

圣诞节快乐



圣诞节真的是一个温柔又温暖的节日了,可以在这飘雪的岁末里,富有仪式感又温柔地对待生命里珍贵的人说上一句:“圣诞快乐 喜乐长安 ”
IO是指Input/Output,即输入和输出。以内存为中心:
-
Input指从外部读入数据到内存,例如,把文件从磁盘读取到内存,从网络读取数据到内存等等。 -
Output指把数据从内存输出到外部,例如,把数据从内存写入到文件,把数据从内存输出到网络等等。
为什么要把数据读到内存才能处理这些数据?因为代码是在内存中运行的,数据也必须读到内存,最终的表示方式无非是byte数组,字符串等,都必须存放在内存里。
从Java代码来看,输入实际上就是从外部,例如,硬盘上的某个文件,把内容读到内存,并且以Java提供的某种数据类型表示,例如,byte[],String,这样,后续代码才能处理这些数据。
因为内存有“易失性”的特点,所以必须把处理后的数据以某种方式输出,例如,写入到文件。Output实际上就是把Java表示的数据格式,例如,byte[],String等输出到某个地方。
IO流是一种顺序读写数据的模式,它的特点是单向流动。数据类似自来水一样在水管中流动,所以我们把它称为IO流。
IO流是一种流式的数据输入/输出模型:
-
二进制数据以 byte为最小单位在InputStream/OutputStream中单向流动; -
字符数据以 char为最小单位在Reader/Writer中单向流动。
Java标准库的java.io包提供了同步IO功能:
-
字节流接口: InputStream/OutputStream; -
字符流接口: Reader/Writer。
圣诞节快乐
io相关的操作
file对象
在计算机系统中,文件是非常重要的存储方式。Java的标准库java.io提供了File对象来操作文件和目录。
要构造一个File对象,需要传入文件路径:
package com.zhsj.test;
import java.io.File;
/**
* @author 刘良琪
* @version V1.0
* <p> </p>
* @Package com.zhsj.test
* @date 2021/12/26 18:24
*/
public class Day3 {
public static void main(String[] args) {
File file = new File("D:\元气壁纸缓存\img");
System.out.println(file);
}
}
注意Windows平台使用
作为路径分隔符,在Java字符串中需要用\表示一个。Linux平台使用/作为路径分隔符:
File对象有3种形式表示的路径,一种是getPath(),返回构造方法传入的路径,一种是getAbsolutePath(),返回绝对路径,一种是getCanonicalPath,它和绝对路径类似,但是返回的是规范路径。
还可以获取目录的文件和子目录:list()/listFiles(),还有一个文件的crud操作,不会的百度就行
案例:遍历文件和目录 (只包含.exe的文件)
package com.zhsj.test;
import java.io.File;
import java.io.FilenameFilter;
import java.io.IOException;
/**
* @author 刘良琪
* @version V1.0
* <p> </p>
* @Package com.zhsj.test
* @date 2021/12/26 18:24
*/
public class Day3 {
public static void main(String[] args) throws IOException {
File file = new File("D:\");
File[] files = file.listFiles();
printFiles(files);
File[] files1 = file.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".exe");
}
});
printFiles(files1);
}
static void printFiles(File[] files) {
System.out.println("==========");
if (files != null) {
for (File f : files) {
System.out.println(f);
}
}
System.out.println("==========");
}
}
俗话说:万物皆字节,我这里只说字节流,字符流大同小异。
InputStream
InputStream:字节输入流基类,抽象类是表示字节输入流的所有类的超类。
InputStream就是Java标准库提供的最基本的输入流。它位于java.io这个包里。java.io包提供了所有同步IO的功能。
要特别注意的一点是,InputStream并不是一个接口,而是一个抽象类,它是所有输入流的超类。这个抽象类定义的一个最重要的方法就是int read(),签名如下:
public abstract int read() throws IOException;
这个方法会读取输入流的下一个字节,并返回字节表示的int值(0~255)。如果已读到末尾,返回-1表示不能继续读取了。
FileInputStream是InputStream的一个子类。顾名思义,FileInputStream就是从文件流中读取数据。
public void readFile() throws IOException {
// 创建一个FileInputStream对象:
InputStream input = new FileInputStream("src/readme.txt");
for (;;) {
int n = input.read(); // 反复调用read()方法,直到返回-1
if (n == -1) {
break;
}
System.out.println(n); // 打印byte的值
}
input.close(); // 关闭流
}
在计算机中,类似文件、网络端口这些资源,都是由操作系统统一管理的。应用程序在运行的过程中,如果打开了一个文件进行读写,完成后要及时地关闭,以便让操作系统把资源释放掉,否则,应用程序占用的资源会越来越多,不但白白占用内存,还会影响其他应用程序的运行。
InputStream和OutputStream都是通过close()方法来关闭流。关闭流就会释放对应的底层资源。
我们还要注意到在读取或写入IO流的过程中,可能会发生错误,例如,文件不存在导致无法读取,没有写权限导致写入失败,等等,这些底层错误由Java虚拟机自动封装成IOException异常并抛出。因此,所有与IO操作相关的代码都必须正确处理IOException。
缓冲
在读取流的时候,一次读取一个字节并不是最高效的方法。很多流支持一次性读取多个字节到缓冲区,对于文件和网络流来说,利用缓冲区一次性读取多个字节效率往往要高很多。InputStream提供了两个重载方法来支持读取多个字节:
-
int read(byte[] b):读取若干字节并填充到byte[]数组,返回读取的字节数 -
int read(byte[] b, int off, int len):指定byte[]数组的偏移量和最大填充数
利用上述方法一次读取多个字节时,需要先定义一个byte[]数组作为缓冲区,read()方法会尽可能多地读取字节到缓冲区, 但不会超过缓冲区的大小。read()方法的返回值不再是字节的int值,而是返回实际读取了多少个字节。如果返回-1,表示没有更多的数据了。
利用缓冲区一次读取多个字节的代码如下:
public void readFile() throws IOException {
try (InputStream input = new FileInputStream("src/readme.txt")) {
// 定义1000个字节大小的缓冲区:
byte[] buffer = new byte[1000];
int n;
while ((n = input.read(buffer)) != -1) { // 读取到缓冲区
System.out.println("read " + n + " bytes.");
}
}
}
案例:
public class FileCount {
/**
* 我们写一个检测文件长度的小程序,别看这个程序挺长的,你忽略try catch块后发现也就那么几行而已。
*/
publicstatic void main(String[] args) {
//TODO 自动生成的方法存根
int count=0; //统计文件字节长度
InputStreamstreamReader = null; //文件输入流
try{
streamReader=newFileInputStream(new File("D:/David/Java/java 高级进阶/files/tiger.jpg"));
/*1.new File()里面的文件地址也可以写成D:\David\Java\java 高级进阶\files\tiger.jpg,前一个是用来对后一个
* 进行转换的,FileInputStream是有缓冲区的,所以用完之后必须关闭,否则可能导致内存占满,数据丢失。
*/
while(streamReader.read()!=-1) { //读取文件字节,并递增指针到下一个字节
count++;
}
System.out.println("---长度是:"+count+" 字节");
}catch (final IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}finally{
try{
streamReader.close();
}catch (IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
OutputStream
OutputStream:字节输出流基类,抽象类是表示输出字节流的所有类的超类。
和InputStream相反,OutputStream是Java标准库提供的最基本的输出流。
和InputStream类似,OutputStream也是抽象类,它是所有输出流的超类。这个抽象类定义的一个最重要的方法就是void write(int b)
常用方法:
// 将 b.length 个字节从指定的 byte 数组写入此输出流
void write(byte[] b)
// 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流
void write(byte[] b, int off, int len)
// 将指定的字节写入此输出流
abstract void write(int b)
// 关闭此输出流并释放与此流有关的所有系统资源
void close()
// 刷新此输出流并强制写出所有缓冲的输出字节
void flush()
案例:
public class FileCopy {
public static void main(String[] args) {
// TODO自动生成的方法存根
byte[] buffer=new byte[512]; //一次取出的字节数大小,缓冲区大小
int numberRead=0;
FileInputStream input=null;
FileOutputStream out =null;
try {
input=new FileInputStream("D:/David/Java/java 高级进阶/files/tiger.jpg");
out=new FileOutputStream("D:/David/Java/java 高级进阶/files/tiger2.jpg"); //如果文件不存在会自动创建
while ((numberRead=input.read(buffer))!=-1) { //numberRead的目的在于防止最后一次读取的字节小于buffer长度,
out.write(buffer, 0, numberRead); //否则会自动被填充0
}
} catch (final IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}finally{
try {
input.close();
out.close();
} catch (IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}
}
}
Filter模式
Java的IO标准库使用Filter模式为InputStream和OutputStream增加功能:
-
可以把一个 InputStream和任意个FilterInputStream组合; -
可以把一个 OutputStream和任意个FilterOutputStream组合。
Filter模式可以在运行期动态增加功能(又称Decorator模式)。
操作zip
ZipInputStream是一种FilterInputStream,它可以直接读取zip包的内容:
┌───────────────────┐
│ InputStream │
└───────────────────┘
▲
│
┌───────────────────┐
│ FilterInputStream │
└───────────────────┘
▲
│
┌───────────────────┐
│InflaterInputStream│
└───────────────────┘
▲
│
┌───────────────────┐
│ ZipInputStream │
└───────────────────┘
▲
│
┌───────────────────┐
│ JarInputStream │
└───────────────────┘
另一个JarInputStream是从ZipInputStream派生,它增加的主要功能是直接读取jar文件里面的MANIFEST.MF文件。因为本质上jar包就是zip包,只是额外附加了一些固定的描述文件。
读取Zip包
我们要创建一个ZipInputStream,通常是传入一个FileInputStream作为数据源,然后,循环调用getNextEntry(),直到返回null,表示zip流结束。
一个ZipEntry表示一个压缩文件或目录,如果是压缩文件,我们就用read()方法不断读取,直到返回-1:
try (ZipInputStream zip = new ZipInputStream(new FileInputStream(...))) {
ZipEntry entry = null;
while ((entry = zip.getNextEntry()) != null) {
String name = entry.getName();
if (!entry.isDirectory()) {
int n;
while ((n = zip.read()) != -1) {
...
}
}
}
}
写入Zip包
ZipOutputStream是一种FilterOutputStream,它可以直接写入内容到zip包。我们要先创建一个ZipOutputStream,通常是包装一个FileOutputStream,然后,每写入一个文件前,先调用putNextEntry(),然后用write()写入byte[]数据,写入完毕后调用closeEntry()结束这个文件的打包。
try (ZipOutputStream zip = new ZipOutputStream(new FileOutputStream(...))) {
File[] files = ...
for (File file : files) {
zip.putNextEntry(new ZipEntry(file.getName()));
zip.write(getFileDataAsBytes(file));
zip.closeEntry();
}
}
上面的代码没有考虑文件的目录结构。如果要实现目录层次结构,new ZipEntry(name)传入的name要用相对路径。
读取classpath资源
把资源存储在classpath中可以避免文件路径依赖;
Class对象的getResourceAsStream()可以从classpath中读取指定资源;
根据classpath读取资源时,需要检查返回的InputStream是否为null。
如果我们把默认的配置放到jar包中,再从外部文件系统读取一个可选的配置文件,就可以做到既有默认的配置文件,又可以让用户自己修改配置:
Properties props = new Properties();
props.load(inputStreamFromClassPath("/default.properties"));
props.load(inputStreamFromFile("./conf.properties"));
序列化
序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。
为什么要把Java对象序列化呢?因为序列化后可以把byte[]保存到文件中,或者把byte[]通过网络传输到远程,这样,就相当于把Java对象存储到文件或者通过网络传输出去了。
有序列化,就有反序列化,即把一个二进制内容(也就是byte[]数组)变回Java对象。有了反序列化,保存到文件中的byte[]数组又可以“变回”Java对象,或者从网络上读取byte[]并把它“变回”Java对象。
把一个Java对象变为byte[]数组,需要使用ObjectOutputStream。它负责把一个Java对象写入一个字节流:
public class Main {
public static void main(String[] args) throws IOException {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
try (ObjectOutputStream output = new ObjectOutputStream(buffer)) {
// 写入int:
output.writeInt(12345);
// 写入String:
output.writeUTF("Hello");
// 写入Object:
output.writeObject(Double.valueOf(123.456));
}
System.out.println(Arrays.toString(buffer.toByteArray()));
}
}
ObjectOutputStream既可以写入基本类型,如int,boolean,也可以写入String(以UTF-8编码),还可以写入实现了Serializable接口的Object。
因为写入Object时需要大量的类型信息,所以写入的内容很大。
反序列化
和ObjectOutputStream相反,ObjectInputStream负责从一个字节流读取Java对象:
try (ObjectInputStream input = new ObjectInputStream(...)) {
int n = input.readInt();
String s = input.readUTF();
Double d = (Double) input.readObject();
}
除了能读取基本类型和String类型外,调用readObject()可以直接返回一个Object对象。要把它变成一个特定类型,必须强制转型。
readObject()可能抛出的异常有:
-
ClassNotFoundException:没有找到对应的Class; -
InvalidClassException:Class不匹配。
对于ClassNotFoundException,这种情况常见于一台电脑上的Java程序把一个Java对象,例如,Person对象序列化以后,通过网络传给另一台电脑上的另一个Java程序,但是这台电脑的Java程序并没有定义Person类,所以无法反序列化。
对于InvalidClassException,这种情况常见于序列化的Person对象定义了一个int类型的age字段,但是反序列化时,Person类定义的age字段被改成了long类型,所以导致class不兼容。
为了避免这种class定义变动导致的不兼容,Java的序列化允许class定义一个特殊的serialVersionUID静态变量,用于标识Java类的序列化“版本”,通常可以由IDE自动生成。如果增加或修改了字段,可以改变serialVersionUID的值,这样就能自动阻止不匹配的class版本:
public class Person implements Serializable {
private static final long serialVersionUID = 2709425275741743919L;
}
要特别注意反序列化的几个重要特点:
反序列化时,由JVM直接构造出Java对象,不调用构造方法,构造方法内部的代码,在反序列化时根本不可能执行。
PrintStream和PrintWriter
PrintStream是一种FilterOutputStream,它在OutputStream的接口上,额外提供了一些写入各种数据类型的方法:
-
写入 int:print(int) -
写入 boolean:print(boolean) -
写入 String:print(String) -
写入 Object:print(Object),实际上相当于print(object.toString()) -
…
以及对应的一组println()方法,它会自动加上换行符。
我们经常使用的System.out.println()实际上就是使用PrintStream打印各种数据其中,System.out是系统默认提供的PrintStream,表示标准输出:
System.out.print(12345); // 输出12345
System.out.print(new Object()); // 输出类似java.lang.Object@3c7a835a
System.out.println("Hello"); // 输出Hello并换行
System.err是系统默认提供的标准错误输出。
PrintStream和OutputStream相比,除了添加了一组print()/println()方法,可以打印各种数据类型,比较方便外,它还有一个额外的优点,就是不会抛出IOException,这样我们在编写代码的时候,就不必捕获IOException。
PrintWriter
PrintStream最终输出的总是byte数据,而PrintWriter则是扩展了Writer接口,它的print()/println()方法最终输出的是char数据。两者的使用方法几乎是一模一样的:
public class Main {
public static void main(String[] args) {
StringWriter buffer = new StringWriter();
try (PrintWriter pw = new PrintWriter(buffer)) {
pw.println("Hello");
pw.println(12345);
pw.println(true);
}
System.out.println(buffer.toString());
}
}
字节缓冲流
BufferedInputStream:字节缓冲输入流,提高了读取效率。
构造方法:
// 创建一个 BufferedInputStream并保存其参数,即输入流in,以便将来使用。
BufferedInputStream(InputStream in)
// 创建具有指定缓冲区大小的 BufferedInputStream并保存其参数,即输入流in以便将来使用
BufferedInputStream(InputStream in, int size)
InputStream in = new FileInputStream("test.txt");
// 字节缓存流
BufferedInputStream bis = new BufferedInputStream(in);
byte[] bs = new byte[20];
int len = 0;
while ((len = bis.read(bs)) != -1) {
System.out.print(new String(bs, 0, len));
// ABCD
// hello
}
// 关闭流
bis.close();
BufferedOutputStream:字节缓冲输出流,提高了写出效率。
构造方法:
// 创建一个新的缓冲输出流,以将数据写入指定的底层输出流
BufferedOutputStream(OutputStream out)
// 创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流
BufferedOutputStream(OutputStream out, int size)
常用方法:
// 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此缓冲的输出流
void write(byte[] b, int off, int len)
// 将指定的字节写入此缓冲的输出流
void write(int b)
// 刷新此缓冲的输出流
void flush()
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("test.txt", true));
// 输出换行符
bos.write("rn".getBytes());
// 输出内容
bos.write("Hello Android".getBytes());
// 刷新此缓冲的输出流
bos.flush();
// 关闭流
圣诞节快乐
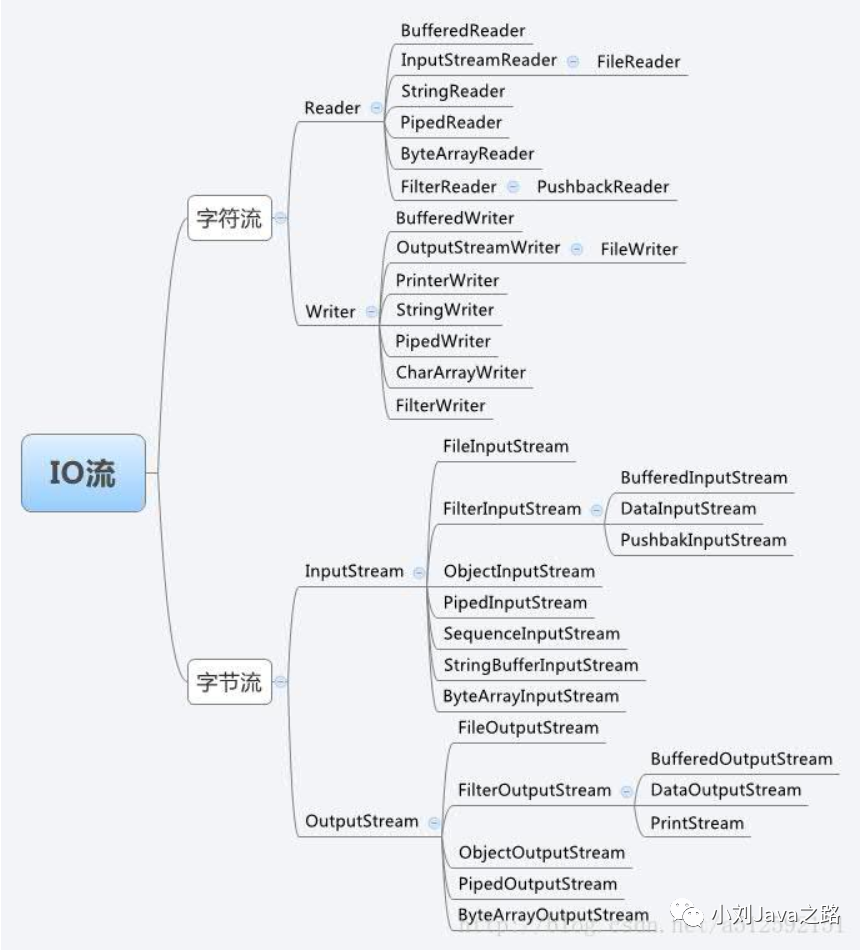
总结:
-
io流是JavaSE很重要的内容,好好学掌握这个技能,对你理解底层实现也很有帮助 -


img
记住这张图片,就OK了
-
我们开发一般都是用的BufferedInputStream与BufferedOutputStream来进行oi操作,这样可以提高效率
-
通俗的理解io:Java中的IO流是输入输出流。至于理解,可以将输入和输出两个端点看作是两个工厂,工厂之间需要互相运输货物,而流则是两工厂之间的公路,没有公路就不能互相运输,至于字符,字节和二进制则可以看作是运输的方式和单位大小,比如说把二进制理解成三轮车,那么字节就是小卡车,而字符则是集卡之类的。
-
希望大家还是好好的学习下io流,在工作中虽然都是用的框架但是对于这些基本的技术还是要掌握扎实,俗话说:基本不好,地动山摇。





本篇文章来源于微信公众号: 小刘Java之路
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/11193.html

