=1)
<QuerySet [<Publication: The Python Journal>]>
>>> Publication.objects.filter(article=1)
<QuerySet [<Publication: The Python Journal>]>
>>> Publication.objects.filter(article=a1)
<QuerySet [<Publication: The Python Journal>]>
>>> Publication.objects.filter(article__in=[1,2]).distinct()
<QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>
>>> Publication.objects.filter(article__in=[a1,a2]).distinct()
<QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>
9,如果我们删除 Publication, 它的 Articles 无法访问它:
>>> p1.delete()
>>> Publication.objects.all()
<QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>]>
>>> a1 = Article.objects.get(pk=1)
>>> a1.publications.all()
<QuerySet []>
10,如果我们删除了 Article,它的 Publications 也无法访问它:
>>> a2.delete()
>>> Article.objects.all()
<QuerySet [<Article: Django lets you build Web apps easily>]>
>>> p2.article_set.all()
<QuerySet []>
11,从 Article 中移除 Publication:
>>> a4.publications.remove(p2)
>>> p2.article_set.all()
<QuerySet [<Article: Oxygen-free diet works wonders>]>
>>> a4.publications.all()
<QuerySet []>
12,从另一端移除:
>>> p2.article_set.remove(a5)
>>> p2.article_set.all()
<QuerySet []>
>>> a5.publications.all()
<QuerySet []>
13,可以设置关系:
>>> a4.publications.all()
<QuerySet [<Publication: Science News>]>
>>> a4.publications.set([p3])
>>> a4.publications.all()
<QuerySet [<Publication: Science Weekly>]>
14,关系可以被清除:
>>> p2.article_set.clear()
>>> p2.article_set.all()
<QuerySet []>
15,可以从另一端清除:
>>> p2.article_set.add(a4, a5)
>>> p2.article_set.all()
<QuerySet [<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]>
>>> a4.publications.all()
<QuerySet [<Publication: Science News>, <Publication: Science Weekly>]>
>>> a4.publications.clear()
>>> a4.publications.all()
<QuerySet []>
>>> p2.article_set.all()
<QuerySet [<Article: Oxygen-free diet works wonders>]>
6,执行原生SQL语句
1,Manager.raw(raw_query, params=None, translations=None)
该方法接受一个原生 SQL 查询语句,执行它,会返回一个 django.db.models.query.RawQuerySet 实例。这个 RawQuerySet 能像普通的 QuerySet 一样是可被迭代获取对象实例。
- raw_query:接收SQL语句
- params:用一个列表替换查询字符串中%s占位符,或用字典替换%(key)s 占位符(key被字典key替换)
- translations:将查询语句中的字段映射至模型中的字段
sql_1 = 'SELECT id, job, title, payment From index_vocation'
p = Vocation.objects.raw(raw_query=sql_1)
for q in p:
print(q.job+': '+q.title)
sql_2 = 'SELECT id, %s, %s, %s From index_vocation'
params = ['job', 'title', 'payment']
p = Vocation.objects.raw(raw_query=sql_2,params=params)
for q in p:
print(q.job+': '+q.title)
2, Manager.extra(self, select=None, where=None, params=None, tables=None,order_by=None, select_params=None):
返回QuerySet类型。
p = Vocation.objects.extra(where=["job=%s"], params=["测试工程师"],order_by=["-payment"])
for q in p:
print(q.job+': '+str(q.payment))
3,原生SQL cursor.execute(sql, [params])
from django.db import connection
def my_custom_sql(self):
with connection.cursor() as cursor:
cursor.execute("UPDATE bar SET foo = 1 WHERE baz = %s", [self.baz])
cursor.execute("SELECT foo FROM bar WHERE baz = %s", [self.baz])
row = cursor.fetchone()
return row
四,多数据库的连接与使用
使用多数据库最简单的方式就是设置数据库路由方案,默认路由方案确保当数据库没有指定时,所有查询回退到 default 数据库。
数据库路由 DATABASE_ROUTERS 配置安装。这个配置定义类名列表,每个类名指定了主路由(django.db.router)应使用的路由。Django 的数据库操作使用主路由来分配数据库使用。每当查询需要知道正在使用哪个数据库时,它会调用主路由,提供一个模型和提示(如果可用的话),然后 Django 会依次尝试每个路由直到找到数据库。如果没有找到,它试着访问提示实例的当前 instance._state.db 。如果没有提供提示实例,或者 instance._state.db 为 None ,主路由将分配默认数据库。
settings.py:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'indexdb',
'USER': 'root',
'PASSWORD': '1234',
"HOST": "localhost",
'PORT': '3306',
},
'db2': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'userdb',
'USER': 'root',
'PASSWORD': '1234',
"HOST": "localhost",
'PORT': '3306',
},
}
# 配置多数据库
DATABASE_ROUTERS = ['MyDjango.dbRouter.DbAppsRouter']
DATABASE_APPS_MAPPING = {
# 设置每个App的模型使用的数据库
# {'app_name':'database_name',}
'admin': 'defualt',
'index': 'db1',
'user': 'db2',
}
MyDjango.dbRouter.DbAppsRouter:
项目同名文件.文件.类:
from django.conf import settings
DATABASE_MAPPING = settings.DATABASE_APPS_MAPPING
class DbAppsRouter(object):
"""
A router to control all database operations on models for different
databases.
In case an app is not set in settings.DATABASE_APPS_MAPPING, the router
will fallback to the `default` database.
Settings example:
DATABASE_APPS_MAPPING = {'app1': 'db1', 'app2': 'db2'}
"""
def db_for_read(self, model, **hints):
""""Point all read operations to the specific database."""
if model._meta.app_label in DATABASE_MAPPING:
return DATABASE_MAPPING[model._meta.app_label]
return None
def db_for_write(self, model, **hints):
"""Point all write operations to the specific database."""
if model._meta.app_label in DATABASE_MAPPING:
return DATABASE_MAPPING[model._meta.app_label]
return None
def allow_relation(self, obj1, obj2, **hints):
"""Allow any relation between apps that use the same database."""
db_obj1 = DATABASE_MAPPING.get(obj1._meta.app_label)
db_obj2 = DATABASE_MAPPING.get(obj2._meta.app_label)
if db_obj1 and db_obj2:
if db_obj1 == db_obj2:
return True
else:
return False
return None
# 用于创建数据表
def allow_migrate(self, db, app_label, model_name=None, **hints):
if db in DATABASE_MAPPING.values():
return DATABASE_MAPPING.get(app_label) == db
elif app_label in DATABASE_MAPPING:
return False
return None
先创建模型,并指定所属的应用:
index/models.py:
from django.db import models
class City(models.Model):
name = models.CharField(max_length=50)
class Meta:
# 设置模型所属的App,从而在相应的数据库里生成数据表
app_label = "index"
# 自定义数据表名称
db_table = 'city'
# 定义数据表在Admin后台的显示名称
verbose_name = '城市信息表'
def __str__(self):
return self.name
user/models.py:
from django.db import models
class PersonInfo(models.Model):
name = models.CharField(max_length=50)
age = models.CharField(max_length=100)
live = models.CharField(max_length=100)
class Meta:
# 设置模型所属的App,从而在相应的数据库里生成数据表
app_label = "user"
# 自定义数据表名称
db_table = 'personinfo'
# 定义数据表在Admin后台的显示名称
verbose_name = '个人信息表'
def __str__(self):
return self.name
当然也能手动指定数据库:
选择指定数据库进行查询:
>>> # This will run on the 'default' database.
>>> Author.objects.all()
>>> # So will this.
>>> Author.objects.using('default').all()
使用 using 关键字来 Model.save() 到指定的数据保存的数据库:
>>> my_object.save(using='db1')
数据迁移:
python manage.py makemigrations
python manage.py migrate --database=index
python manage.py migrate --database=users
需要注意的是:
- 由于上面两张表不在一个数据库里,如果任何模型包含与其他数据库之外的模型的关系,那么将导致这个例子将无法运行。主要是因为Django 当前不提供对跨多数据库的外键或多对多关系任何支持,这是为了维护参照完整性。
- 数据库路由进定义了使对用不同数据库的分发,但读写方式同时相同的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98116.html

