
索引用于提高查询的性能。 如果没有索引,MongoDB必须搜索整个集合以选择与查询语句匹配的那些文档。 因此,为了加快查询速度,MongoDB使用索引来限制它必须扫描的文档数。
索引是一种特殊的数据结构,以易于转换的格式存储集合数据集中的一小部分。索引存储一组按字段值排序的字段,此排序有助于提高相等匹配和基于范围的查询操作的性能。
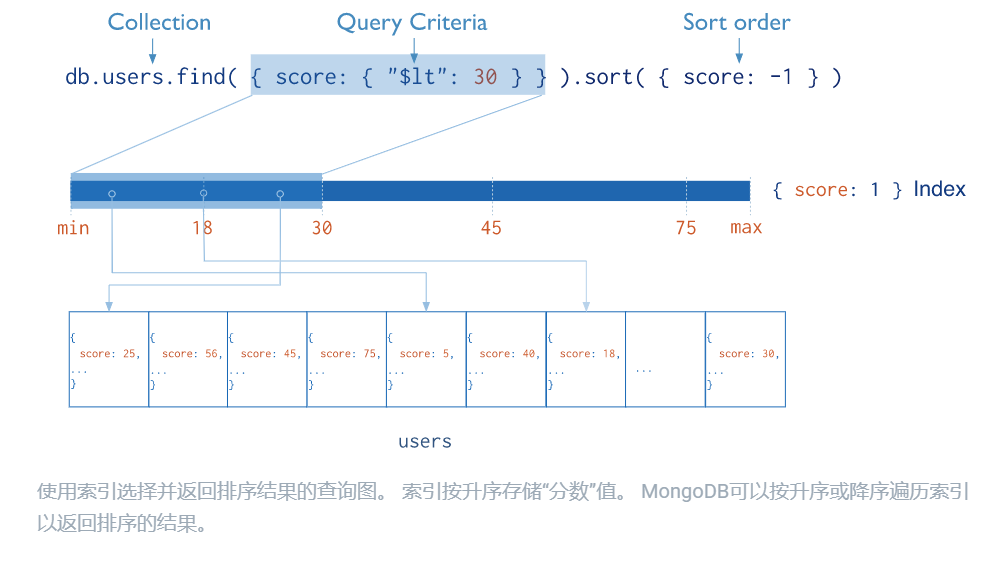

MongoDB在集合级别定义索引,并且可以在文档的任何字段上创建索引。默认情况下,MongoDB为_id字段创建索引。
一,使用索引
1,创建索引
方法:db.collection.createIndex()
> db.employee.insert({empId:1,empName:"John",state:"KA",country:"India"})
WriteResult({ "nInserted" : 1 })
> db.employee.insert({empId:2,empName:"Smith",state:"CA",country:"US"})
WriteResult({ "nInserted" : 1 })
> db.employee.insert({empId:3,empName:"James",state:"FL",country:"US"})
WriteResult({ "nInserted" : 1 })
> db.employee.insert({empId:4,empName:"Josh",state:"TN",country:"India"})
WriteResult({ "nInserted" : 1 })
> db.employee.insert({empId:5,empName:"Joshi",state:"HYD",country:"India"})
WriteResult({ "nInserted" : 1 })
示例:在empId字段创建单字段索引
> db.employee.createIndex({empId:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
- 在此,参数值“
1”指示将以升序存储empId字段值。
示例:创建复合索引
> db.employee.createIndex({empId:1,empName:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
2,查询索引
方法:db.collection.getIndexes()
示例:查询索引列表
> db.employee.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.employee"
},
{
"v" : 2,
"key" : {
"empId" : 1
},
"name" : "empId_1",
"ns" : "test.employee"
},
{
"v" : 2,
"key" : {
"empId" : 1,
"empName" : 1
},
"name" : "empId_1_empName_1",
"ns" : "test.employee"
}
]
3,删除索引
方法:db.employee.dropIndexes()
示例:删除复合索引
> db.employee.dropIndex({empId:1,empName:1})
{ "nIndexesWas" : 3, "ok" : 1 }
示例:删除所有索引
> db.employee.dropIndexes()
{
"nIndexesWas" : 2,
"msg" : "non-_id indexes dropped for collection",
"ok" : 1
}
- 不能删除默认的)
_id索引
二,索引类型

1,Multikey Index
多键索引对含有数组值的字段很有用,它可以为数组中的每一个元素创建索引。
db.employeeproject.insert({empId:1001,empName:"John",projects:["Hadoop","MongoDB"]})
db.employeeproject.insert({empId:1002,empName:"James",projects:["MongoDB","Spark"]})
示例:对projects字段创建索引
> db.employeeproject.createIndex({projects:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
- 不能创建复合多键索引
2,Text Indexes
MongoDB提供文本索引以支持对字符串内容的文本搜索查询。可以在以字符串或字符串元素数组作为其值的字段上创建文本索引。
> db.post.insert({
... "post_text": "Happy Learning",
... "tags": [
... "mongodb",
... "10gen"
... ]
... })
WriteResult({ "nInserted" : 1 })
示例,对post_text字段创建文本索引
> db.post.createIndex({post_text:"text"})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
示例:使用文本索引进行查询
> db.post.find({$text:{$search:"Happy"}})
{ "_id" : ObjectId("5f696fe39dc47b216b82fb2a"), "post_text" : "Happy Learning", "tags" : [ "mongodb", "10gen" ] }
3,Hashed Indexes
索引的大小可以借助哈希索引来减小。 哈希索引存储索引字段值的哈希值。 哈希索引支持使用哈希分片键进行分片。 在基于哈希索引的分片中,字段的哈希索引用作分片键,以跨分片群集对数据进行分区。
- 哈希索引不支持多键索引。
db.user.insert({userId:1,userName:"John"})
db.user.insert({userId:2,userName:"James"})
db.user.insert({userId:3,userName:"Jack"})
示例:对userId字段创建哈希索引
> db.user.createIndex( { userId: "hashed" } )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
3,2dsphereIndexes
2dsphere索引支持所有MongoDB地理空间查询。
db.schools.insert( { name: "St.John's School", location: { type: "Point", coordinates: [ -73.97, 40.77 ] }, } );
db.schools.insert( { name: "St.Joseph's School", location: { type: "Point", coordinates: [ -73.9928, 40.7193 ] }, } );
db.schools.insert( { name: "St.Thomas School", location: { type: "Point", coordinates: [ -73.9375, 40.8303 ] }, } );
- 插入了三个geojson点的数据
示例:创建2dsphere索引
> db.schools.createIndex( { location : "2dsphere" } )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
示例:使用$near返回距指定点至少500m至多1500m的坐标点
> db.schools.find({location:{$near:{$geometry: { type: "Point", coordinates: [ -73.9667, 40.78 ] },$minDistance: 500,$maxDistance: 1500}}})
{ "_id" : ObjectId("5f69bad89dc47b216b82fb2e"), "name" : "St.John's School", "location" : { "type" : "Point", "coordinates" : [ -73.97, 40.77 ] } }
三,索引的属性
索引也可以具有属性。 索引属性定义了运行时索引字段的某些特征和行为。 例如,唯一索引可确保索引字段不支持重复项。
1,TTL Indexes
生存时间索引TTL Indexes是单字段索引,用于在一定时间后从集合中删除文档。 数据到期对于某些类型的信息(例如日志,机器生成的数据等)很有用。
db.credit.insert({credit:16})
db.credit.insert({credit:18})
db.credit.insert({credit:12})
示例:在credit字段创建索引
> db.credit.createIndex( { credit: 1 }, { expireAfterSeconds:35 } )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
2,Unique Indexes
确保索引Unique Indexes字段不包含任何重复值。 默认情况下,MongoDB在_id字段上创建一个唯一索引。
db.student.insert({_id:1,studid:101,studname:"John"})
db.student.insert({_id:2,studid:102,studname:"Jack"})
db.student.insert({_id:3,studid:103,studname:"James"})
示例:在studId字段创建唯一索引
> db.student.createIndex({"studid":1}, {unique:true})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
当再想插入包含stuid:101的文档就会报错:
> db.student.insert([{_id:1,studid:101,studname:"John"}])
BulkWriteResult({
"writeErrors" : [
{
"index" : 0,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: test.student index: _id_ dup key: { _id: 1.0 }",
"op" : {
"_id" : 1,
"studid" : 101,
"studname" : "John"
}
}
],
"writeConcernErrors" : [ ],
"nInserted" : 0,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
3,Partial Indexes
要索引集合中满足特定过滤条件的文档时,部分索引Partial Indexes很有用。 可以使用任何运算符指定过滤条件。 例如,db.person.find({age:{$ gt:15}})可用于在person集合中查找具有大于15的年龄的文档。 部分索引可降低存储要求和性能成本,因为它们仅存储文档的一部分。
使用partialFilterExpression选项创建部分索引,它接受如下过滤器:
- equality expressions (i.e., field: value or using the
$eqoperator) $exists: true expression$gt,$gte,$lt, and$lteexpressions$typeexpressions$andoperator at the top level only
db.person.insert({personName:"John",age:16})
db.person.insert({personName:"James",age:15})
db.person.insert({personName:"John",hobbies:["sports","music"]})
示例:创建age大于15的部分索引
> db.person.createIndex( { age: 1},{partialFilterExpression: {
... age: { $gt: 15 }}})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.person.find( { age: { $gt: 15 } } )
{ "_id" : ObjectId("5f69c2bd9dc47b216b82fb34"), "personName" : "John", "age" : 16 }
4,Sparse Indexes
稀疏索引Sparse Indexes仅存储具有索引字段的文档的条目,即使它包含空值也是如此。 稀疏索引将跳过所有没有索引字段的文档。 该索引被认为是稀疏的,因为它不包括集合的所有文档。
db.person.insert({personName:"John",age:16})
db.person.insert({personName:"James",age:15})
db.person.insert({personName:"John",hobbies:["sports","mus
ic"]})
示例:在age字段创建稀疏索引
> db.person.createIndex( { age: 1 }, { sparse: true } )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
示例:使用hint()指明使用指定索引字段的文档
> db.person.find().hint( { age: 1 } ).count()
2
示例:使用count()对查询结果进行统计
> db.person.find().count();
3
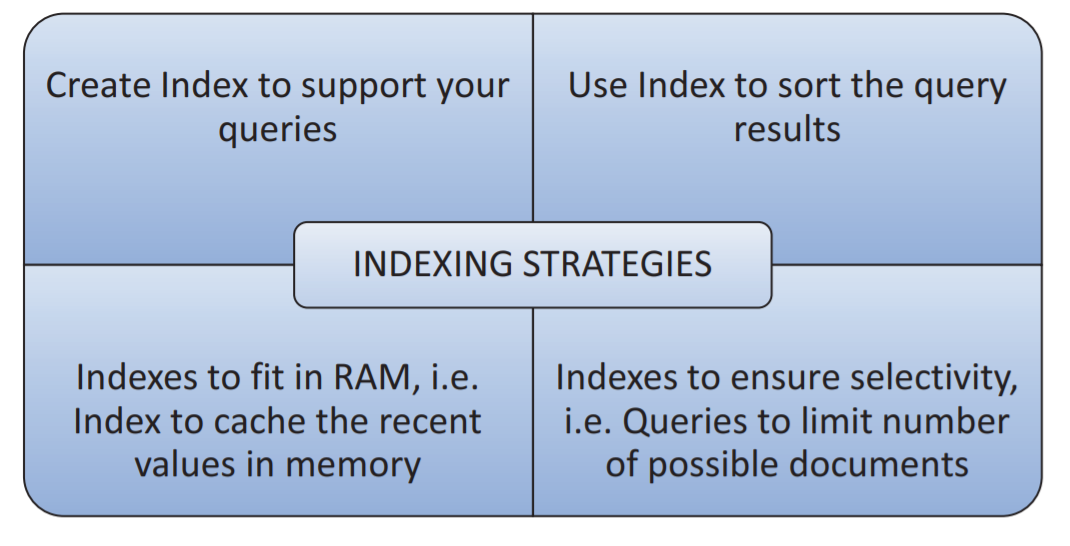
四,索引策略
我们必须遵循不同的策略来为我们的需求创建正确的索引。
最好的索引策略需要由不同的因素来定义,包括:
- 执行查询的类型
- 读写的数据流量
- 可用内存
the different indexing strategies:
1,Create an Index to Support Your Queries
创建正确的索引以支持查询可提高查询性能。
如果所有查询都使用相同的单个键来检索文档,则创建一个单字段索引。
如果所有查询都使用相同的单个键来检索文档,则创建一个单字段索引。
如果所有查询都使用多个关键字(多个过滤条件)来检索文档,则创建一个多字段复合索引。
> db.employee.createIndex({empId:1,empName:1})
2,Using an Index to Sort the Query Results
排序操作可使用索引以获得更好的性能。 索引根据索引中的顺序获取文档来确定排序顺序。 可以在以下情况下进行排序:
- 使用单字段索引排序
- 使用多字段索引排序
1,Sorting with a Single-Field Index
索引支持升序与降序排序。
> db.employee.createIndex({empId:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
示例:查询所有文档
> db.employee.find()
{ "_id" : ObjectId("5f6967bc9dc47b216b82fb23"), "empId" : 1, "empName" : "John", "state" : "KA", "country" : "India" }
{ "_id" : ObjectId("5f6967c79dc47b216b82fb24"), "empId" : 2, "empName" : "Smith", "state" : "CA", "country" : "US" }
{ "_id" : ObjectId("5f6967cc9dc47b216b82fb25"), "empId" : 3, "empName" : "James", "state" : "FL", "country" : "US" }
{ "_id" : ObjectId("5f6967d29dc47b216b82fb26"), "empId" : 4, "empName" : "Josh", "state" : "TN", "country" : "India" }
{ "_id" : ObjectId("5f6967d79dc47b216b82fb27"), "empId" : 5, "empName" : "Joshi", "state" : "HYD", "country" : "India" }
- 默认_id升序
示例:empId降序
> db.employee.find().sort({empId:-1})
{ "_id" : ObjectId("5f6967d79dc47b216b82fb27"), "empId" : 5, "empName" : "Joshi", "state" : "HYD", "country" : "India" }
{ "_id" : ObjectId("5f6967d29dc47b216b82fb26"), "empId" : 4, "empName" : "Josh", "state" : "TN", "country" : "India" }
{ "_id" : ObjectId("5f6967cc9dc47b216b82fb25"), "empId" : 3, "empName" : "James", "state" : "FL", "country" : "US" }
{ "_id" : ObjectId("5f6967c79dc47b216b82fb24"), "empId" : 2, "empName" : "Smith", "state" : "CA", "country" : "US" }
{ "_id" : ObjectId("5f6967bc9dc47b216b82fb23"), "empId" : 1, "empName" : "John", "state" : "KA", "country" : "India" }
示例:empId升序
> db.employee.find().sort({empId:1})
{ "_id" : ObjectId("5f6967bc9dc47b216b82fb23"), "empId" : 1, "empName" : "John", "state" : "KA", "country" : "India" }
{ "_id" : ObjectId("5f6967c79dc47b216b82fb24"), "empId" : 2, "empName" : "Smith", "state" : "CA", "country" : "US" }
{ "_id" : ObjectId("5f6967cc9dc47b216b82fb25"), "empId" : 3, "empName" : "James", "state" : "FL", "country" : "US" }
{ "_id" : ObjectId("5f6967d29dc47b216b82fb26"), "empId" : 4, "empName" : "Josh", "state" : "TN", "country" : "India" }
{ "_id" : ObjectId("5f6967d79dc47b216b82fb27"), "empId" : 5, "empName" : "Joshi", "state" : "HYD", "country" : "India" }
2,Sorting on Multiple Fields
> db.employee.createIndex({empId:1,empName:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
示例:多字段索引排序
> db.employee.find().sort({empId:1,empName:1})
{ "_id" : ObjectId("5f6967bc9dc47b216b82fb23"), "empId" : 1, "empName" : "John", "state" : "KA", "country" : "India" }
{ "_id" : ObjectId("5f6967c79dc47b216b82fb24"), "empId" : 2, "empName" : "Smith", "state" : "CA", "country" : "US" }
{ "_id" : ObjectId("5f6967cc9dc47b216b82fb25"), "empId" : 3, "empName" : "James", "state" : "FL", "country" : "US" }
{ "_id" : ObjectId("5f6967d29dc47b216b82fb26"), "empId" : 4, "empName" : "Josh", "state" : "TN", "country" : "India" }
{ "_id" : ObjectId("5f6967d79dc47b216b82fb27"), "empId" : 5, "empName" : "Joshi", "state" : "HYD", "country" : "India" }
3,Index to Hold Recent Values in Memory
当使用多个集合时,我们必须考虑所有集合上索引的大小,并确保索引适合内存,以避免系统从磁盘读取索引。 使用以下查询检查任何集合的索引大小:
> db.employee.totalIndexSize()
77824
4,Create Queries to Ensure Selectivity
任何查询使用创建的索引来缩小结果范围的能力称为选择性。 编写查询来限制带有索引字段的可能文档的数量,以及相对于索引数据适当选择的查询,可以确保选择性。
示例:扫描所有文档查询empId值大于1的文档
> db.employee.find({empId:{$gt:1}, country:"India"})
{ "_id" : ObjectId("5f6967d29dc47b216b82fb26"), "empId" : 4, "empName" : "Josh", "state" : "TN", "country" : "India" }
{ "_id" : ObjectId("5f6967d79dc47b216b82fb27"), "empId" : 5, "empName" : "Joshi", "state" : "HYD", "country" : "India" }
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98128.html

