
前言
教你如何使用Sharding-JDBC实现对数据库的分库分表。
一、概念
分库分表
分库分表是当数据量大到一定程度时,对数据库、表进行一个合理拆分。以MySQL为例:单表的数据量建议最大不要超过千万级,索引树不要超过3层。否则就需对表进行水平拆分。
由于高并发下单库的性能受限以及服务器的性能等方面原因,为了更好的提供服务,也需要将数据进行分片存储。也就是分库。在Sharding-JDBC中,分库被称为数据分片。
常见的分库分表有两种方式
- proxy代理方式:mycat、Sharding-Proxy等,代理方式主要逻辑是,在代理客户端做分库分表规则配置,应用连接代理客户端,代理客户端连接mysql,将应用的sql请求拦截重组后发到mysql执行。并返回给应用
- jdbc增强方式:Sharding-JDBC,jdbc增强方式主要逻辑是在应用端配置分库分表规则,并根据配置规则拦截sql请求并重组发到mysql
水平拆分
将数据进行水平拆分,举例:一张order单表存有1000万数据,此时不管对这张表进行查询、插入、更新操作都会很慢。但是当我将这张order表根据规则(某个字段名)拆分出10张order{0…9}表出来,每张order表存100万数据。这样查询、插入、更新就相对会快很多。这就是水平拆分
垂直拆分
按照业务拆分的方式称为垂直分片,又称纵向拆分,核心理念是专库专用、专表专用。垂直拆分可以缓解数据量和访问量带来的问题,但是无法根治
二、使用步骤
1.准备
- 准备一个springboot+mybatisplus+mysql整合好的项目(正常增删改查)
- 新建两个库:yxj、yxj_1
- 每个库中建三张t_website_0、1、2表


2.依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<!-- 可以换成其他数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
</dependency>
3.配置
配置是整个Sharding-JDBC的核心,Sharding-JDBC需要通过配置规则来实现对数据的拆分。Sharding-JDBC提供了4种配置方式,用于不同的使用场景。

这里主要介绍spring boot方式的配置:
spring:
shardingsphere:
datasource:
names: yxj0,yxj1 #数据源名称,多数据源以逗号分隔
yxj0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://127.0.0.1:3306/yxj
yxj1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://127.0.0.1:3306/yxj_1
sharding:
default-database-strategy: #默认分库策略
inline:
sharding-column: id #分库列名,根据此数据列进行规则分库
algorithm-expression: yxj$->{id % 2} #分库规则,一般n个库就对n取余
tables: #分表策略
t_website:
#由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
actual-data-nodes: yxj$->{0..1}.t_website_$->{0..2}
table-strategy:
inline:
sharding-column: id #分表列名,根据此列按规则分表
#分表规则,一般n个表就对n取余
algorithm-expression: t_website_$->{id % 3}
key-generator:
column: id #主键字段
type: SNOWFLAKE #主键生成策略,可选SNOWFLAKE/UUID
broadcast-tables: t_role #公共表,每个库都有。改变该表会将其他库的该表一起更新
props:
sql:
show: true #控制台日志展示
4. 验证
使用postman对t_website表插入N条数据,在执行插入数据库之前,Sharding-JDBC会将其拦截下来,根据配置的规则计算,该条插入数据具体落的哪个库的哪个表。
比如上面的例子:建了两个库且规则是对2取余的情况下,库分片列id尾数是奇数则会存yxj_1库

偶数则会存yxj库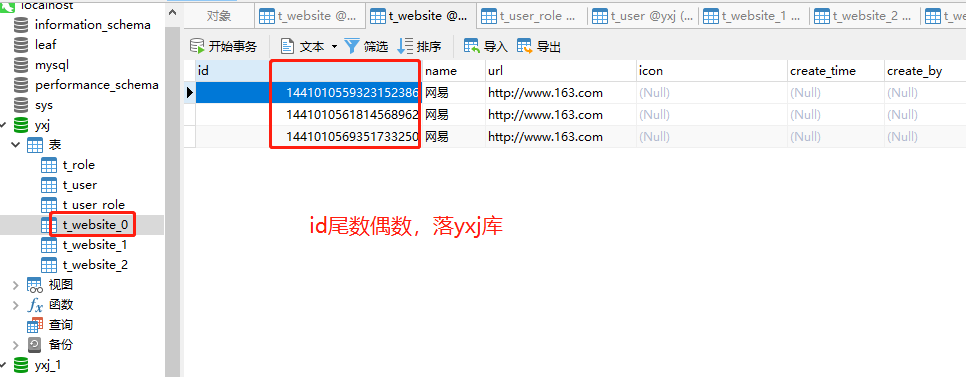
确定了哪个库后然后继续根据表分片规则判断具体存进哪个表里
总结
使用Sharding-JDBC实现分库分表其实很简单,主要搞清楚规则配置就可以使用。具体的配置规则可以参考官方文档
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/99043.html

