
Bucket agregations 分桶聚合
根据属性进行分桶,把具有某些相同属性的数据放到一起,相当于MySQl的group by。
语法:
GET product/_search
{
“aggs”: {
“<aggs_name>”: {
“<agg_type>”: {
“field”: “<field_name>”
}
}
}
}
查询统计不同标签的商品数量
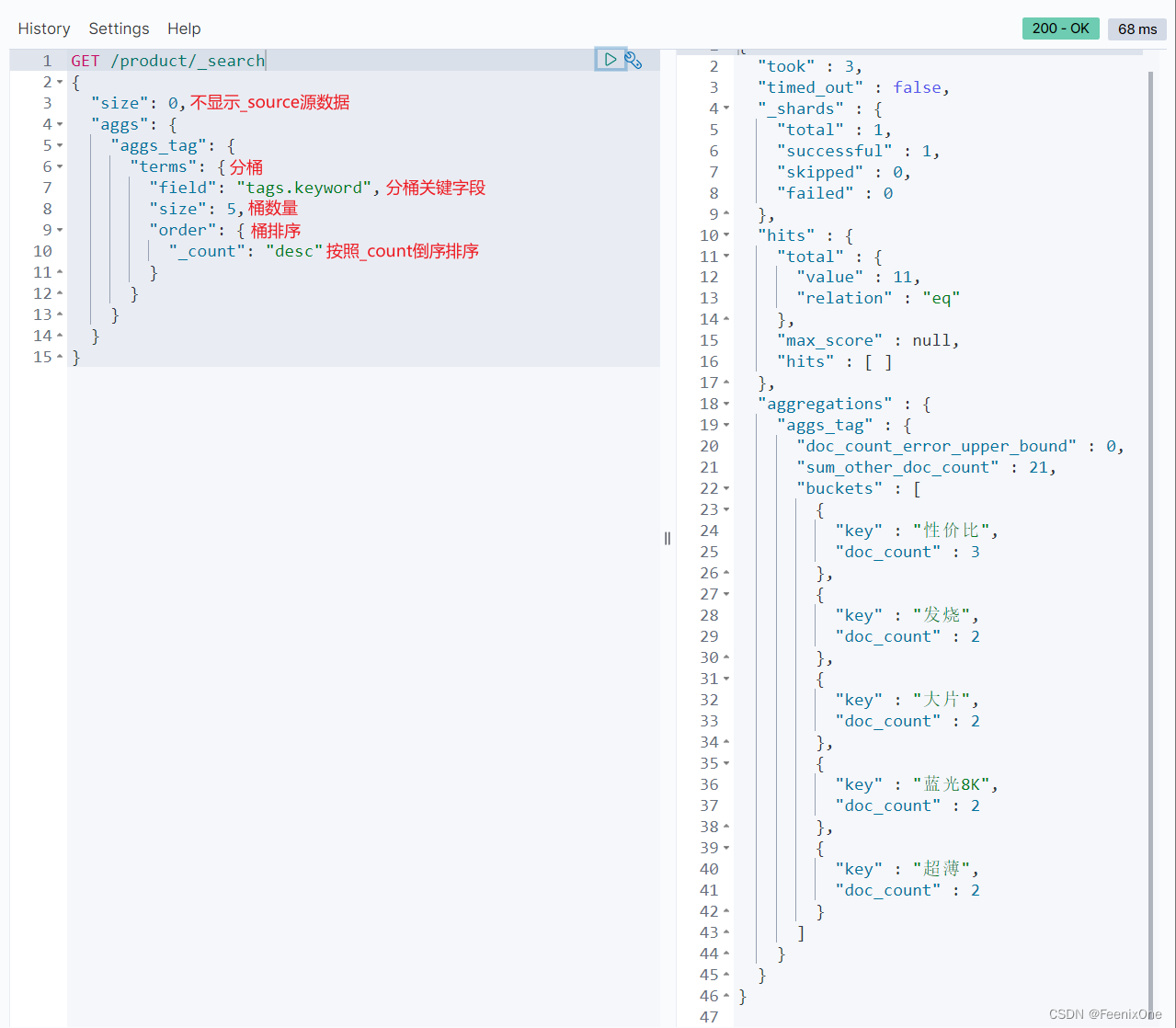
为什么是”field”: “tags.keyword”,而不是”field”: “tags”?
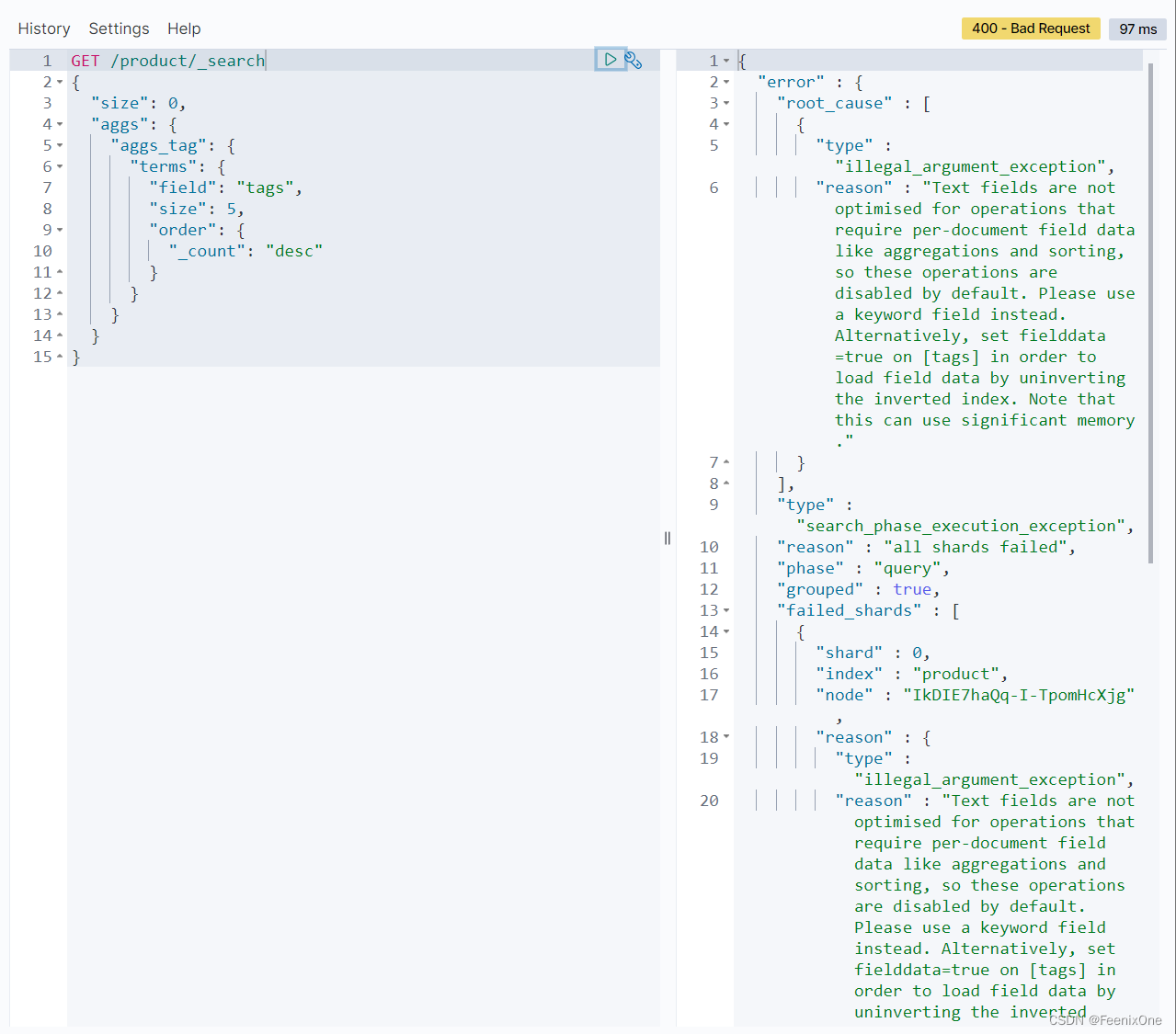
aggs底层使用的数据结构是正排索引doc_values,而tags的type是text,text在创建的时候是默认不创建正排索引,所以如果tags.keyword直接写成tags则会报错,得指定tags.keyword才可以使用正排索引。
“tags”: {
“type”: “text”,
“fields”: {
“keyword”: {
“type”: “keyword”,
“ignore_above”: 256
}
}
}
如果一定要对tags本身进行聚合分析怎么办呢,要将tags的fielddata设置为true:
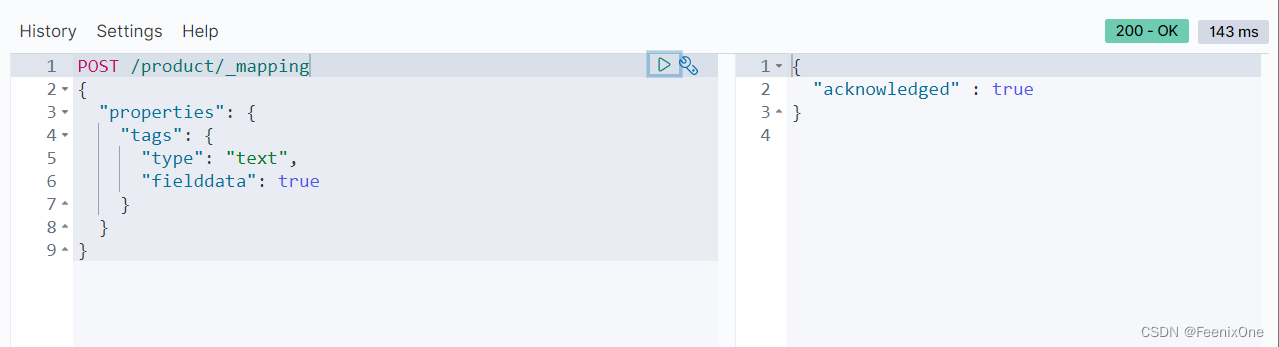
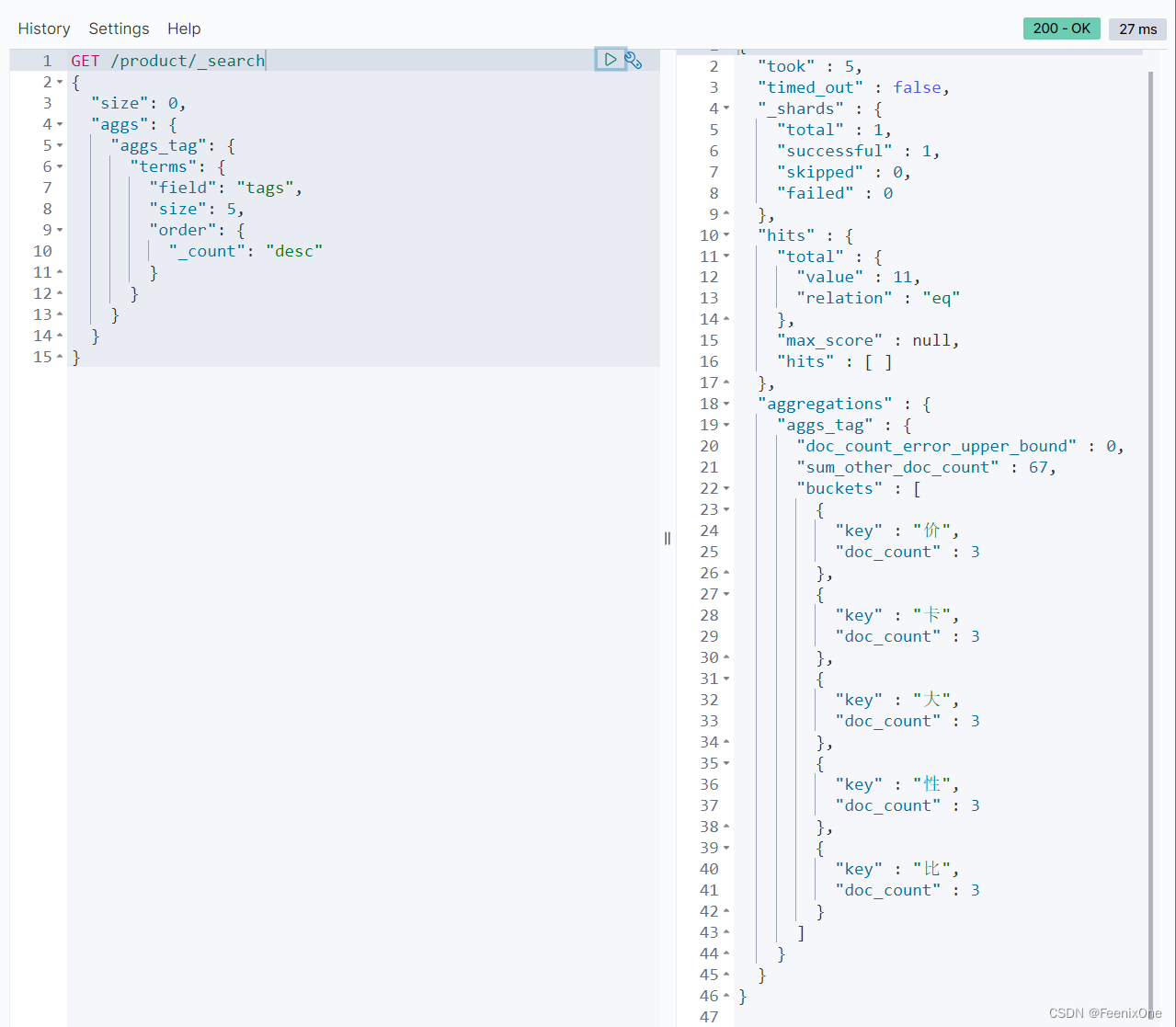
这个时候就可以直接使用”field”: “tags”:
Metrics agregations 指标聚合
根据一些特定的指标进行数据的聚合,比如avg、max、min、sum等。
查询最贵、最便宜、平均价格三个指标
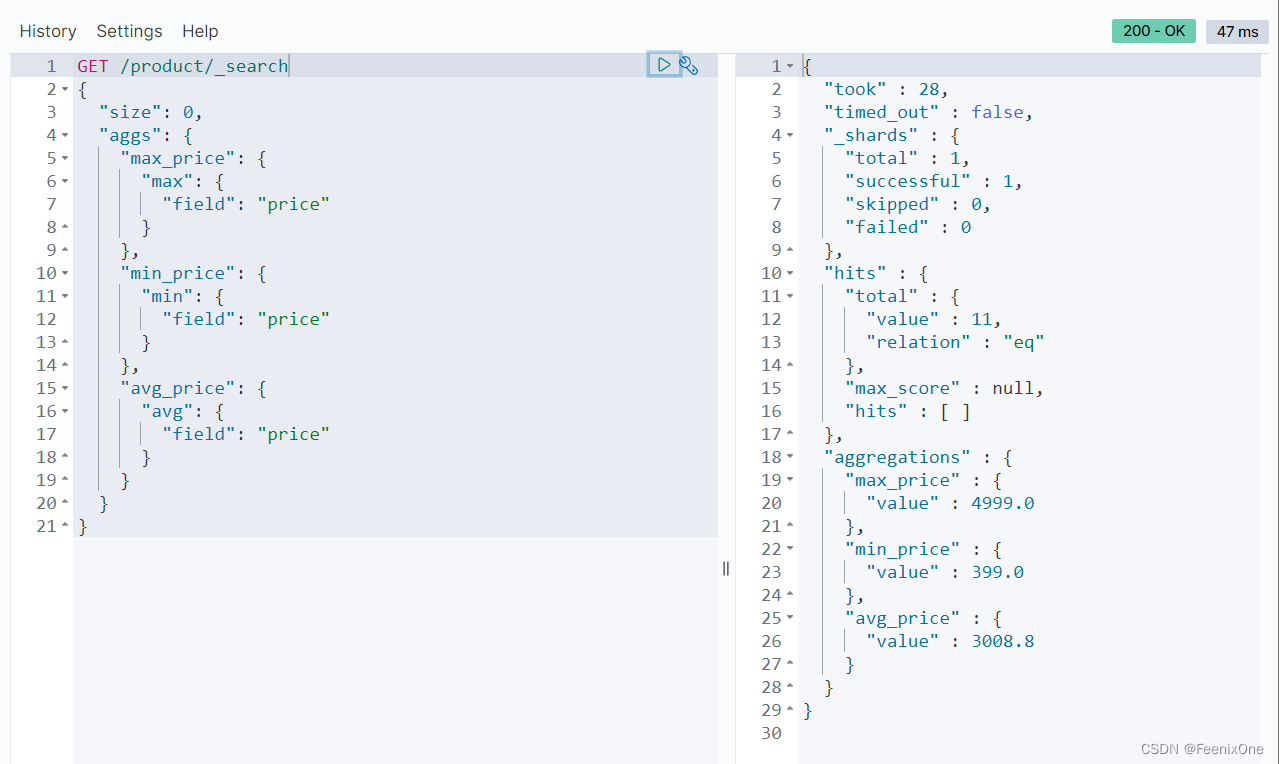
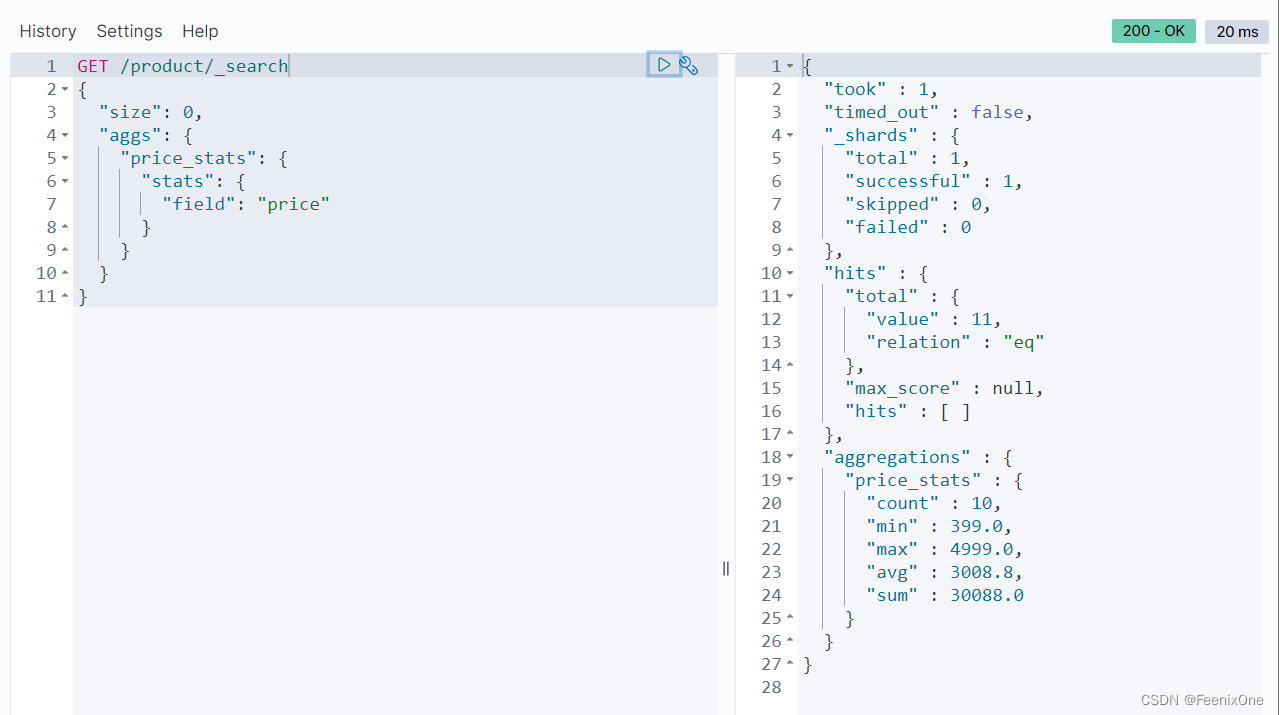
查询所有指标
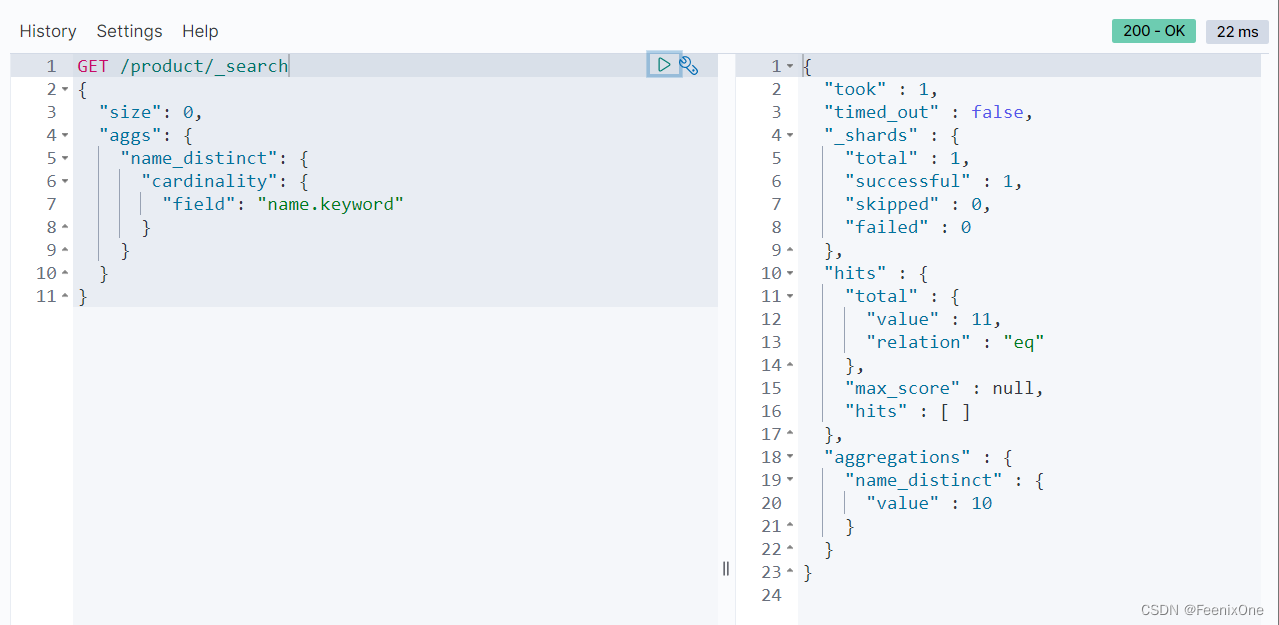
按照name去重的数量
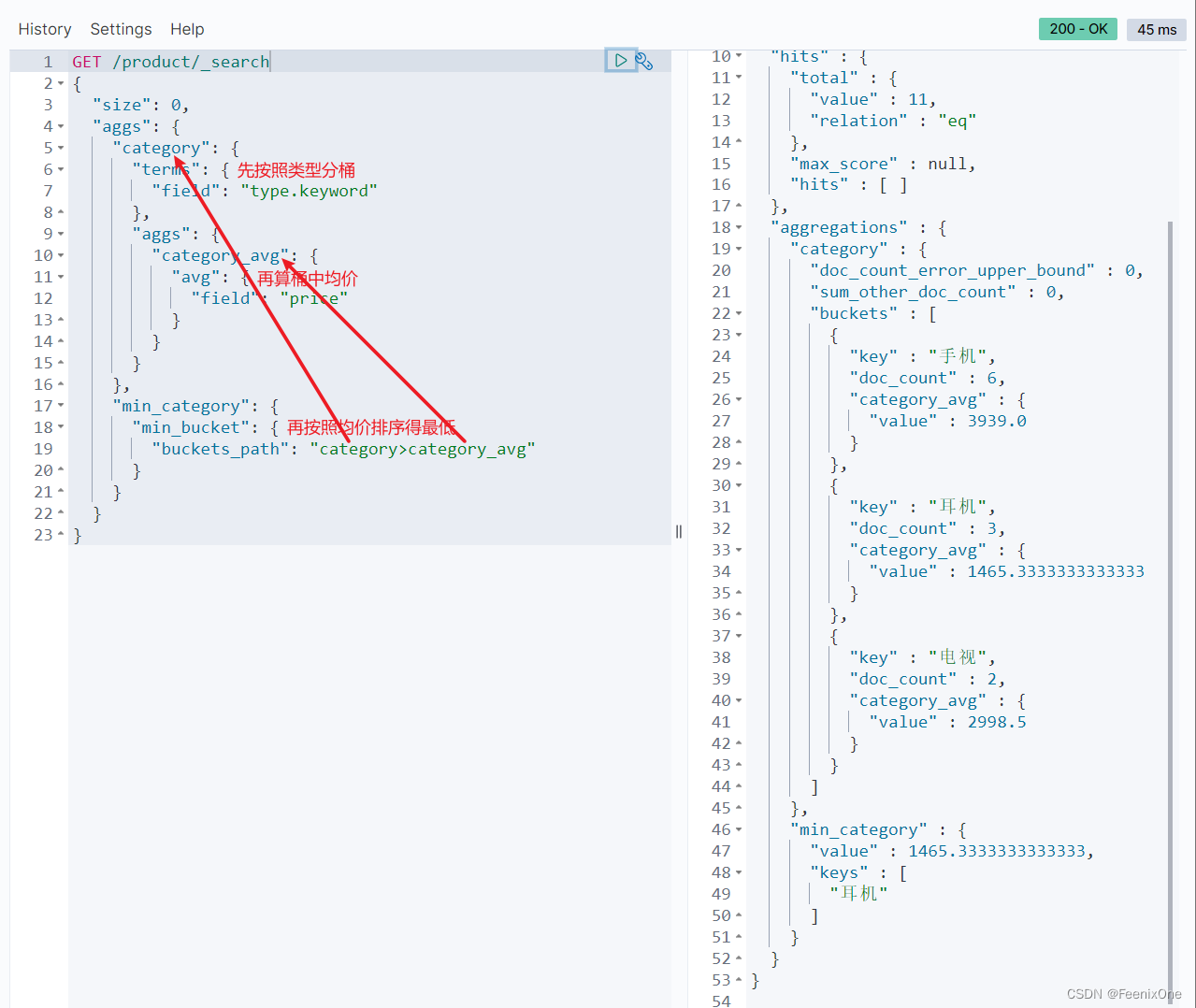
Pipeline agregations 管道聚合
对聚合的结果再进行聚合,比如统计平均价格最低的商品分类,就得先按分类聚合,再按平均价格聚合,再按价格的高低聚合。
统计平均价格最低的商品分类
统计不同类型的商品的不同级别的数量
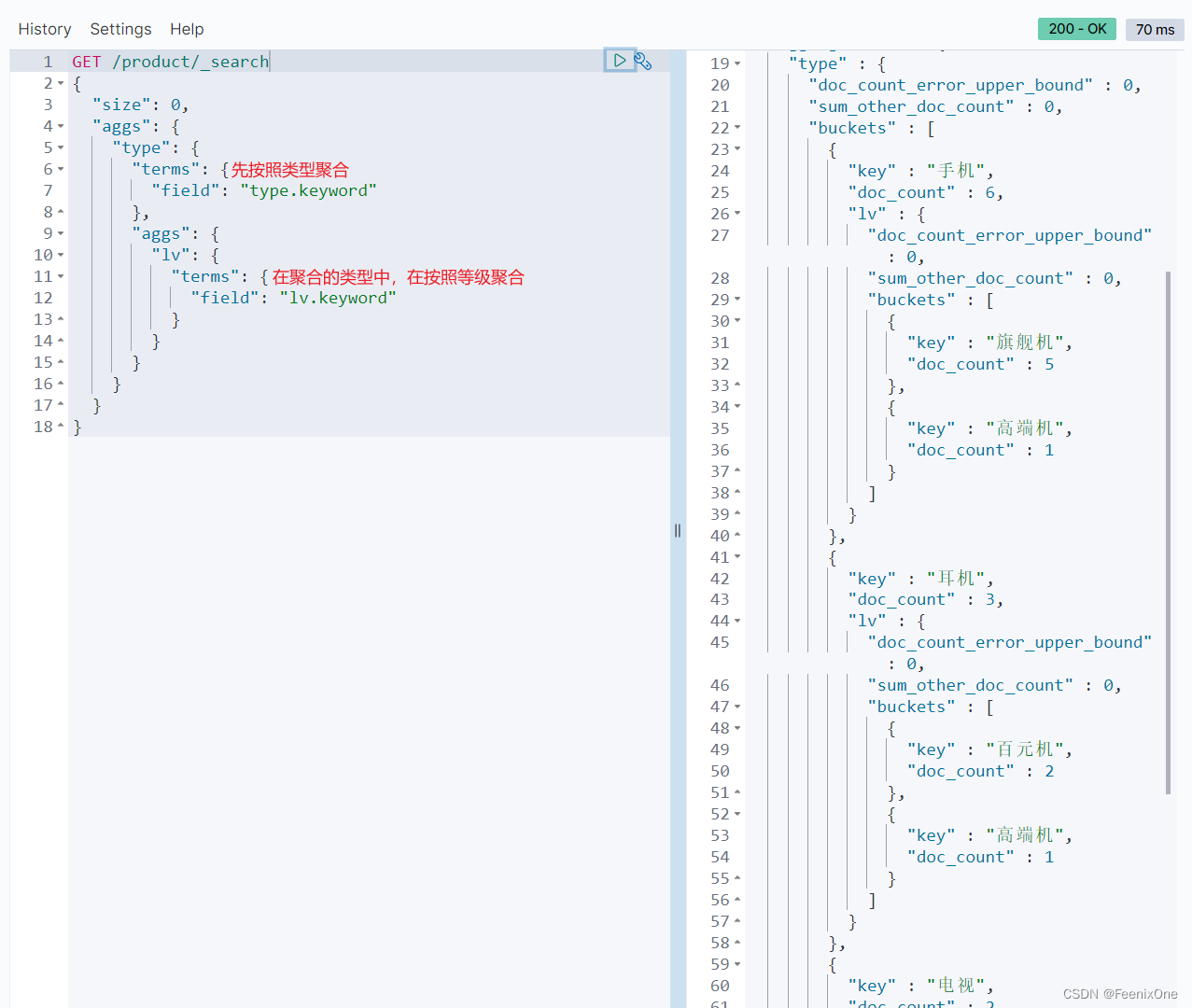
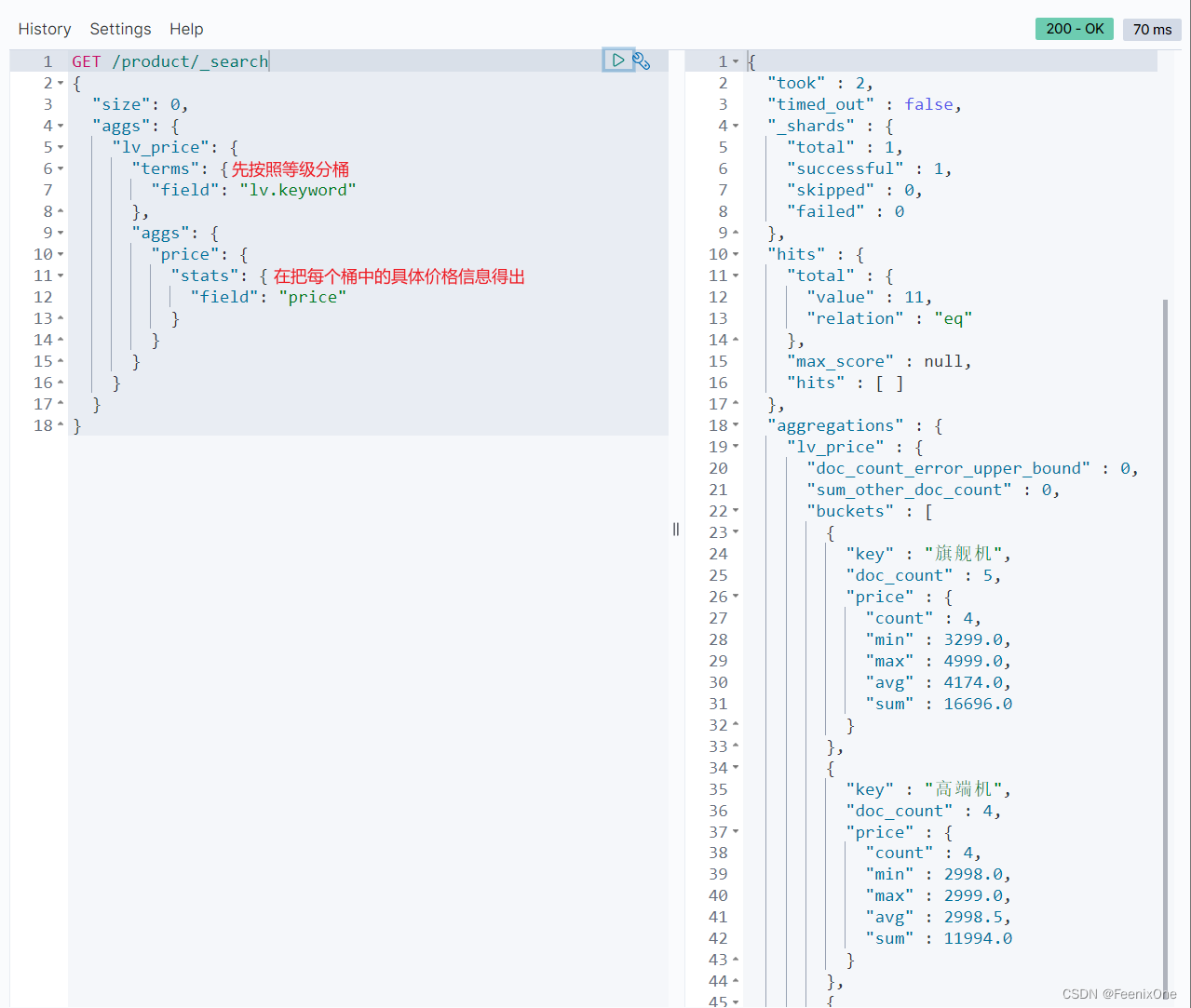
按照等级分桶,并输出每个桶的具体价格信息
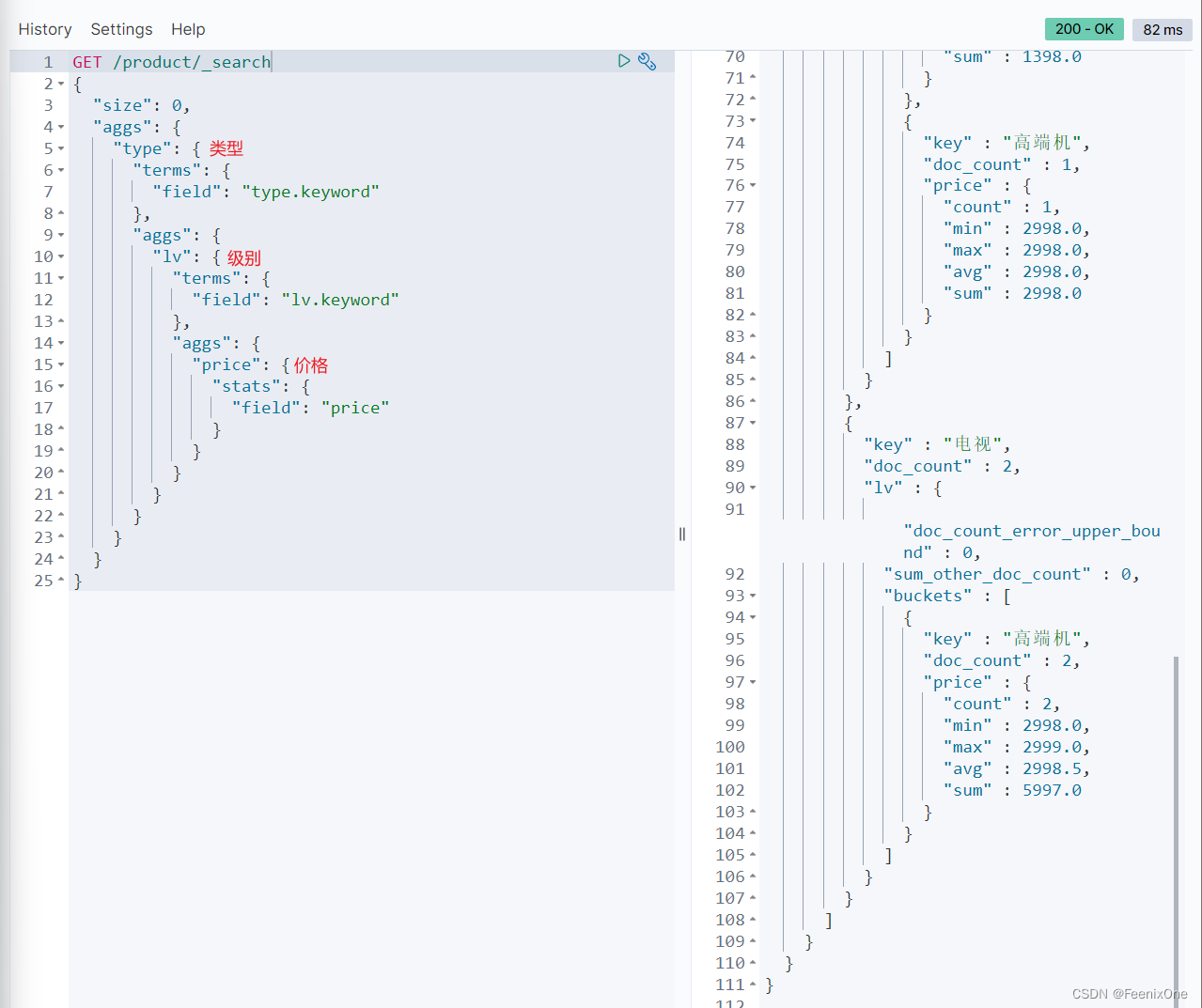
统计不同类型的商品、不同档次,各价格信息
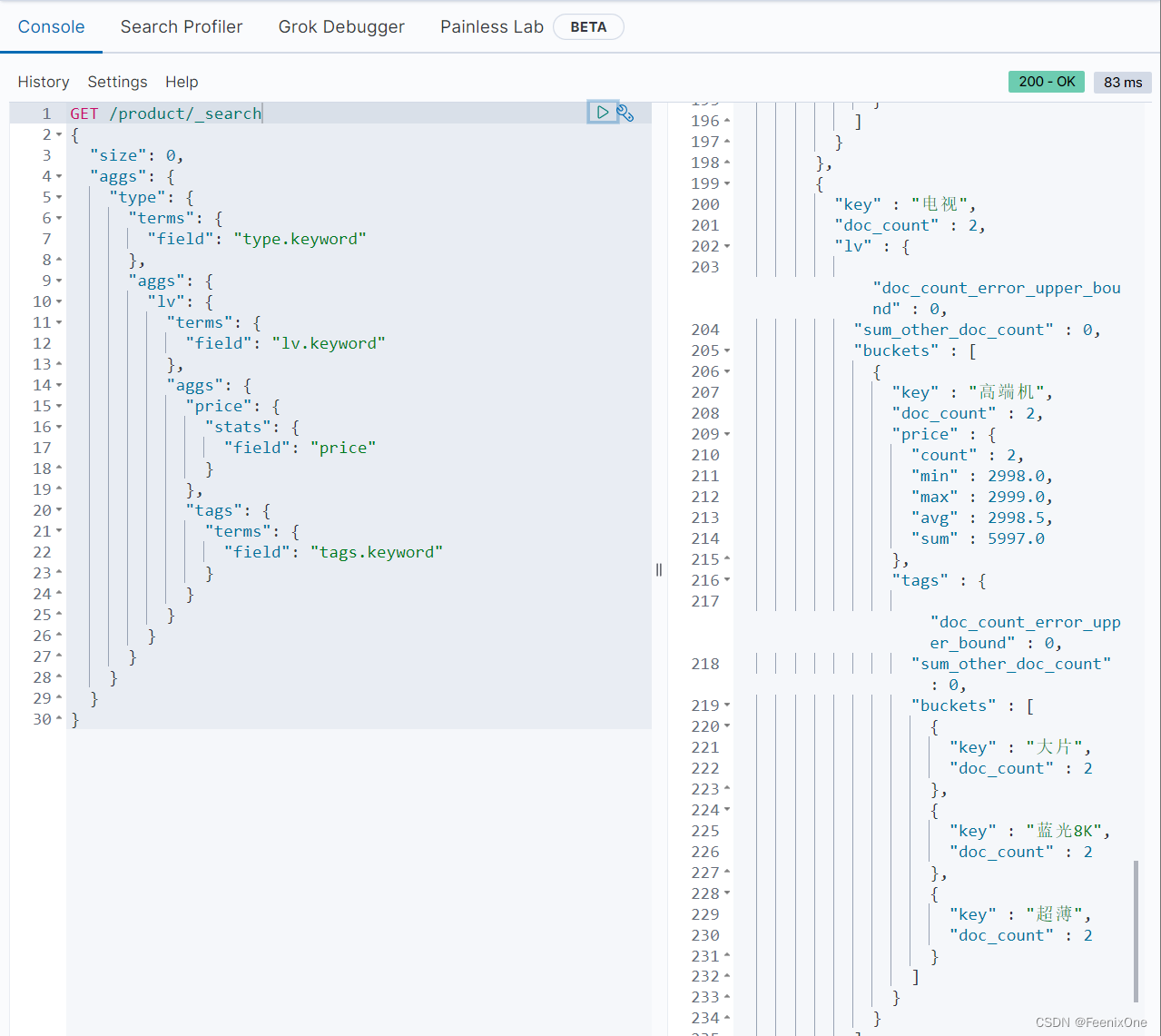
统计不同类型的商品、不同档次、各价格信息和标签信息
统计每个商品类型中,不同等级分类商品中,平均价格最低的等级
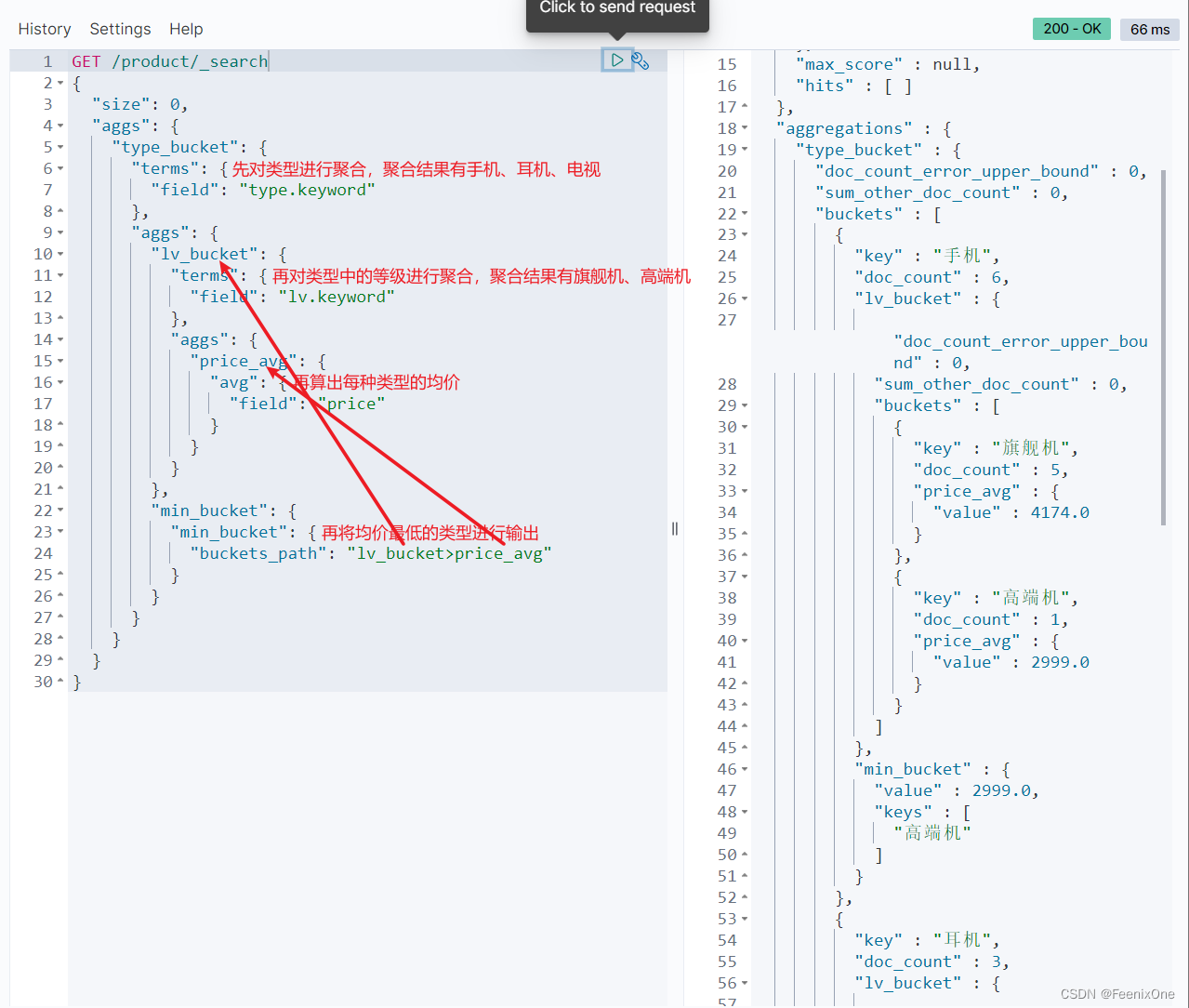
基于查询结果的聚合
管道聚合其实就是基于聚合结果的聚合,那么基于查询结果的聚合其实和管道聚合本质上一样的,先将需要查询的数据查询出来,再将查询的结果进行进一步的聚合运算。
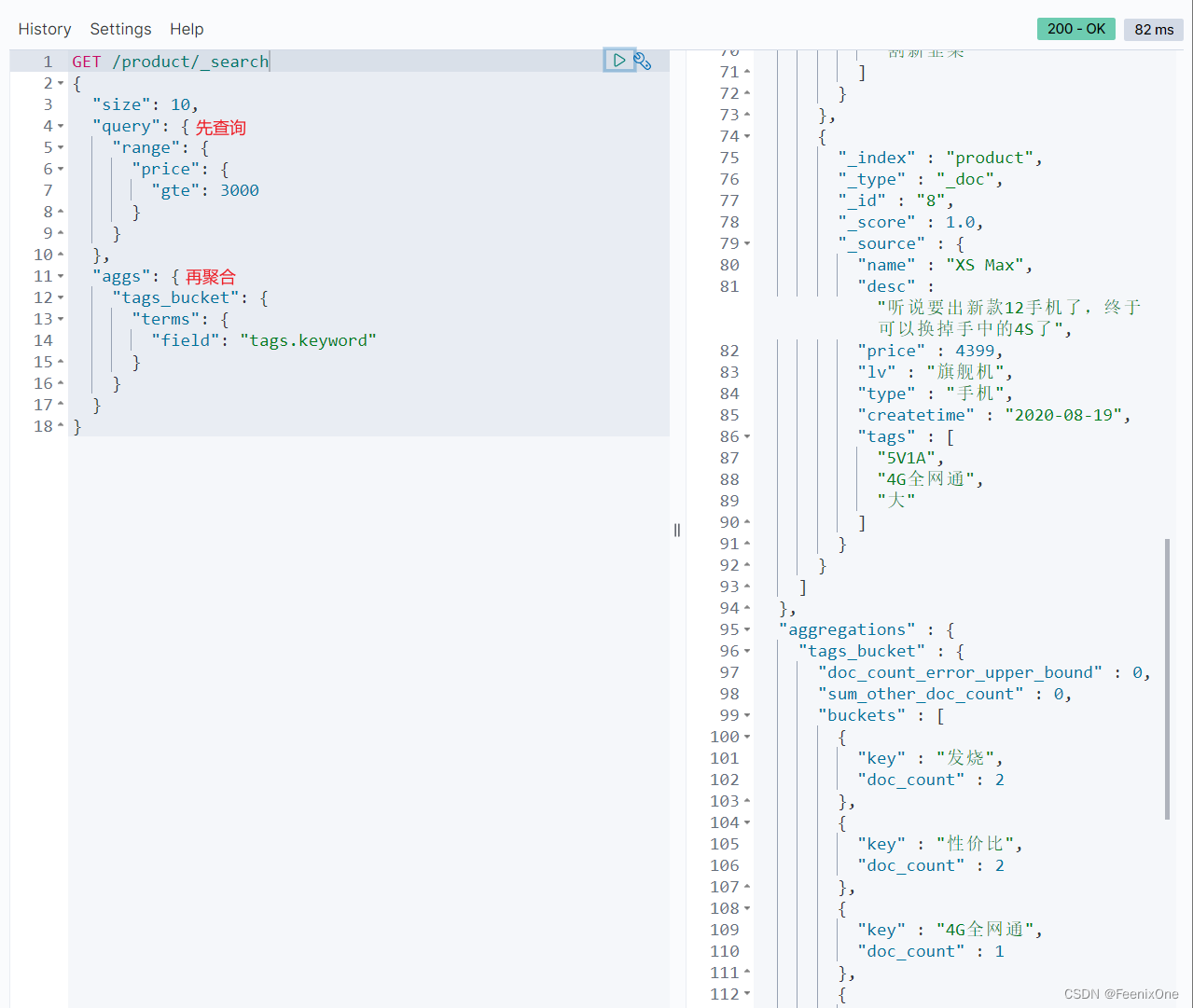
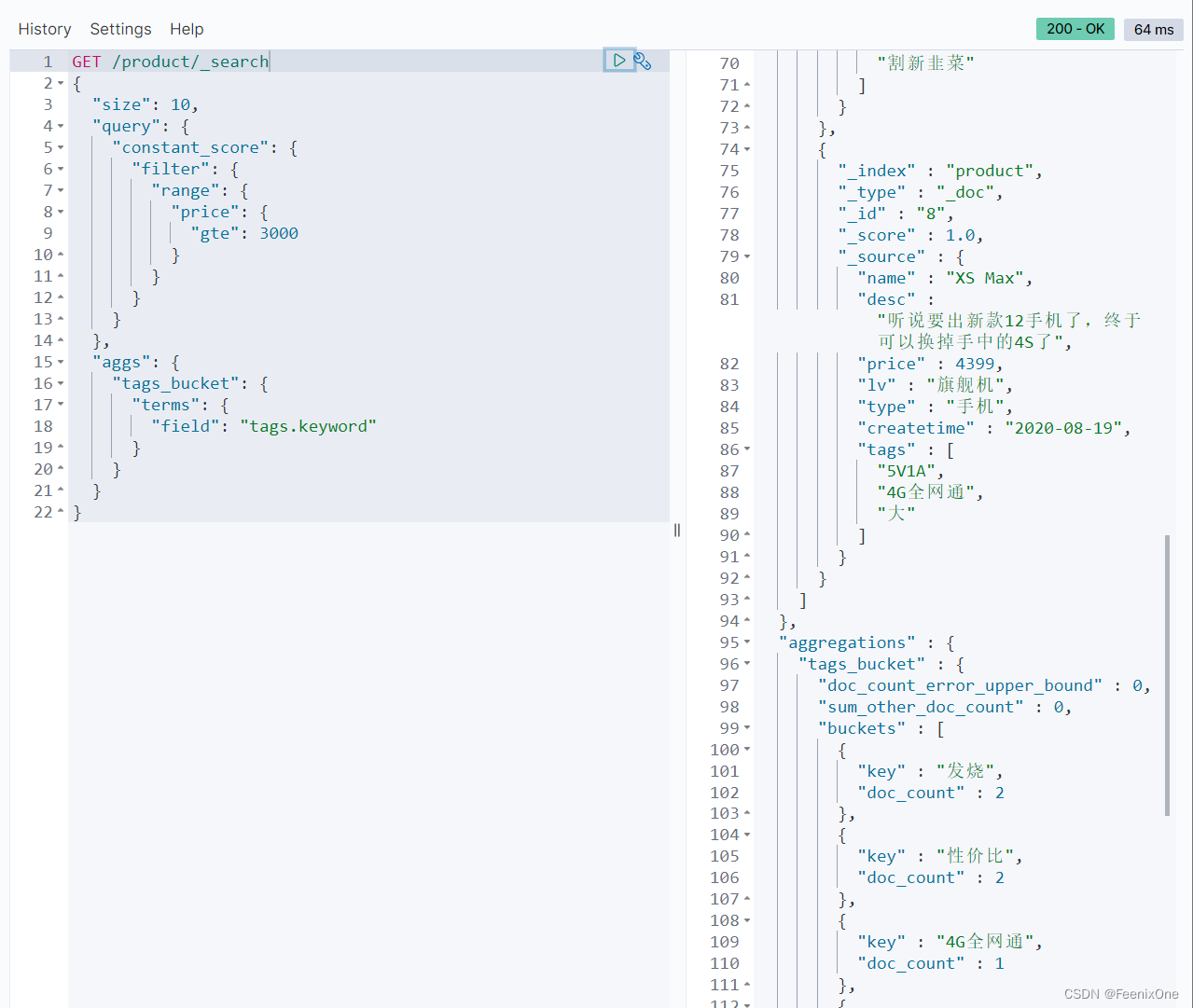
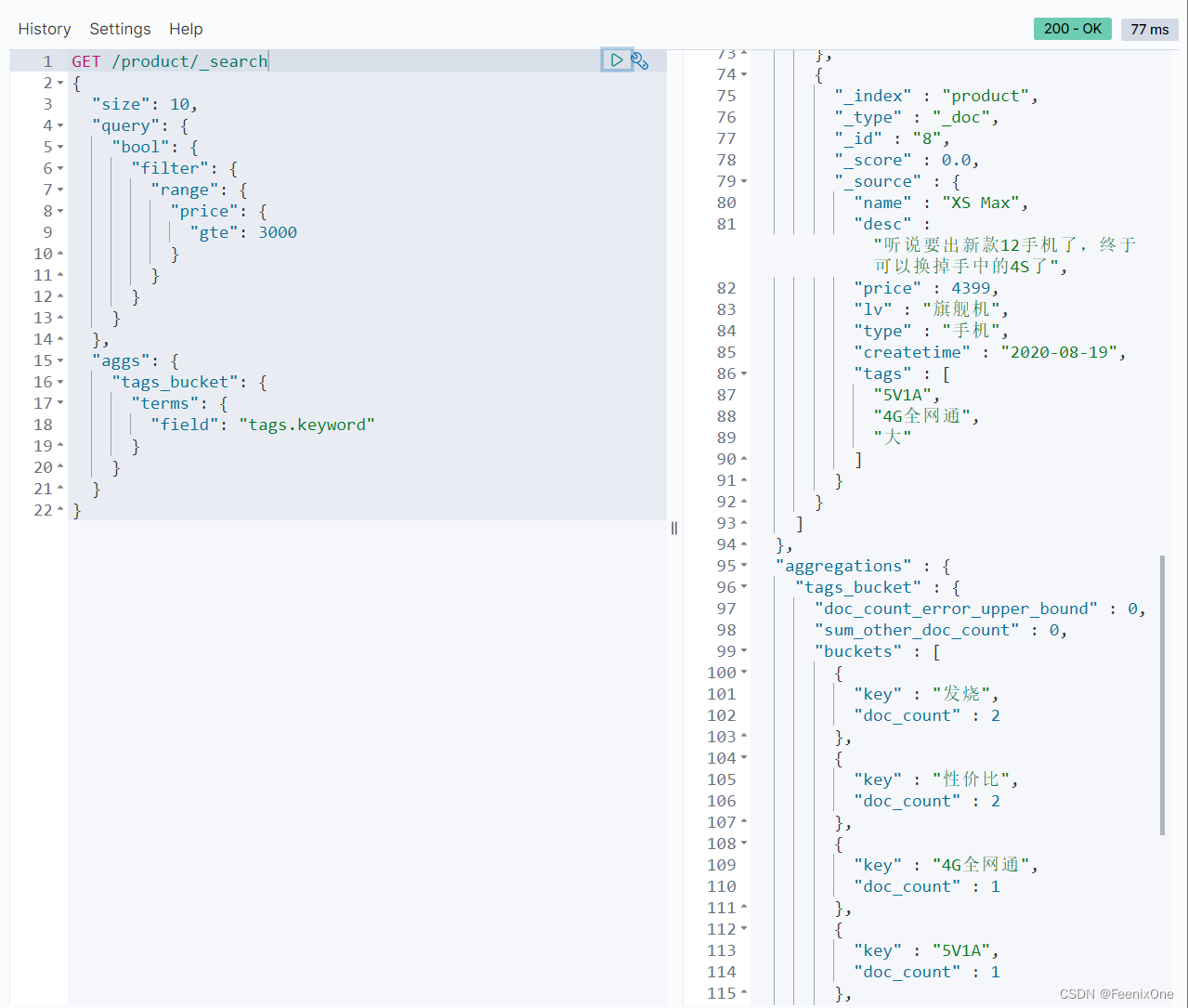
基于聚合的查询
绝不是直接将query写在aggs之后就行,即便这么写,也还是基于查询的聚合,本质上并不是基于聚合的查询。
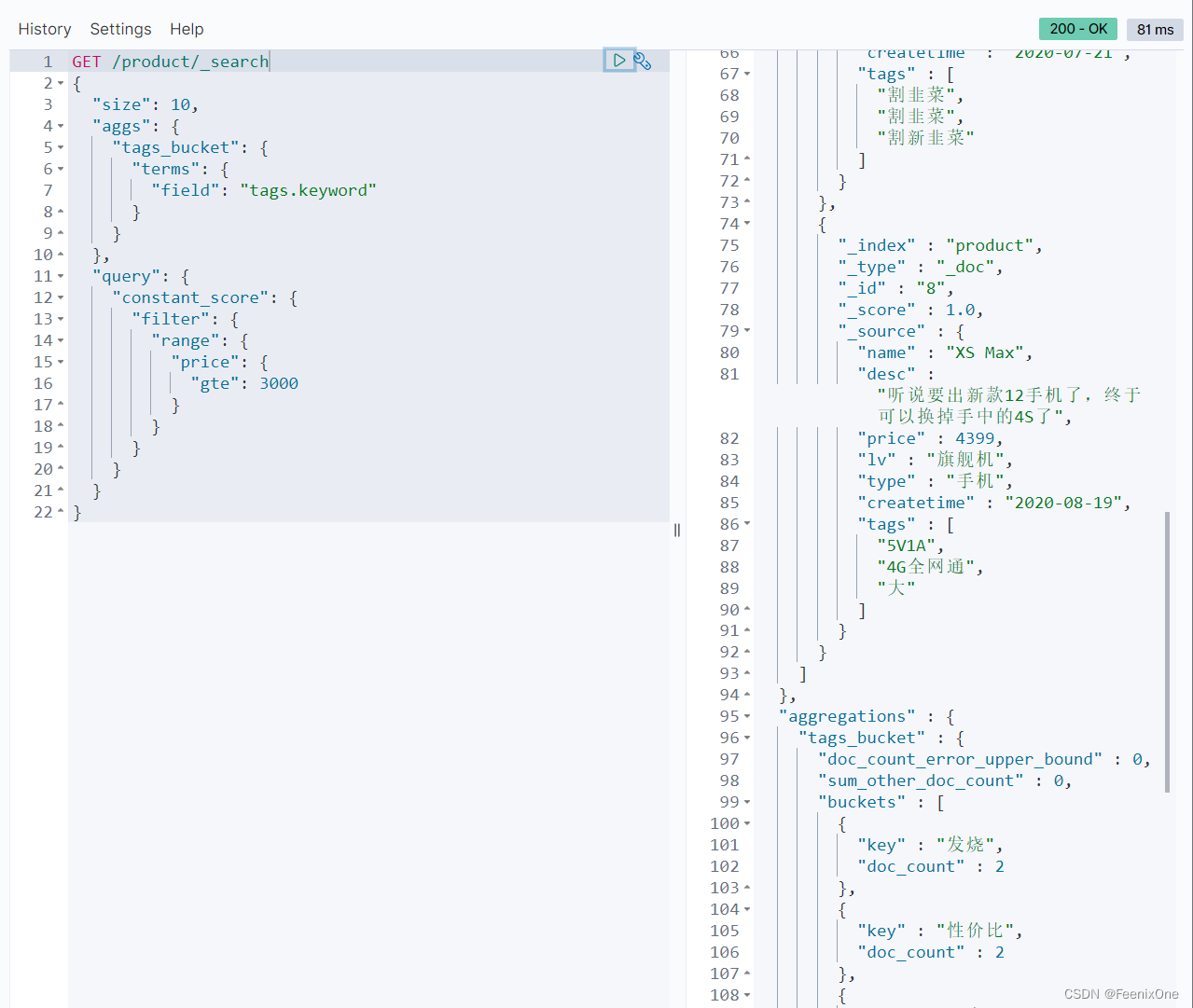
使用post_filter才是基于聚合后的结果进行查询。
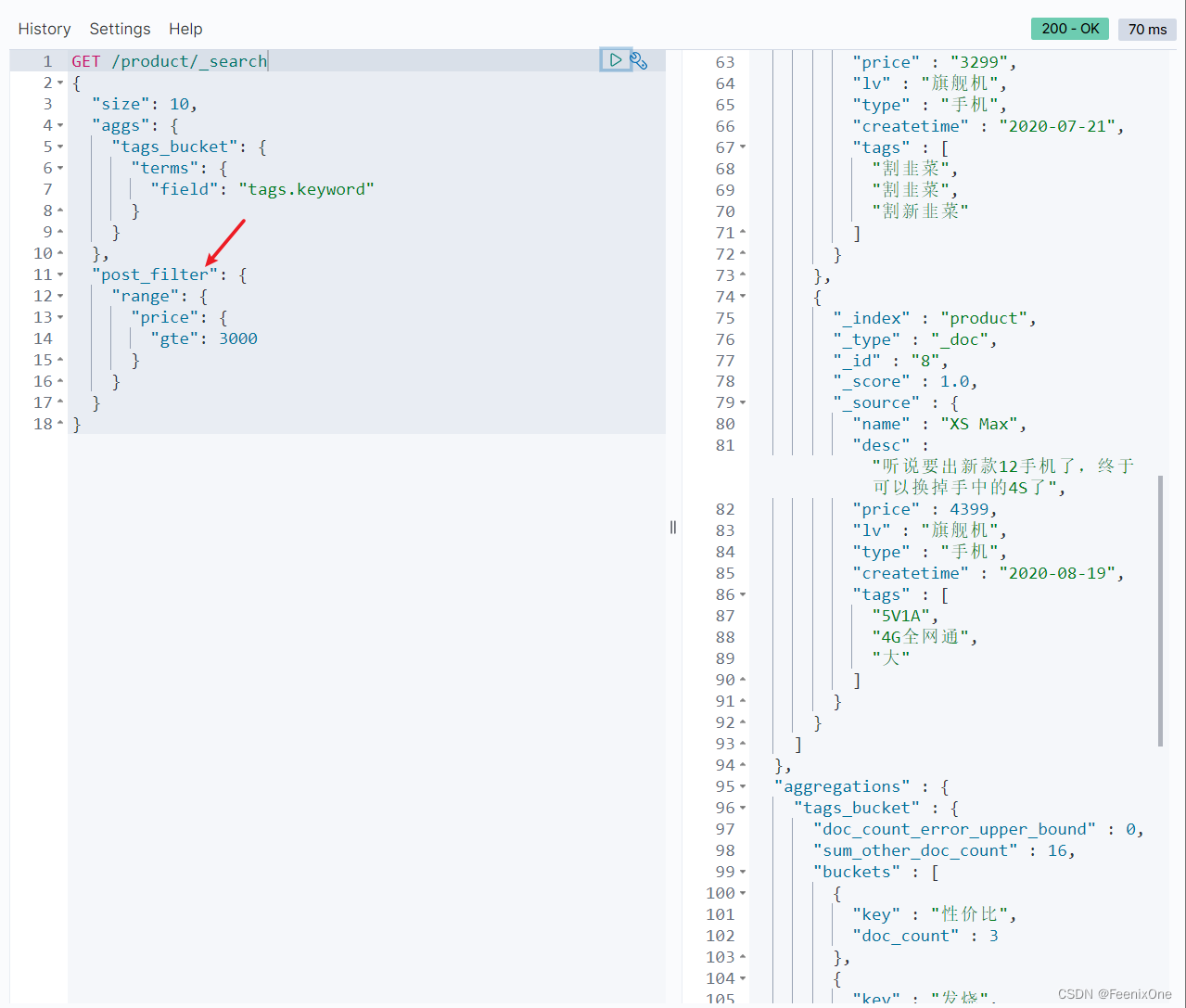
其实很多基于聚合的查询,本质上只是做一些简单的过滤,为了方便去看聚合的结果而已。
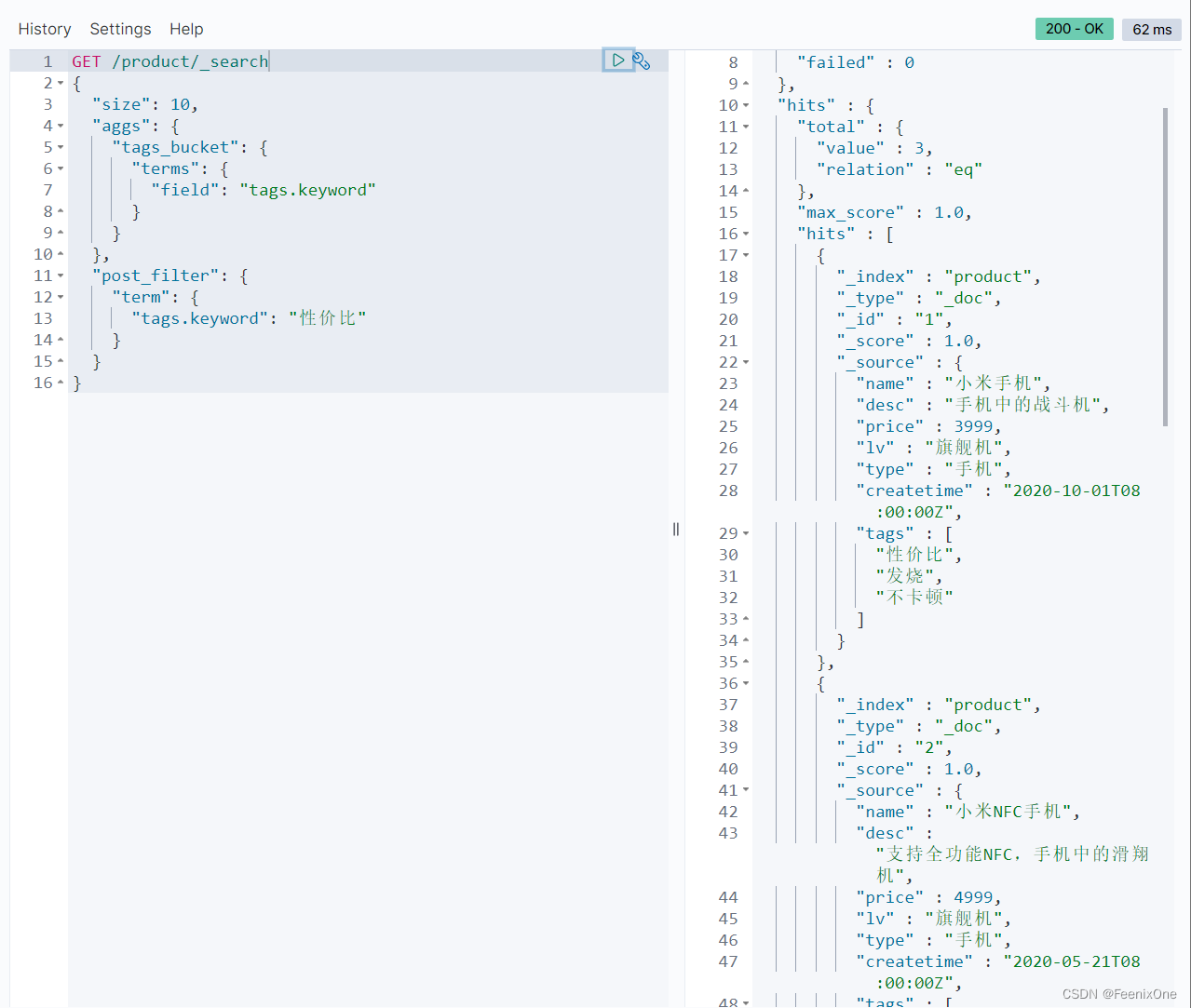
图形图像聚合函数
histogram 柱状图或直方图
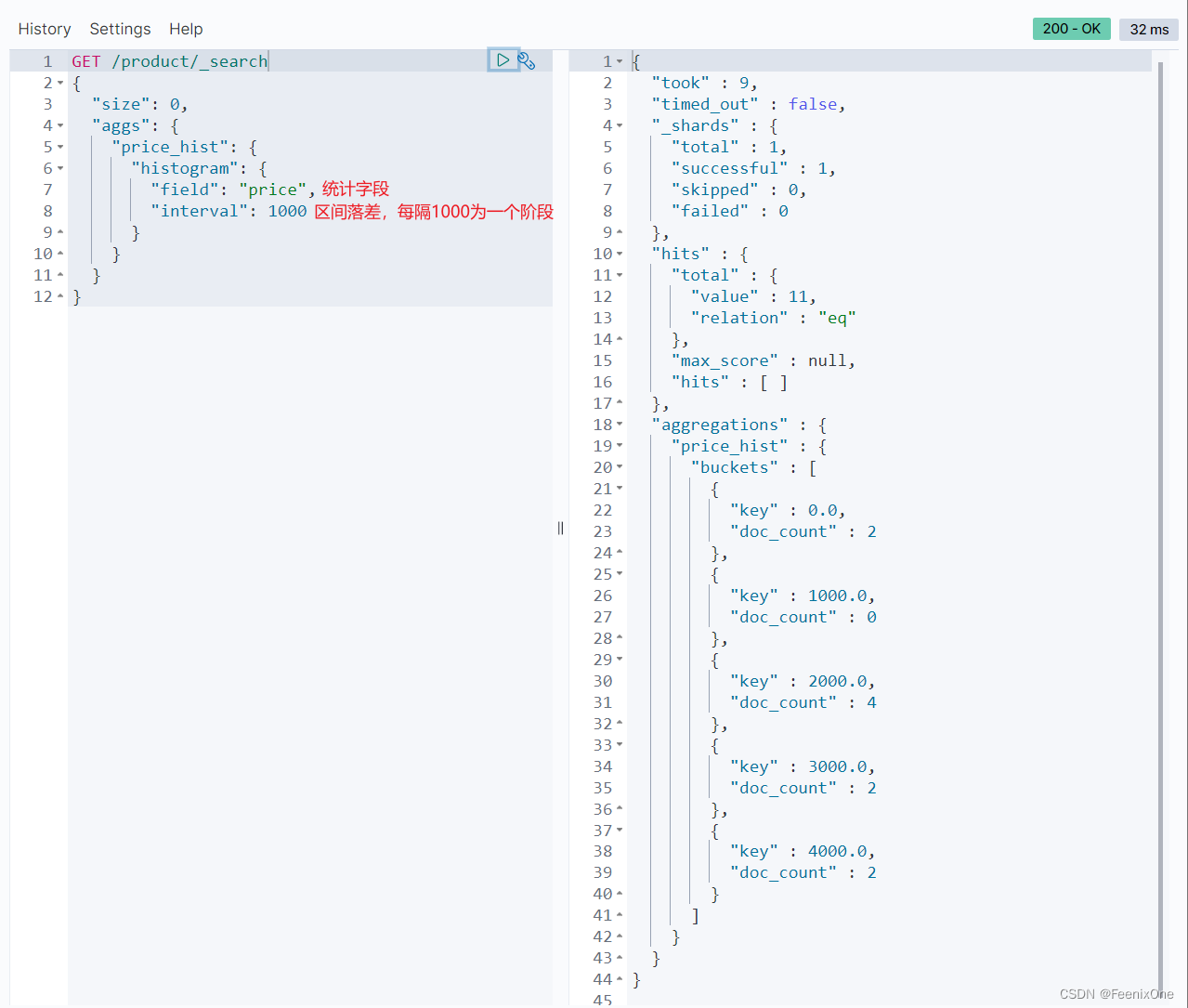
设置:”keyed”: true,可以将区间的落差值作为key使用
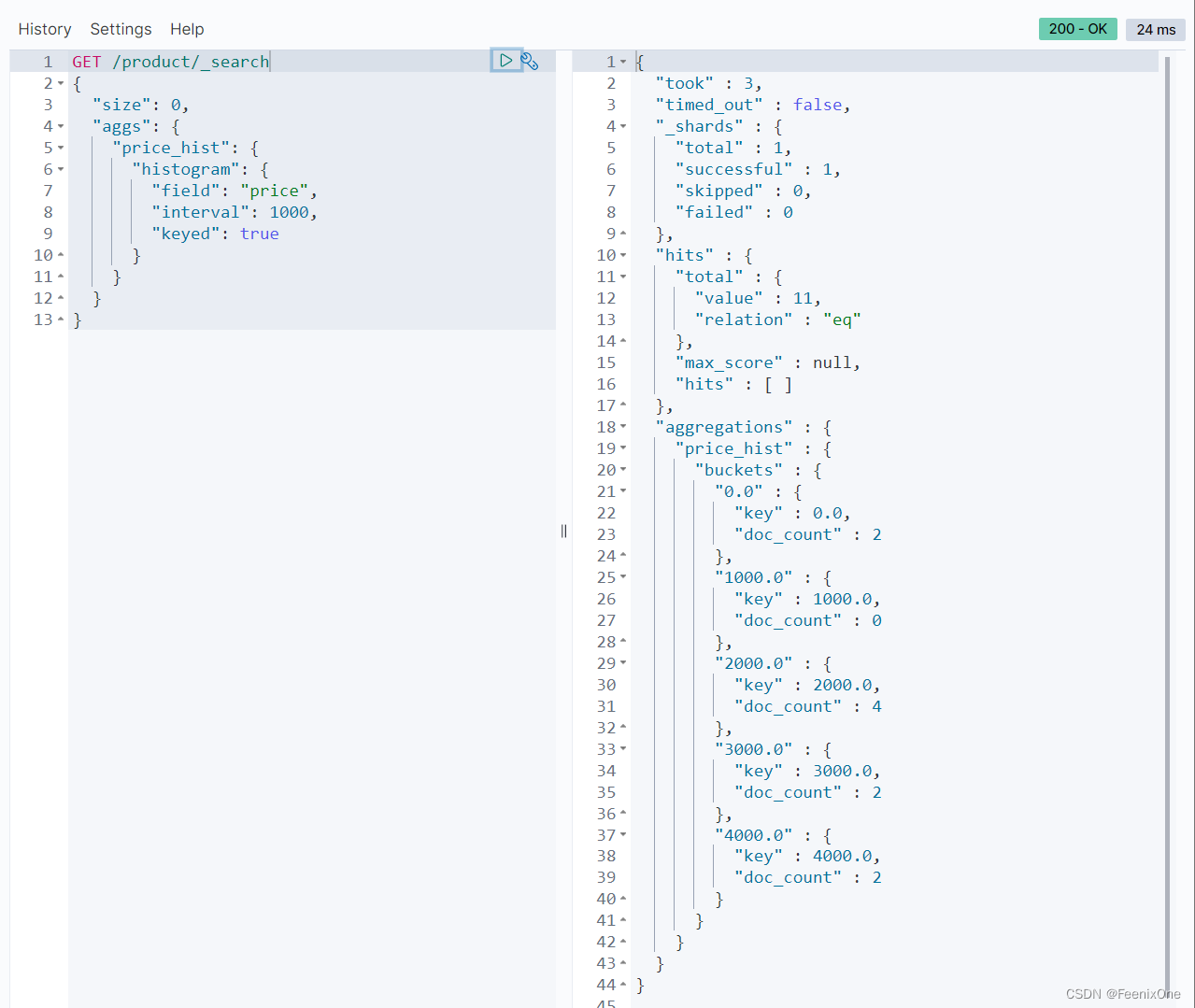
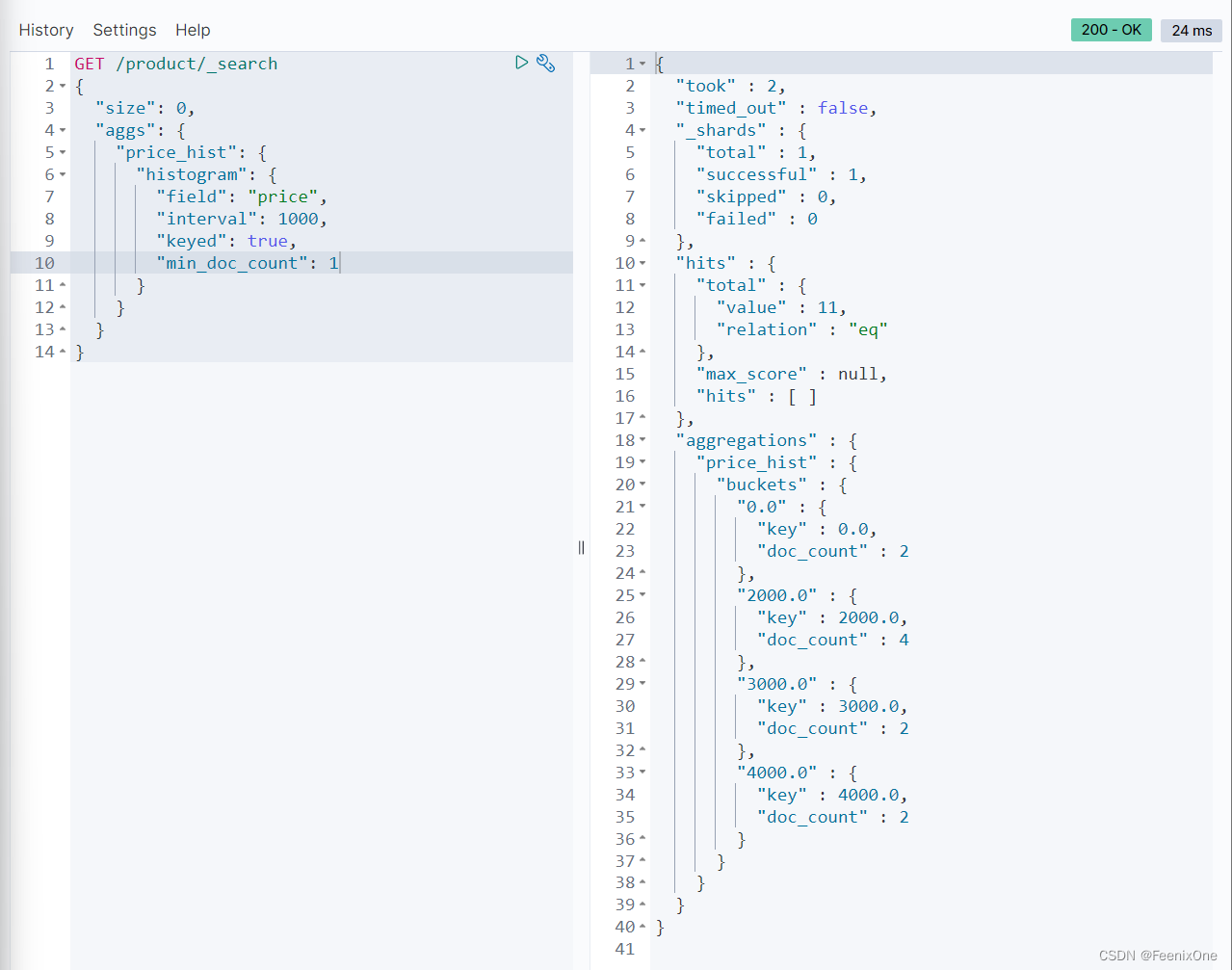
设置:”min_doc_count”: 1,只将doc_count>=1的显示出来
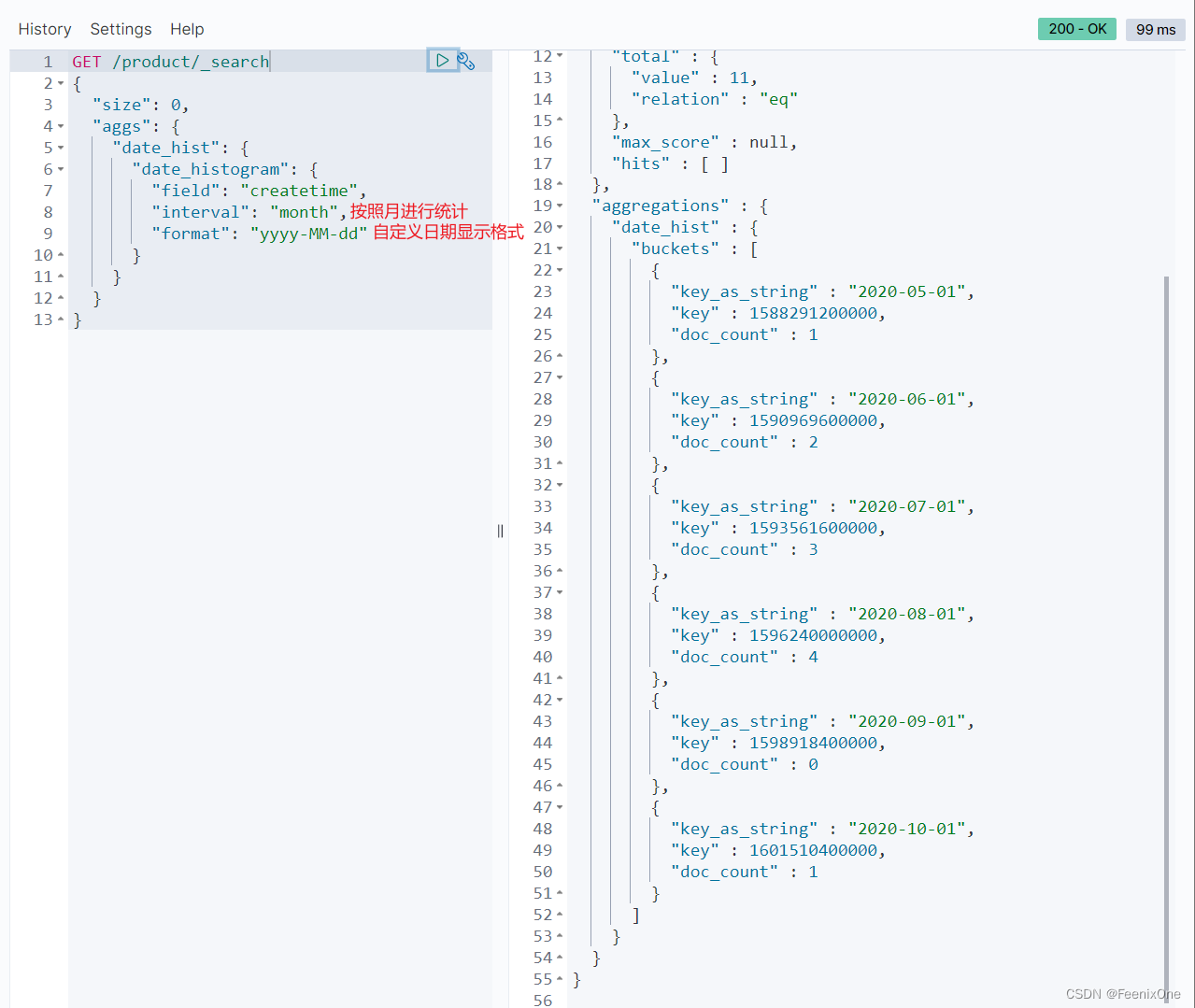
date_histogram 柱状图或直方图
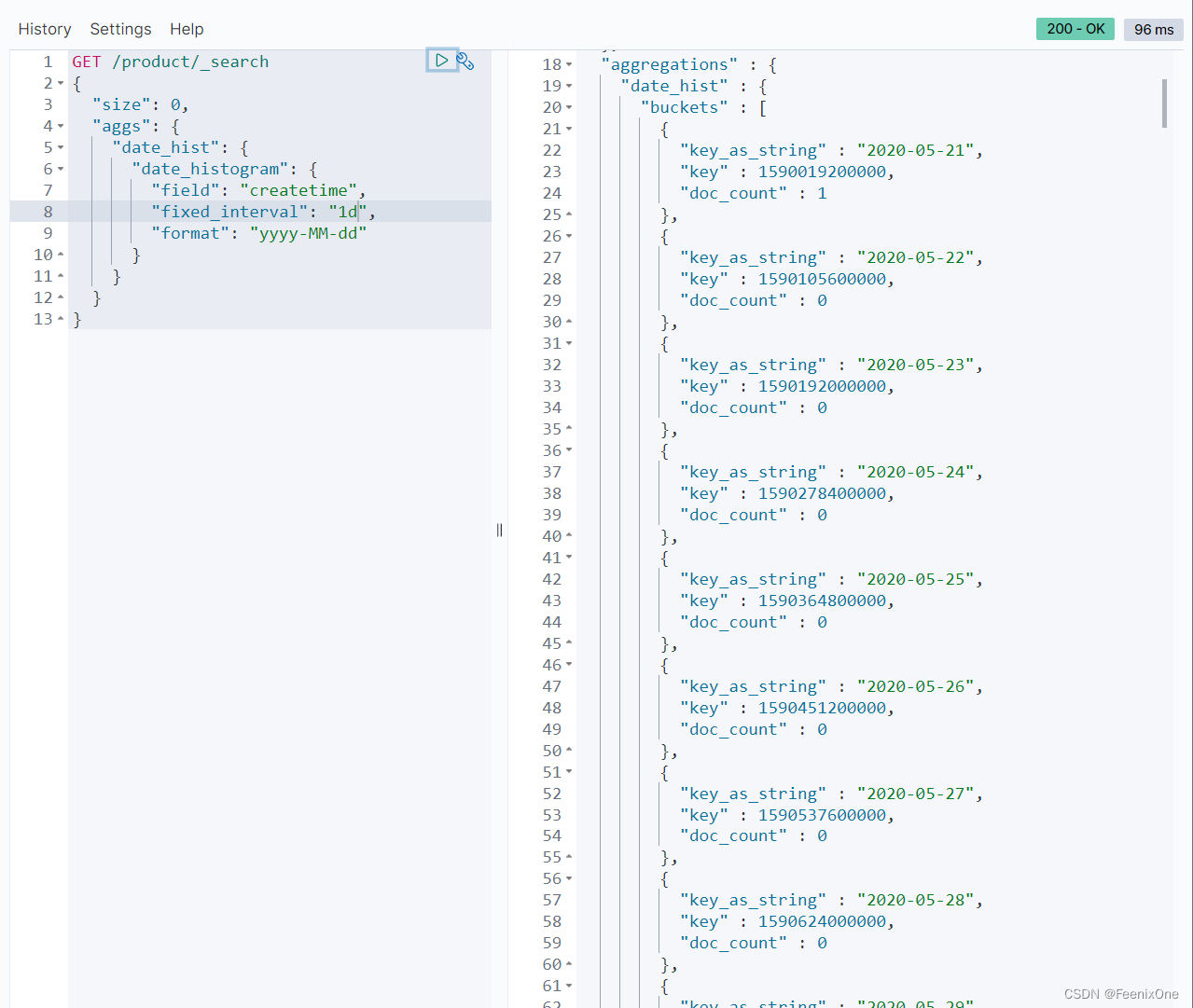
interval已经被官方遗弃,建议使用fixed_interval或calendar_interval来进行日期的分类:
fixed_interval支持的粒度有:ms(毫秒)、s(秒)、m(分)、h(小时)、d(天),fixed_interval的灵活度很高,1d就是1天,10d就是10天。
calendar_interval支持的粒度有:hour(小时)、day(天)、week(周)、month(月)、year(年),calendar_interval的跨度很大,从每小时到每年都可拿下。
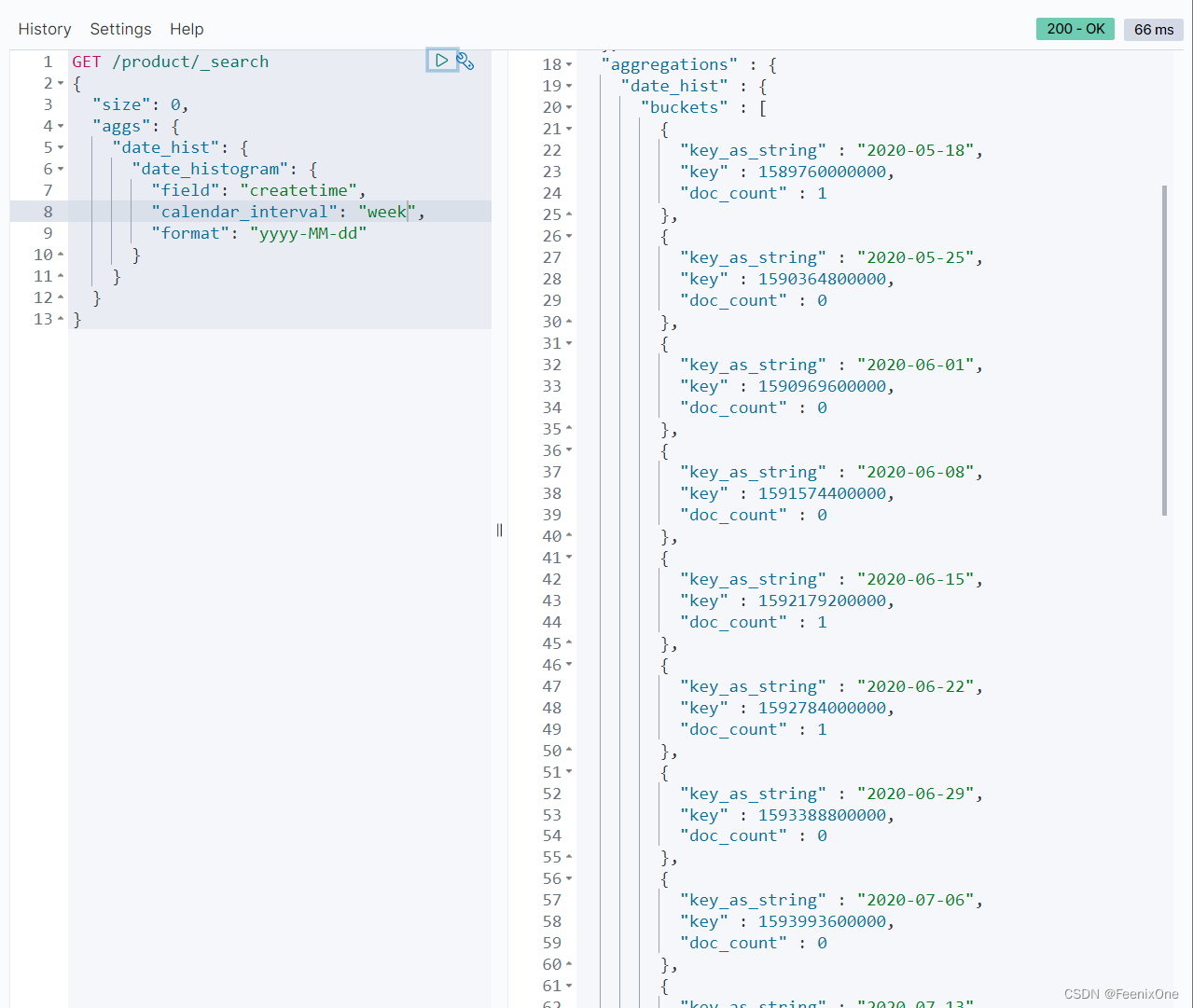
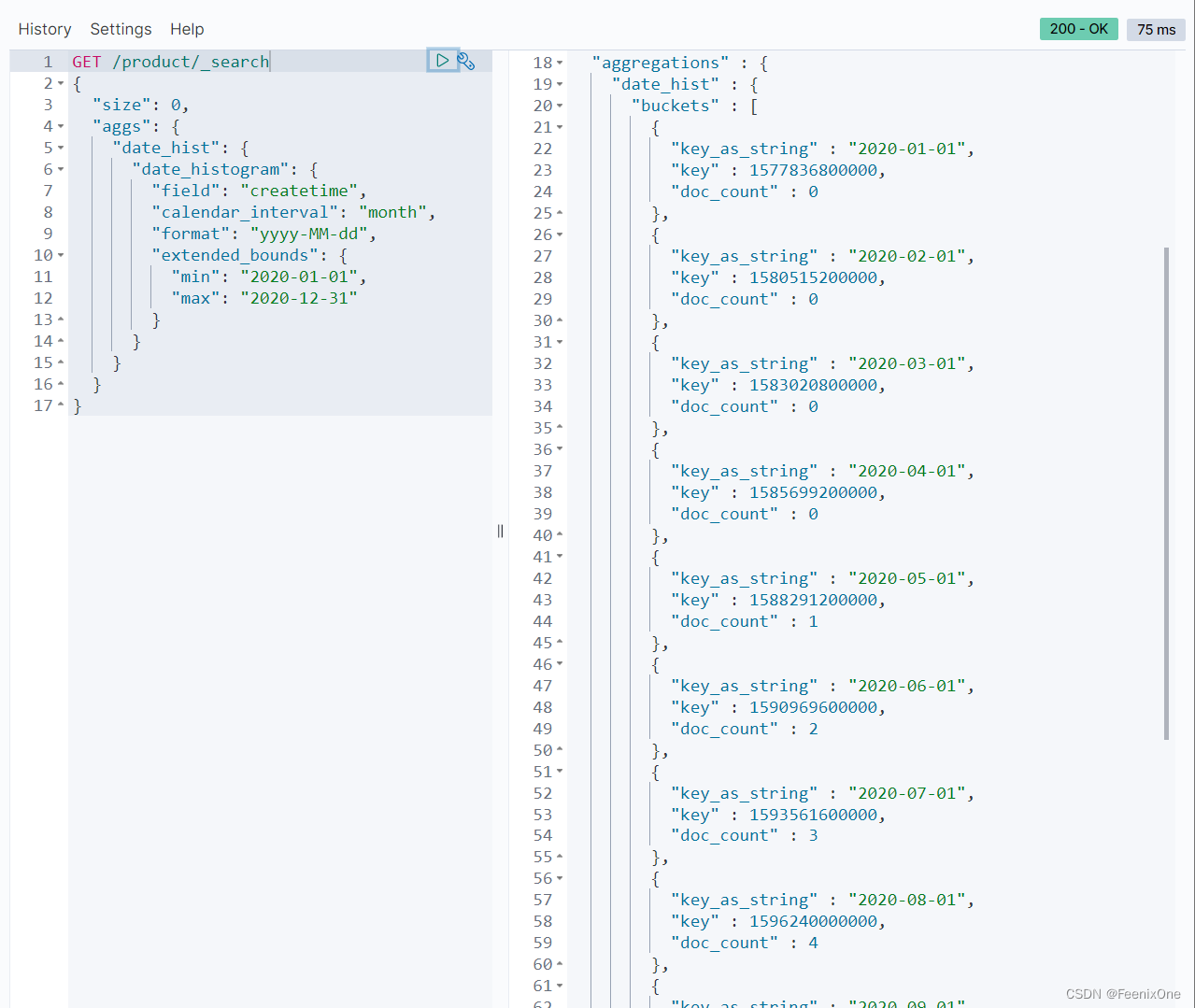
加上extended_bounds条件后,即使是0的数据也会被展示
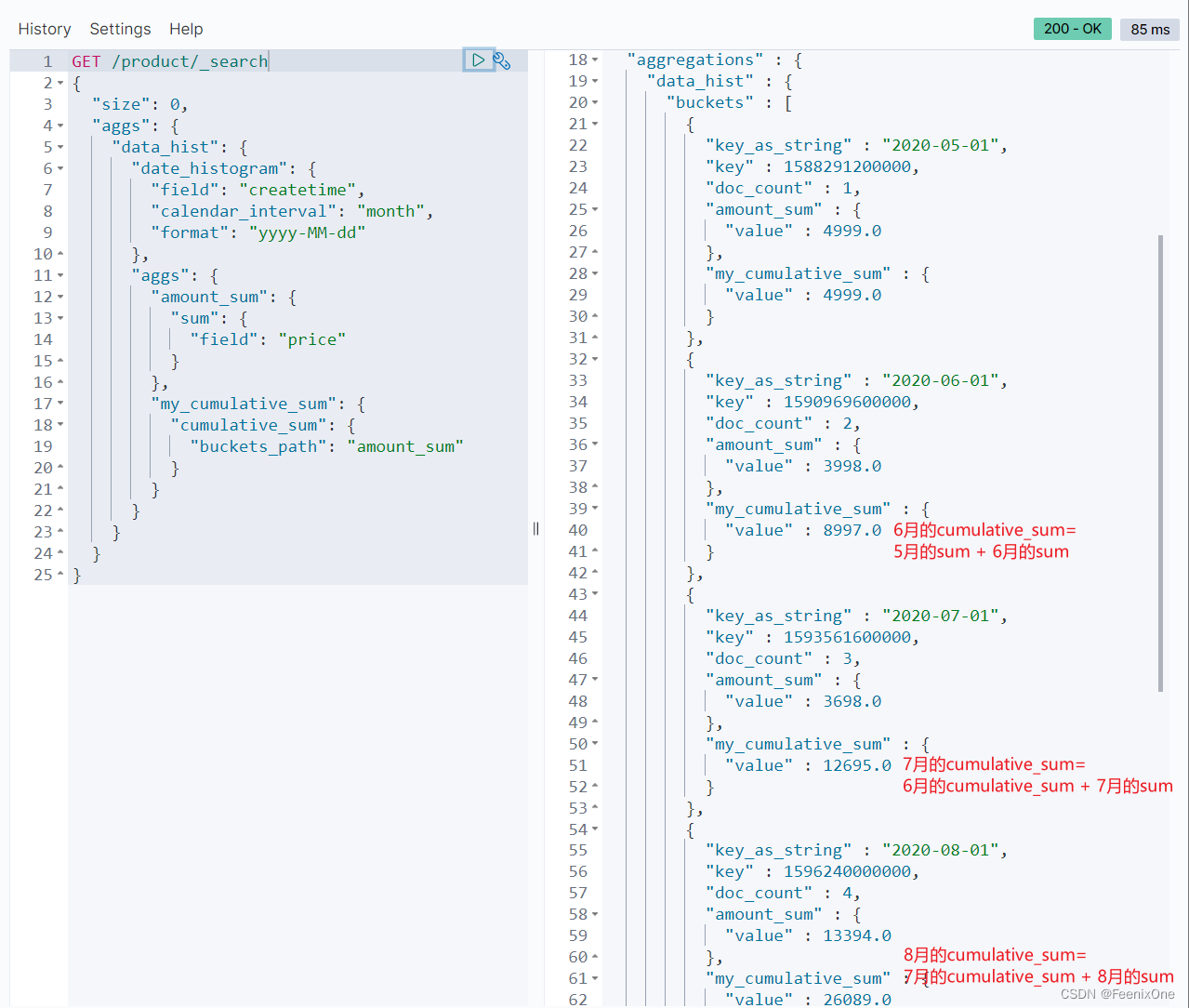
加上cumulative_sum条件后,可以将聚合的每个阶段的数据进行累计叠加
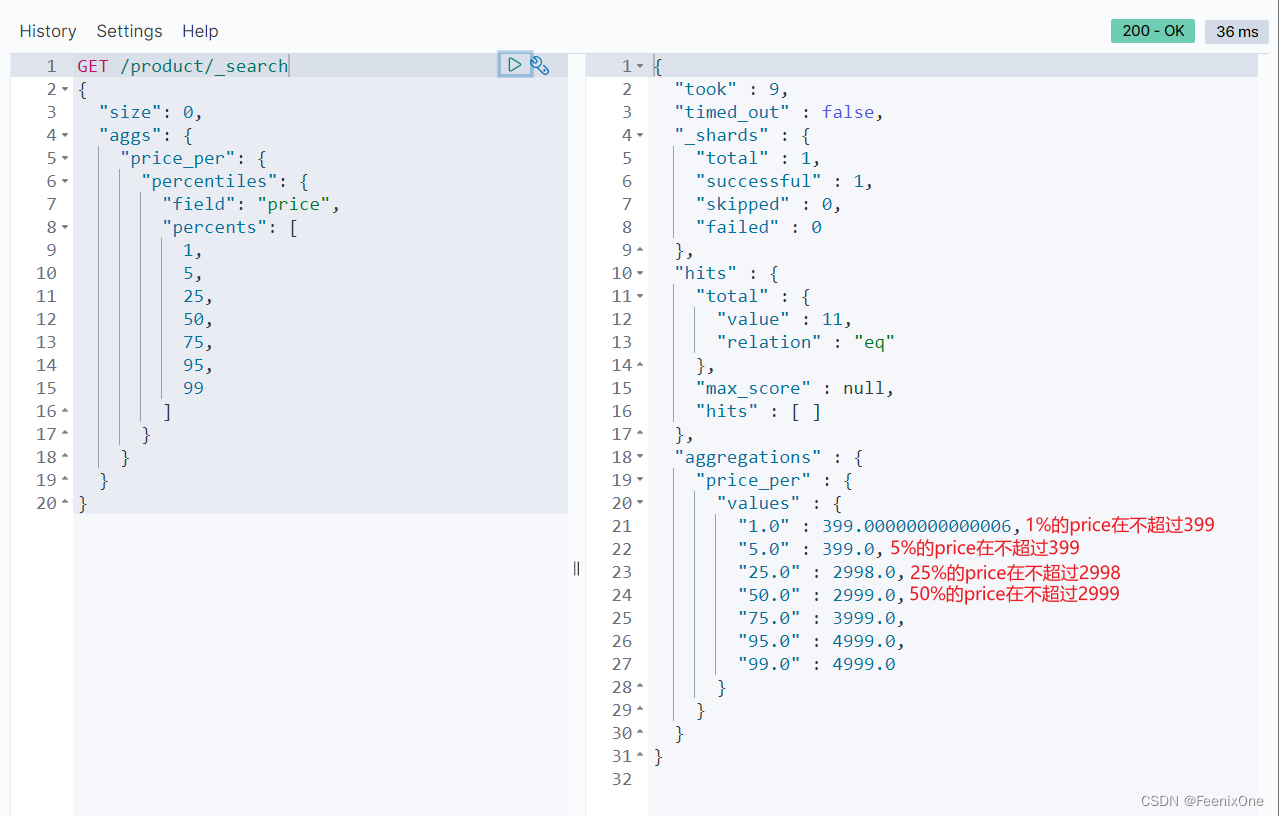
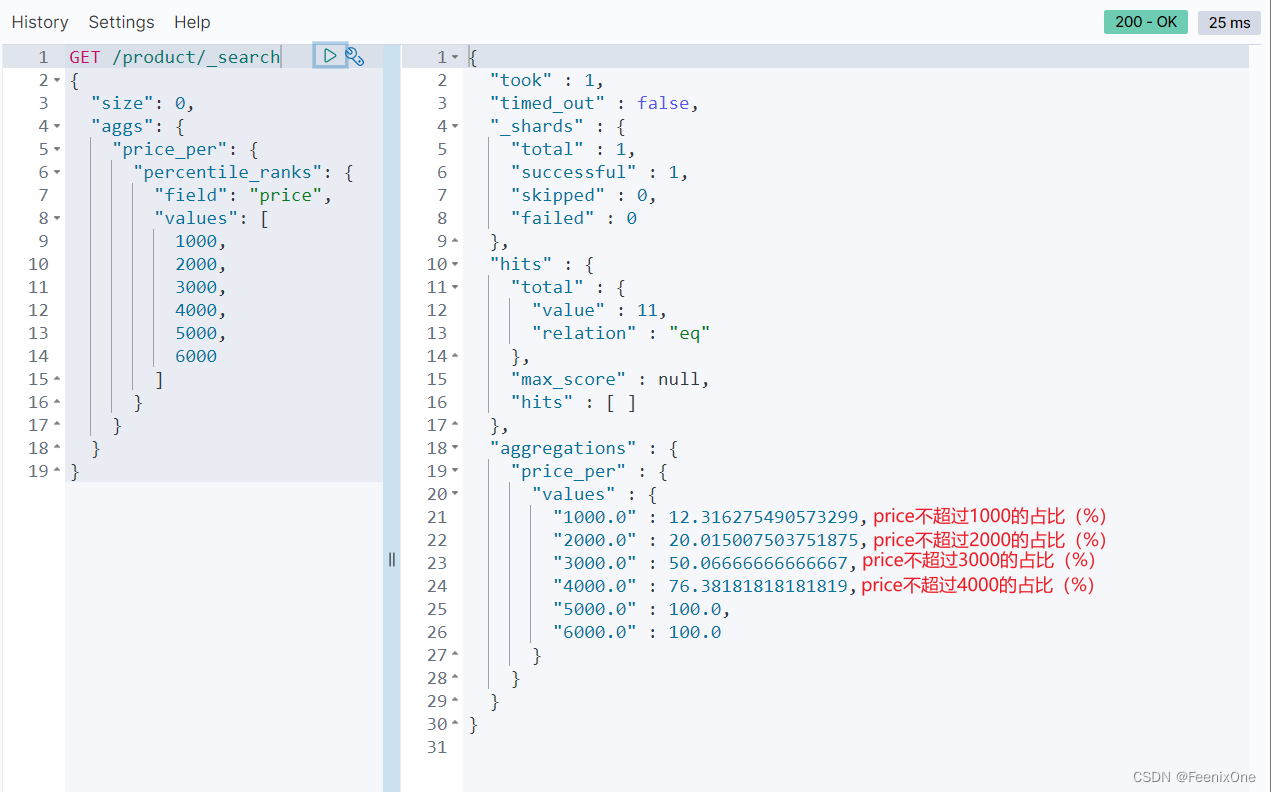
percentile 百分位统计或饼状图
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/111908.html

