
目录
数据类型
基本数据类型
正如我们所熟知的那样,java分为八大基本数据类型,分别是:
-
整数类型:byte(1) short(2) int(4) long(8)
-
浮点类型:float(4) double(8)
-
字符类型:char
-
布尔类型:boolean(true|false)
何谓字节
-
字节:即
byte,用来计量存储容量的一种计量单位。 -
字节的单位是
bit -
一个字节等于8位
1byte = 8bit
基本数据类型占多少字节
char占用的是2个字节 16位,所以一个char类型的可以存储一个汉字。
整型
-
byte:1字节 8位 -128~127
-
short :2字节 16位
-
int :4字节 32位
-
long:8字节 64位
浮点型
-
float:4个字节 32 位
-
double :8个字节 64位
char类型
- char:2个字节。
boolean 类型
- boolean: (true or false)(并未指明是多少字节 1字节 1位 4字节)
【注意】:浮点型的默认类型是double,整数的默认类型是 int
引用类型
诸如String类,数组,容器,自定义类等都是引用类型,其分为强引用、弱引用、软引用、虚引用
强引用( Final Reference)
类似Object obj = new Object()这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
强引用具备以下三个特点:
-
强引用可以直接访问目标对象;
-
强引用锁指向的对象在任何时候都不会被系统回收。JVM宁愿抛出OOM异常也不回收强引用所指向的对象;
-
强应用可能导致内存泄露;
整个FinalReference类的部分源码如下:
package java.lang.ref;
/* Final references, used to implement finalization */
class FinalReference<T> extends Reference<T> {
public FinalReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}
从类定义中可以看出,只有一个构造函数,根据所给的对象的应用和应用队列构造一个强引用。
软引用(Soft Reference)
用来描述一些还有用但并非必须的对象。
对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
对于软引用关联着的对象,如果内存充足,则垃圾回收器不会回收该对象,如果内存不够了,就会回收这些对象的内存。
在 JDK 1.2 之后,提供了 SoftReference类来实现软引用。
软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
弱引用(Weak Reference)
用来描述非必须的对象。
但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发送之前。
当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。
一旦一个弱引用对象被垃圾回收器回收,便会加入到一个注册引用队列中。
虚引用(Phantom Reference)
虚引用也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。
一个持有虚引用的对象,和没有引用几乎是一样的,随时都有可能被垃圾回收器回收。
当试图通过虚引用的get()方法取得强引用时,总是会失败。
并且,虚引用必须和引用队列一起使用,它的作用在于跟踪垃圾回收过程。
strictfp
strictfp 即 strict float point (精确浮点)。它可应用于类、接口或方法。
strictfp修饰一个方法时,该方法中所有的float和double表达式都严格遵守FP-strict的限制,符合IEEE-754规范。
strictfp 修饰类或接口,该类中的所有代码,包括嵌套类型中的初始设定值和代码,都将严格地进行计算。严格约束意味着所有表达式的结果都必须是 IEEE 754算法对操作数预期的结果,以单精度和双精度格式表示。
容量转换
小容量的数据在计算时,jvm会将其自动转为大容量数据,而大容量数据要转为小容量的数据,需要我们手动去转型。
为何需要strictfp
大容量的数据类型可以转化为小容量的数据类型时,需要在前面加上强制类型转化符, 否则,java虚拟机会自动捕捉这种错误(这就涉及到error和exception的区别), 但在转换的过程中,容易造成数据的失真,因而,需要strictfp关键字。
Java虚拟机会自动将小容量的数据类型转化为大容量的数据类型,转型顺序为:short,byte,char-->int-->long-->float-->-->double。但short,byte,char之间不能转换。
分析double
public class Test1 {
public static void main(String[] args){
testWithoutStrictfp();
//steictfpTest();
}
/**
* 原子性:一个事务或多个事务要么同时提交而不受任何因素的干扰,要么就不提交。
* 有序性
* 可见性
*
* @auhtor 念兮
*
*/
private static void testWithoutStrictfp(){
//因为整形的数据类型,默认为int
int i=10;
int j=8;
System.out.println("i+j的数值为:"+(i+j));
//因为是double类型,Java虚拟机将其默认地转型
// 因而,数据会出现失真。
double ijd=(i+j)*1.2;
System.out.println(ijd);
//ijd的输出结果为:21.599999999999998
//因为是float浮点类型,Java虚拟机为发将其转型为float类类型
//因而,我们需要将其手动转型。
float ijf=(float)((i+j)*1.2);
System.out.println(ijf);
//ijf的输出结果为:21.6
//这样也是报错,因为浮点数默认的是double,而不是float
//因而需要转型,即在10.0后面加上F/f
float f1=10;
// 输出结果并不是10,而是10.0
System.out.println("f1"+f1);
float f2=10.0F;
System.out.println("f2:"+f2);
double strictfp_ijd=(i+j)*1.2;
System.out.println(strictfp_ijd);
float strictfp_ijf=(float)((i+j)*1.2);
System.out.println(strictfp_ijf);
System.out.println("f1/strictfp_ijf:"+f1/strictfp_ijf);
System.out.println("f2/strictfp_ijf:"+f2/strictfp_ijf);
short s1=10;
//这样就会报错,因为s1+1的结果类型不再是short,而是自动转型为int
// 这是需要将大类型的int转换为小类型的short
s1=(short)(s1+1);
System.out.println(s1);
// 但是 s1++就不会出现错误
System.out.println(s1++);
float f4=10000000.6F; //转型时,符合四舍五入的方法,满6才进1
float f5=10000000.5F;
long l4=(long)f4;
long l5=(long)f5;
System.out.println(l4);
System.out.println(l5);
}
}
由ijd的ijf输出的数据来看,在数据进行转型的时候,就出现了数据的不一致。
怎么才能保证不失真呢,我们就需要用到strictfp这个保留字。它是script float potion精准浮点,完全符合IEEE 754标准的。IEEE745规定了硬件的数据的准确性,保罗单精度浮点数,和双精度浮点数。
但strictfp只能修饰类、接口、方法,不能修饰局部变量和成员变量
分析long
long l1=10000000000L;
long l2=(long)1E10; //用科学计数法需要转型
double d1=l1+l2;
// 输出结果为:2.0E18 采用的科学计数法,因为是double类型的浮点数
/**
* “aEb”所表示的值是a × 10b E/e表示10,b表示指数
* 但我们国家一般要求科学计数法不是这样的,可以参见:
* GB3101-1993,GBT15835-2011,GBT8170-2008
* 而是a*10b;
*/
System.out.println(d1);
//float fd=d1/l1;这是会报错的,因为需要进行转型
float fd=(float)d1/l1;
System.out.println(fd);
如果我们对long修饰的变量赋值是100000000000000000000000,那么就会报错。因为l的长度是:-2^63-2^63-1,这远远超过了长度。
但即便我们写成这样:10000000000000000,没有超过长度,依然会报。因为,Java虚拟机的整形数据类型默认为int,而这确实long类型,当然会报错。
一般我们在末尾加上L/l,我们一般不用小写的l,因而这看起来其极像阿拉伯数字1。因而,我们一般写成为L;
分析byte
// byte 2^-8~2^8-1 即-128-127
byte byte1=23;
byte byte2=24;
byte byte3=(byte)(byte1+byte2+1000);
System.out.println("byte:"+byte3);
上述代码也会报错,因为byte1 + byte2时,java虚拟机将其的类型转化为int了。
如果,我们想要获取类型为byte的结果,就必须将其转型。但有一个重要的方法,它的输出结果为23,难道只输出了byte1吗?
答案是错误的,首先我们来了解byte这个基本数据类型,byte是字节类型的,它的取值范围是-128~127之间,占位是256位,也就是说,这是一个循环。
我们全部将其转化为二进制(利用windows自带的计算器):
- 23为10111
- 24为11000
对其进行二进制的加法可得:10000010111,而byte是八位的,因而只取00010111。
首位是符号位,0表示正,1表示负。
将其转化为十进制为:结果正好为23。
因为,所有的代码在内存中都是二进制,即0和1表示。
这是原码的加法,计算器组成原理的知识点
这也就是黑客帝国中的二进制代码的看点。
使用strictfp
如果想要精度更加准确,而且不会因为硬件的改变而失真, 我们可以用strictfp来修饰,如下代码所示:
private static strictfp void steictfpTest(){
int i=10; //因为整形的数据类型,默认为int
int j=8;
float f=10.0f;
double strictfp_ijd=(i+j)*1.2;
System.out.println(strictfp_ijd);
float strictfp_ijf=(float)((i+j)*1.2);
System.out.println(strictfp_ijf);
System.out.println(f/strictfp_ijf);
System.out.println(System.class);
}
输出结果如下图所示:
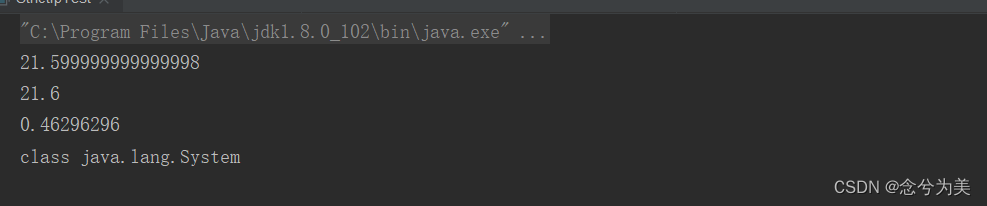
i++和++i的区别
i++
表示i先获得i1++的数值,然后i1在自行加1。
换句话说,i1把初始值赋给i后,i1再自行加1,如下代码所示:
public static void main(String[] args) {
int i, j = 20;
i = j++;
System.out.printf("i的数值:%d \n", i);
System.out.printf("j的数值:%d", j);
}
输出结果为:
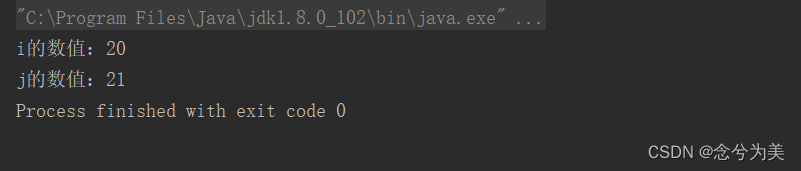
++i
这种方式表示,i先进行加1的计算,再把值赋给i,如下代码所示:
public static void main(String[] args) {
int i, j = 20;
i = ++j;
System.out.printf("i的数值:%d \n", i);
System.out.printf("j的数值:%d", j);
}
输出结果为:
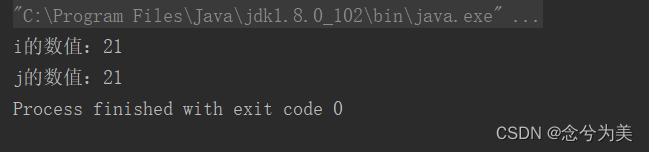
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/99302.html

