
normalization 规范化

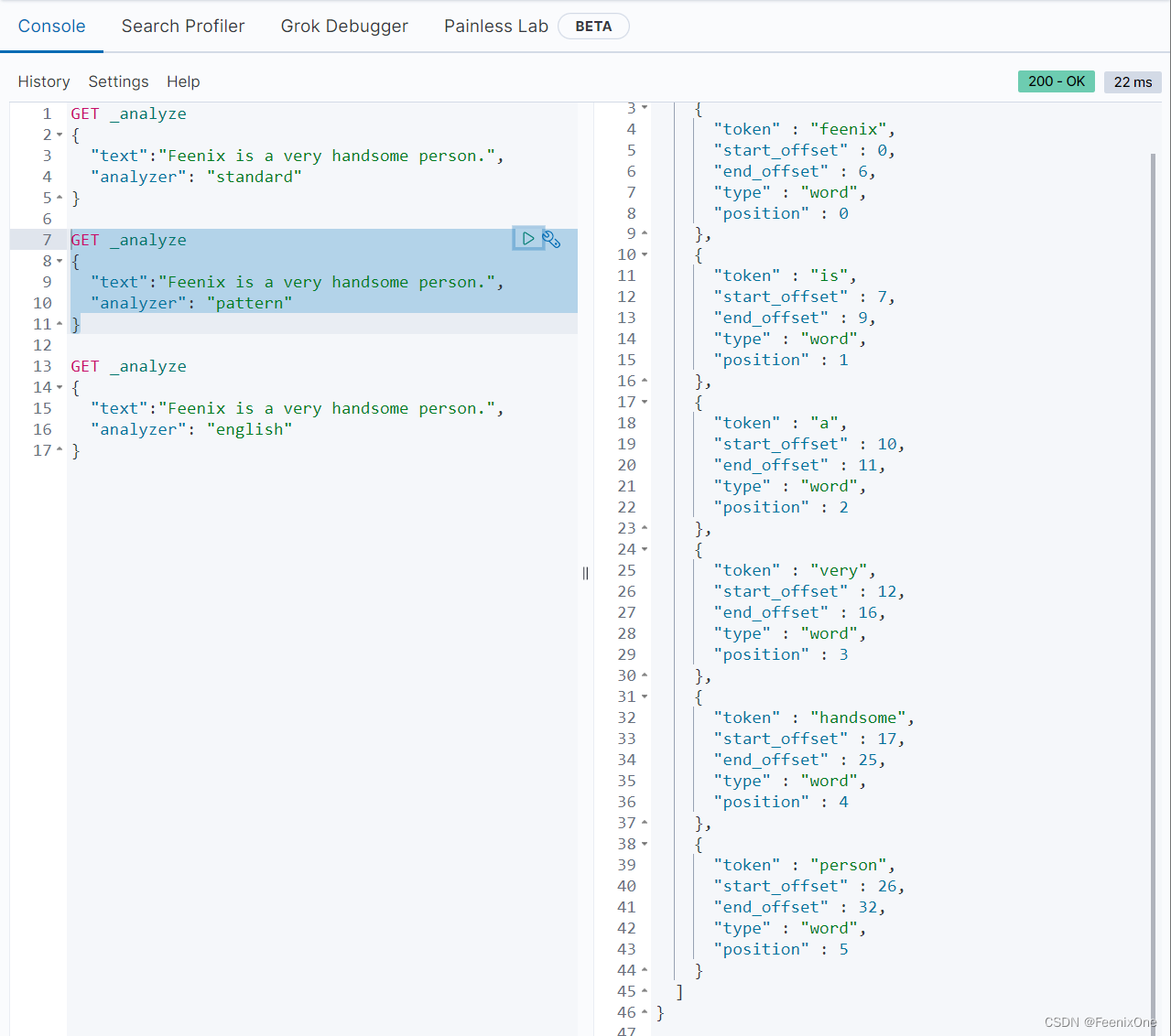

不同的分词器对词语的切分也不一样。
character filter 字符过滤器
分词之前的预处理,过滤无用字符
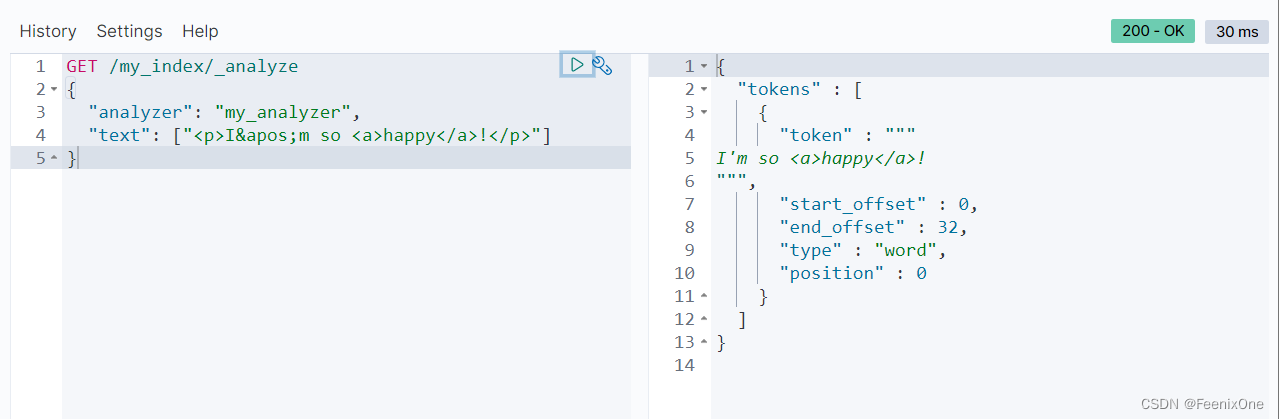
HTML Strip
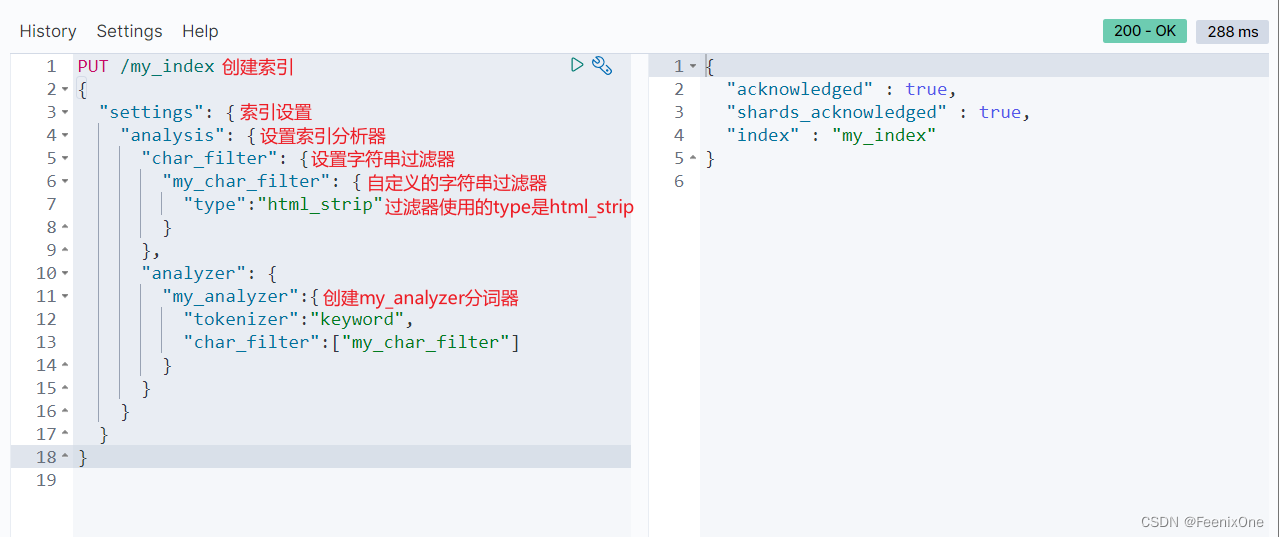
自定义字符过滤器my_analyzer,作用是过滤数据中的html标签
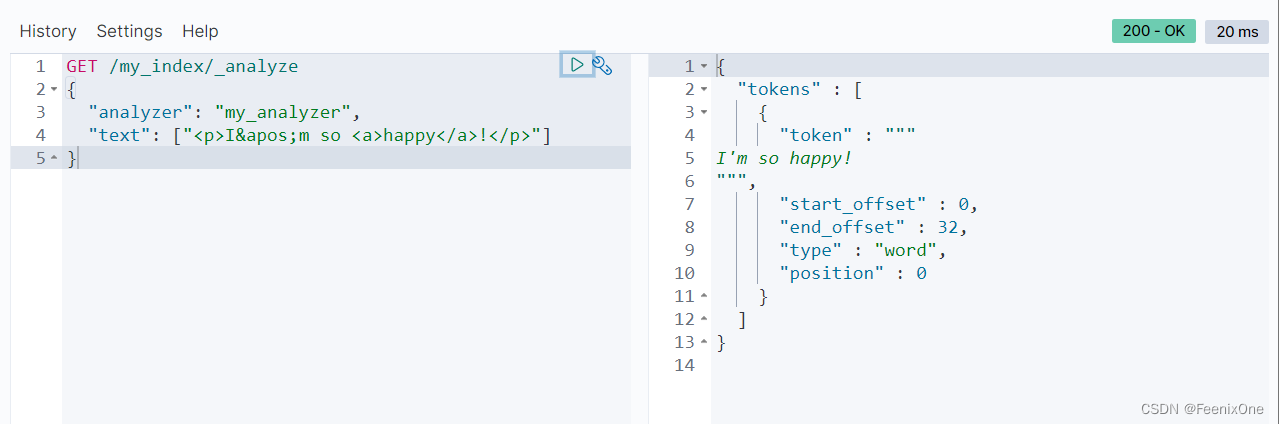
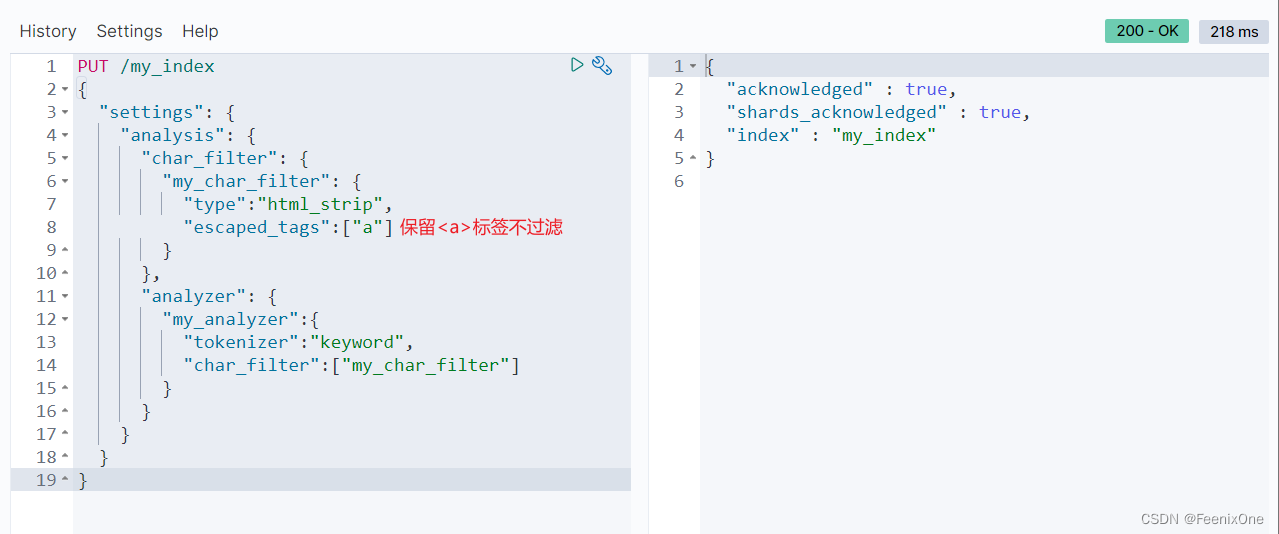
可使用“escaped_tags”:[“a”]设置保留不被过滤的标签
Mapping
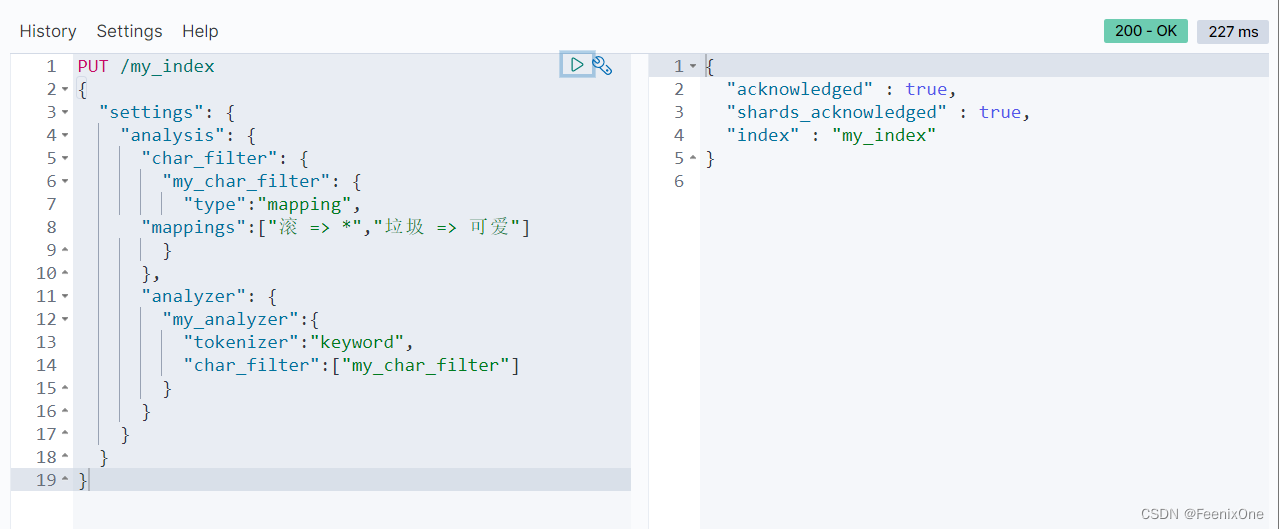
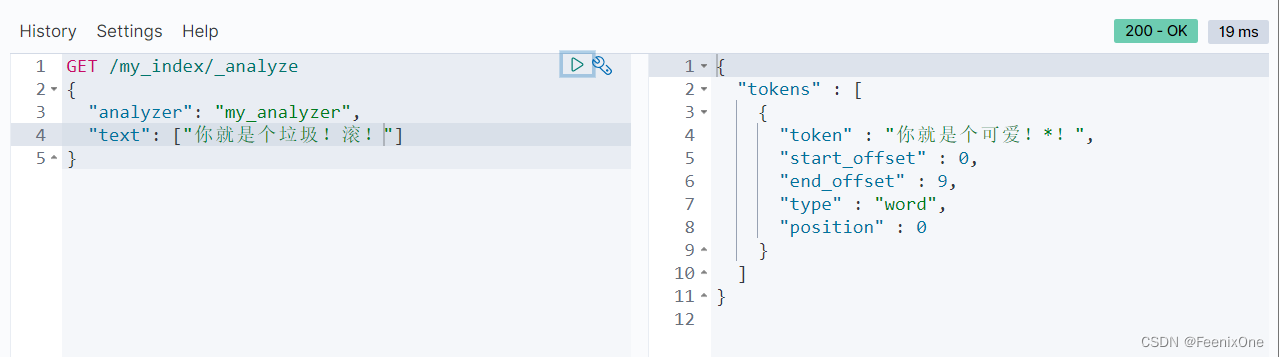
通过自定义的过滤器,可以将聊天、留言或者弹幕之类的发言根据需求进行屏蔽或替换。
Pattern Replace
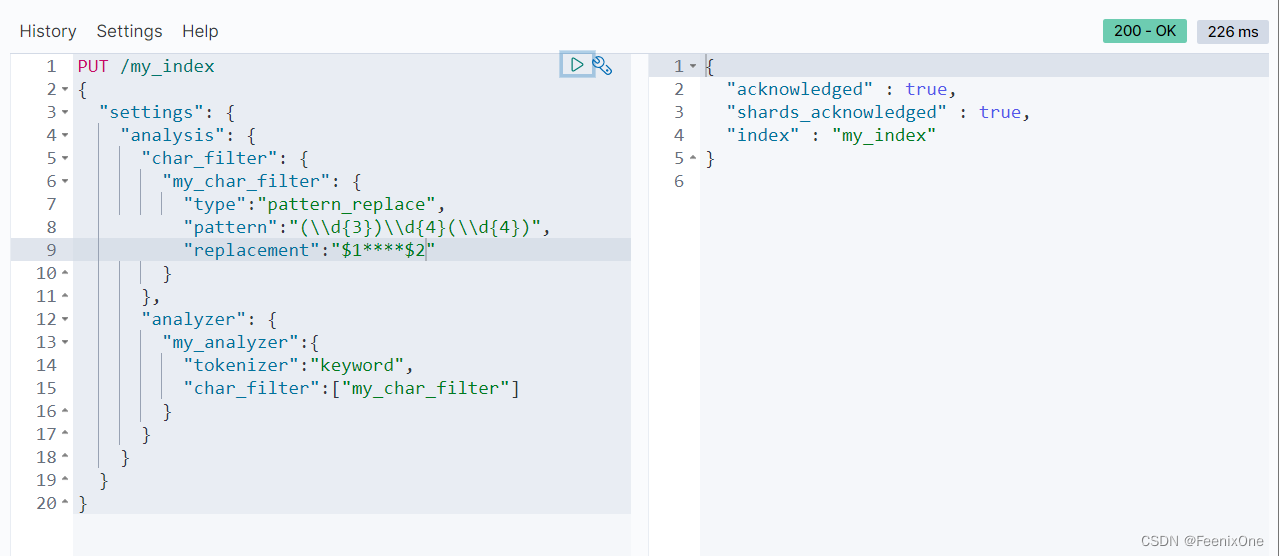
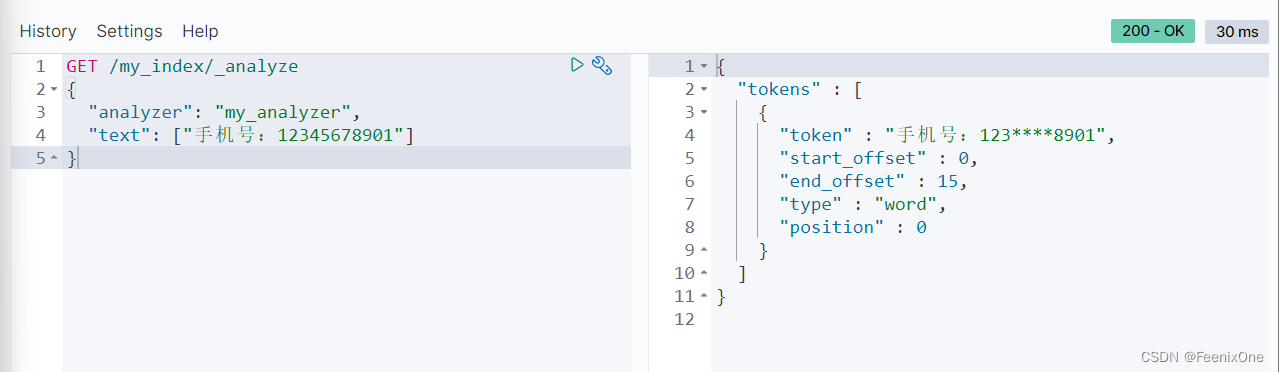
通过正则表达式进行数据的替换。
token filter 令牌过滤器
停用词、时态转换、大小写转换、同义词转换、语气词处理等。
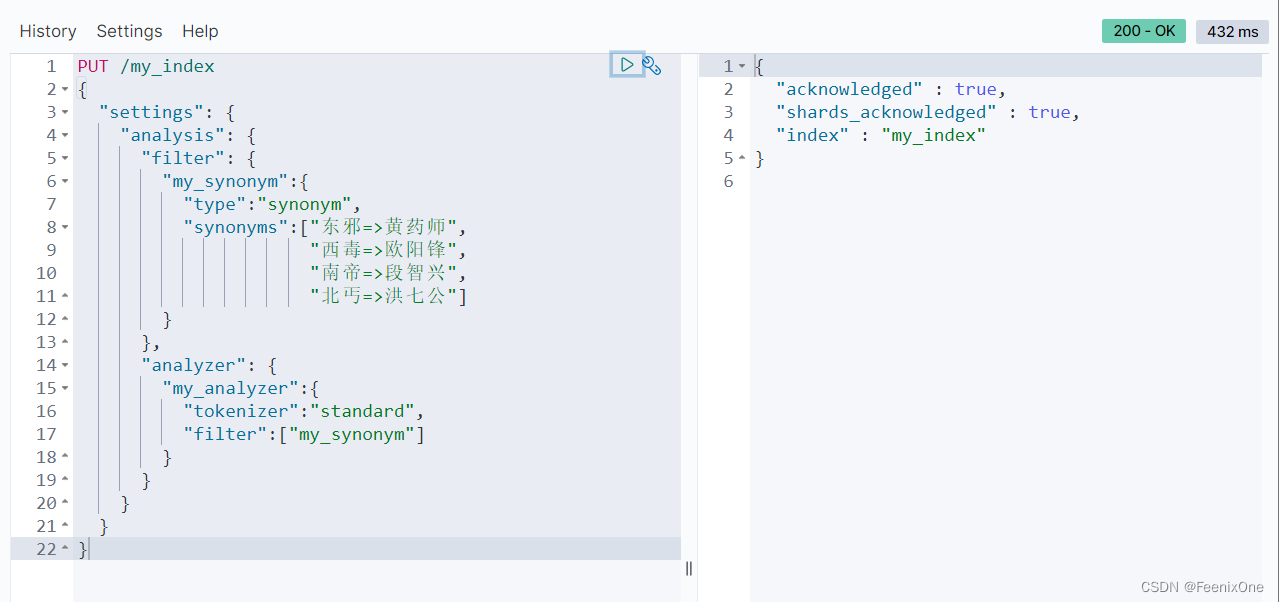
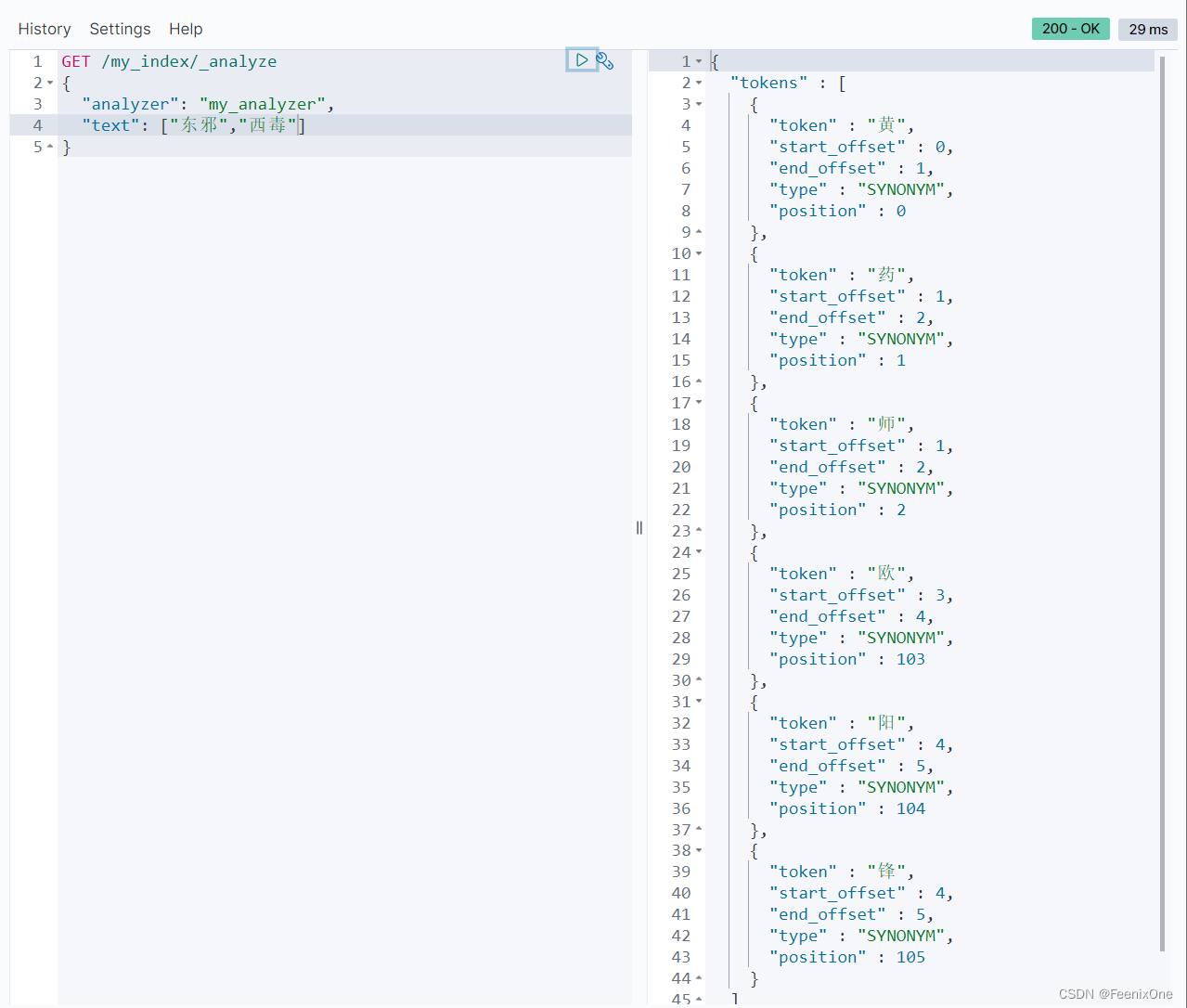
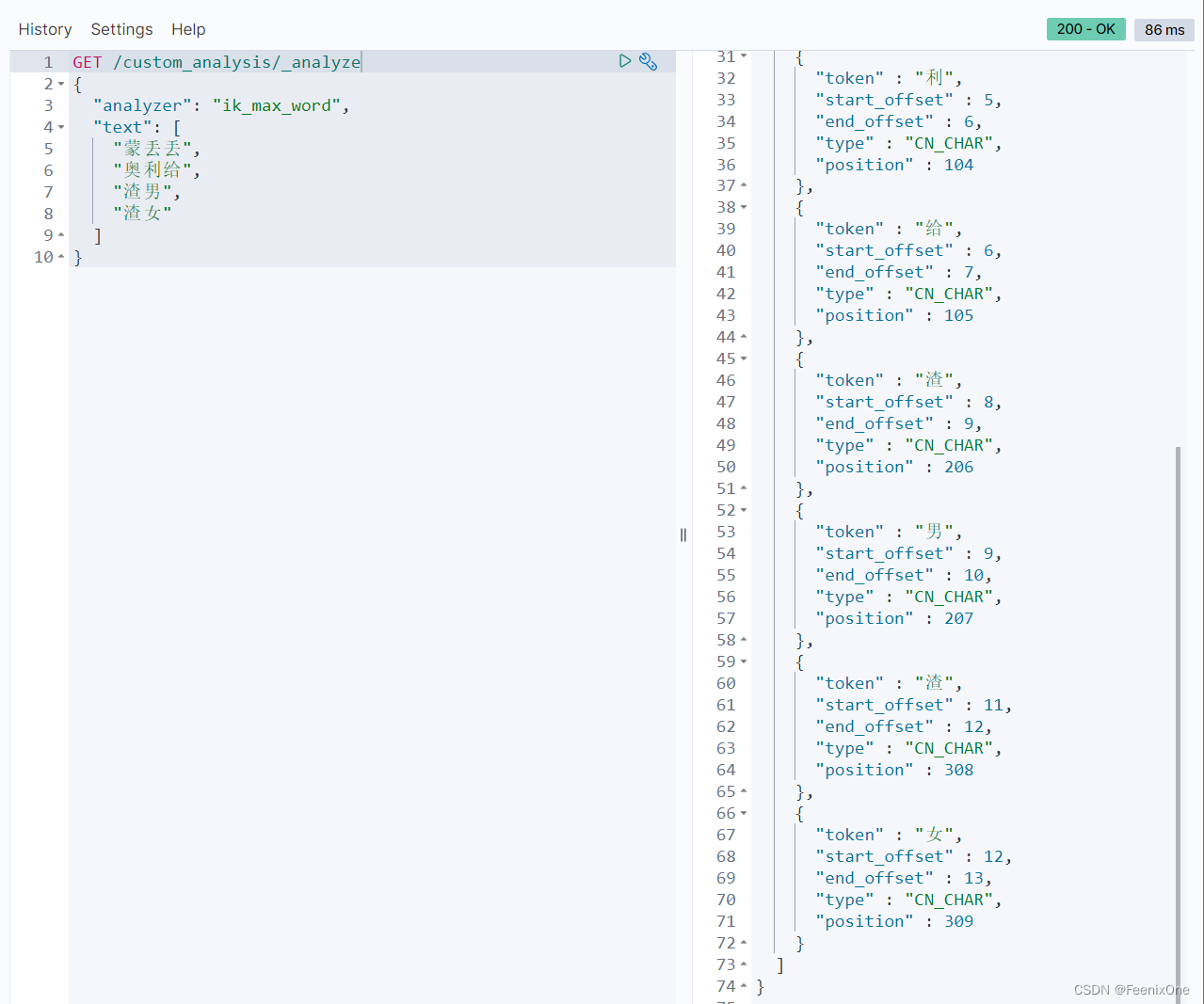
可以看到”东邪”检索到”黄药师”的分词,”西毒”检索到”欧阳锋”的分词。
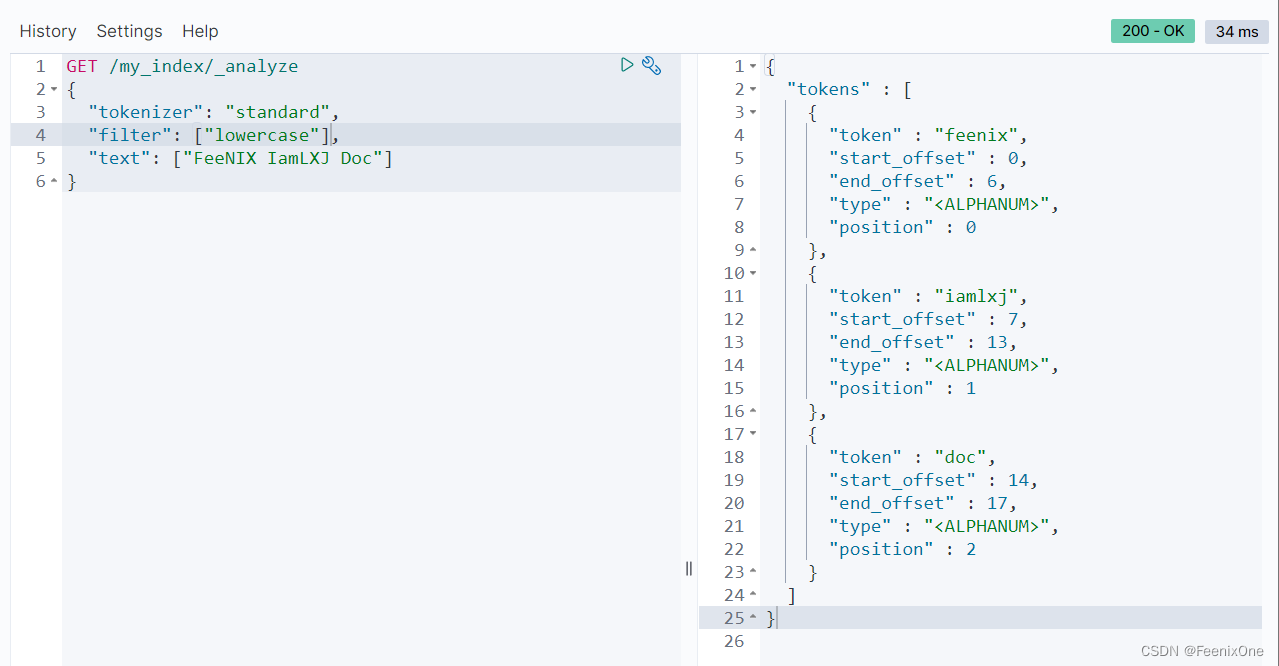
除了自定义的以外,也可以使用ES自带的,比如大小写的转换:
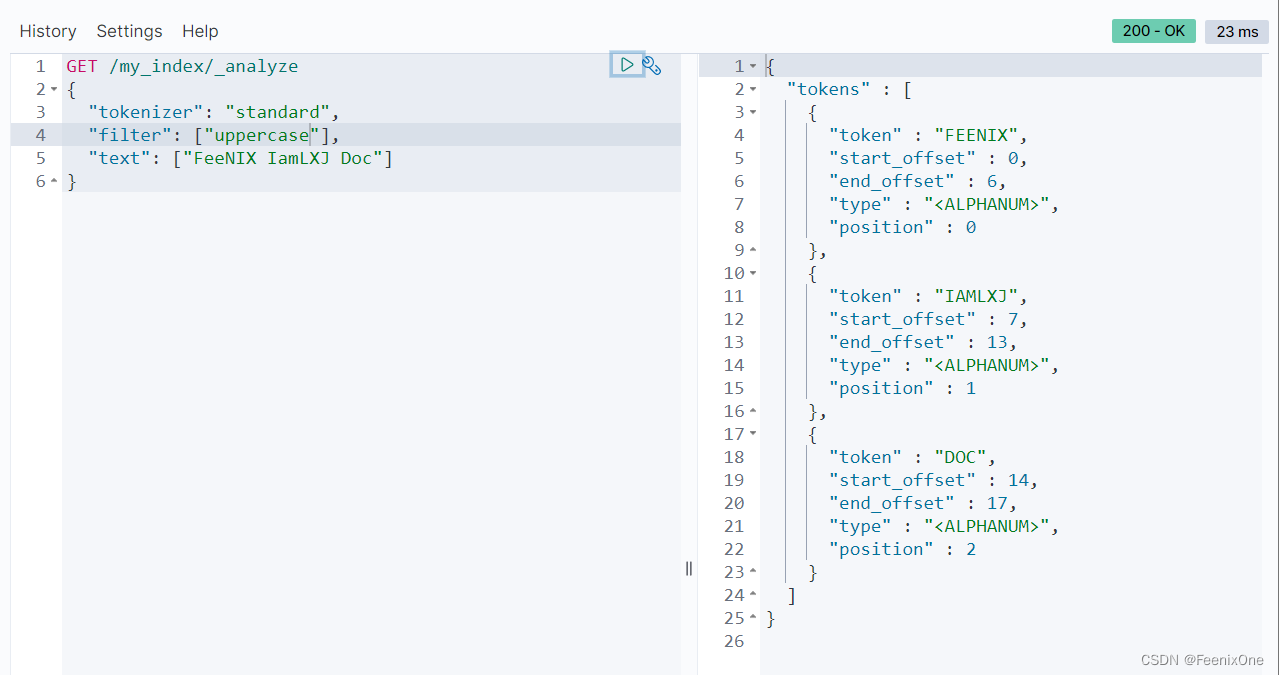
甚至可以通过自定义脚本动态的控制过滤逻辑,比如将长度大于5的字符串转为全大写:
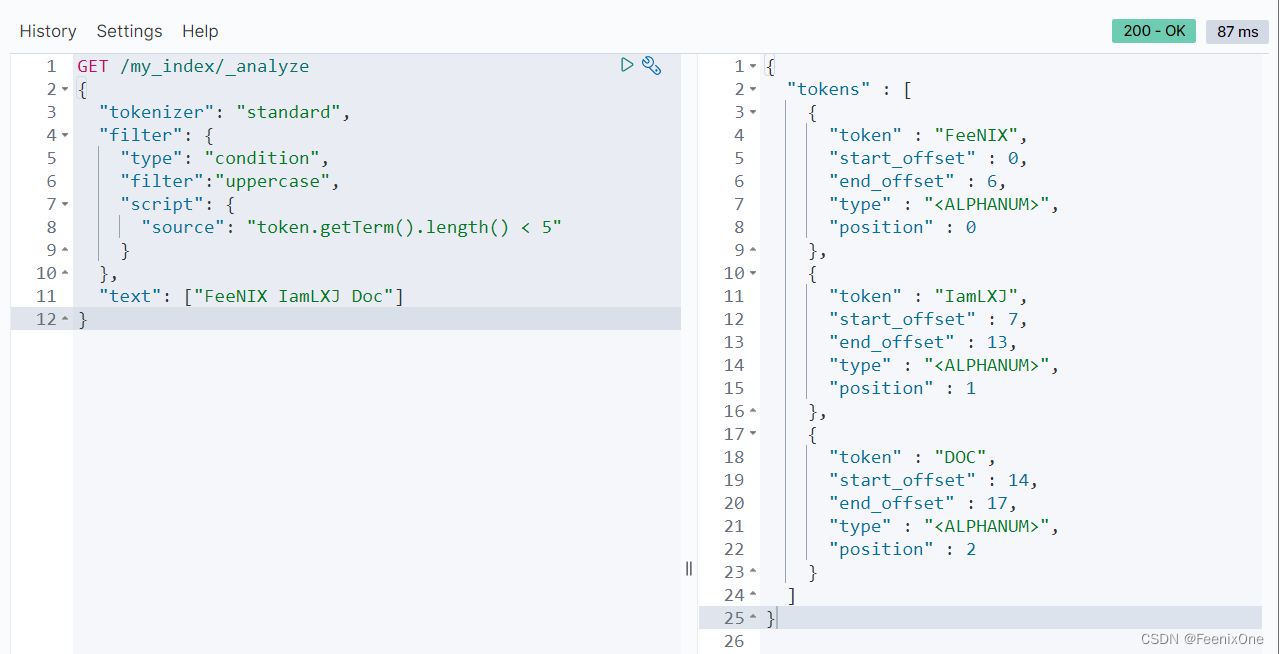
也可以将一些语句中没有什么意义的语气词等作为停用词不参与检索:
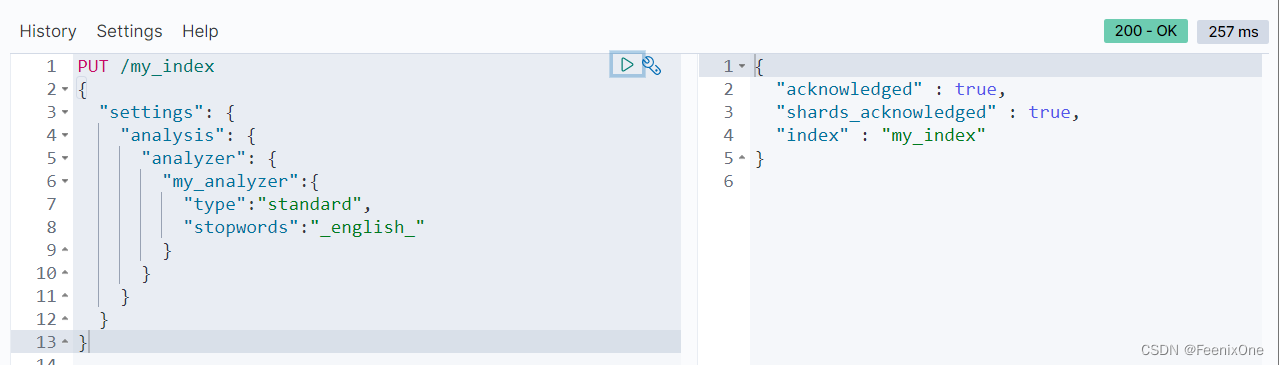
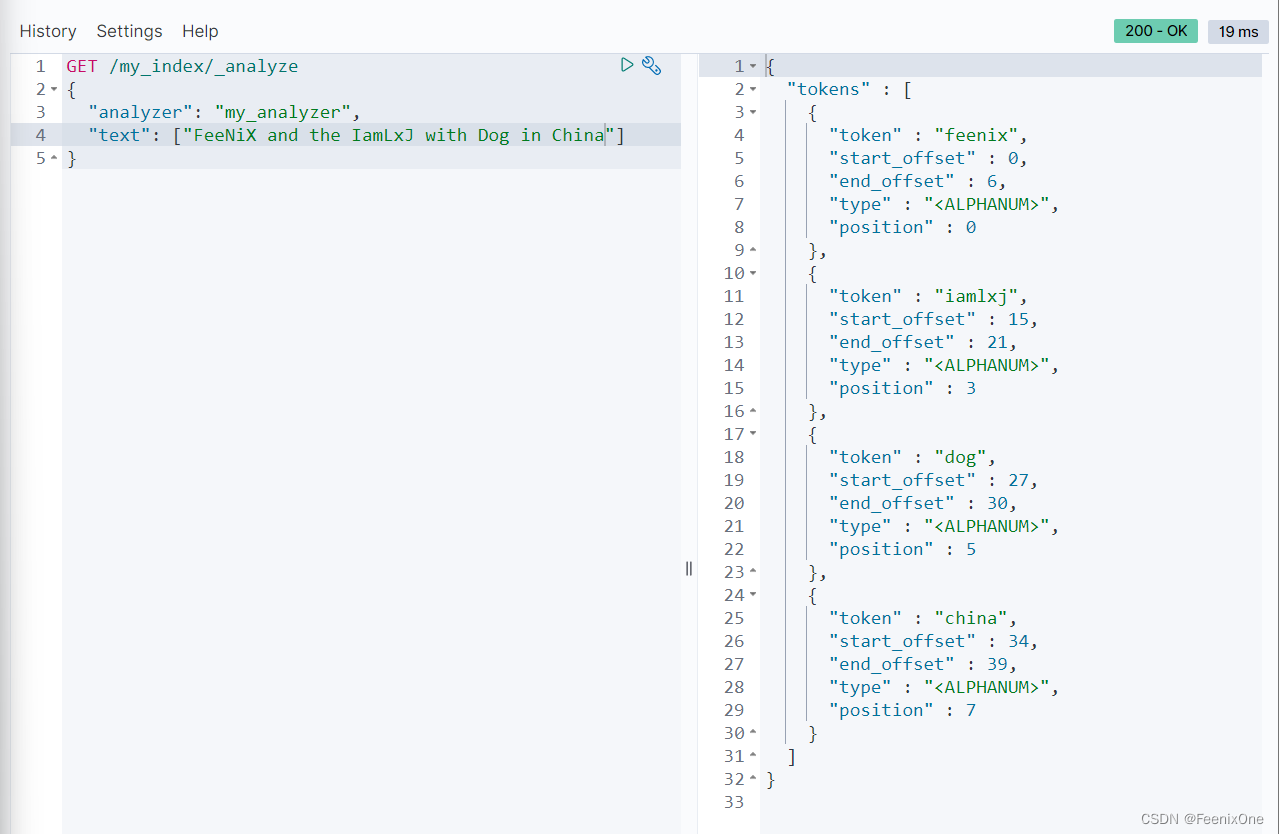
也可以将一些语句中不管有没有意义所有的词都不作为停用词参与检索:
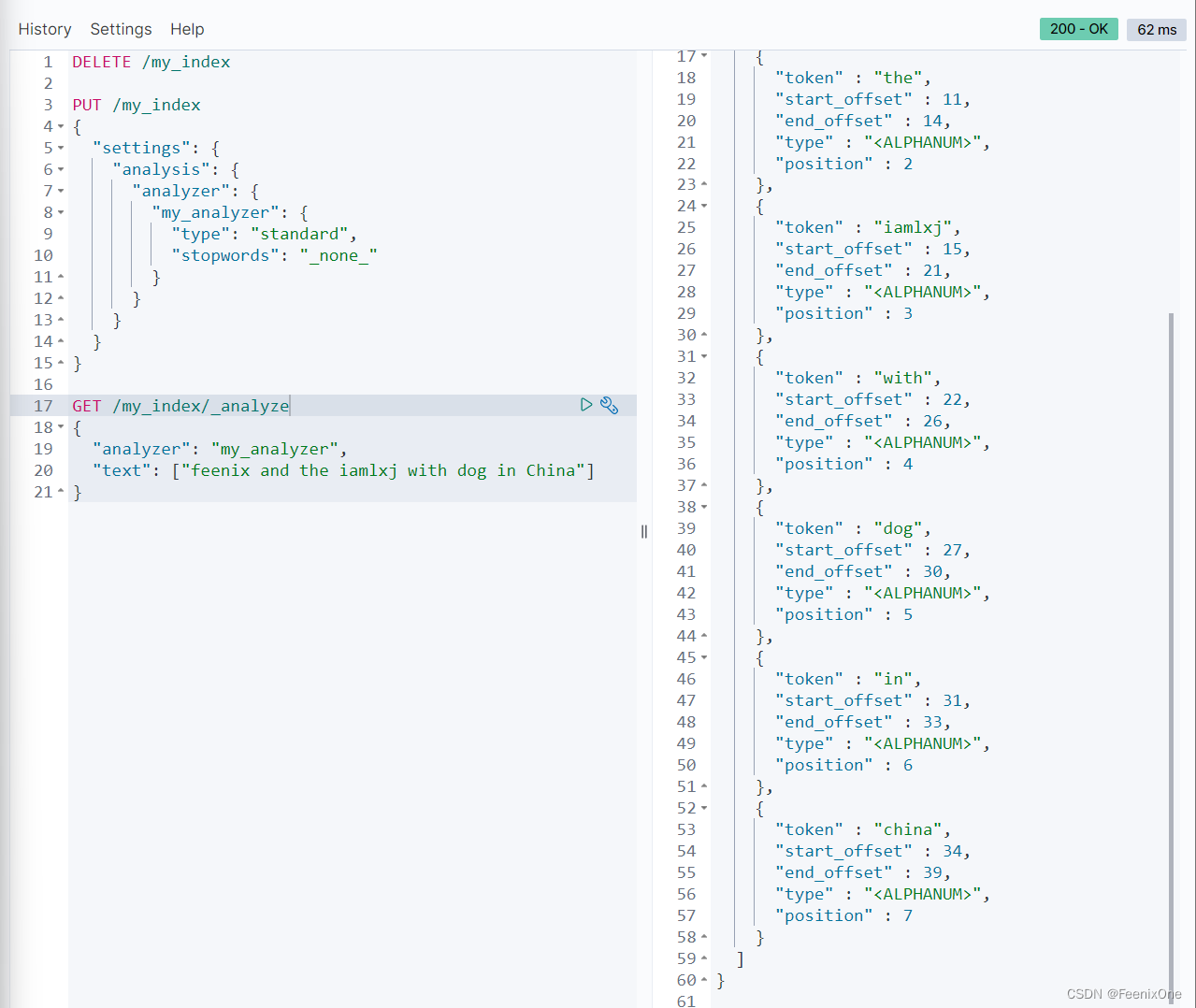
当然也可以手动自定义去设置那些词作为停用词使用:
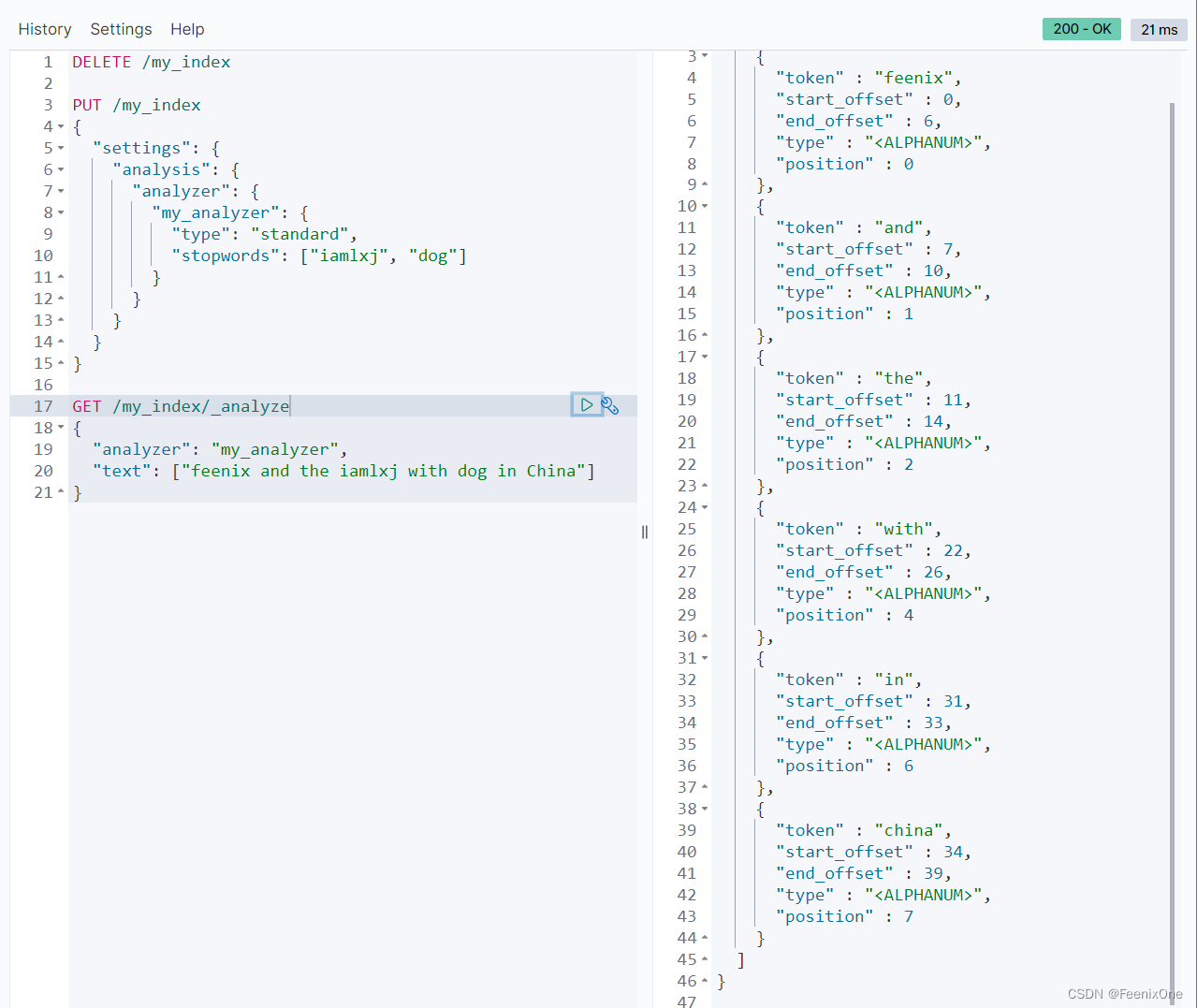
tokenizer 分词器
其实在上面的过程中一直都在使用分词器,ES中默认的分词器是standard。这个分词器在切词的时候是基于英文的空格去切分,对于英文检索来说简单粗暴,直接好用。
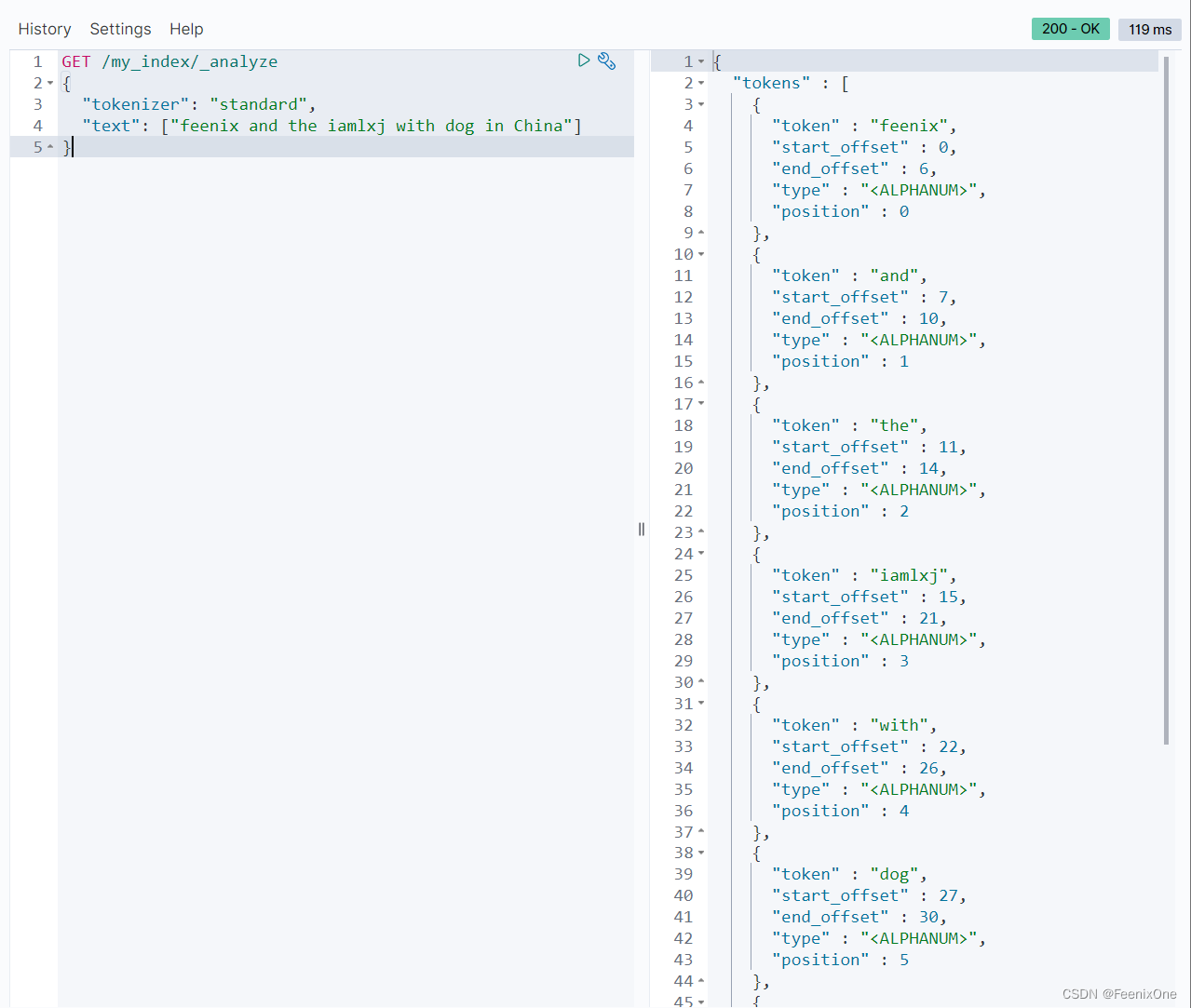
但是对于中文来说,standard也是非常简单粗暴的按照每一个汉字来进行切割,这就很难受了

虽然ES官方提供了很多个分词器,其实对于中文的支持都不好用:
standard:默认分词器,中文会逐字拆分;
pattern:以正则匹配分隔符,把文本拆分成若干词项;
simple pattern:以正则匹配词项,速度比pattern会快一些;
whitespace:以空白符分隔,把文本拆分成若干词项;
既然官方提供的不好用,那就得自己手动来自定义分词器:
char_filter:内置或自定义字符过滤器;
token_filter:内置或自定义token过滤器;
tokenizer:内置或自定义分词器;
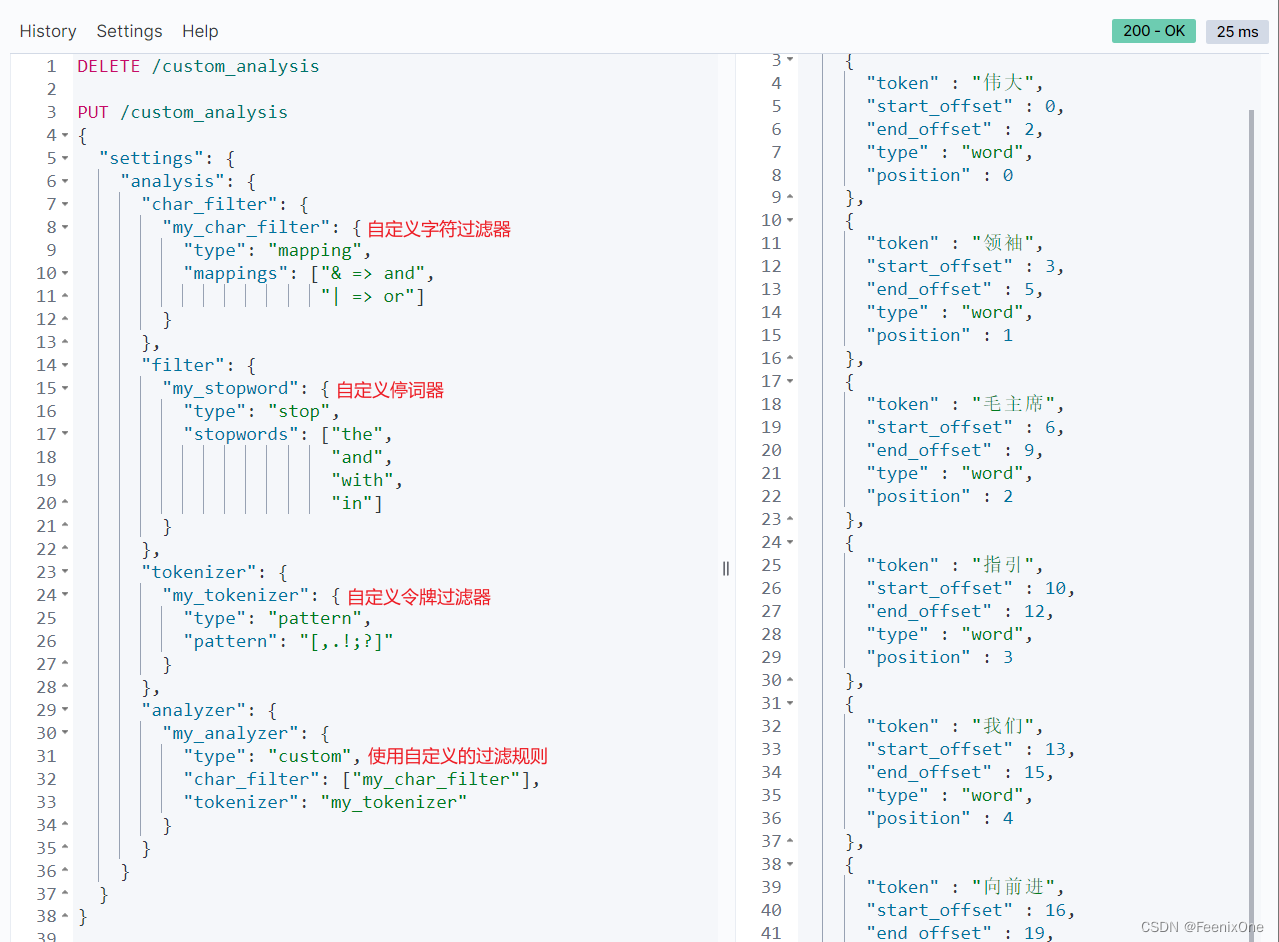
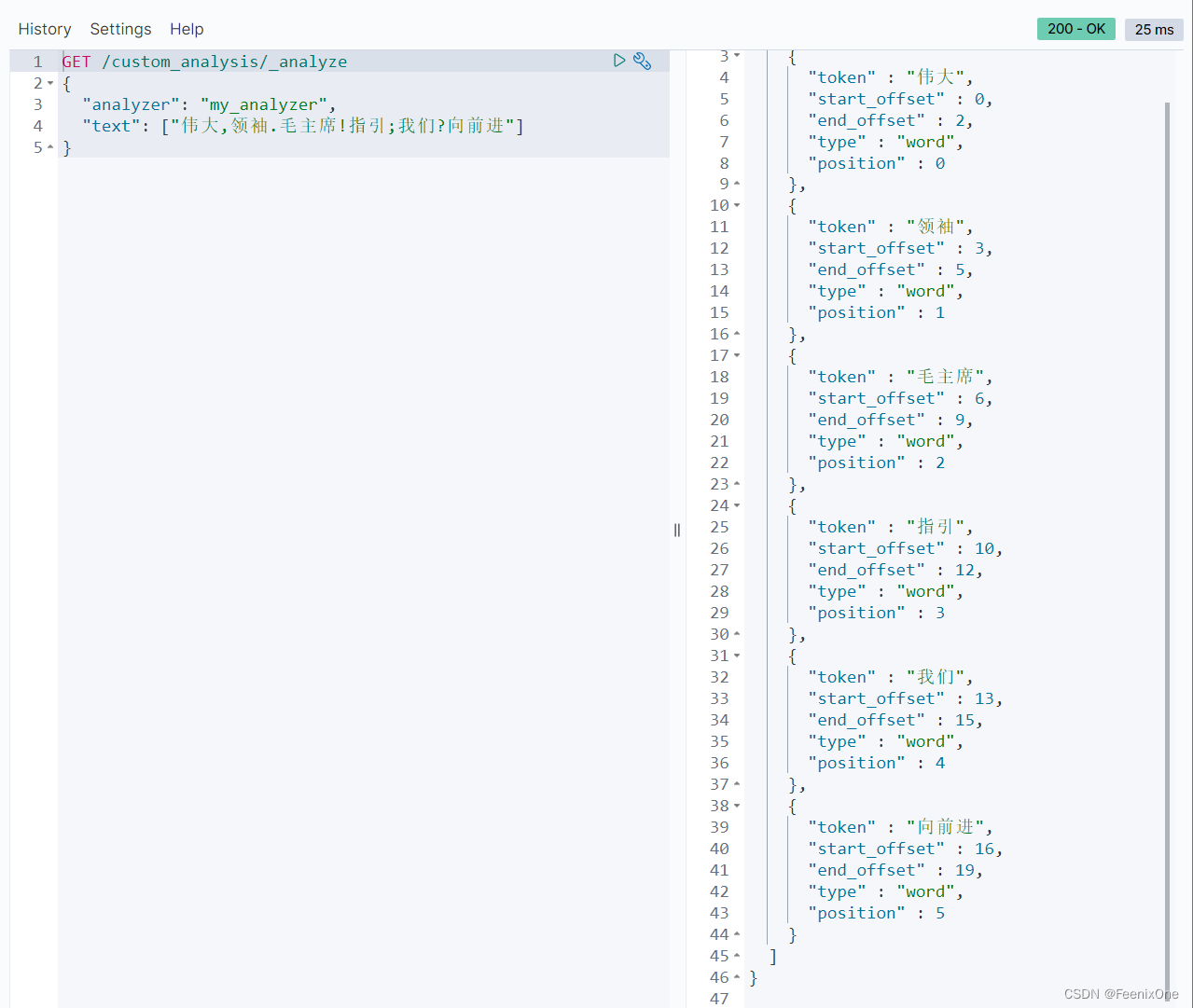
值得一提的是my_tokenizer的设置,”pattern”: “[,.!;?]”指的是文本会按照[]中有的符号去切割
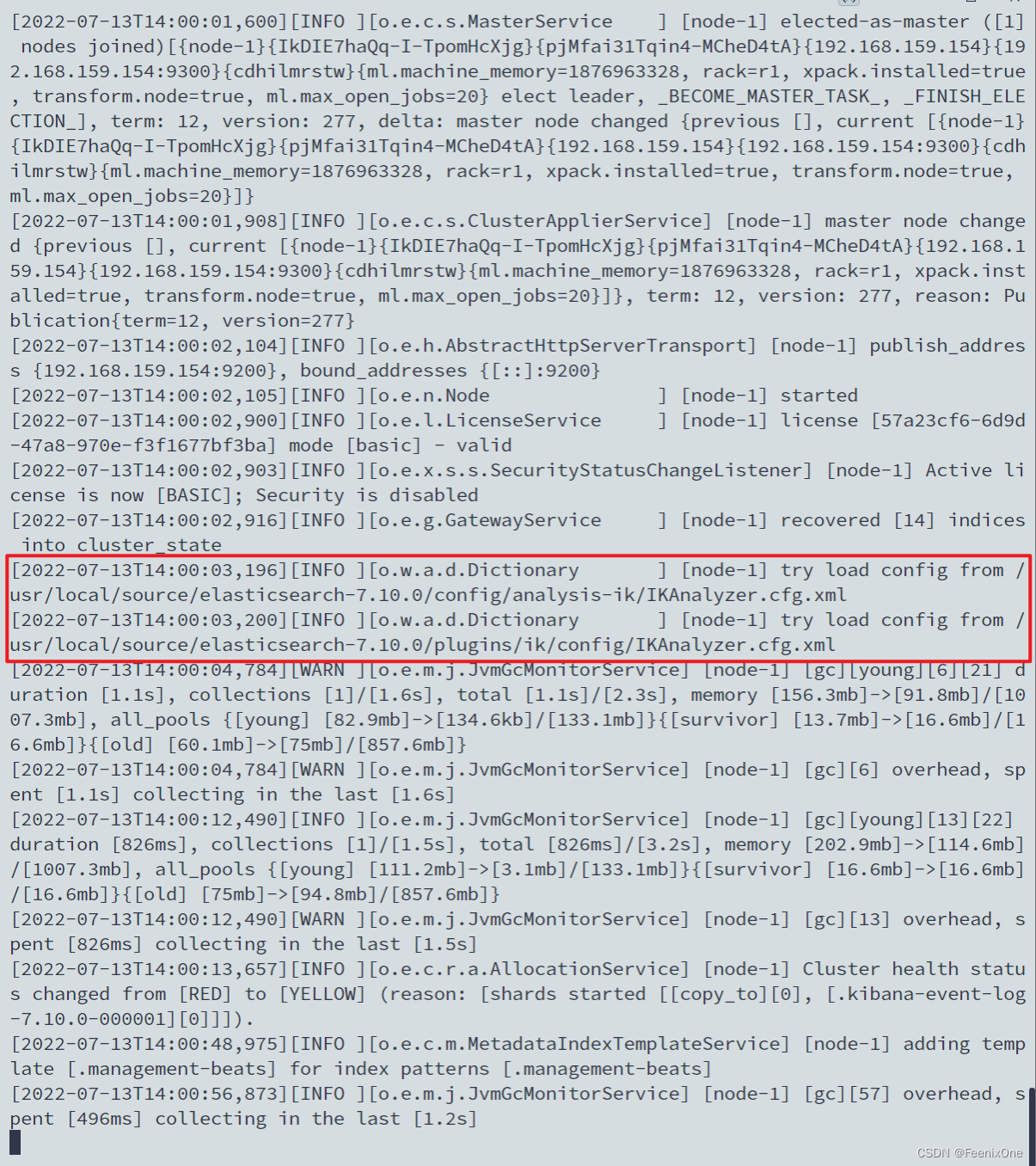
ES安装IK分词器
进入到ES的根目录下的插件目录下,下载IK分词器安装包
cd /usr/local/source/elasticsearch-7.10.0/plugins/
mkdir ik
cd ik/
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.0/elasticsearch-analysis-ik-7.10.0.zip

解压IK分词器安装包,重启ES服务
unzip elasticsearch-analysis-ik-7.10.0.zip
rm -rf elasticsearch-analysis-ik-7.10.0.zip
cd ../../bin/
./elasticsearch
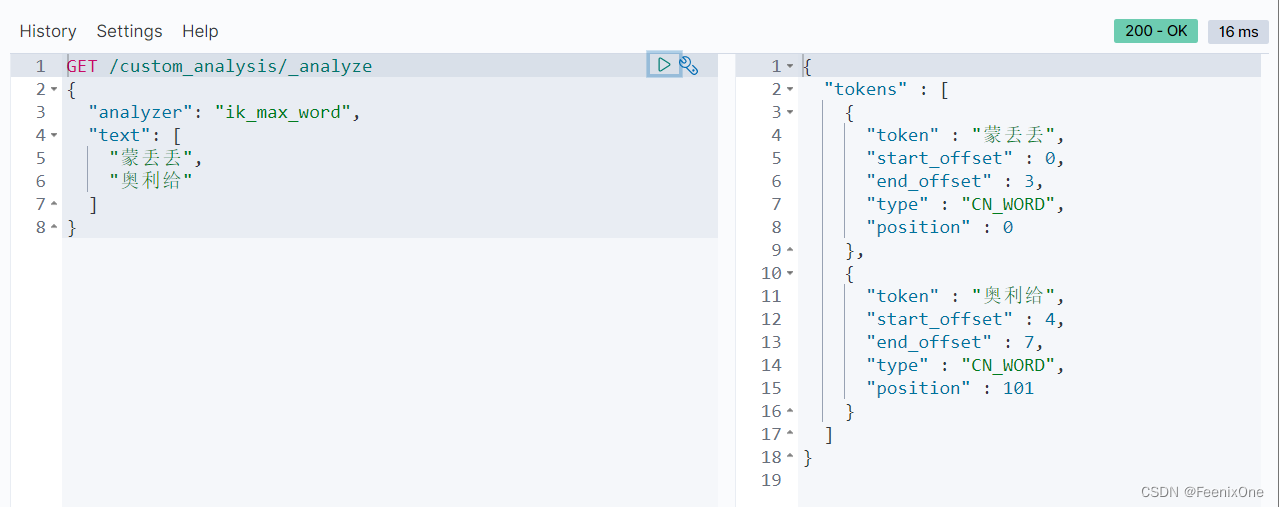
指定使用IK分词器查看分词效果:

ik_max_word对文本的分词粒度比较小
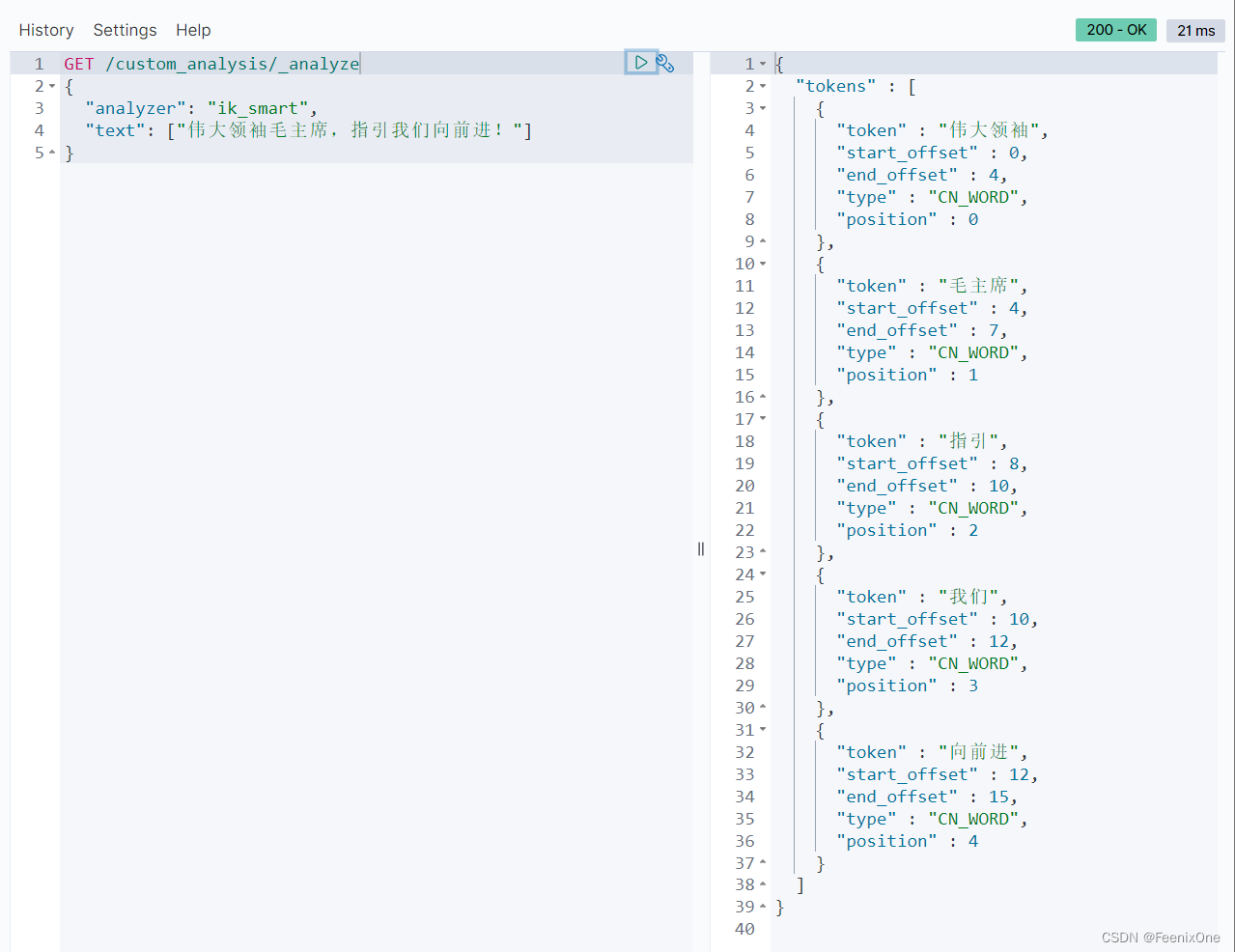
ik_smart对文本的分词粒度比较小
根据IK分词器官方提供的文档,提供了两个analyzer和两个tokenizer,都是ik_smart和ik_max_word。
IK文件描述
IKAnalyzer.cfg.xml:IK分词器配置文件

main.dic:IK分词器主词库,也是IK最大的词库,收录了20多万常用的汉语词汇

stopword.dic:英文停用词库,不会建立在倒排索引中
quantifier.dic:特殊词库,计量单位

suffix.dic:特殊词库,行政、地理单位

surname.dic:特殊词库,百家姓

preposition.dic:特殊词库,语气词

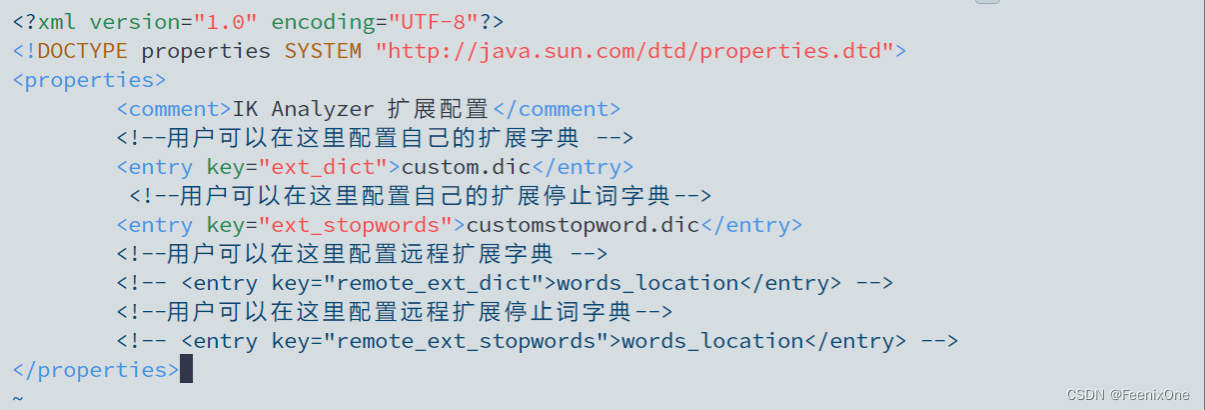
当某些文本无法被正确分词,可以自定义分词
vim custom.dic

vim customstopword.dic

vim IKAnalyzer.cfg.xml
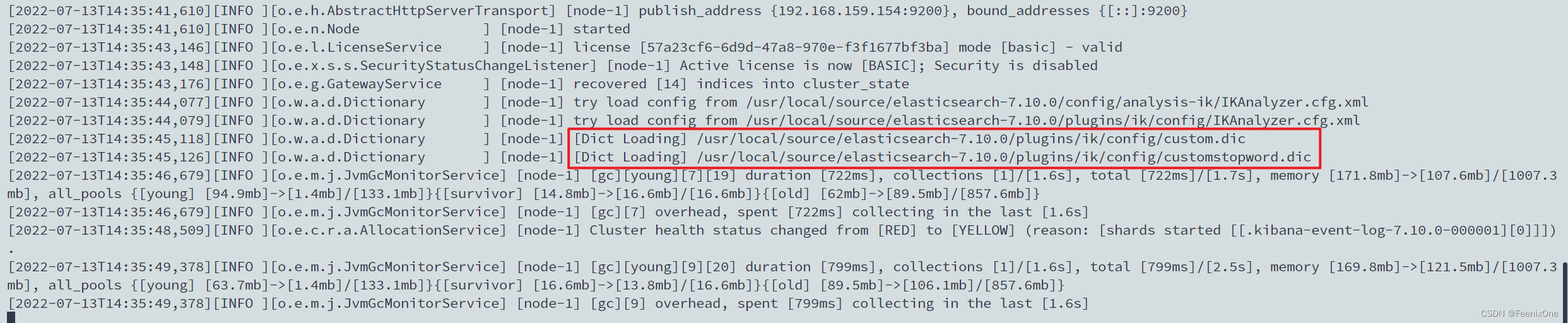
重启ES服务
热更新
基于远程词库的热更新
每次在修改完IK分词器的配置文件之后,都需要对ES服务进行重新启动
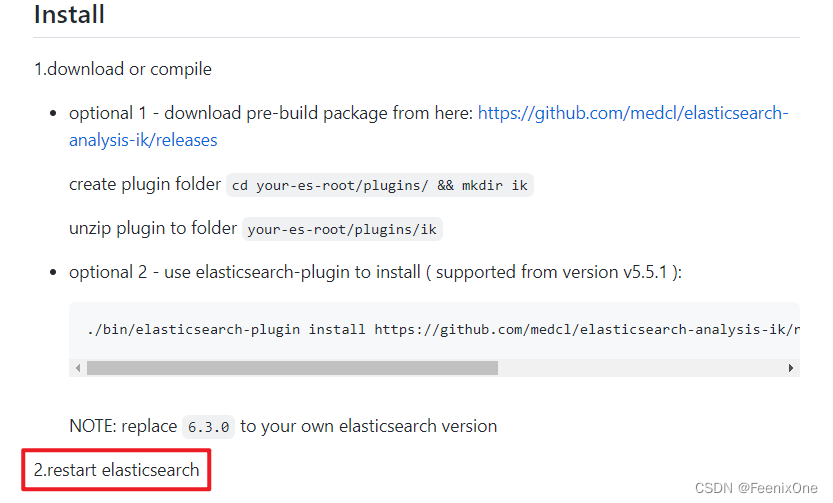
现在每天网络热门词汇层出不穷,按照词汇更新的速度频率经常重启ES服务显示是不可能的。在新版本中,IK分词器官方可以支持配置远程扩展字典和扩展停止词字典:
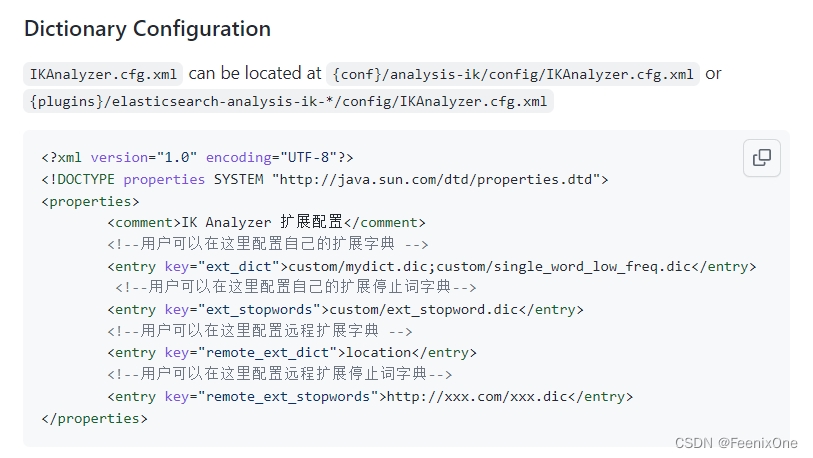
并且官方也提供了非常详细的使用步骤说明:

下面就按照官方提供的教程来试试:
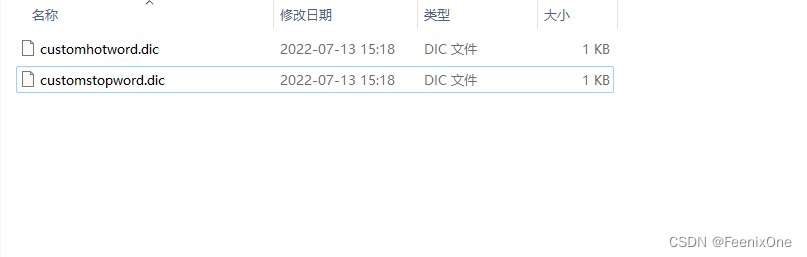
先定义好热词文件和停用词文件:
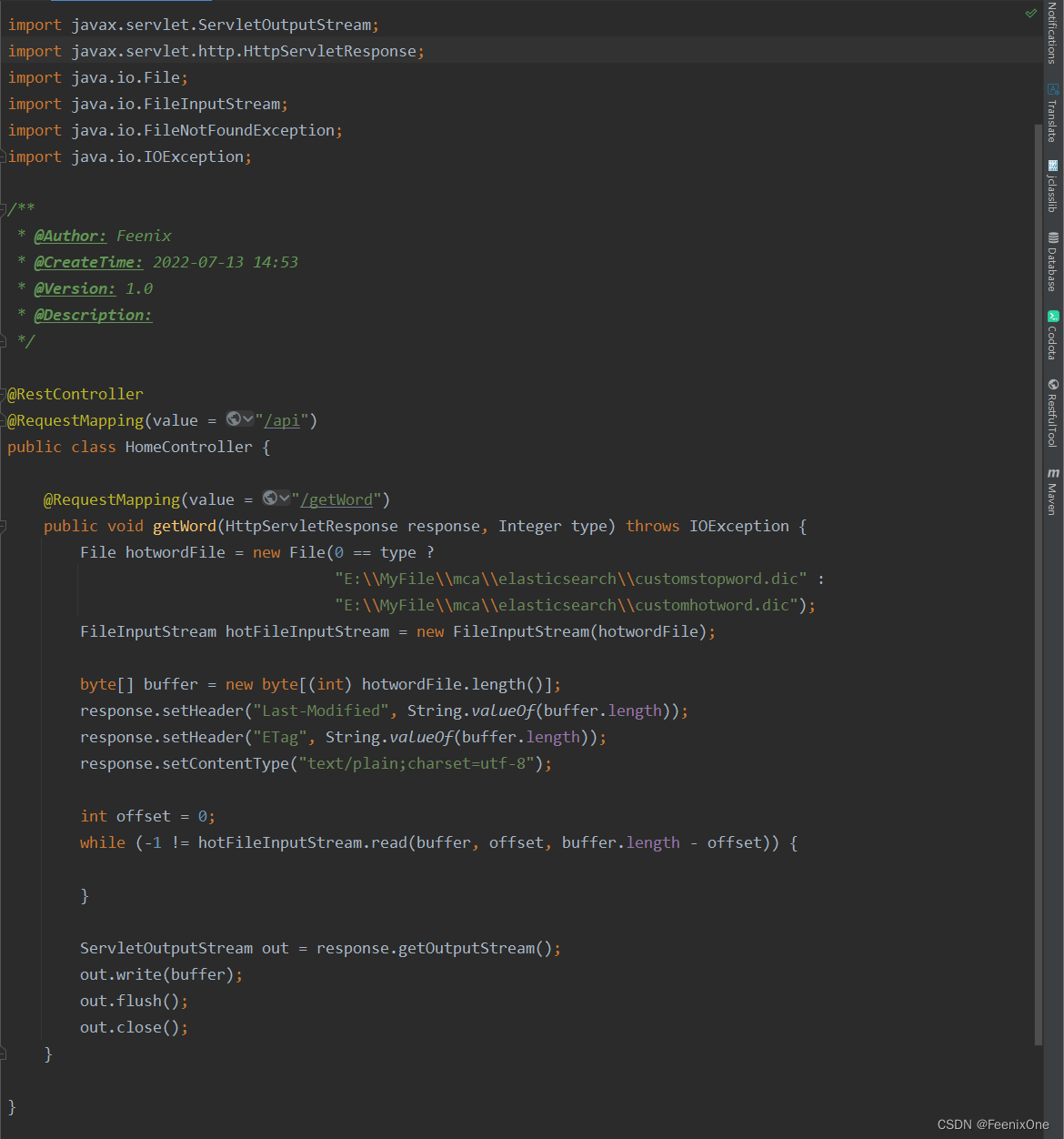
写段代码给读出来看看:
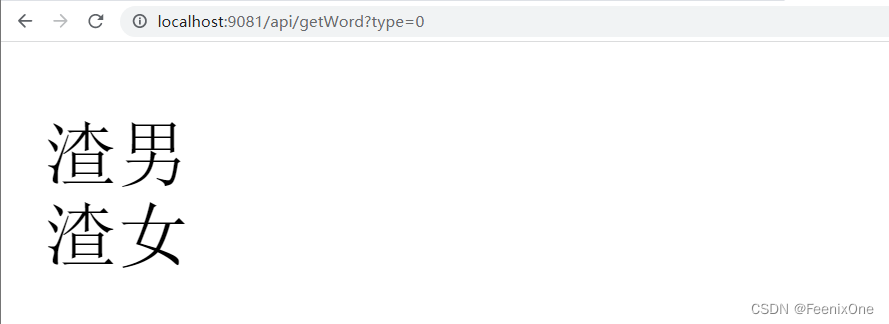
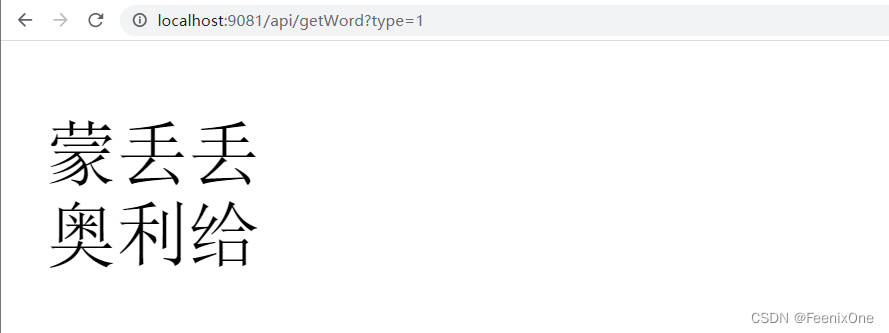
修改IK分词器配置文件:
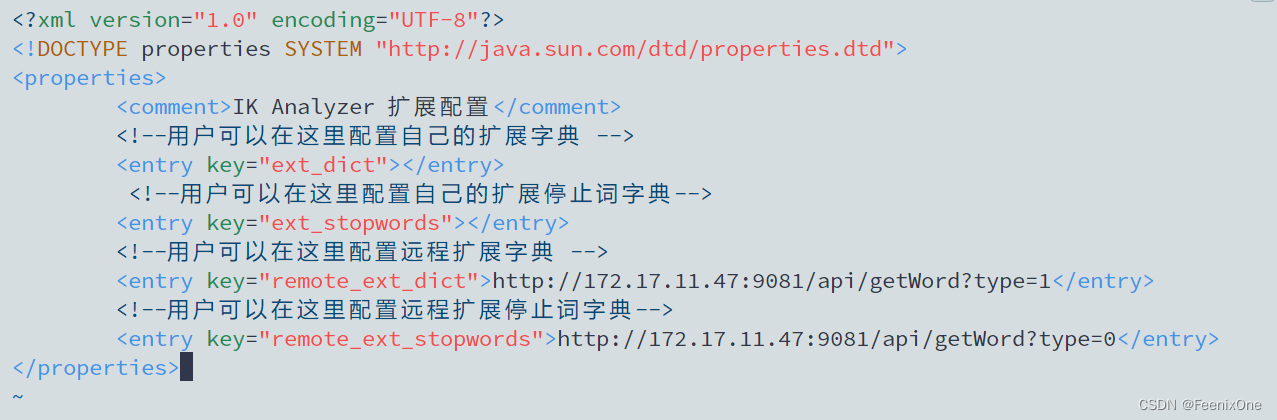
重启ES服务

验证分词器是否可以远程读词
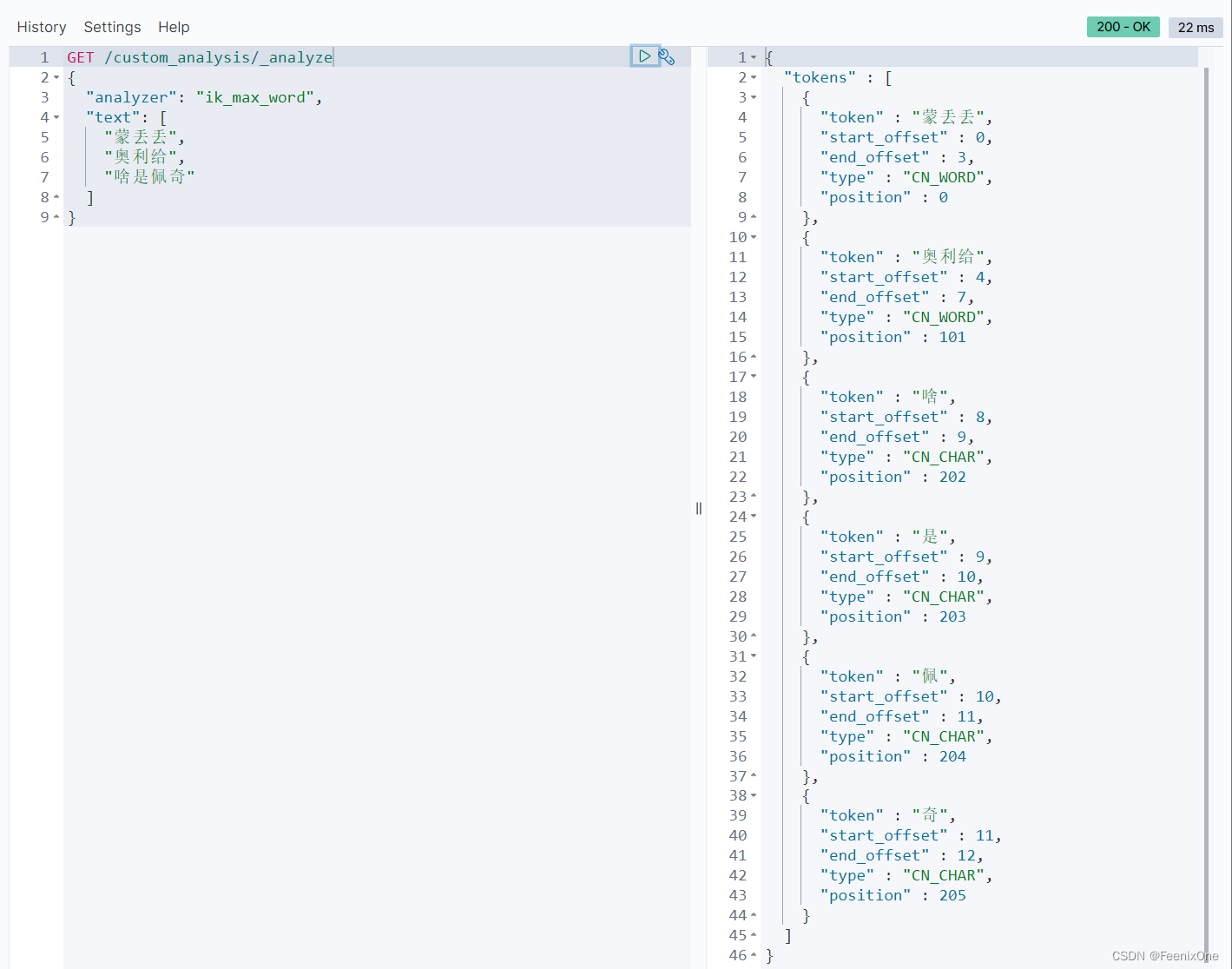
给热词文件新增一个热词
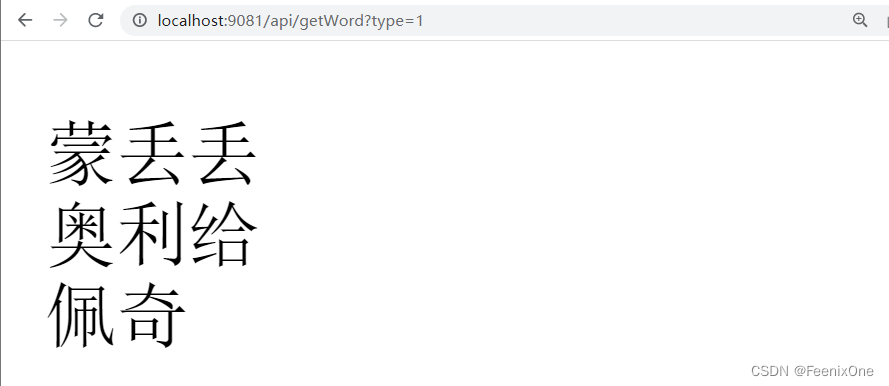
ES服务在未重启的基础上有读取到新增的热词


基于MySQL数据库的热更新
使用静态文件加远程访问的形式进行热词更新,虽然上手比较简单,但是缺点也非常明显:
1、词库的管理很不方便,必须直接操作磁盘文件,检索页很麻烦;
2、文件的读写没有专门的优化,词汇量大的情况下性能是个问题;
3、多一层接口的调用和网络传输;
IK访问MySQL数据库驱动下载:
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-versions.html
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-versions.html
IK分词器下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/(下载未经编译的.tar.gz压缩包)
在加载词典的方法中,添加一个连接数据库,从数据库中查询词语的操作即可。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/111909.html

