
目标:爬取博客园首页的文章标题和URL
1,打开博客园https://www.cnblogs.com/,“检查”网页元素,定位到博客文章位置:
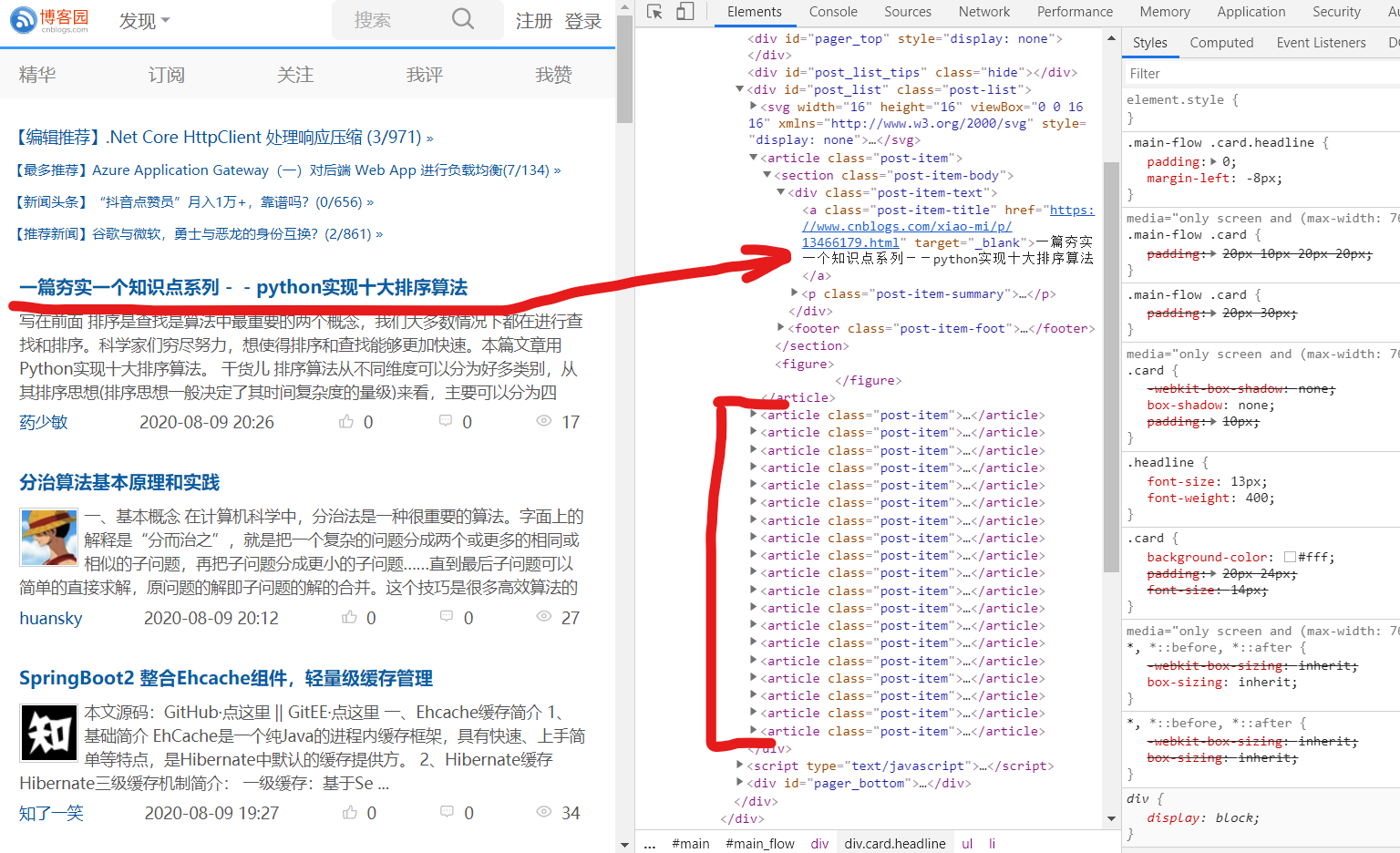
2,文章标题与URL都在class值为”post-item-title”的a标签中,可以用正则表达式过滤:
from urllib3 import *
from re import *
http = PoolManager() #使用连接池,加快响应速度。
disable_warnings() #禁用urllib3的https安全警告
def download(url):
result = http.request('GET', url)
htmlStr = result.data.decode('utf-8')
return htmlStr
def analyse(htmlStr):
aList = findall('<a[^>]*post-item-title[^>]*>[^<]*</a>', htmlStr) #正则过滤指定的<a>标签
result = []
for a in aList:
g = search('href[\s]*=[\s]*[\'"]([^>\'""]*)[\'"]', a) #从标签中获取URL
if g != None:
url = g.group(1)
index1 = a.find(">")
index2 = a.rfind("<")
title = a[index1 + 1:index2] #URL裁剪
d = {}
d['url'] = url
d['title'] = title
result.append(d)
return result
def crawler(url):
html = download(url)
blogList = analyse(html)
for blog in blogList:
print("title:", blog["title"])
print("url:", blog["url"])
crawler('https://www.cnblogs.com')
- 网页请求:urllib3库
- 页面解析:正则表达式
3,运行:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98162.html

