
在ES中准备先准备好相关的数据



以上的数据使用ES的查询语句 GET /jywx/_search 执行出的查询结果,和
GET /jywx/_search
{
“query”: {
“match_all”: {}
}
}
查询出的结果是一样的, “match_all”: {} 类似于MySQL的 where 1 = 1
上下文
使用query关键字进行检索,倾向于相关度搜索,需要计算评分,搜索是ES最核心的部分。
相关度评分 _score
相关度评分用于对搜索结果排序,评分越高认为结果越和搜索的预期值相关度越高,也就是越符合搜索预期值。在7.x之前评分默认使用TF/IDF算法,7.x之后默认使用BM25算法。
元数据 _source
1、禁用_source
优点:可节省存储开销
缺点:不支持_update、update_by_query、reindex API
不支持高亮
不支持reindex、更改mapping分析器和版本升级
通过查看索引时使用的原始文档来调整查询或聚合的功能
将来有可能自动修复索引损坏
如果只是为了节省磁盘,可以使用压缩索引,比禁用_source会更好。
GET /jywx/_search
{
“_source”: false,
“query”: {
“match_all”: {}
}
}
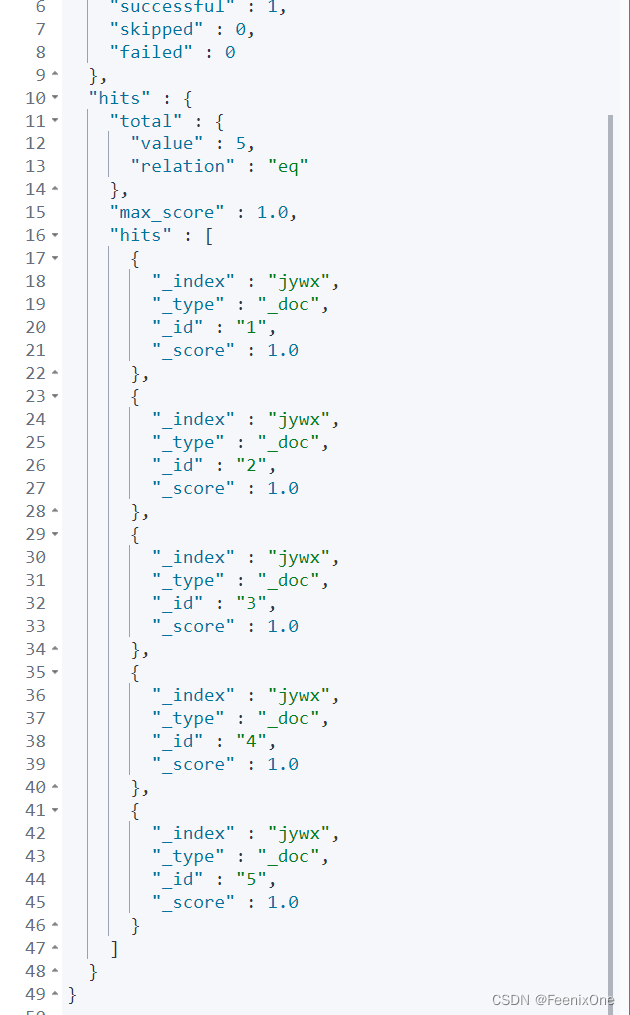
通过“_source”: false的设置,查询的结果集中就会不包含_source的数据。
2、数据源过滤器
includes:结果集中返回那些field;
excludes:结果集中不返回那些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表索引不存在;
PUT /jywx2
{
“mappings”: {
“_source”: {
“includes”:[“name”, “age”],
“excludes”:[“desc”, “weapon”]
}
}
}
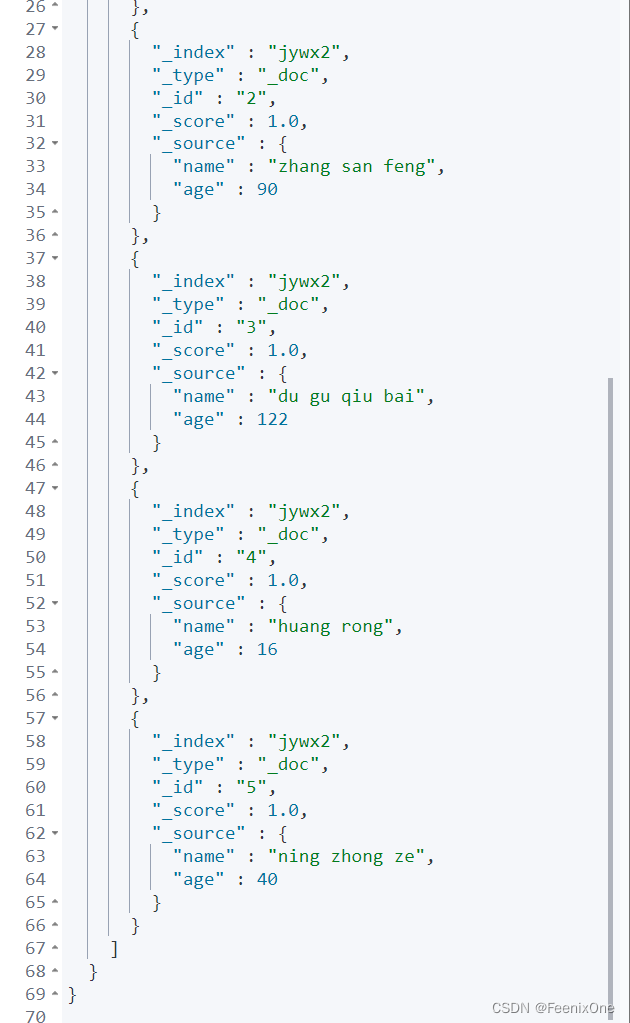
其实在mapping中指定_source作为数据过滤源并不推荐,因为mapping是不可变的。也就是说一旦在创建的时候在mapping中指定了,后续则没办法进行修改,被隐藏的元数据永远不可显示。比较推荐在查询的时候进行动态的指定:
GET /jywx/_search
{
“_source”: [“name”, “age”],
“query”: {
“match_all”: {}
}
}
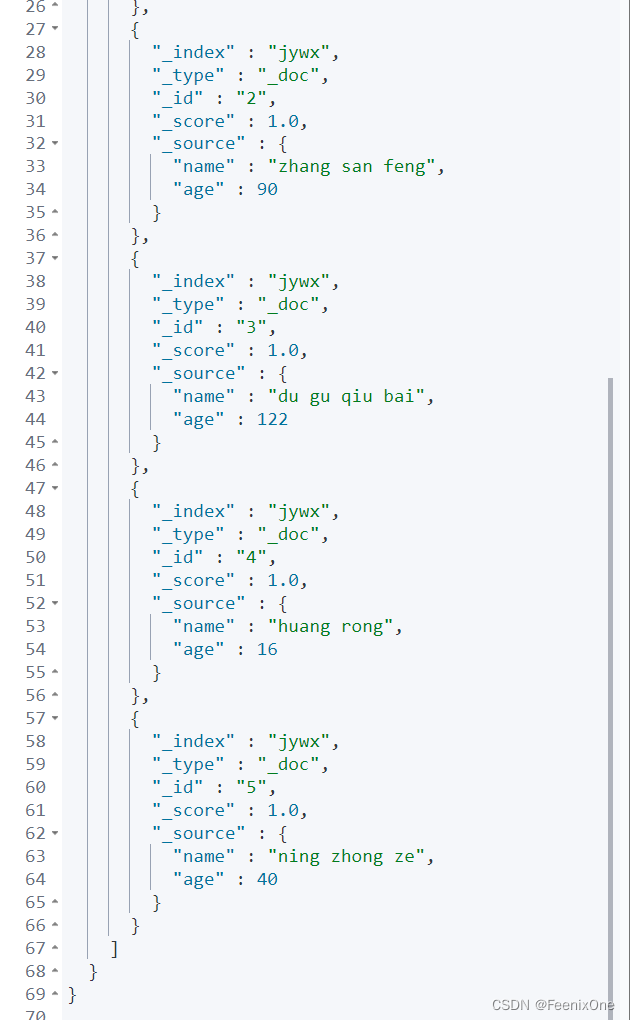
除了includes和excludes之外,_source常用过滤规则还有:
“_source”:”false”
“_source”:”x.*”(x是对象,*是x中的属性,作为通配符使用)
“_source”:[“x1.*”, “x2.*”]
Query String
带参数查询(精准匹配)
GET /jywx/_search?q=name:xie xun
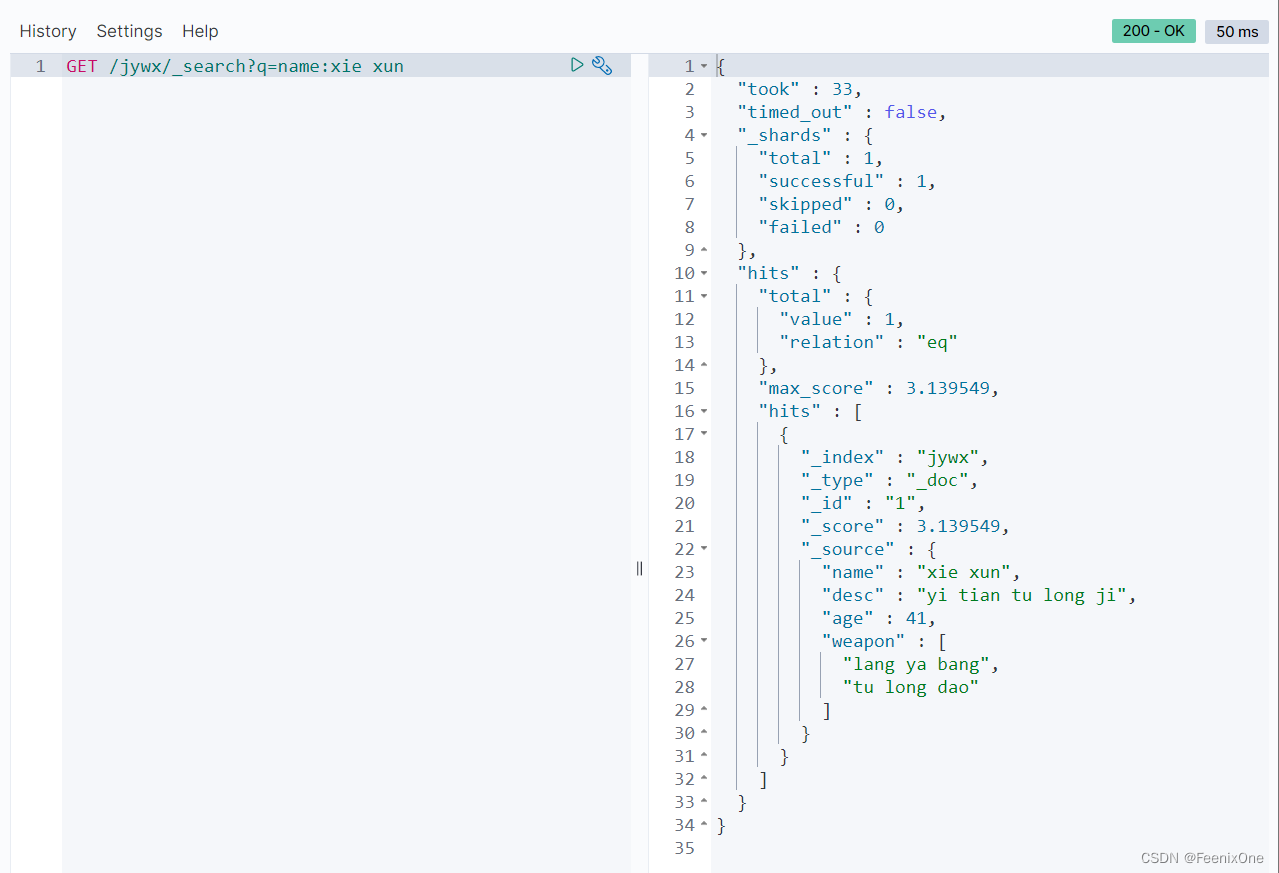
当没有指定匹配值的field的时候,默认将所有值相同的字段的记录都检索出
GET /jywx/_search?q=yi tian tu long ji

但是如果将field作为索引使用禁用掉的话,则无法通过这个field检索出数据
PUT /jywx3
{
“mappings”: {
“properties”: {
“desc”:{
“type”: “text”,
“index”: false
}
}
}
}
分页:
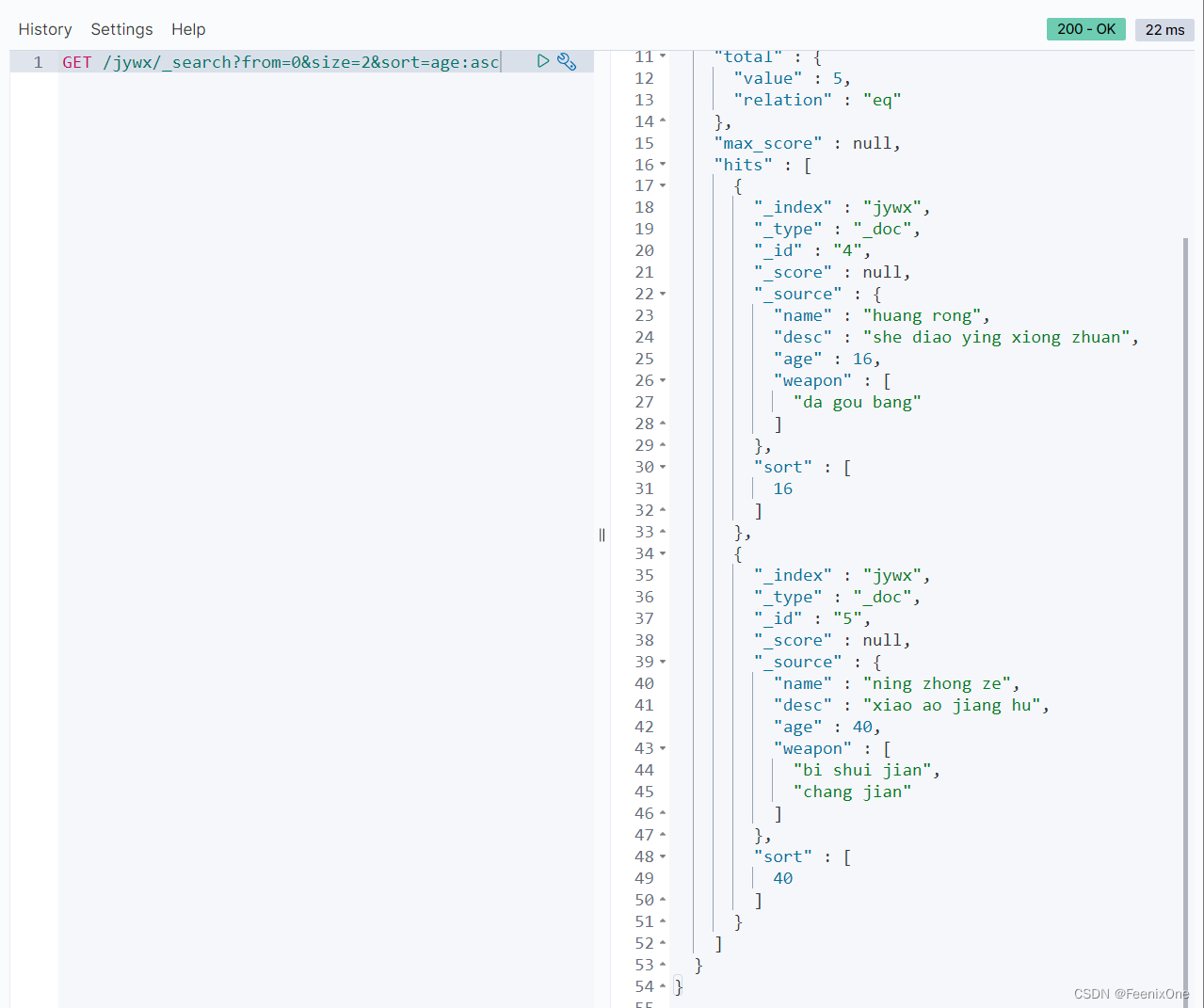
GET /jywx/_search?from=0&size=2&sort=age:asc
Fulltext Query 全文检索
match:匹配包含某个term的子句
GET /jywx/_search
{
“query”: {
“match“: {
“FIELD”: “TEXT”
}
}
}
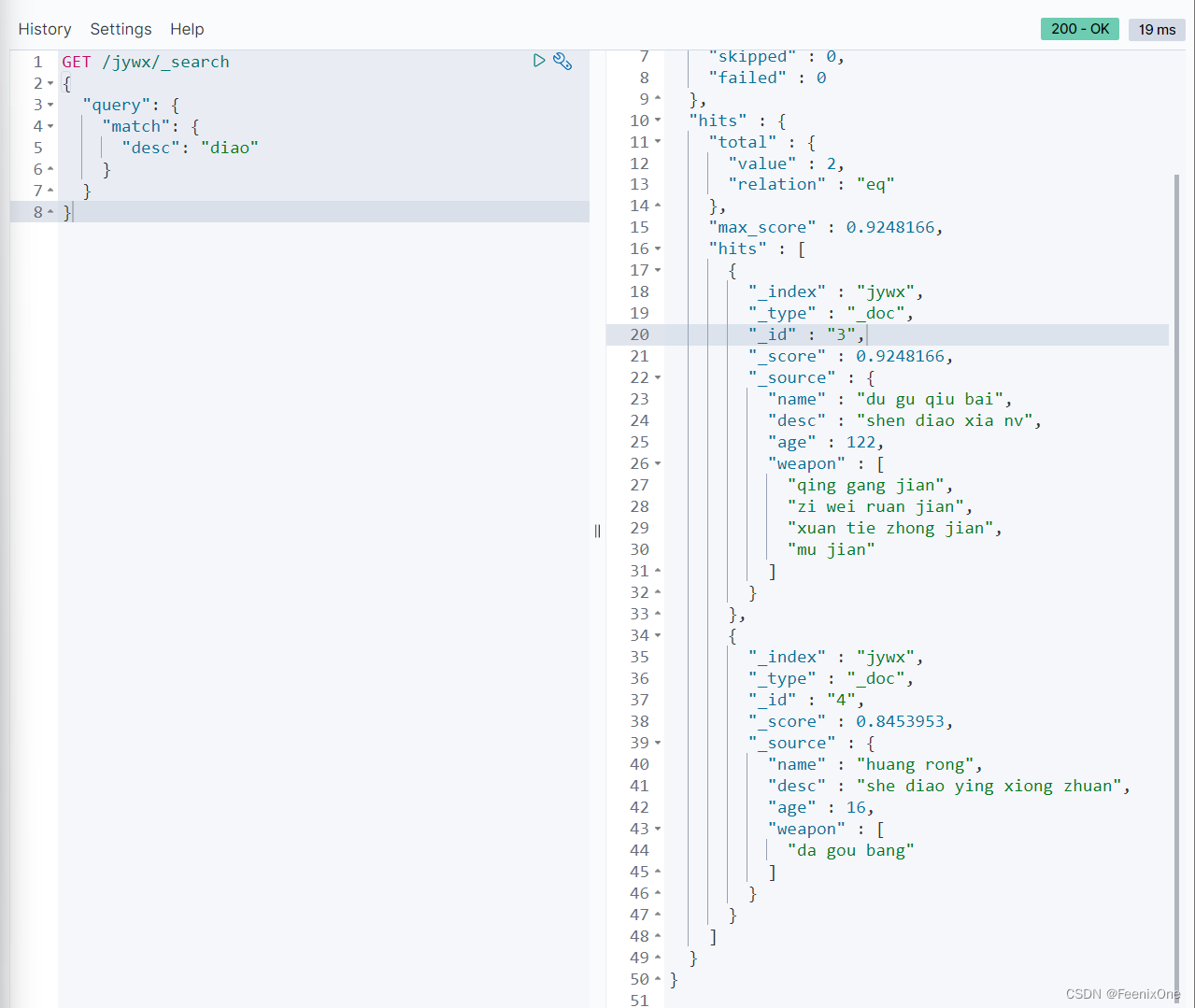
查询的结果会根据_score评分来进行排序展示,这个评分的逻辑后面会详细讲解。
match_all:匹配所有结果的子句
GET /jywx/_search
{
“query”: {
“match_all“: {}
}
}
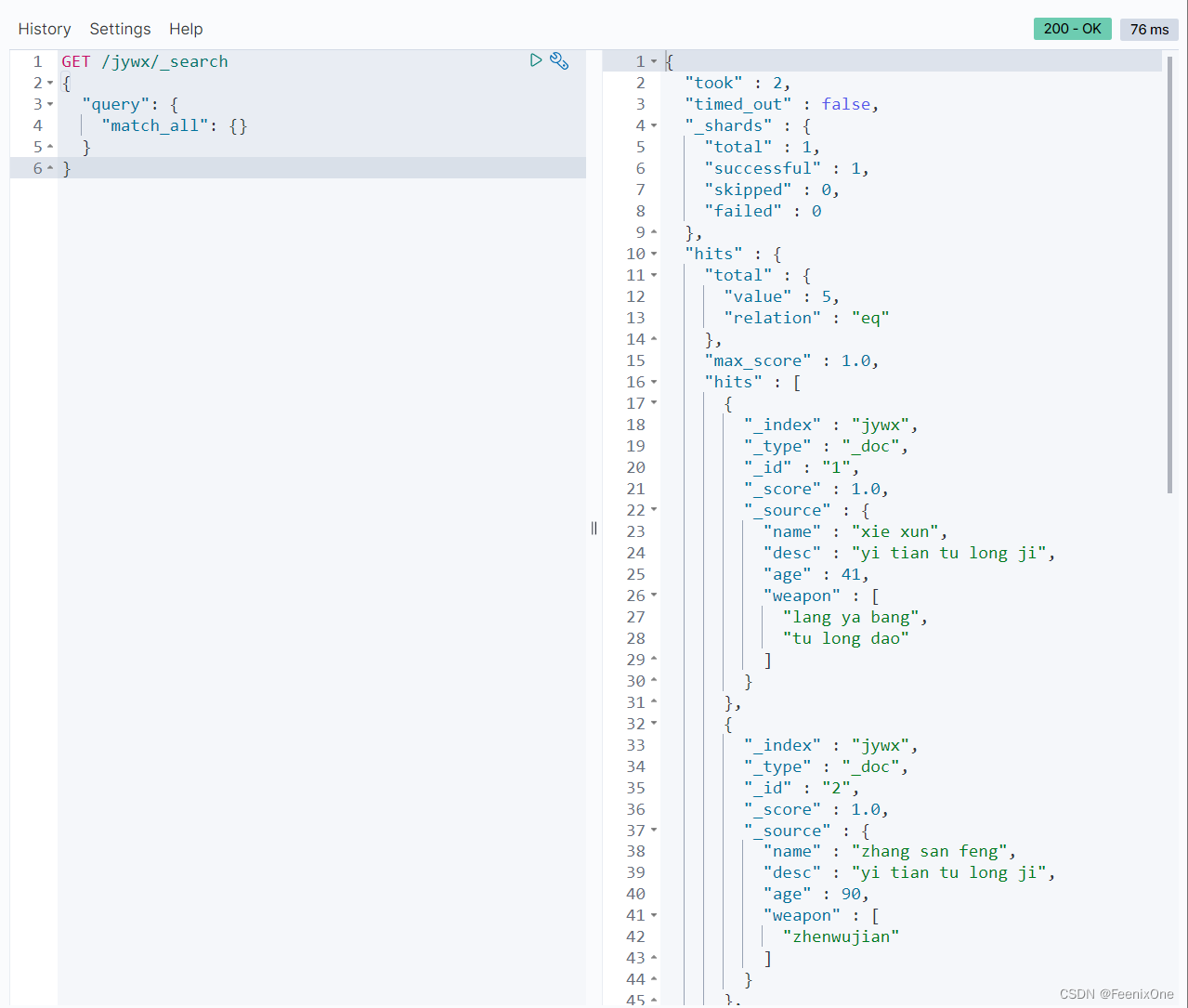
查询jywx索引下的所有数据。
multi_match:多字段条件
GET /jywx/_search
{
“query”: {
“multi_match“: {
“query”: “”,
“fields”: []
}
}
}
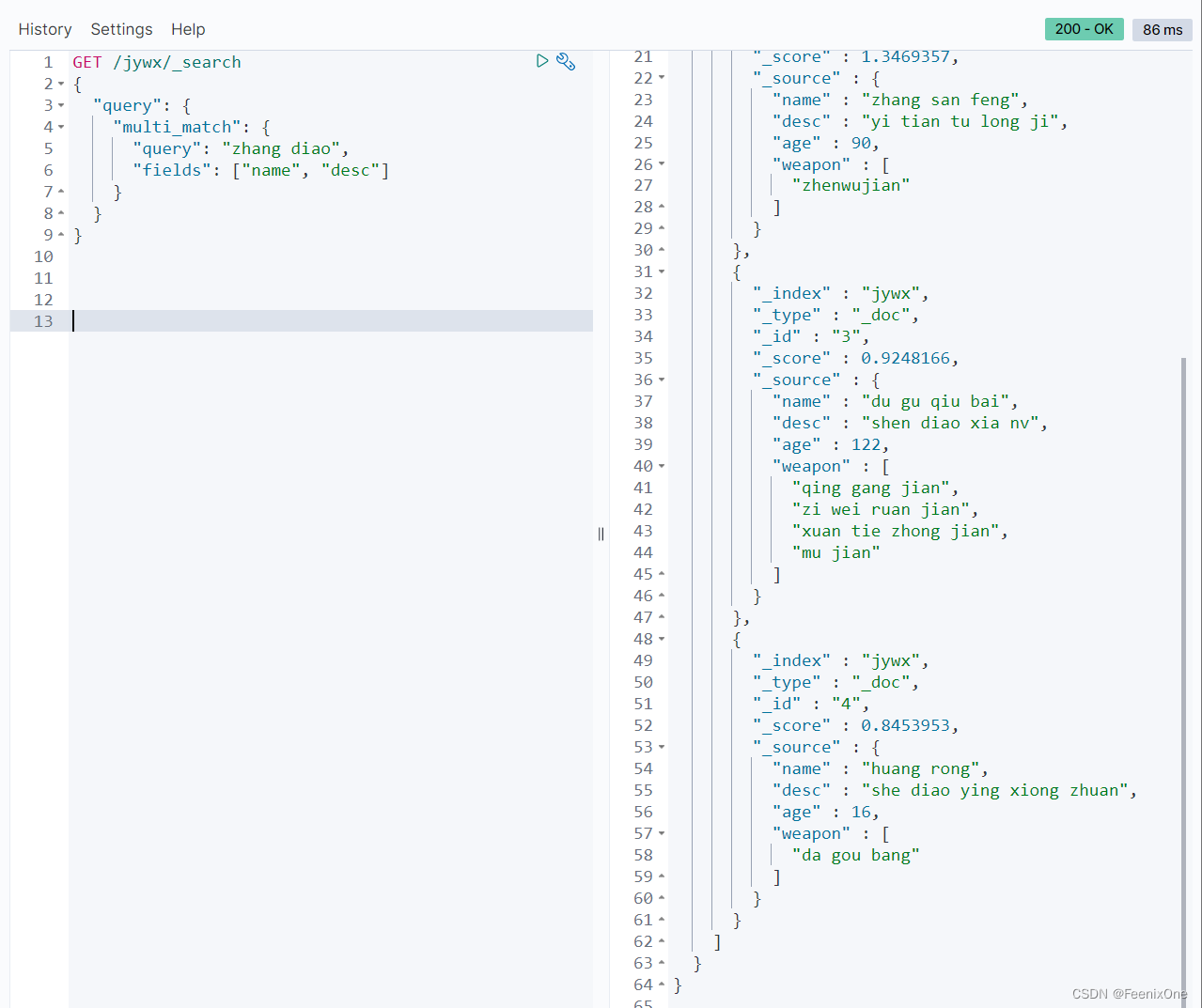
在name和desc两个字段,有任意一个字段匹配到zhang或者diao的,都会被检索出来。
类似于MySQL中的:
select * from jywx where name = ‘zhang’ or name = ‘diao’ or desc = ‘zhang’ or desc = ‘diao’
match_phrase:短语查询,匹配包含查询短语中所有词项的子句
GET /jywx/_search
{
“query”: {
“match_phrase“: {
“FIELD”: “PHRASE”
}
}
}
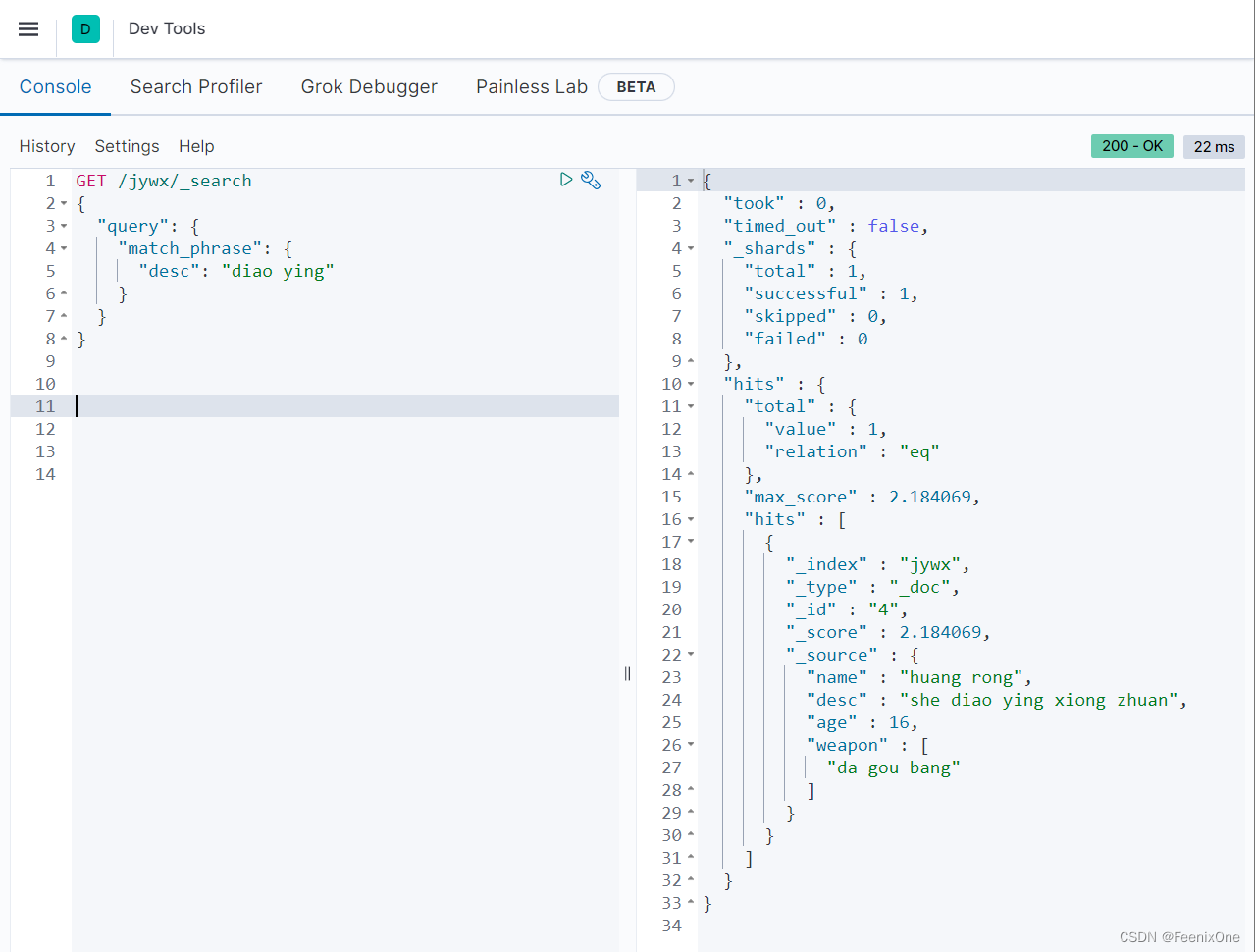
desc字段中需要包含diao和ying,并且顺序不可乱,才可被检索出。
exact match 精准匹配
term:匹配和搜索词项完全相等的结果
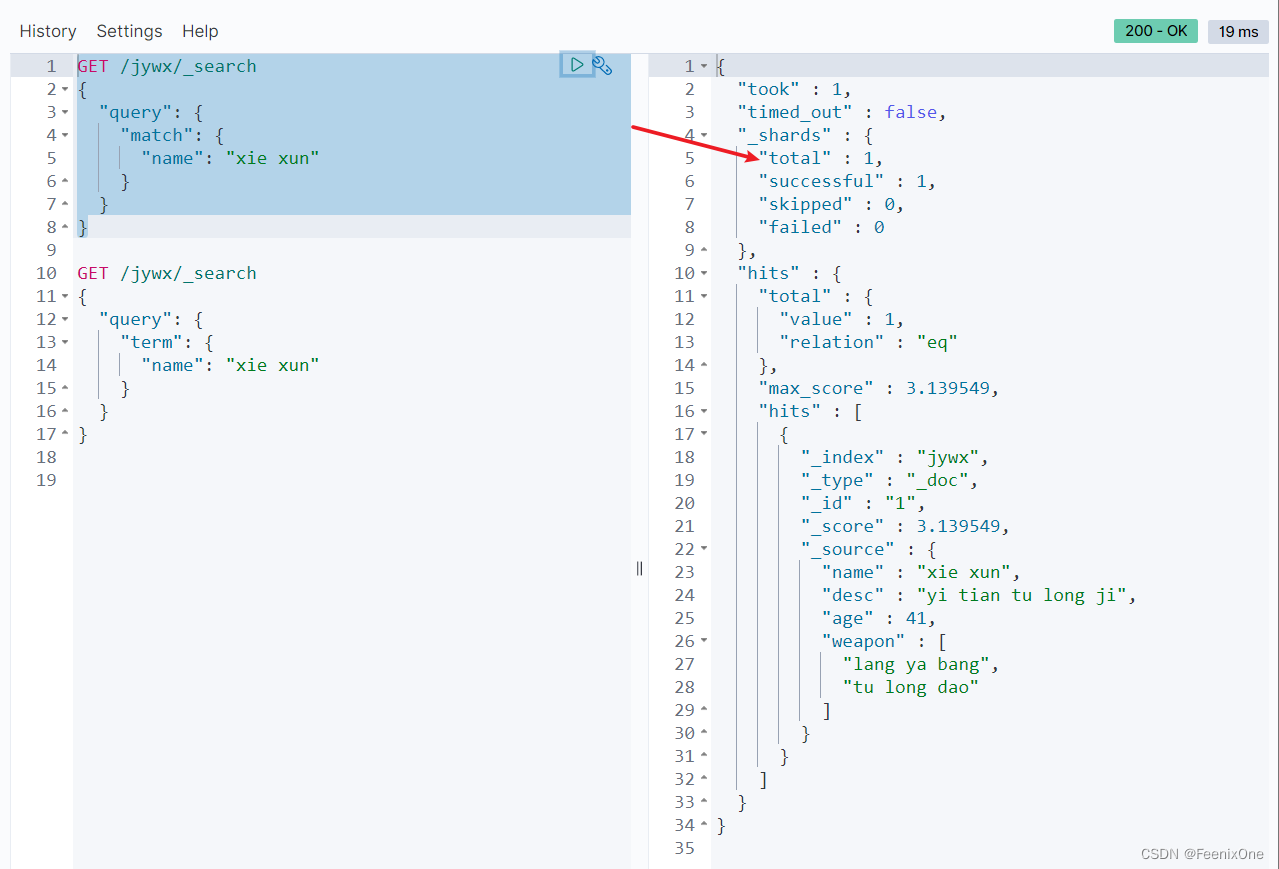
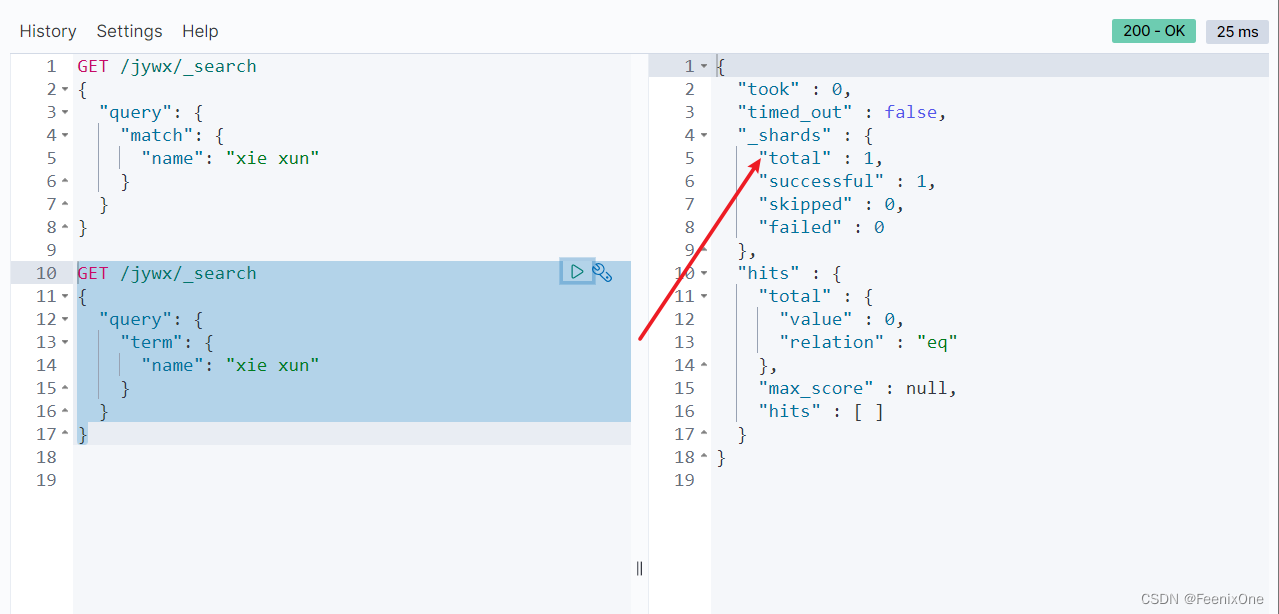
因为xie xun在创建的时候被分词了,term检索要求不能被分词,所以xie xun作为一个完整的字段无法被分词后的xie xun匹配上,搜索结果就是没有结果。
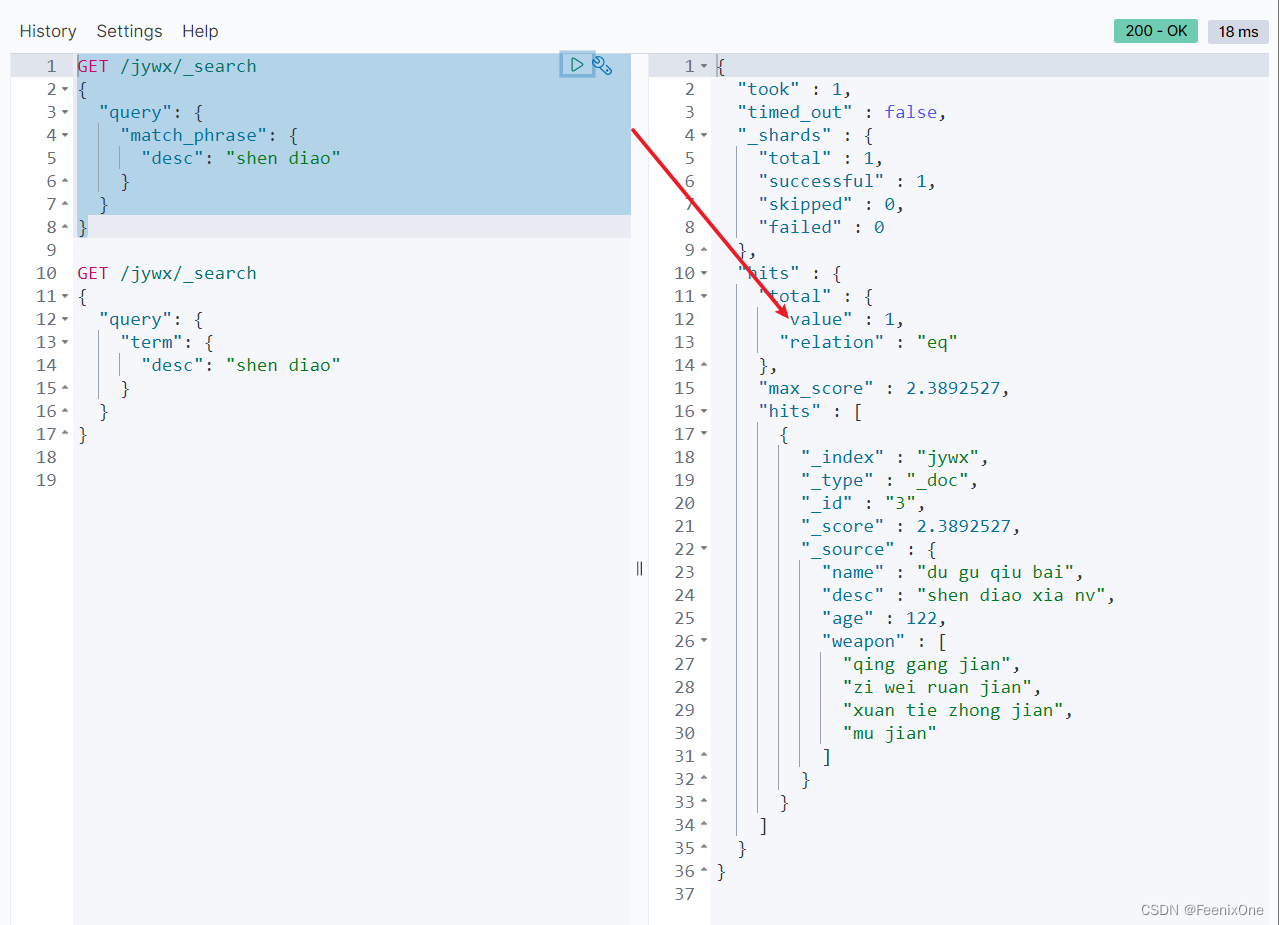
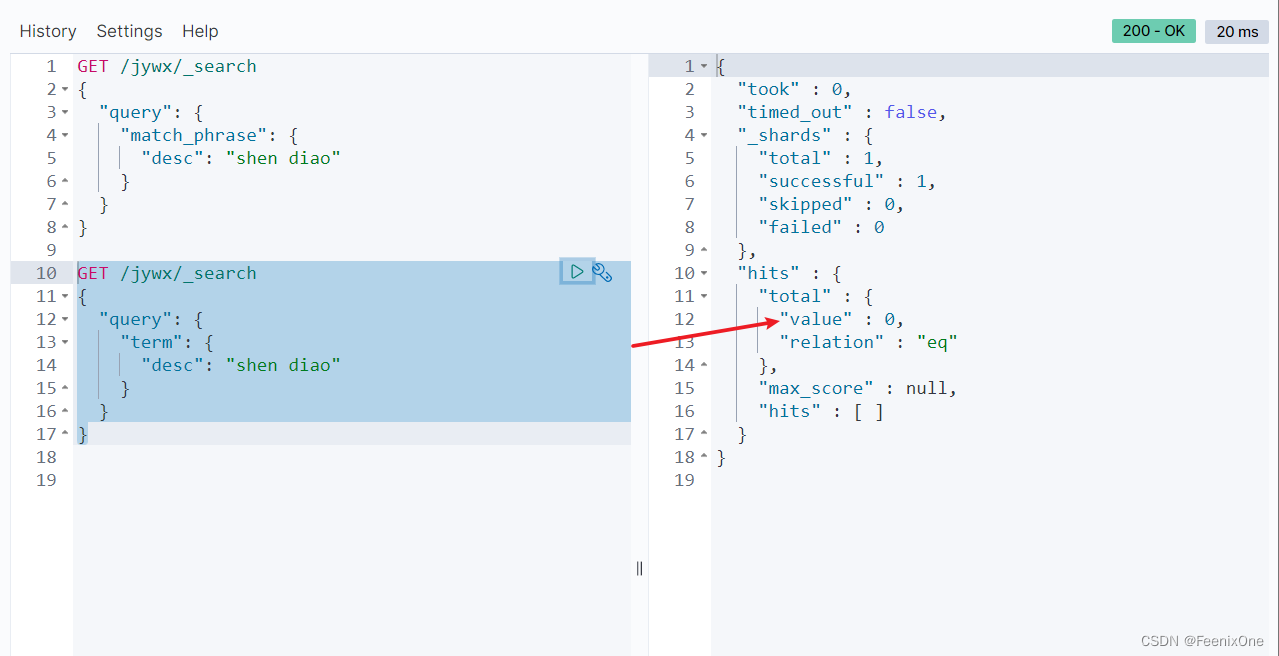
term和match_phrase的区别:
match_phrase会将检索关键词分词,match_phrase的分词结果必须在被检索字段的分词中都包含,且顺序必须相同,而且默认必须都是连续的,term搜索不会将搜索词分词。
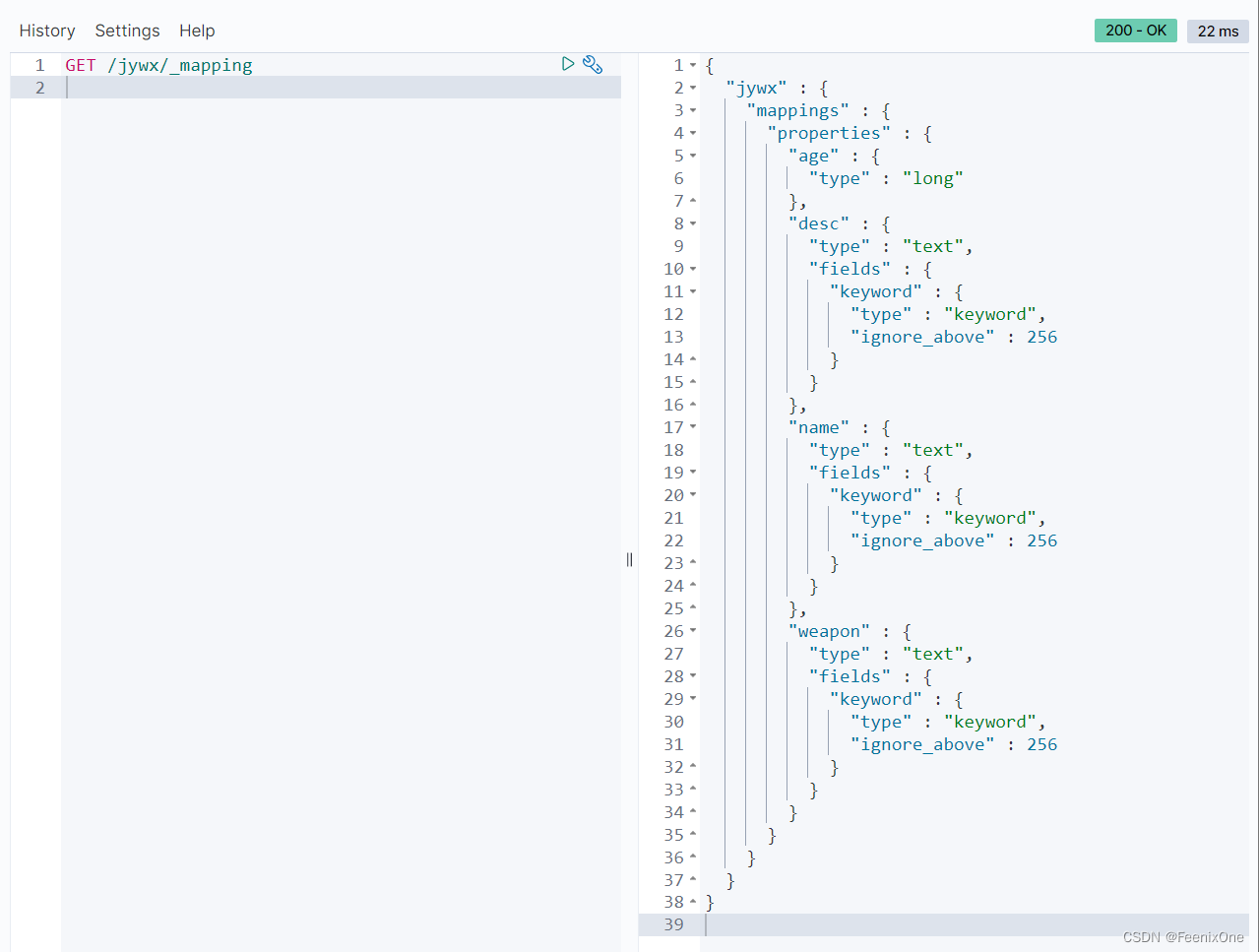
term和keyword的区别:
term是对于搜索词不分词,keyword是字段类型,是对于元数据中的字段值不分词。
terms:数组中的条件有一个匹配即可
GET /jywx/_search
{
“query”: {
“terms“: {
“FIELD”: [
“VALUE1”,
“VALUE2”
]
}
}
}
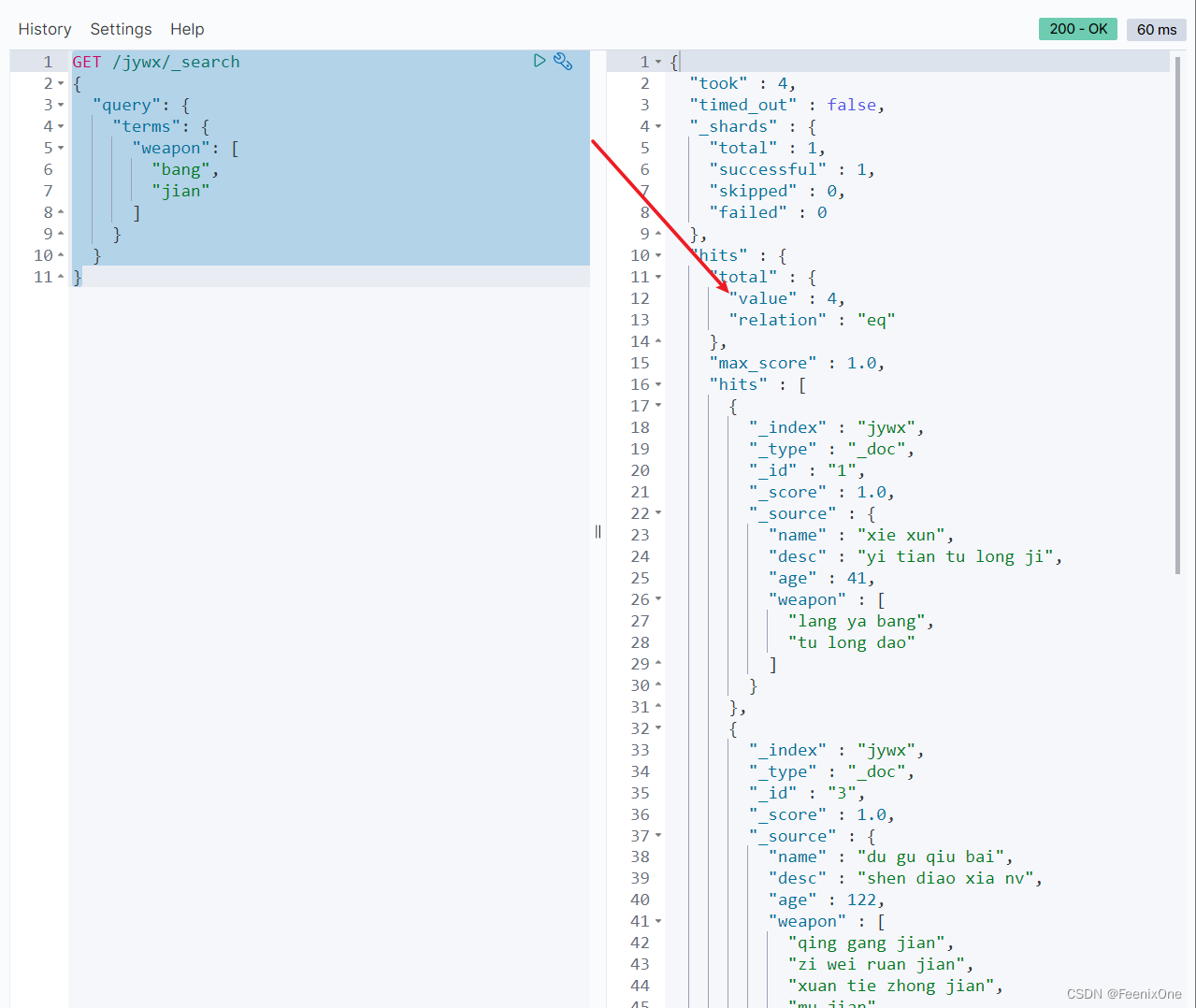
没有匹配上的那条数据是”weapon”:[“zhenwujian”],zhenwujian中的jian没有被分词,也再次证明了被分词后的数据不会被item关键字检索出。
range:范围查询
GET /jywx/_search
{
“query”: {
“range“: {
“FIELD”: {
“gte”: xx,
“lte”: xx
}
}
}
}
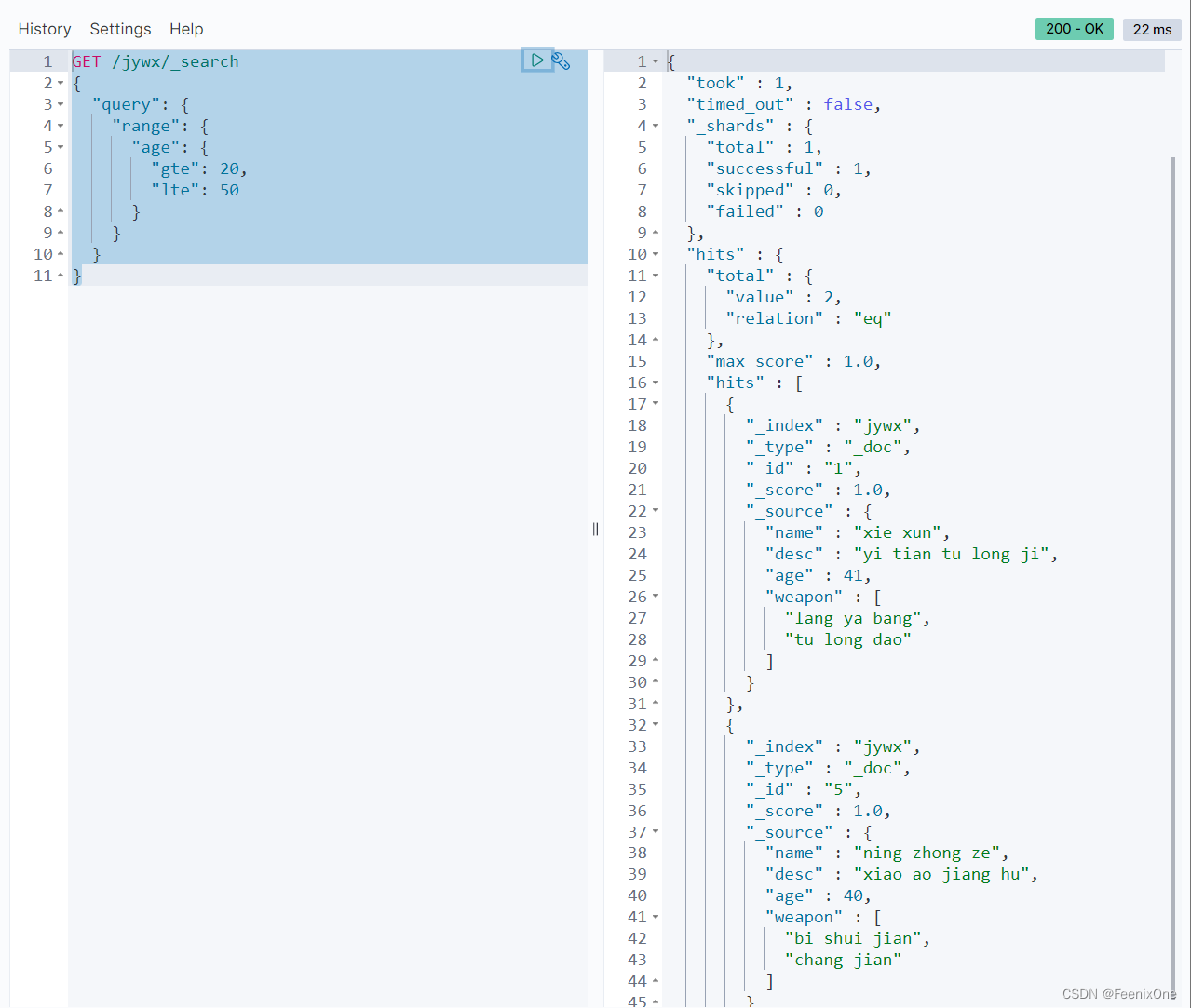
range的范围匹配不仅仅是普通的数字类型,对于日期类型的数值也同样支持范围检索,而且日期还支持某些特定的函数:
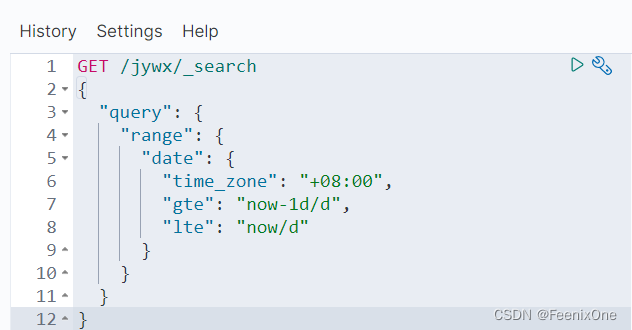
“time_zone”: “+08:00” // 时区不一致时,通过time_zone来调整时区间的时差
“gte”: “now-1d/d” // 大于等于前一天
“lte”: “now/d” // 小于等于今天
/d的意思是以天作为单位。
filter 过滤器
filter本质也是一种查询,和query的主要区别在于:filter是以结果为导向,而query是以过程为导向。说直白点就是query更倾向于当前文档和语句的相关度,而filter则是更倾向于当前查询的条件和文档是不是相符。在查询的过程中,query要对每一个查询的结果计算相关度得分,并以得分作为排序条件;而filter不会计算什么得分,查询结果也不会按照什么得分去排序,而且filter也有相关的缓存机制,这也就意味filter的查询性能要高于query。
GET /jywx/_search
{
“query”: {
“constant_score“: {
“filter“: {},
“boost“: 1.0
}
}
}
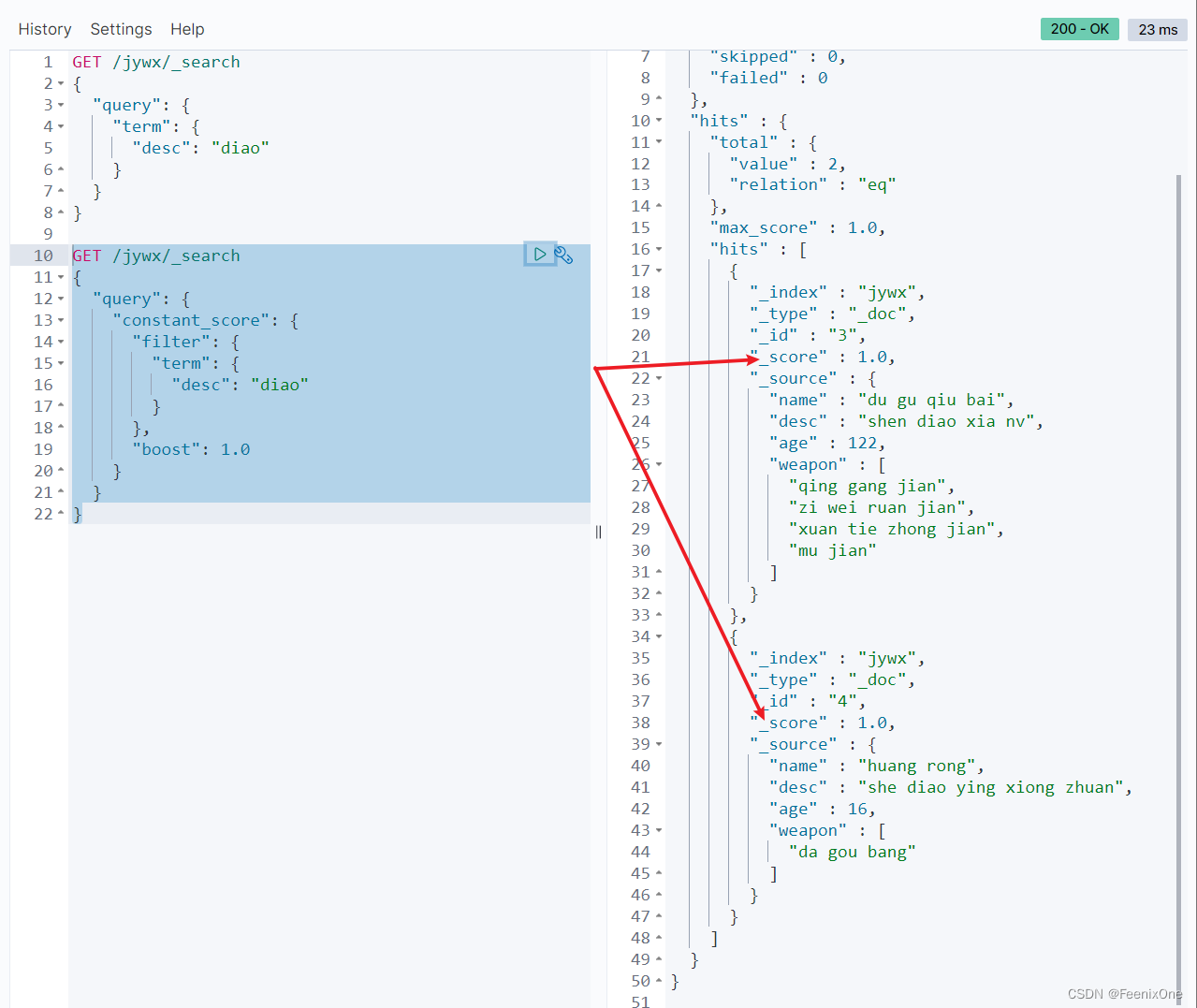
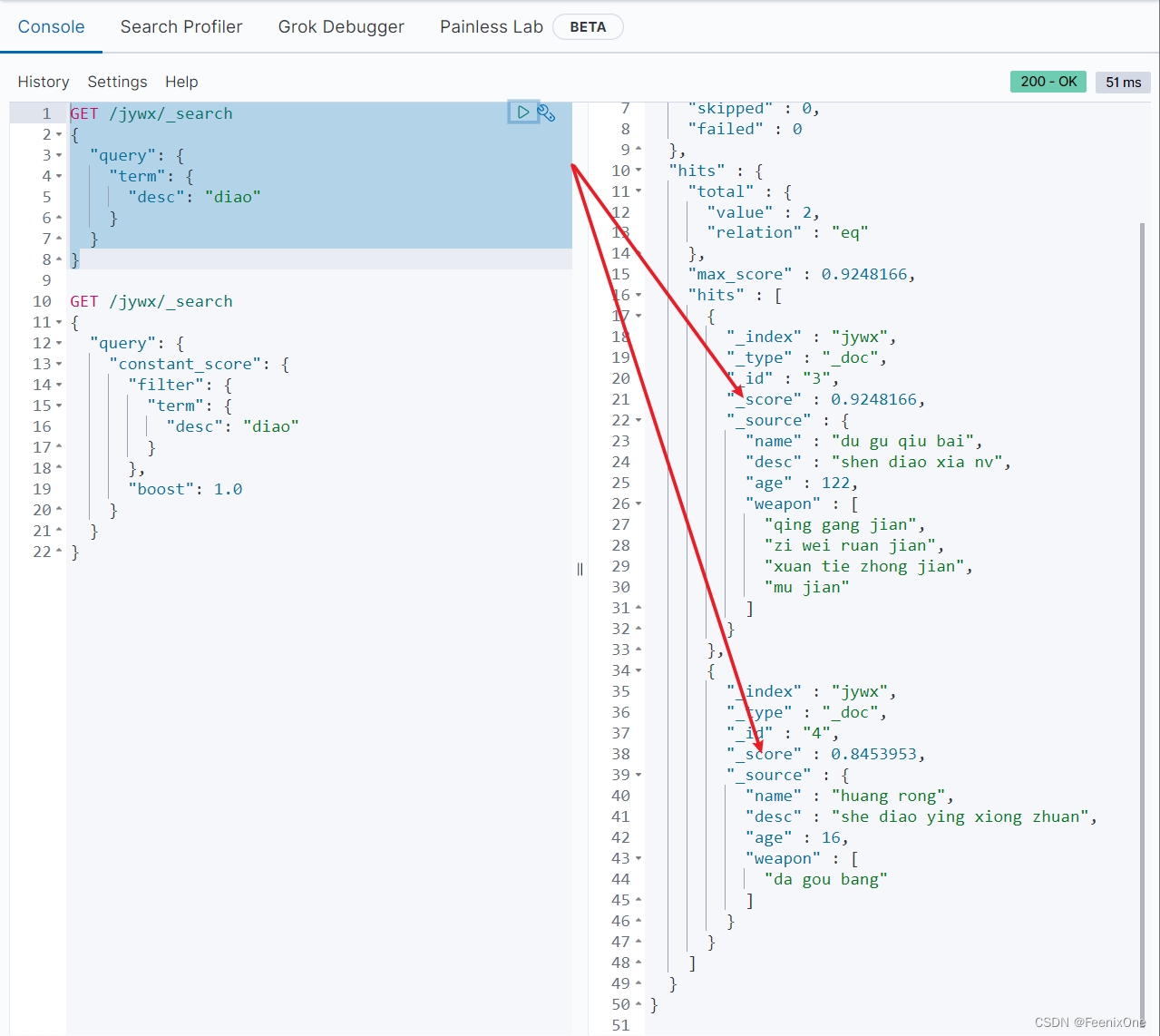
不是说filter不会计算结果的得分吗,怎么还会有_score这个值,这个值正是在查询的时候手动指定的”boost”: 1.0,而不是filter自身计算出的。
bool query 组合查询
可以组合多个查询条件,bool query也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值
must:必须满足查询,必须出现在匹配的文档中,并将有助于得分;
filter:不计算相关度得分,cache查询必须出现在匹配的文档中,但是不像must查询的分数将会被忽略。filter查询在filter上下文中执行,查询语句可能会被缓存;
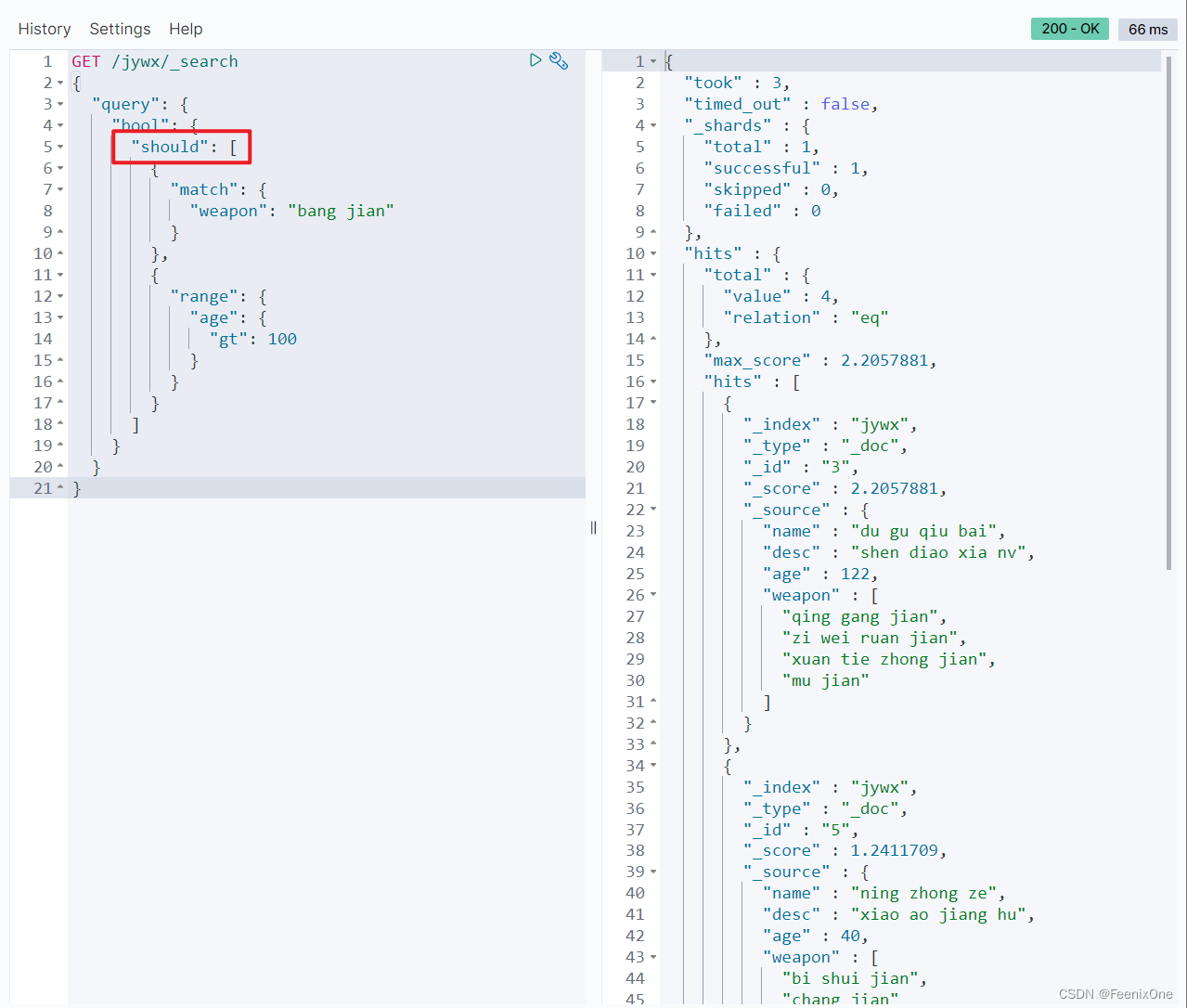
should:or查询出现在匹配的文档中;
must_not:不计算相关度得分,not查询不得出现在匹配的文档中,查询在过滤器上下文中执行,也就是说没有计算得分,并且查询会被缓存。
minimum_should_match:参数指定should返回的文档必须匹配的查询的子句的数量或百分比,如果bool query包含至少一个should查询,而没有must或filter子句,则默认值为1,否则为0。
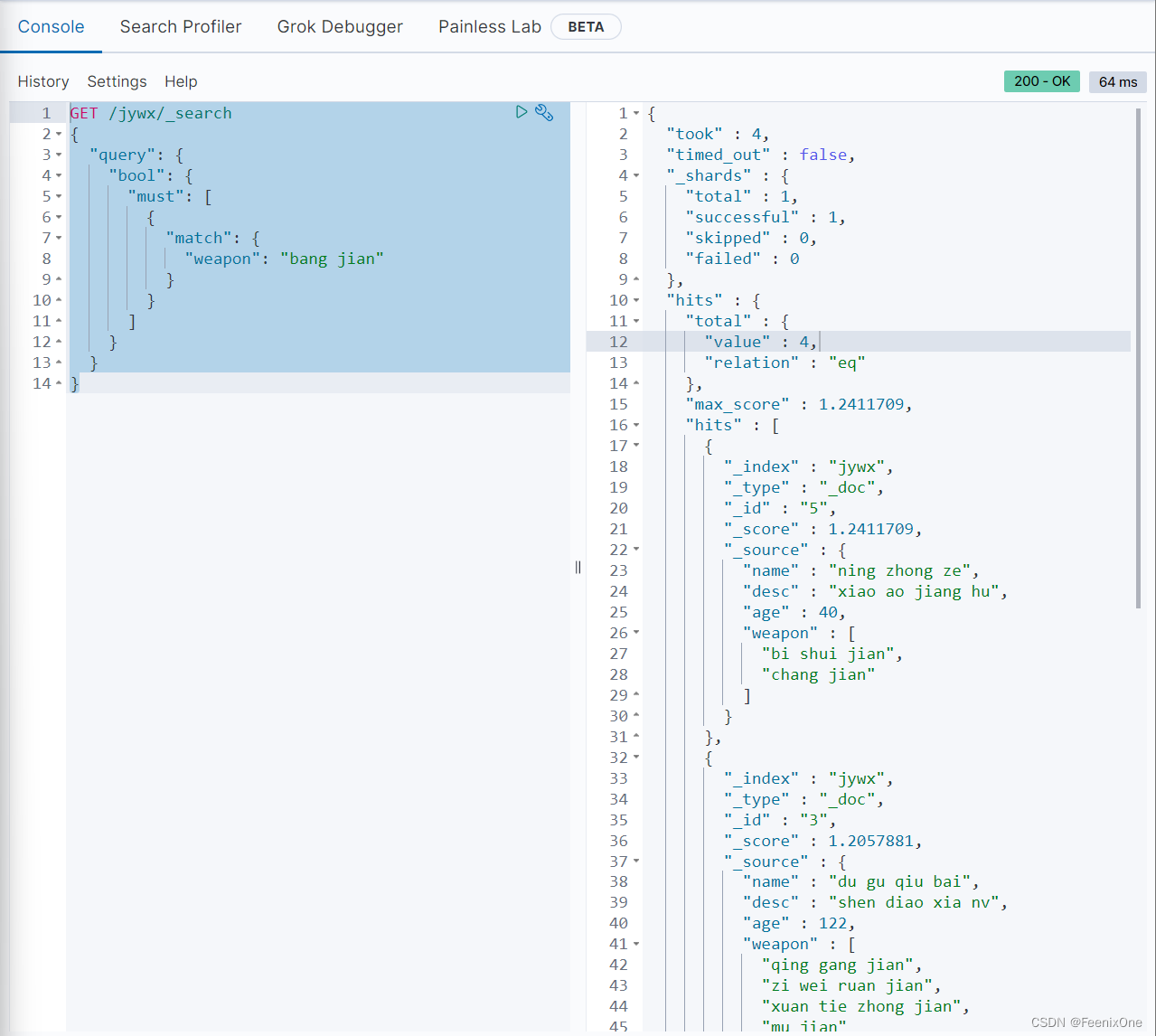
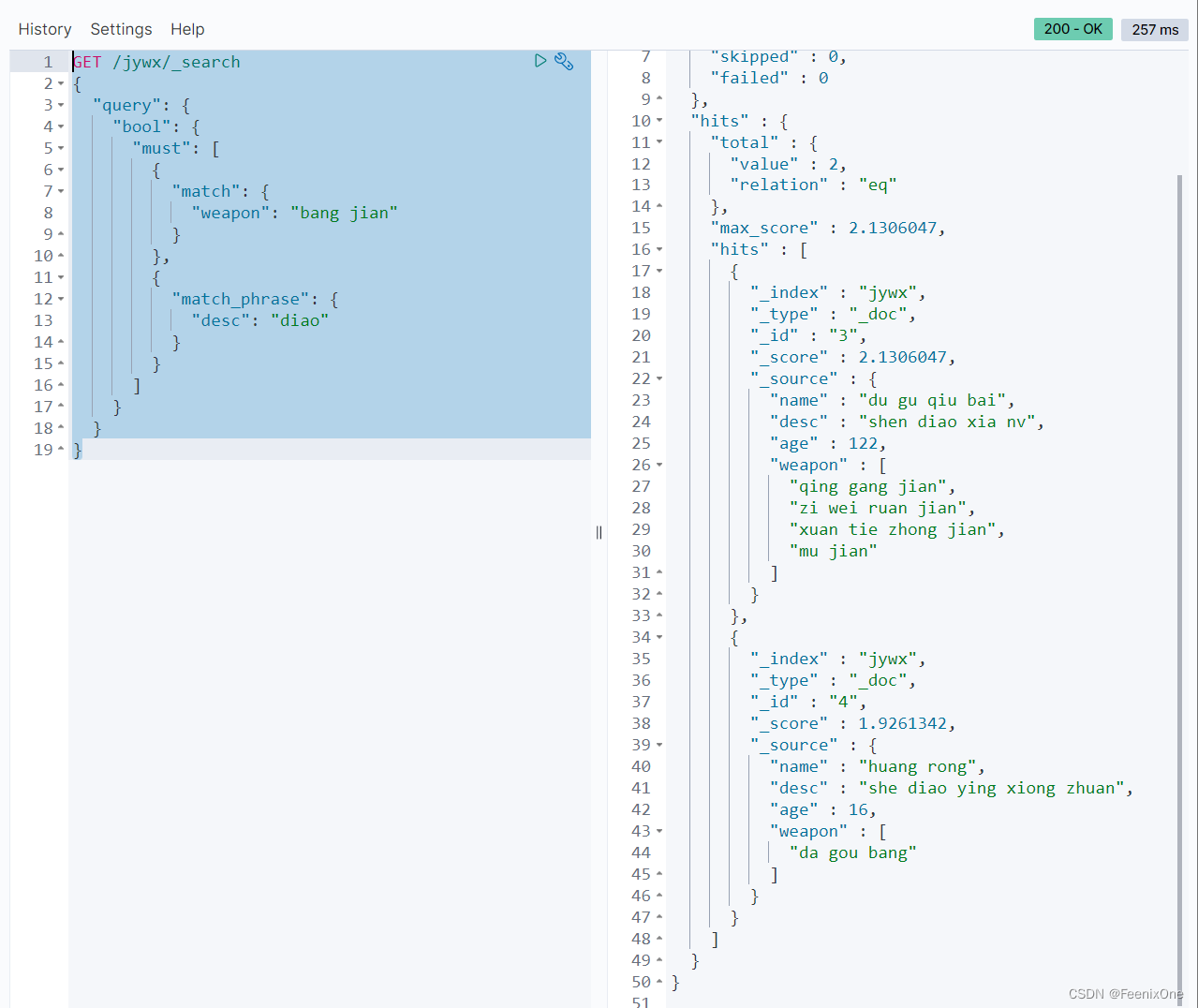
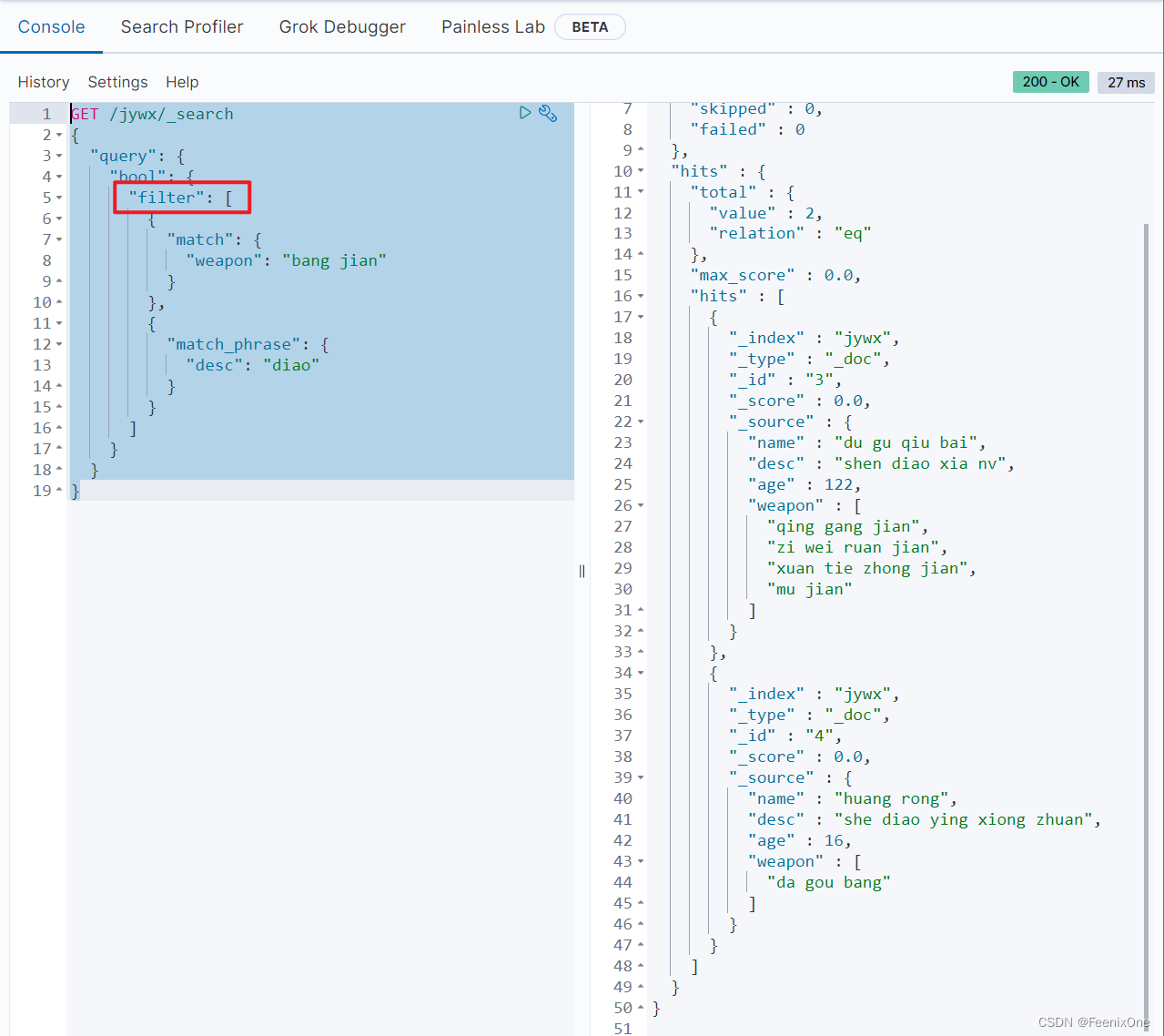
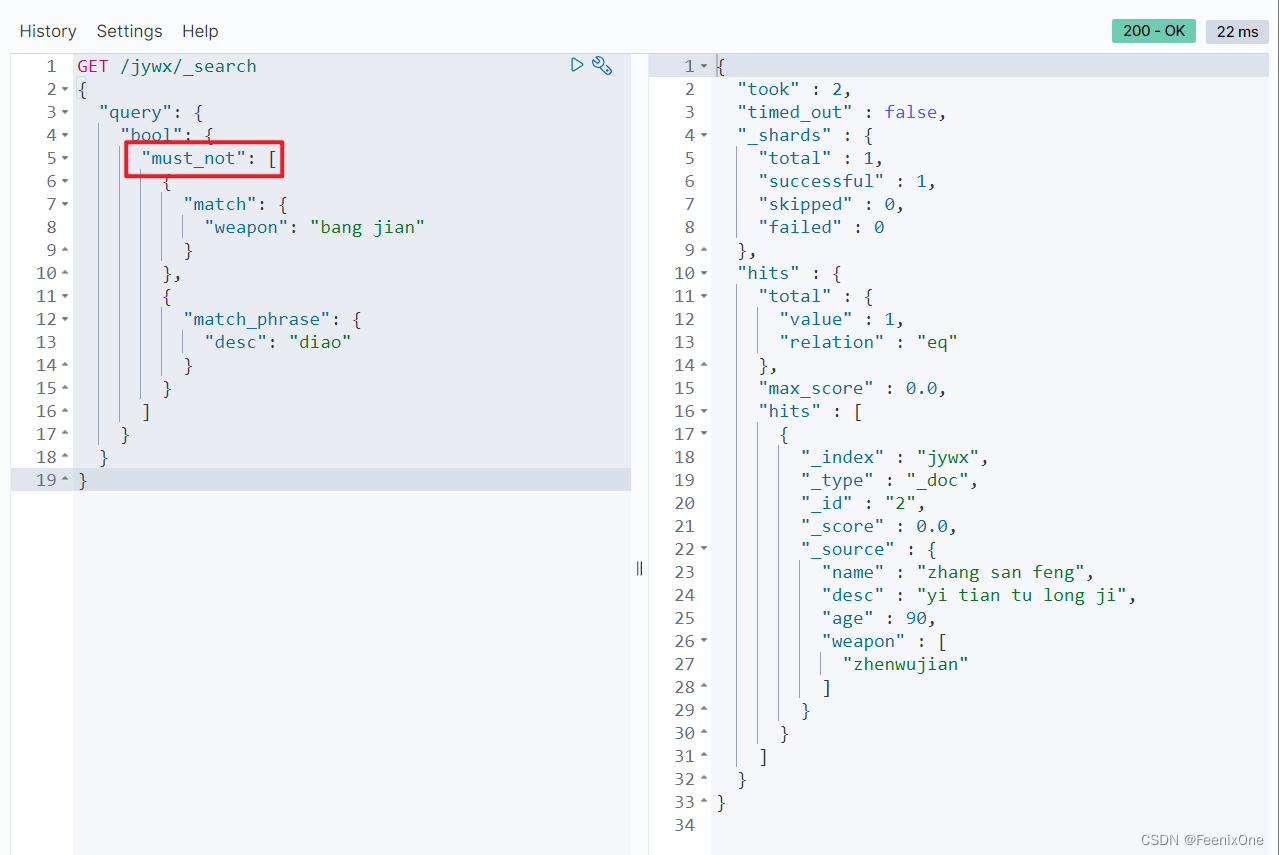
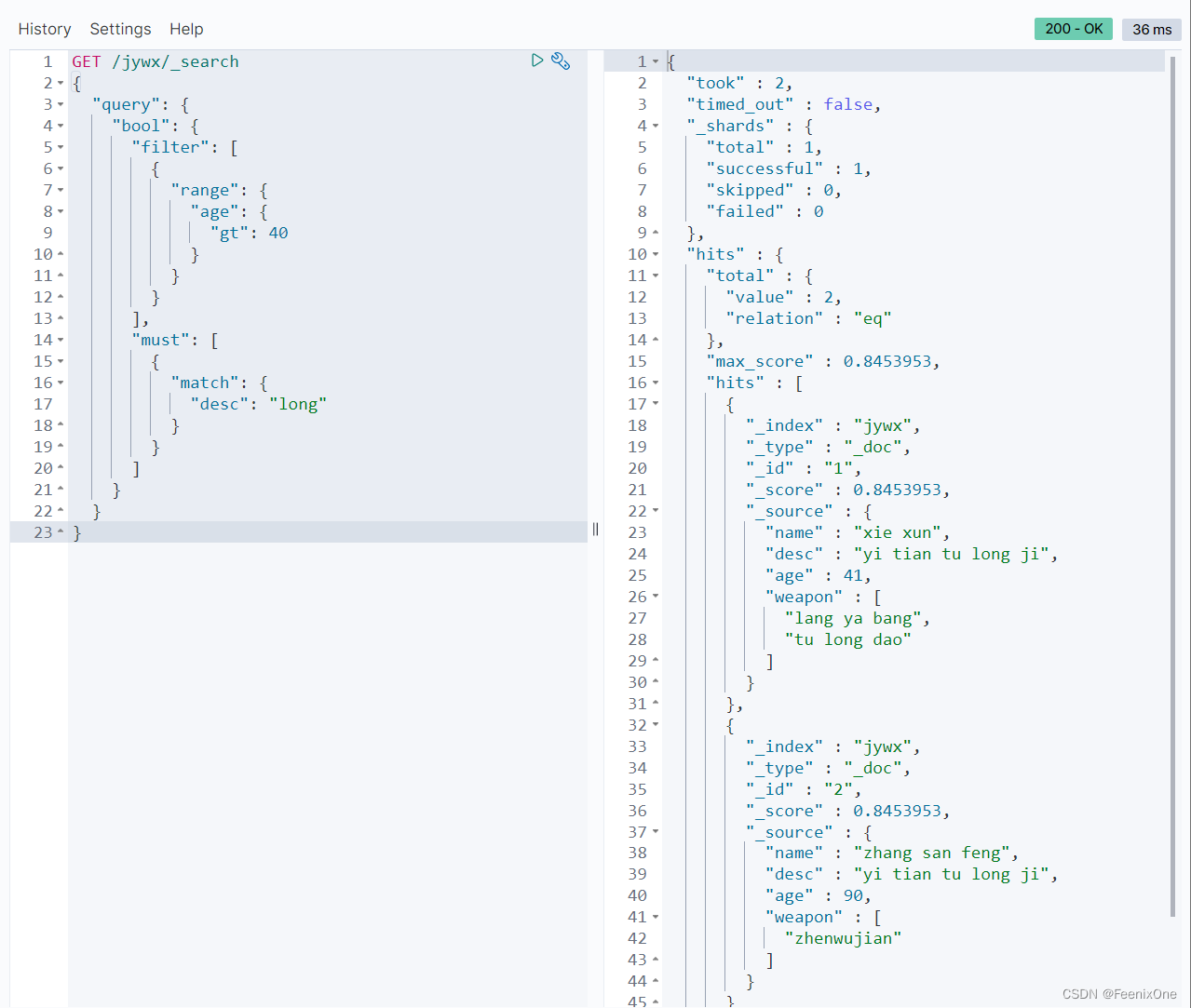
既然组合查询中多个组合以and的组合形式查询,如上的条件中must和filter是and组合起来的,那为什么不用两个must或两个filter呢?假设要查询全中国十几亿人口中满足20-30岁的人群,按照人的年龄或者id去排名显示。使用must会直接对十几亿的人口数据进行评分再排名,消耗极大的性能。可以先将20-30的筛选交给filter去做,单纯的筛选不涉及打分操作,再将排名结束之后的数据交给must去计算评分再排序,会节省很多性能。
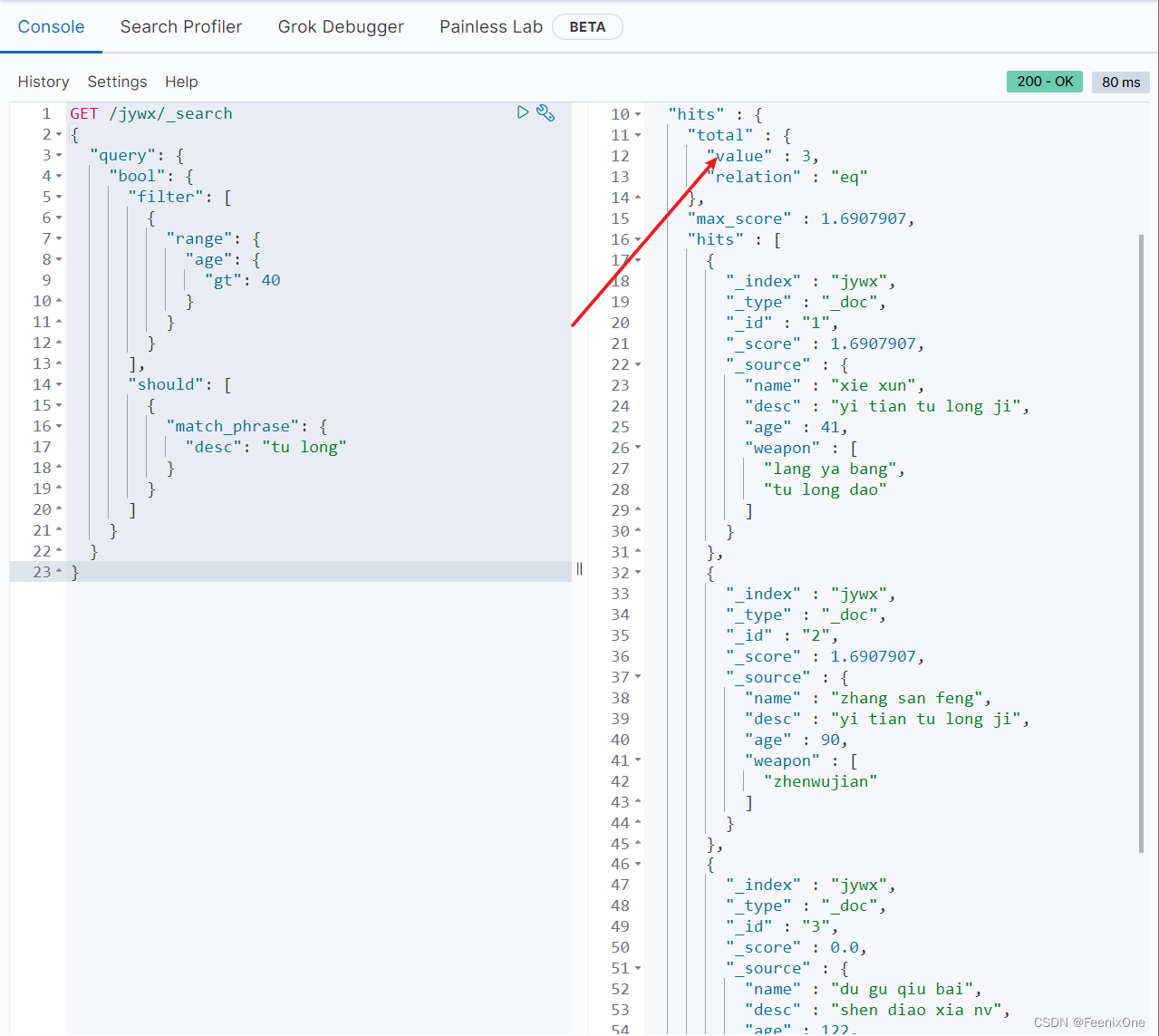
加了should之后还是3条数据,感觉should加没加没啥区别。这是因为bool query中已经有了filter或者must之后,那么should里面必须满足的条件数量就是0。也就是说再有了must或者filter之后,should中的条件可以无需满足。如果想让should中的条件起到作用的话,使用minimum_should_match关键字。
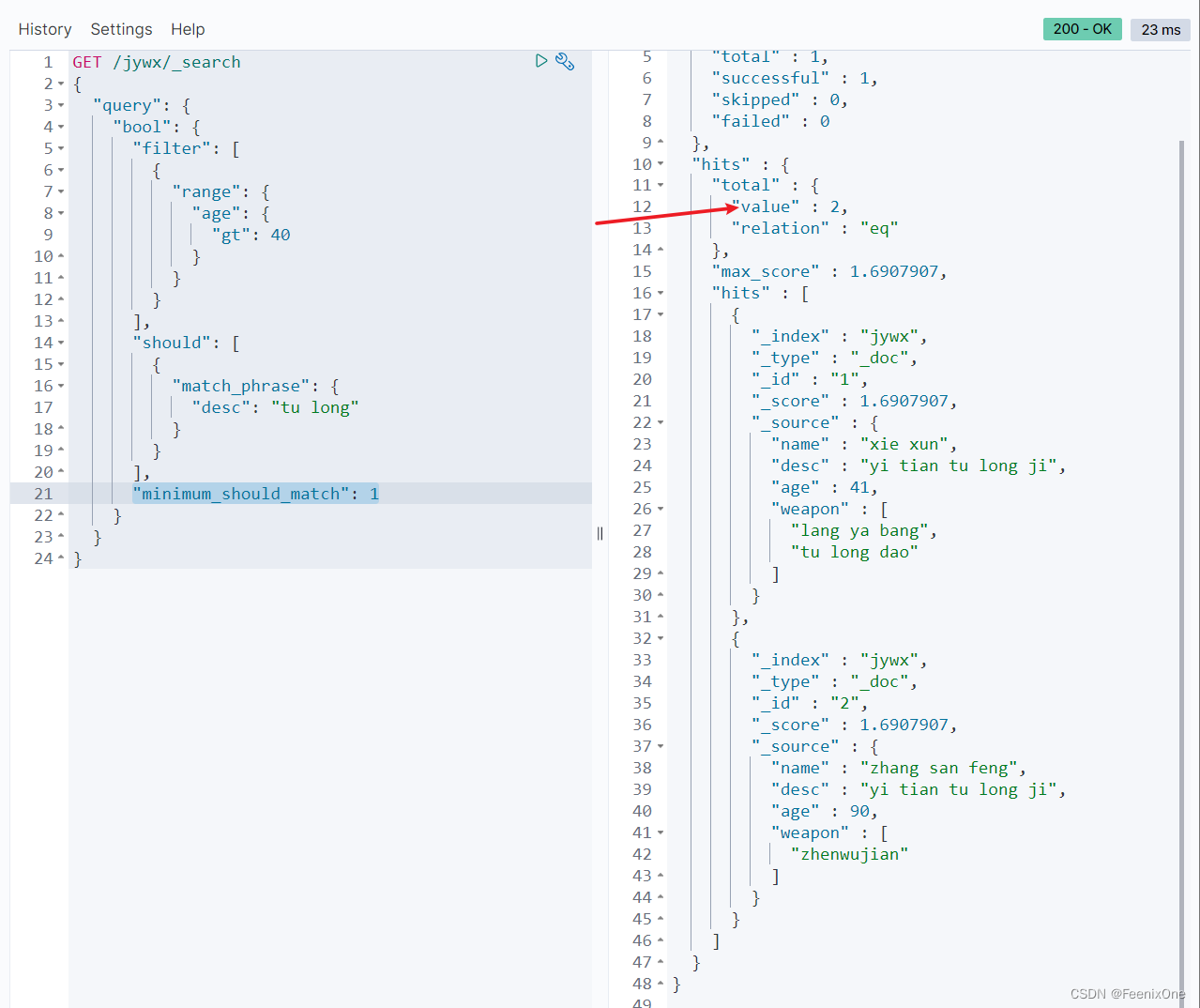
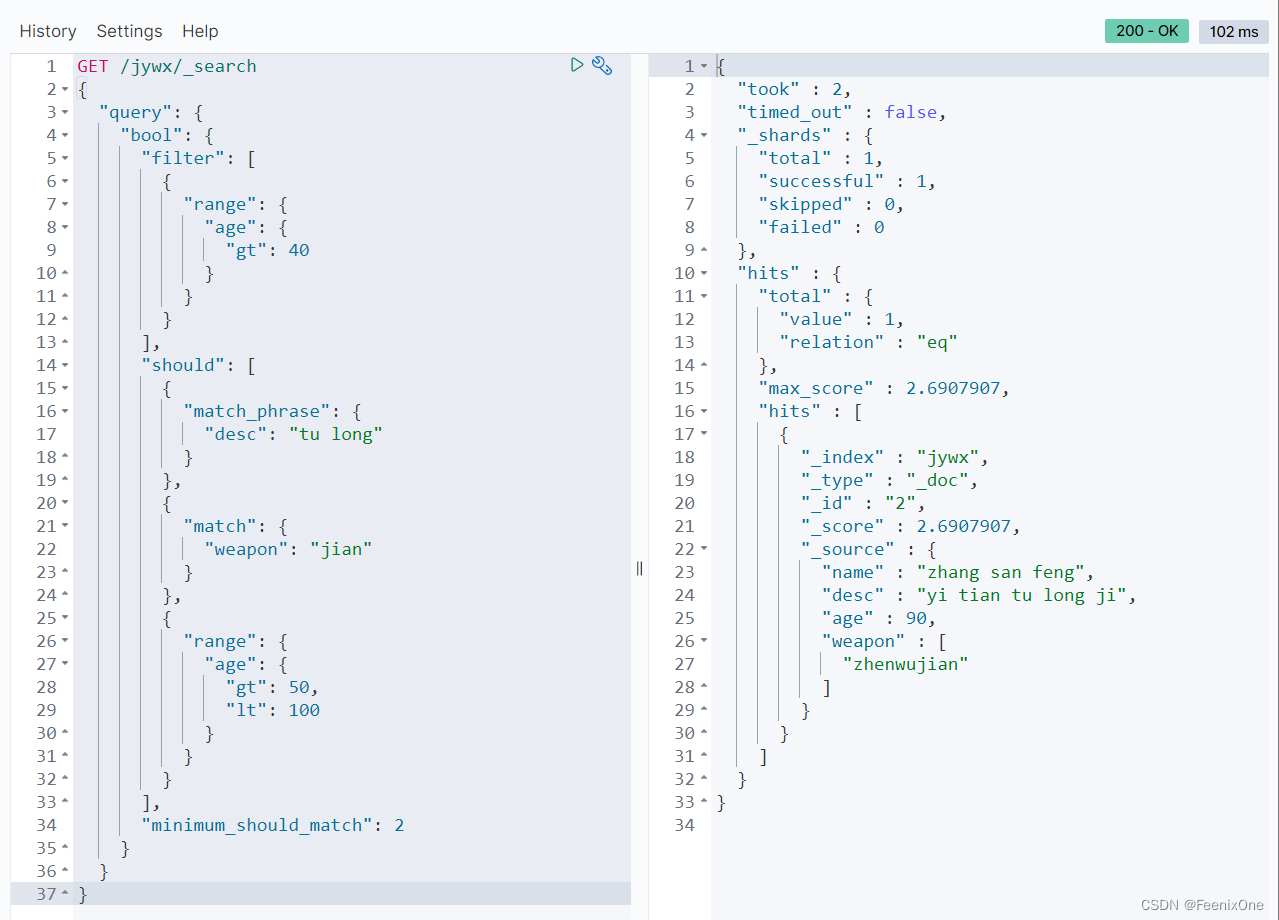
“minimum_should_match”: 1,只需满足should中的一个条件即可。match_phrase和match是or的关系:
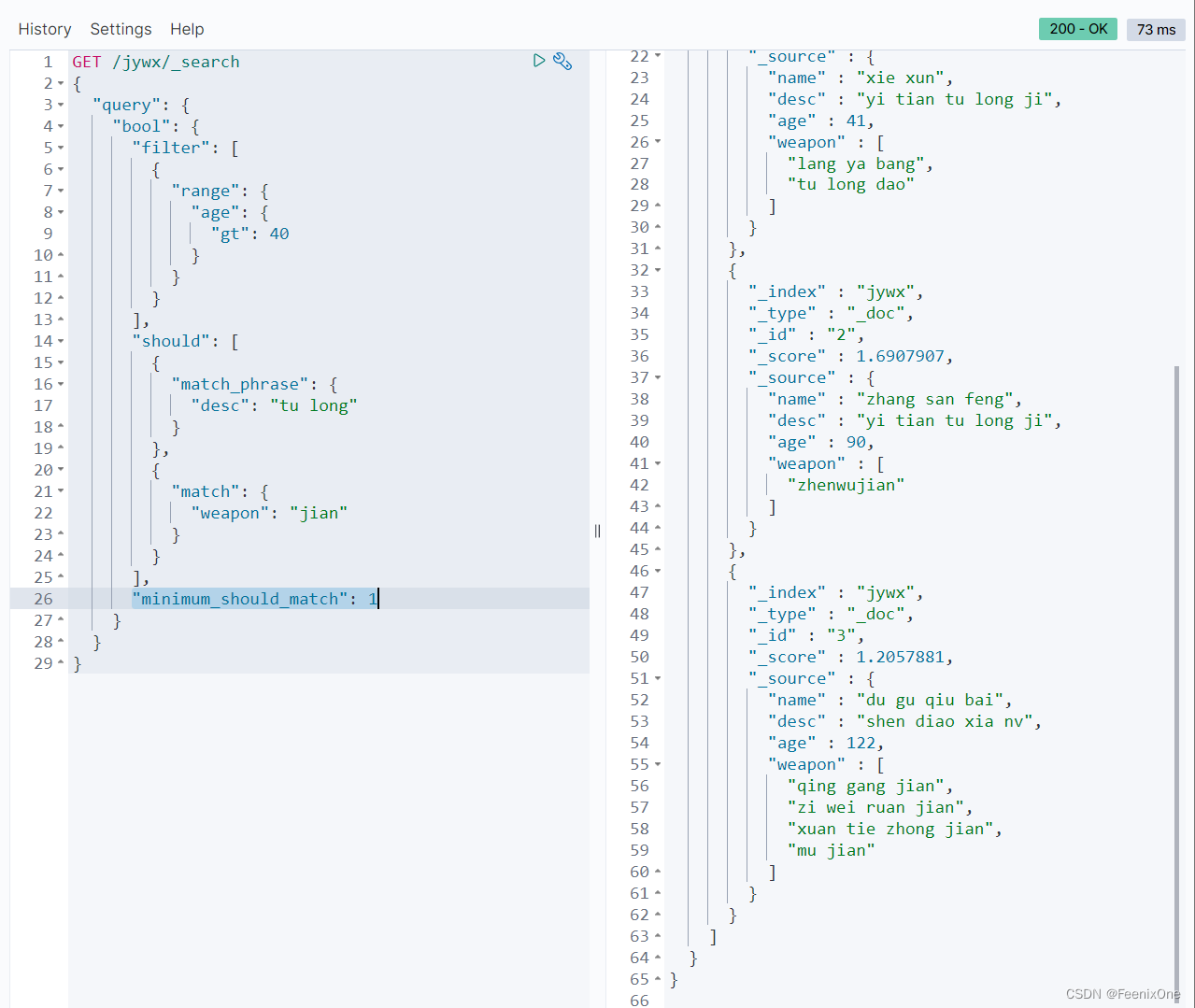
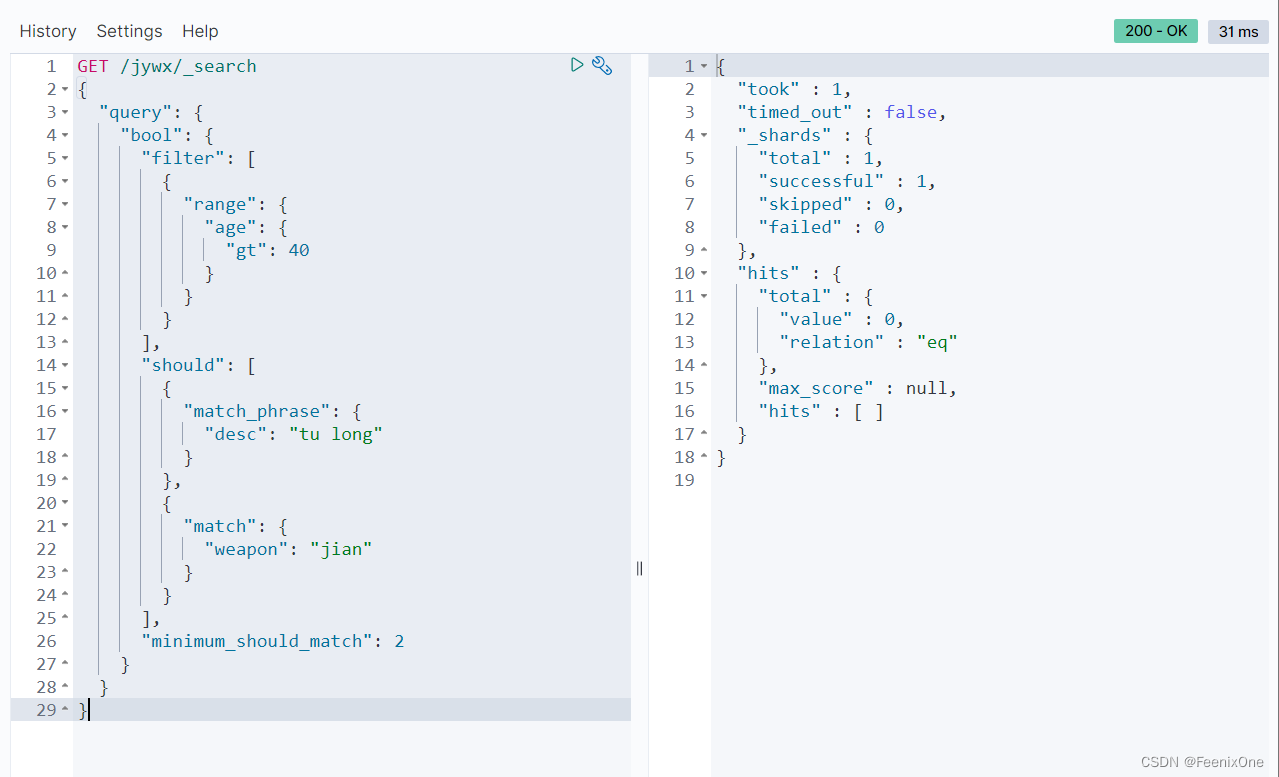
“minimum_should_match”: 2,得满足should中的两个条件才行。match_phrase和match是and的关系:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/111910.html

