
0、本篇承接上一篇的搭建基础上进行的操作,没有先搭建Kafka集群的可以先看看上一篇中的内容:
1、新建topic、partitions、replication-factor
kafka-topics.sh –zookeeper Kafka2:2181,Kafka3:2181/kafka –create –topic feenix-isr –partitions 2 –replication-factor 3



在Kafka的数据目录中(/var/kafka_data)可以看到刚刚创建的两个分区
cd /var/kafka_data

进入数据目录中查看详细的数据信息:
cd feenix-isr-0/
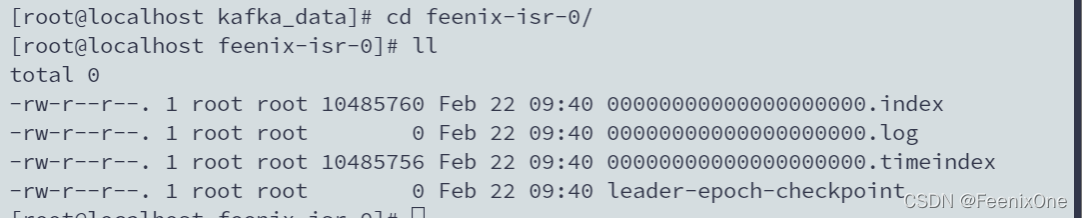
00000000000000000000.index >> offset偏移量的索引
00000000000000000000.log >> 存储数据,数据当前为0
00000000000000000000.timeindex >> 时间戳的索引,其实就是index的索引,timeindex>index>log从而最终找到具体的数据
注意一个点:在没有任何数据的时候,00000000000000000000.index和00000000000000000000.timeindex已经占了10M左右的空间,这个是因为在首次创建的时候Kafka进行了空间的预分配:文件的块和内核的块映射和应用程序之间先打通。
那为什么.log文件不用mmap结构呢?因为.log使用普通I/O的形式是为了通用性,数据存入磁盘的可靠性级别。普通的I/O只是在app层级调用了I/O的write,但这时候只到达了内核(pagecache的缓存中,没有到磁盘),性能快,但是丢数据。只有NIO的filechannel调用了write+force才是真正的写到了磁盘,但性能极低。
看下现在log和index的空数据文件
kafka-dump-log.sh –files 00000000000000000000.log

kafka-dump-log.sh –files 00000000000000000000.index
2、通过代码生产数据
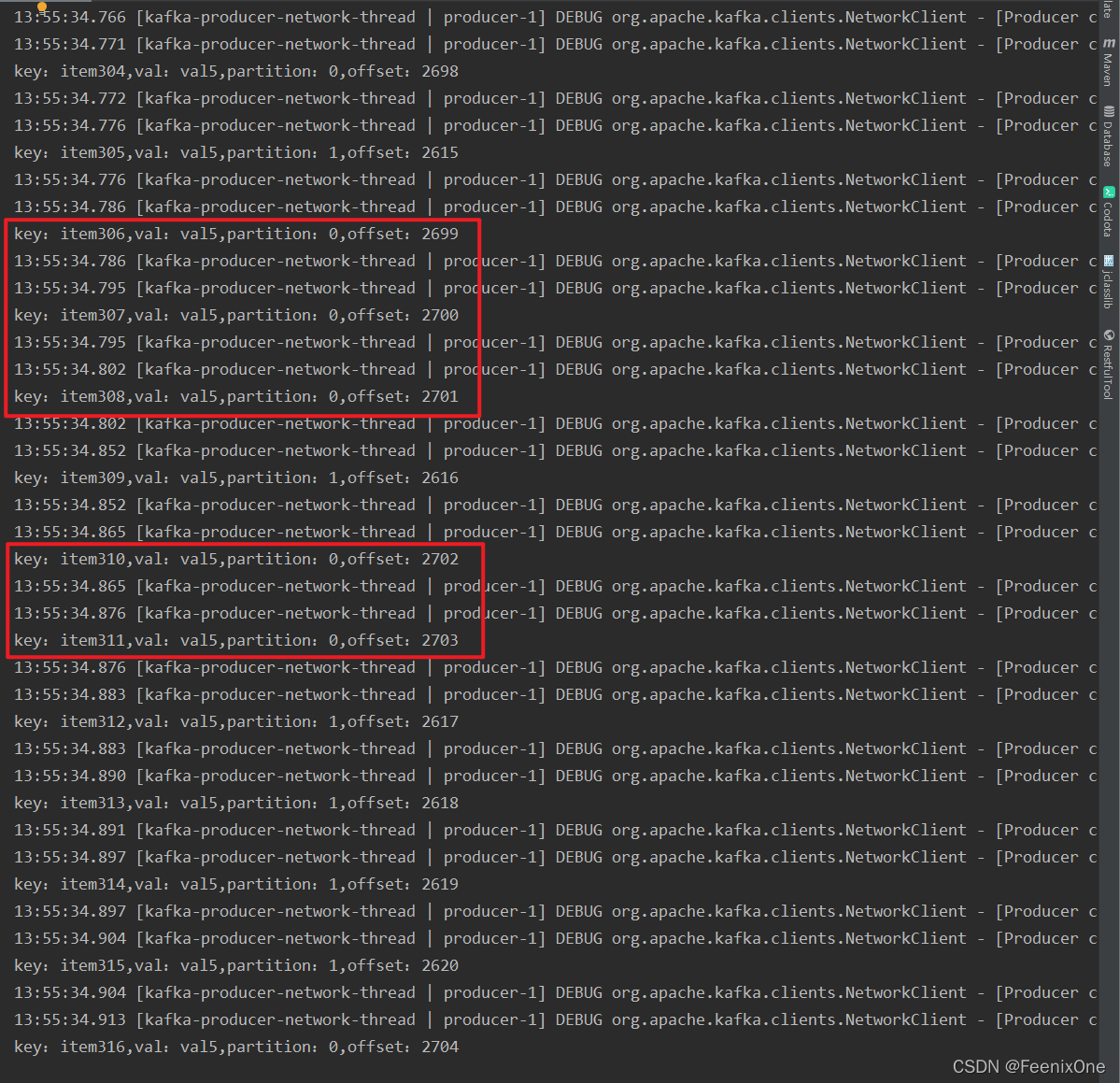
以partition0的数据来举例,按照上面的分区信息来看,partition0的住是Kafka1,进入Kafka1这台主机的/var/kafka_data/feenix-isr-0/目录中
kafka-dump-log.sh –files 00000000000000000000.log
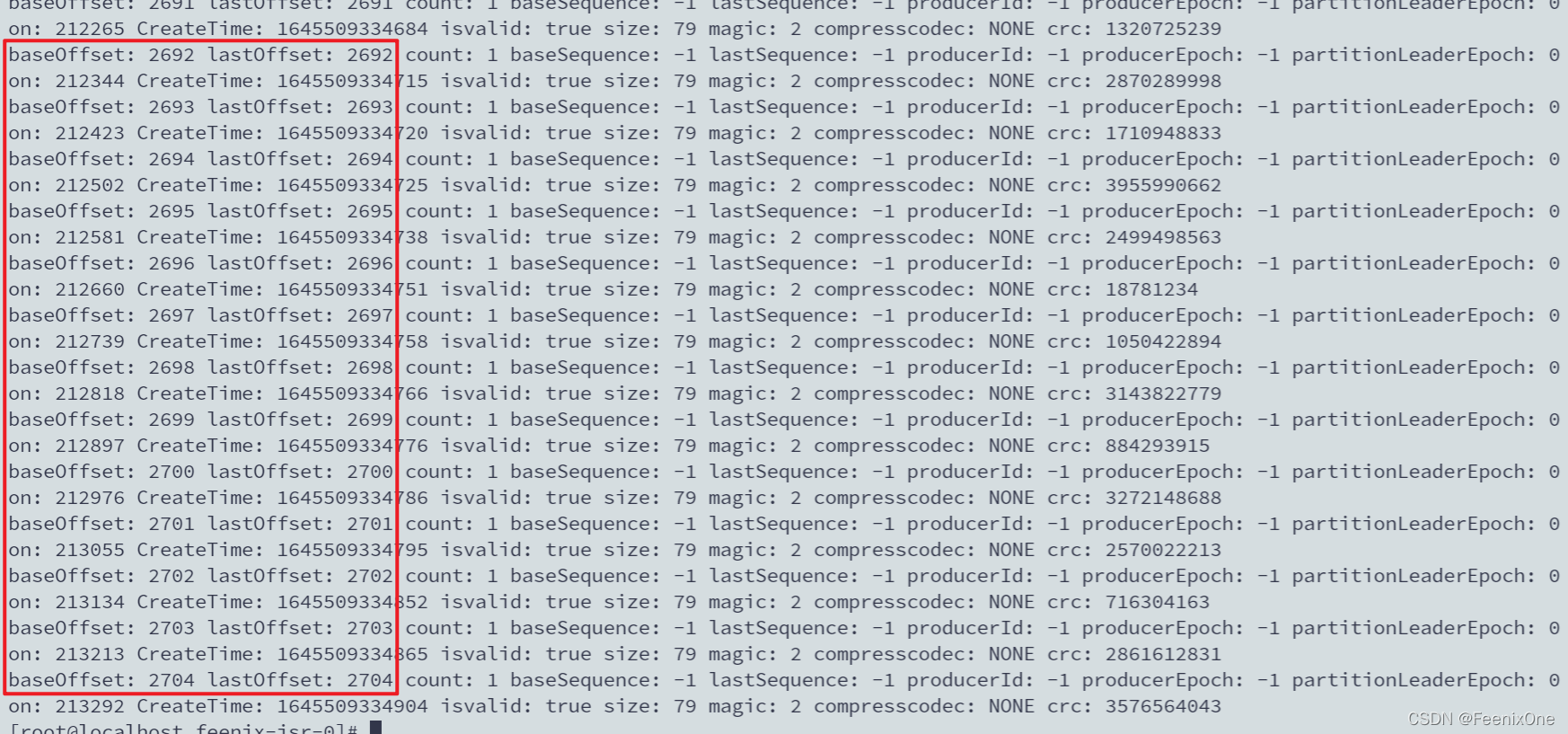
kafka-dump-log.sh –files 00000000000000000000.index
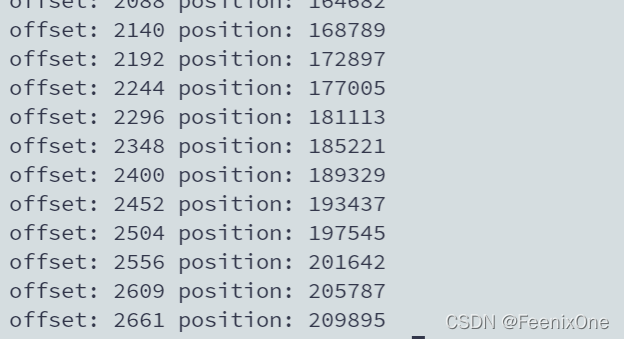
offset: 2661,针对程序代码中维护的偏移量;
position: 209895,针对log文件中的偏移量。可以理解为log文件就是一堆字节数组,通过position的值来定位找到数组中具体的位置。
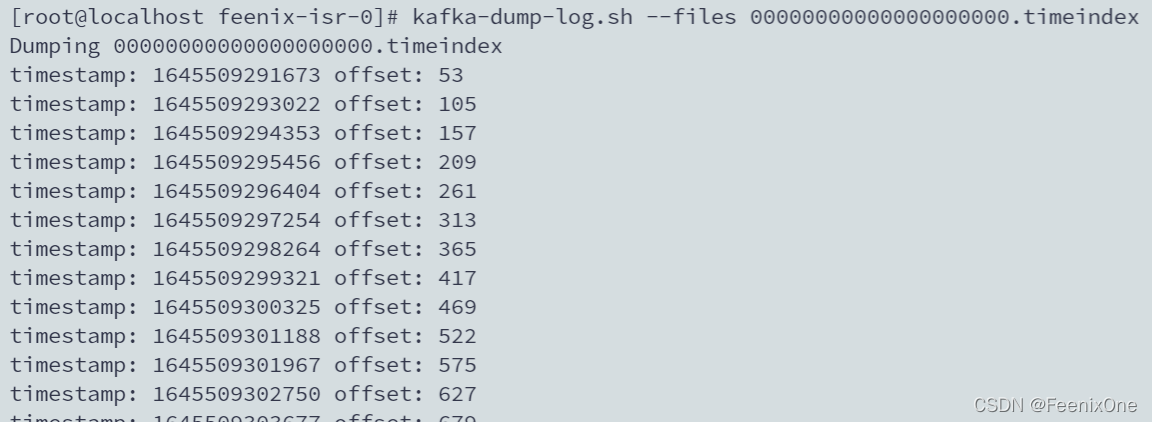
kafka-dump-log.sh –files 00000000000000000000.timeindex
3、配置Producer的ACK参数
p.setProperty(ProducerConfig.ACKS_CONFIG, "0");
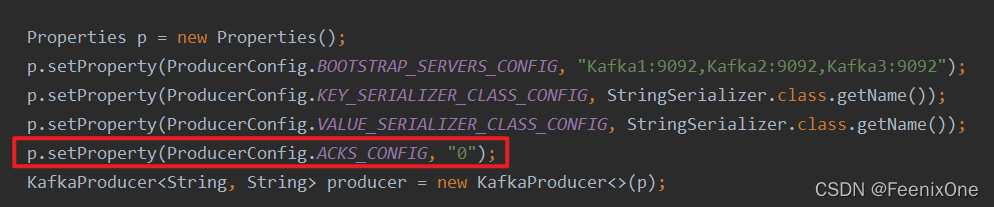
此时生产的数据offset值全为-1
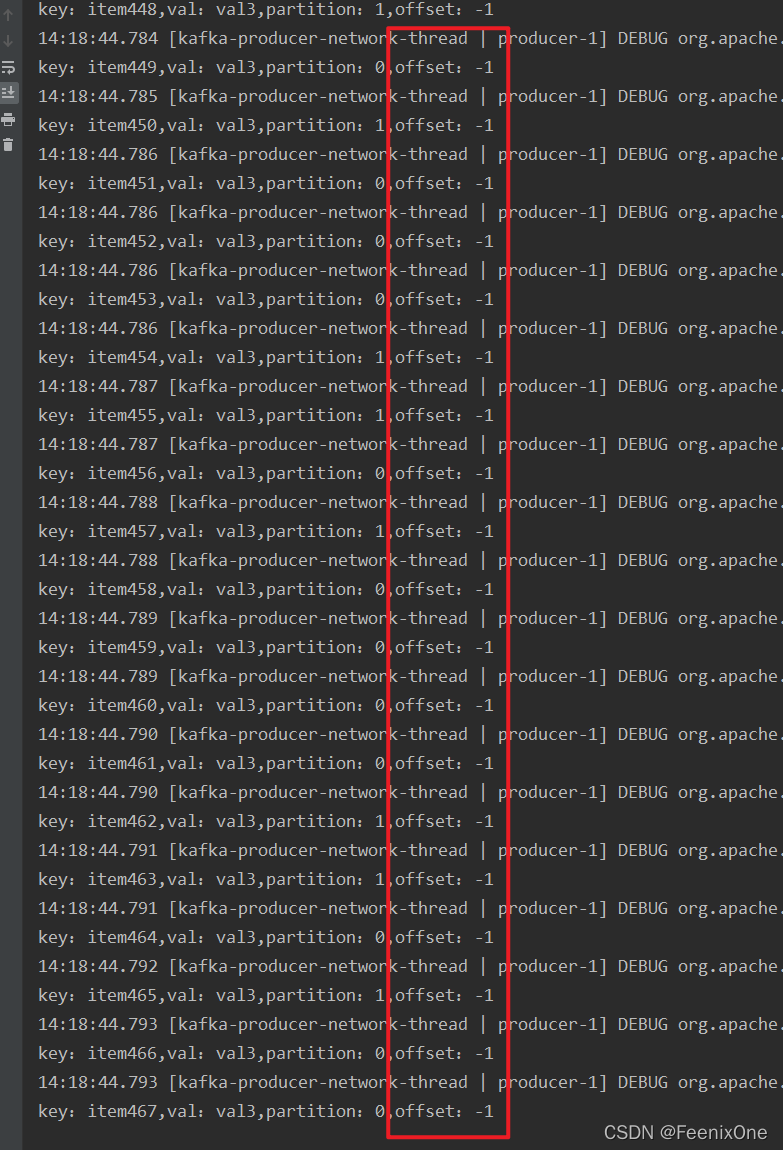
站在生产者的角度来说,并不需要等待broker的返回,只需要一股脑的发送就可以。这种模式下生产的可靠性是最低的,速度是最快的。
p.setProperty(ProducerConfig.ACKS_CONFIG, “1”);
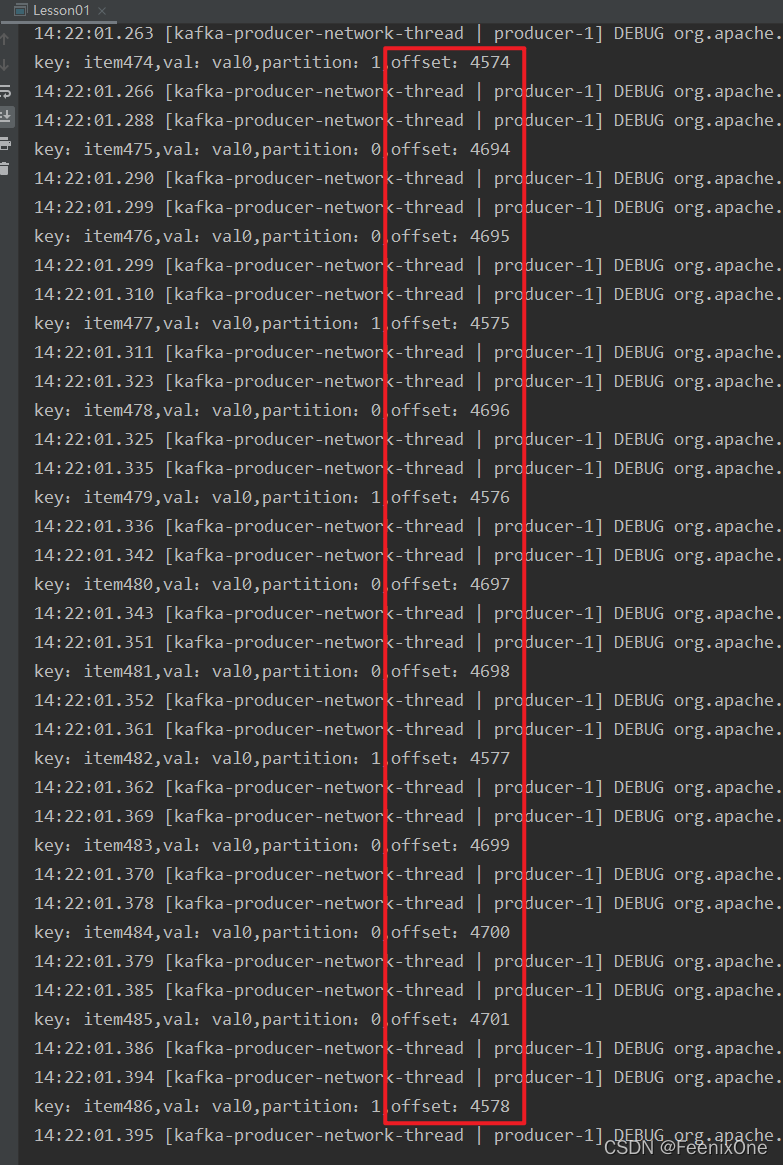
此时的offset是有维护的,生产的数据只到达leader,不关心是否到达了slave,只要到达leader只有就返回OK。
p.setProperty(ProducerConfig.ACKS_CONFIG, “-1”);
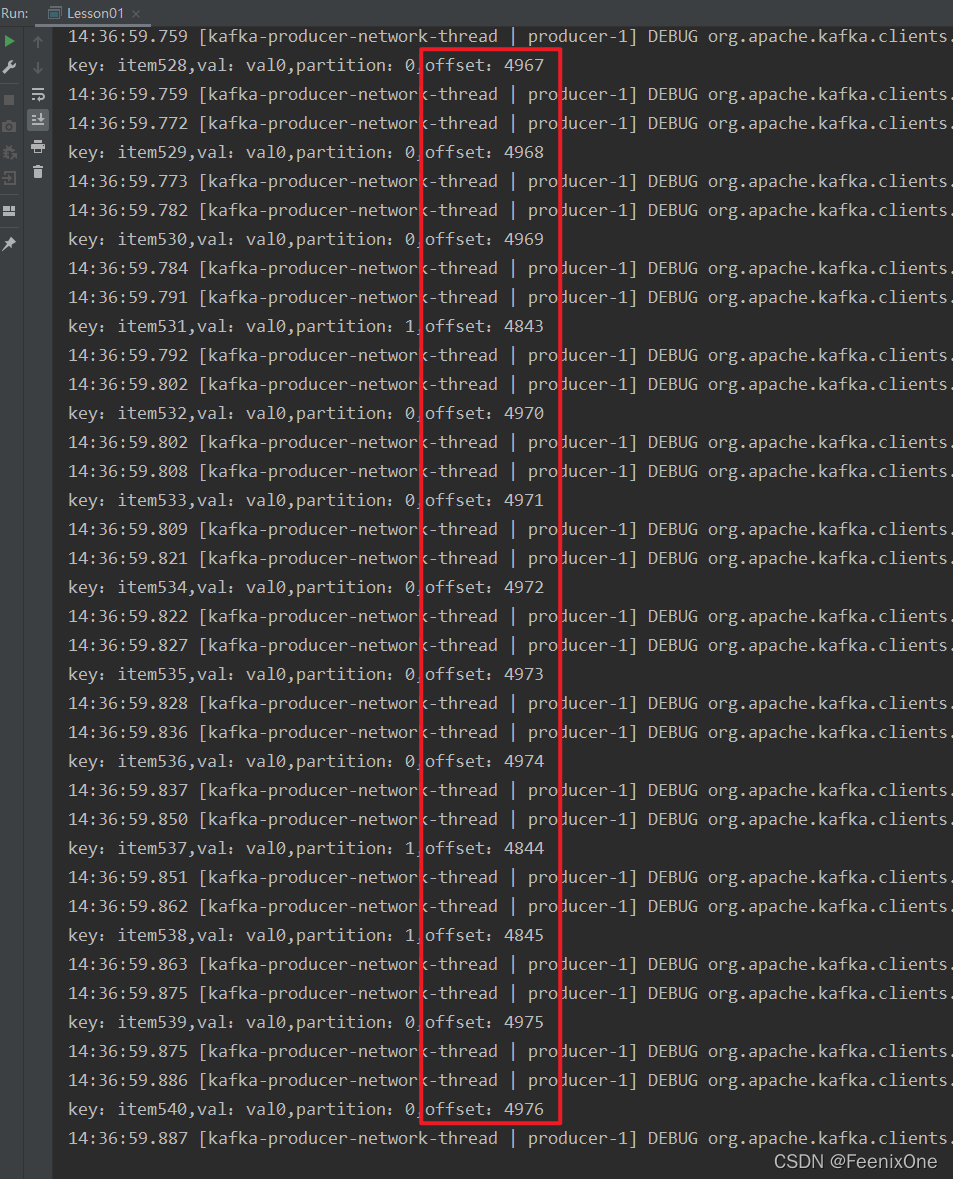
设为-1的时候, offset的获得是要经过所有的分区的副本在集群里面全部同步完之后才能返回。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/111930.html

