
一,数据模型
有效的数据模型能平衡应用程序的需求、数据库引擎的性能特征和数据检索模式。在设计数据模型时,始终考虑数据的应用程序使用(即数据的查询、更新和处理)以及数据本身的固有结构。
MongoDB为数据建模提供了两种数据模型设计:
嵌入式数据模型规范化数据模型
1,Embedded Data Models
在MongoDB中,您可以将相关数据嵌入到单个文档中。 这个模式设计被称为非规范化模型。如下:
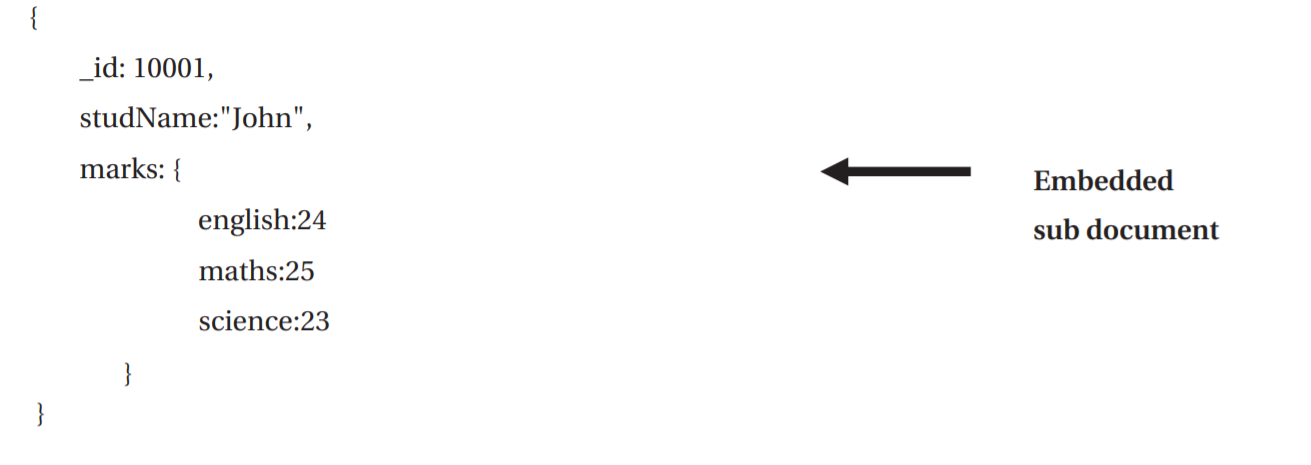
嵌入式数据模型允许应用程序存储同一记录中的相关信息,所以,应用程序只需要很少的查询和更新即可完成通用操作。
可以使用嵌入式文档Embedded documents来表示一对一`关系两个实体之间的“包含”关系)和一对多关系(在一个父文档中可以看到多条文档)。
在以下情况下,嵌入式数据模型可提供更好的操作效果:
- 用于大量读操作时。
- 当需要从一个数据库操作中找到相关数据时。
嵌入式数据模型在单原子操作中更新相关数据。
嵌入式文档数据可以使用点表示法进行访问。
2,Normalized Data Models
规范化的数据模型使用引用references描述关系。如下:
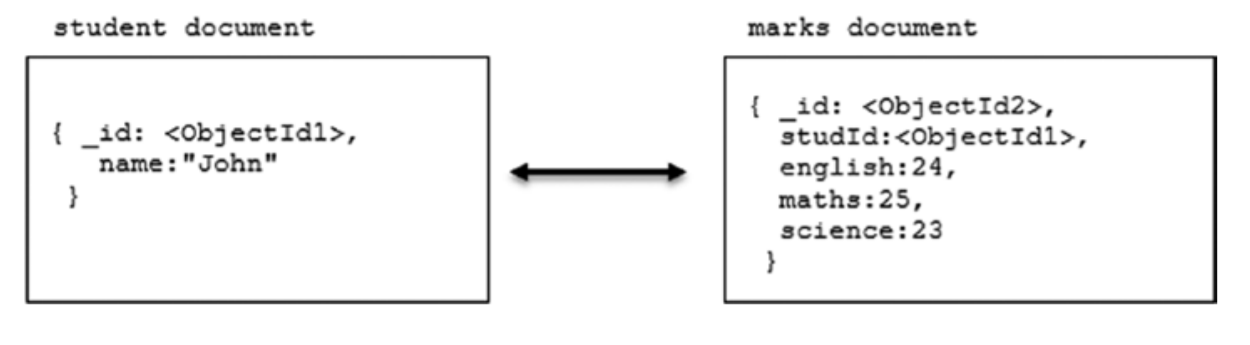
在以下情况下,规范化数据模型可提供最好的操作效果:
- 嵌入数据模型会导致数据重复时。
- 表示复杂的多对多关系时。
- 为大型分层数据集建模时。
规范化数据模型的读表现不太好。
二,文档间的数据模型关系
为MongoDB应用程序设计数据模型的关键决策是围绕文档的结构以及应用程序如何表示数据之间的关系。
接下来就需要探索使用嵌入式文档和引用的数据模型。
1,Data Model Using an Embedded Document
示例:One-to-One Relationships
{
_id: "James",
name: "James William"
}
{
student_id: "James",
street: "123 Hill Street",
city: "New York",
state: "US",
}
在这里,有学生和地址的关系,其中一个地址属于一个学生。 如果我们要经常根据学生姓名来检索地址数据,则需要多个查询才能解析引用。
在这种情况下,我们可以将地址数据与学生数据一起嵌入,以提供更好的数据模型,如下所示:
{
_id: "James",
name: "James William",
address: {
street: "123 Hill Street",
city: "New York",
state: "US",
}
}
使用此数据模型,我们可以通过一个查询检索完整的学生信息。
示例:One-to-Many Relationships
{
_id: "James",
name: "James William"
}
{
student_id: "James",
street: "123 Hill Street",
city: "New York",
state: "US",
}
{
student_id: "James",
street: "234 Thomas Street",
city: "New Jersey",
state: "US",
}
也是同样的情况,也采用同样的嵌入式文档:
{
_id: "James",
name: "James William",
address: [
{
street: "123 Hill Street",
city: "New York",
state: "US",
},
{
street: "234 Thomas Street",
city: "New Jersey",
state: "US",
}
]
}
2,Data Model Using Document References
示例:One-to-Many Relationships
{
title: "Practical Apache Spark",
author: [ "Subhashini Chellappan", "Dharanitharan Ganesan" ],
published_date: ISODate("2018-11-30"),
pages: 300,
language: "English",
publisher: {
name: "Apress",
founded: 1999,
location: "US"
}
}
{
title: "MongoDB Recipes",
author: [ "Subhashini Chellappan"],
published_date: ISODate("2018-11-30"),
pages: 120,
language: "English",
publisher: {
name: "Apress",
founded: 1999,
location: "US"
}
}
在这里,出版商文档嵌入在图书文档中,这导致数据模型的重复。
在这种情况下,我们可以记录引用以避免重复数据。 在文档引用中,关系的增长决定了存储引用的位置。 如果每个出版商的图书数量很少,那么我们可以将图书参考存储在出版商文档中,如下所示:
{
name: "Apress",
founded: 1999,
location: "US",
books: [123456, 456789, ...]
}
{
_id: 123456,
title: "Practical Apache Spark",
author: [ "Subhashini Chellappan", "Dharanitharan Ganesan"],
published_date: ISODate("2018-11-30"),
pages: 300,
language: "English"
}
{
_id: 456789,
title: "MongoDB Recipes",
author: [ "Subhashini Chellappan"],
published_date: ISODate("2018-11-30"),
pages: 120,
language: "English"
}
如果每个出版商的书籍数量不受限制,则此数据模型将导致可变的、不断增长的引用数组。
我们可以通过将对出版商的引用资料存储在本书文档中来避免这种情况,如下所示:
{
_id:"Apress",
name: "Apress",
founded: 1999,
location: "US"
}
{
_id: 123456,
title: "Practical Apache Spark",
author: [ "Subhashini Chellappan", "Dharanitharan Ganesan" ],
published_date: ISODate("2018-11-30"),
pages: 300,
language: "English",
publisher_id: "Apress"
}
{
_id: 456789,
title: "MongoDB Recipes",
author: [ "Subhashini Chellappan"],
published_date: ISODate("2018-11-30"),
pages: 120,
language: "English",
publisher_id: "Apress"
}
示例:Query Document References
db.publisher.insert({_id:"Apress",name:"Apress", founded:1999,location:"US"})
db.authors.insertMany([
{_id: 123456,title: "Practical Apache Spark",author:["Subhashini Chellappan", "Dharanitharan Ganesan"], published_date:ISODate("2018-11-30"),pages: 300,language:"English",publisher_id: "Apress"},
{_id: 456789,title: "MongoDB Recipes", author: [ "Subhashini Chellappan"],published_date: ISODate("2018-11-30"), pages: 120,language:
"English",publisher_id: "Apress"}
])
要执行左连接(返回左表中所有记录和右表中连接字段相等的记录,即返回的记录数和左表的记录数一样),请使用$ lookup,如下所示:
> db.publisher.aggregate([{$lookup:{from:"authors",localField:"_id", foreignField:"publisher_id",as:"authors_docs"}}])
{ "_id" : "Apress", "name" : "Apress", "founded" : 1999,
"location" : "US", "authors_docs" : [ { "_id" : 123456,
"title" : "Practical Apache Spark", "author" : [ "Subhashini
Chellappan", "Dharanitharan Ganesan" ], "published_date" :
ISODate("2018-11-30T00:00:00Z"), "pages" : 300, "language"
: "English", "publisher_id" : "Apress" }, { "_id" : 456789,
"title" : "MongoDB Recipes", "author" : [ "Subhashini
Chellappan" ], "published_date" : ISODate("2018-11-
30T00:00:00Z"), "pages" : 120, "language" : "English",
"publisher_id" : "Apress" } ] }
三,模型树结构
https://docs.mongodb.com/manual/applications/data-models-tree-structures/
Tree Structure with Parent References
父引用模式将每个树节点存储在文档中; 除树节点外,文档还存储该节点的父节点的_id,如下:
db.author.insert( { _id: "Practical Apache Spark", parent:"Books" } )
db.author.insert( { _id: "MongoDB Recipes", parent: "Books" } )
db.author.insert( { _id: "Books", parent: "Subhashini" } )
db.author.insert( { _id: "A Framework For Extracting Information From Web Using VTD-XML ' s XPath", parent:"Article" } )
db.author.insert( { _id: "Article", parent: "Subhashini" } )
db.author.insert( { _id: "Subhashini", parent: null } )
模型树结构如下:
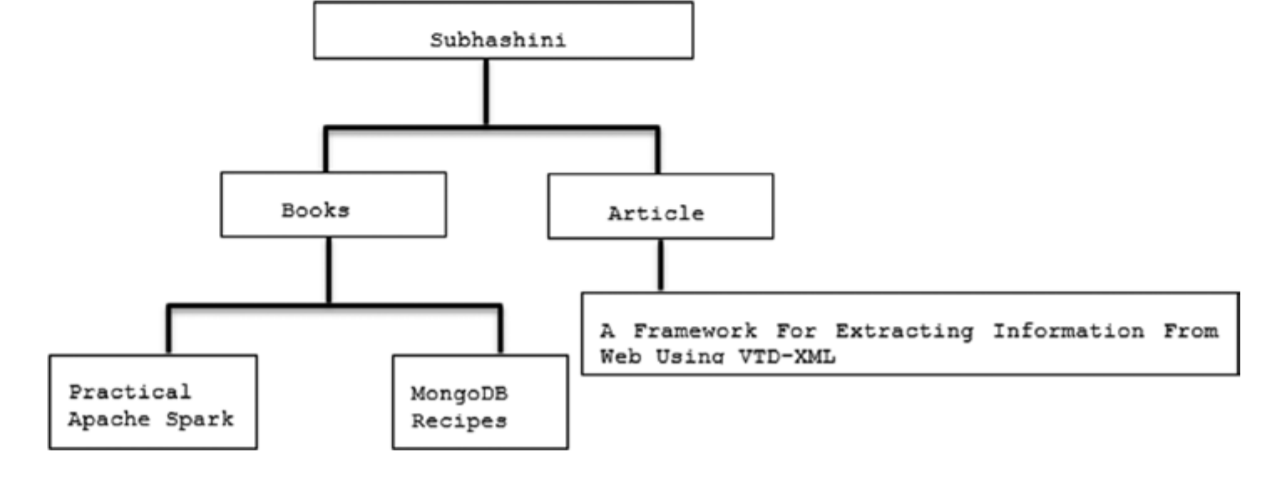
示例:使用下面的命令查询一个结点的父节点:
> db.author.findOne( { _id: "MongoDB Recipes" } ).parent
Books
示例:使用下面的命令查询有同一个父结点的所有节点:
> db.author.find( { parent: "Subhashini" } )
{ "_id" : "Books", "parent" : "Subhashini" }
{ "_id" : "Article", "parent" : "Subhashini" }
Tree Structure with Child References
子引用模式将每个树节点存储在文档中; 除了树节点之外,该文档还将该节点的子节点的_id值存储在数组中。
db.author.insert( { _id: "Practical Apache Spark", children: [] } )
db.author.insert( { _id: "MongoDB", children: [] } )
db.author.insert( { _id: "Books", children: [ "Practical Apache Spark", "MongoDB Recipes" ] } )
db.author.insert( { _id: " A Framework For Extracting Information From Web Using VTD-XML ' s XPath ", children: [] } )
db.author.insert( { _id: "Article", children: [ " A Framework For Extracting Information From Web Using VTD-XML ' s XPath " ] } )
db.categories.insert( { _id: "Subhashini", children: ["Books","Article" ] } )
示例:查询Books节点的子节点
> db.author.findOne( { _id: "Books" } ).children
[ "Practical Apache Spark", "MongoDB Recipes" ]
示例:查询子节点包含MongoDB Recipes信息的节点
> db.author.find( { children: "MongoDB Recipes" } )
{ "_id" : "Books", "children" : [ "Practical Apache Spark", "MongoDB Recipes" ] }
Tree Structure with an Array of Ancestors
祖先数组将每个树节点存储在文档中。 除树节点外,文档还将节点祖先或路径的_id值存储在数组中。
db.author.insert( { _id: "Practical Apache Spark", ancestors: ["Subhashini", "Books" ], parent: "Books" } )
db.author.insert( { _id: "MongoDB Recipes", ancestors: ["Subhashini", "Books" ], parent: "Books" } )
db.author.insert( { _id: "Books", ancestors: [ "Subhashini" ],parent: "Subhashini" } )
db.author.insert( { _id: " A Framework For Extracting Information From Web Using VTD-XML ", ancestors: [ "Subhashini", "Article" ], parent: "Article" } )
db.author.insert( { _id: "Article", ancestors: [ "Subhashini"], parent: "Subhashini" } )
db.author.insert( { _id: "Subhashini", ancestors: [ ], parent:null } )
示例:查询节点祖先
> db.author.findOne( { _id: "MongoDB Recipes" } ).ancestors
[ "Subhashini", "Books" ]
示例:查询拥有该祖先的后代
> db.author.find( { ancestors: "Subhashini" } )
{ "_id" : "Practical Apache Spark", "ancestors" : [
"Subhashini", "Books" ], "parent" : "Books" }
{ "_id" : "MongoDB Recipes", "ancestors" : [ "Subhashini",
"Books" ], "parent" : "Books" }
{ "_id" : "Books", "ancestors" : [ "Subhashini" ], "parent" :
"Subhashini" }
{ "_id" : " A Framework For Extracting Information From Web
Using VTD-XML ", "ancestors" : [ "Subhashini", "Article" ],
"parent" : "Article" }
{ "_id" : "Article", "ancestors" : [ "Subhashini" ], "parent" :
"Subhashini" }
四,聚集Aggregation
聚集(聚合)操作对来自多个文档的值进行分组,并且可以对分组后的值执行各种操作以返回单个结果。 MongoDB提供以下聚合操作:
- 聚合管道
- Map-reduce功能
- 单一目的聚合方法
1,聚集管道
聚合管道是用于数据聚合的框架。 它是基于数据处理管道的概念建模的。 管道对某些输入执行操作,并将该输出用作下一个操作的输入。 文档进入多阶段流水线,将其转换为汇总结果。作用类似于Linux shell中的“ | ”。
函数:db.collection.aggregate()
db.orders.insertMany([{custID:"10001",amount:500,status:"A"},{custID:"10001",amount:250,status:"A"},{custID:"10002",amount:200,status:"A"},{custID:"10001",amount: 300,status:"D"}]);
示例:查询消费者IDs
> db.orders.aggregate( [ { $project : { custID : 1 , _id : 0 }} ] )
{ "custID" : "10001" }
{ "custID" : "10001" }
{ "custID" : "10002" }
{ "custID" : "10001" }
$project将带有请求字段的文档传递到管道的下一个阶段。 指定的字段可以是输入文档中的现有字段,也可以是新计算的字段。
示例:分组custID并对amount求和
> db.orders.aggregate({$group:{_id:"$custID",TotalAmount:{$sum: "$amount"}}});
{ "_id" : "10002", "TotalAmount" : 200 }
{ "_id" : "10001", "TotalAmount" : 1050 }
- 使用
$获取变量的值 $group按指定的标识符表达式对输入文档进行分组$sum计算并返回数值值的和。忽略非数字值- 使用了类似MySQL中的别名
TotalAmount
示例:过滤出status为A的文档,分组custID并对amount求和
>db.orders.aggregate({$match:{status:"A"}},{$group:{_id:"$custID",TotalAmount:{ $sum:"$amount"}}});
{ "_id" : "10002", "TotalAmount" : 200 }
{ "_id" : "10001", "TotalAmount" : 750 }
$match筛选文档,只将匹配指定条件的文档传递到下一个管道阶段。
示例:分组custID并对amount平均值
> db.orders.aggregate({$group:{_id:"$custID",AverageAmount:{$avg:"$amount"}}});
{ "_id" : "10002", "AverageAmount" : 200 }
{ "_id" : "10001", "AverageAmount" : 350 }
$avg返回数值的平均值。忽略非数值
2,Map-Reduce
MongoDB还提供了Map-Reduce来执行聚合操作。Map-Reduce中有两个阶段:
- 一个处理每个文档并输出一个或多个对象的map阶段
- 一个将map操作的输出合并在一起的reduce阶段。
自定义的JavaScript函数可用于执行映射和归约操作。 与聚合管道相比,Map-reduce的效率较低且更为复杂。
db.orders.insertMany([{custID:"10001",amount:500,status:"A"},{custID:"10001",amount:250,status:"A"},{custID:"10002",amount:200,status:"A"},{custID:"10001",amount: 300, status:"D"}]);
示例:用map-reduce功能实现“过滤出status为A的文档,分组custID并对amount求和”
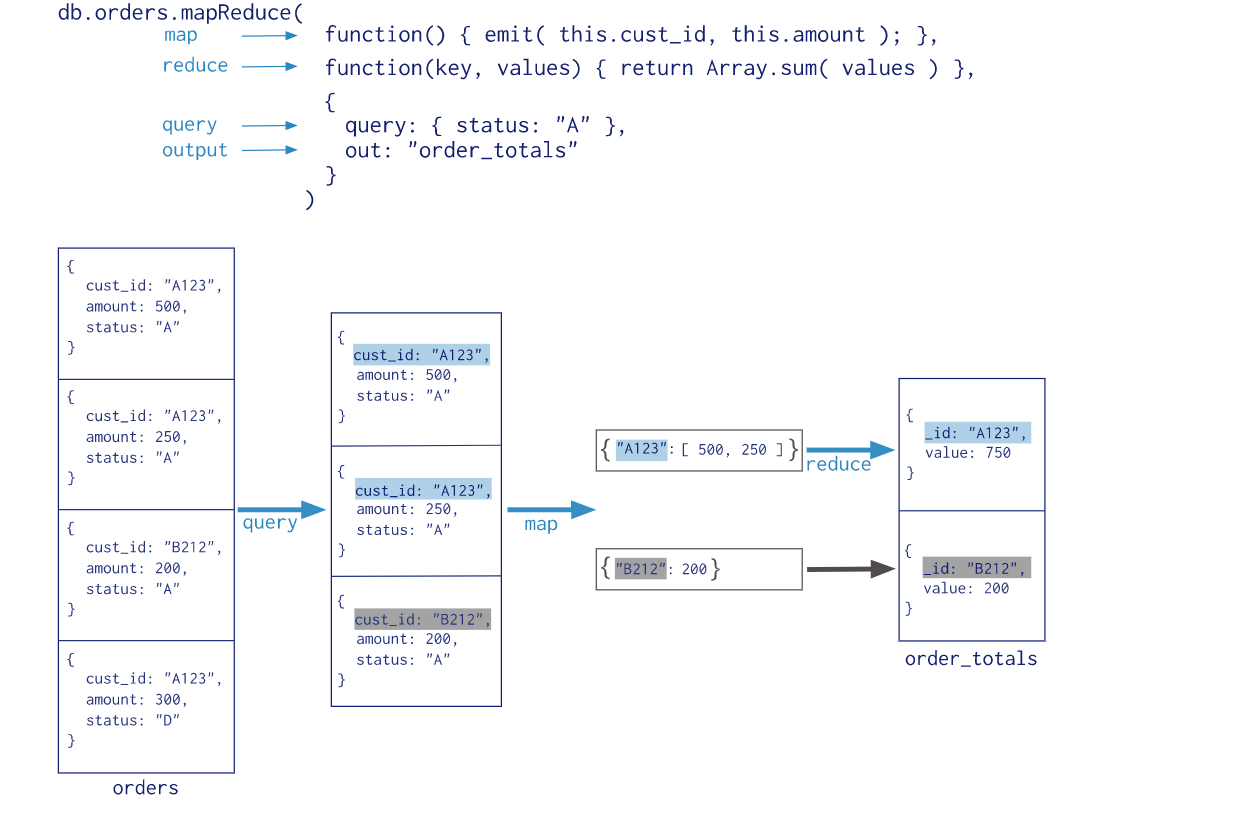
//Map function:
> var map = function(){emit (this.custID, this.amount);}
//Reduce function:
> var reduce = function(key, values){ return Array.sum(values);}
> db.orders.mapReduce(map, reduce,{out: "order_totals",query:{status:"A"}});
{
"result" : "order_totals",
"timeMillis" : 82,
"counts" : {
"input" : 3,
"emit" : 3,
"reduce" : 1,
"output" : 2
},
"ok" : 1
}
> db.order_totals.find()
{ "_id" : "10001", "value" : 750 }
{ "_id" : "10002", "value" : 200 }
3,Single-Purpose Aggregation Operations
MongoDB还提供了单一用途的聚合操作,例如db.collection.count()和db.collection.distinct()。 这些汇总操作汇总单个集合中的文档。 此功能提供对常见聚合过程的简单访问。
db.orders.insertMany([{custID:"10001",amount:500,status:"A"},{custID:"10001",amount:250,status:"A"},{custID:"10002",amount:200 ,status:"A"},{custID:"10001",amount: 300, status:"D"}]);
示例:消除取值重复的custID
> db.orders.distinct("custID")
[ "10001", "10002" ]
示例:统计文档数量
> db.orders.count()
4
五,SQL聚集术语与对应的MongoDB聚集操作
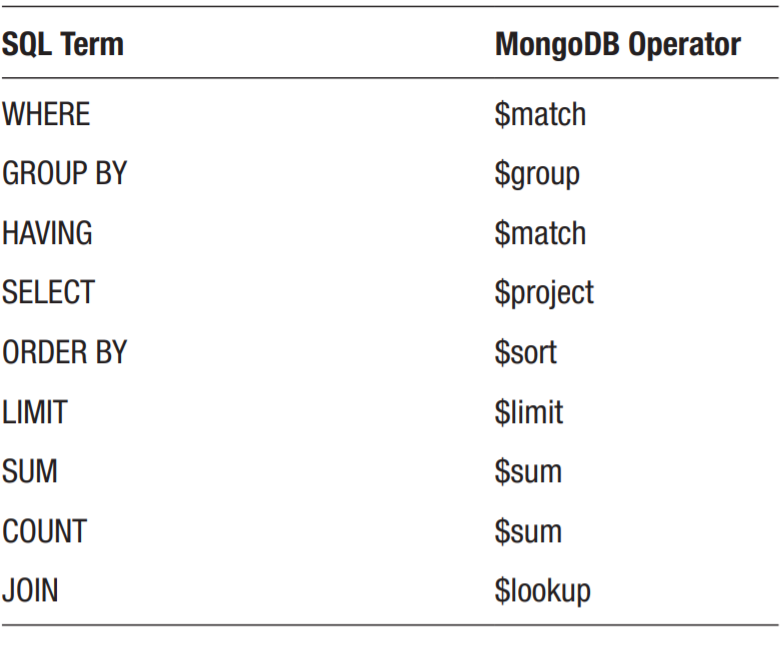
示例:查询orders集合的细节
> db.orders.find()
{ "_id" : ObjectId("5d636112eea2dccfdeafa522"), "custID" :
"10001", "amount" : 500, "status" : "A" }
{ "_id" : ObjectId("5d636112eea2dccfdeafa523"), "custID" :
"10001", "amount" : 250, "status" : "A" }
{ "_id" : ObjectId("5d636112eea2dccfdeafa524"), "custID" :
"10002", "amount" : 200, "status" : "A" }
{ "_id" : ObjectId("5d636112eea2dccfdeafa525"), "custID" :
"10001", "amount" : 300, "status" : "D" }
与任何RDBMS中的orders表相同,从表中获取记录计数的SQL如下:
SELECT COUNT(*) AS count FROM orders
获取集合中的文档总数:
> db.orders.aggregate( [ { $group: { _id: null, count: {$sum: 1 } } } ] )
{ "_id" : null, "count" : 4 }
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98131.html

