
对于传统的关系型数据库而言,事务的控制是调整数据的隔离级别。但是对于MongoDB而言,在数据读和写的时候用于指定怎么读怎么写来控制事务。MongoDB为什么要这么设计呢?因为在传统的关系型数据库而言,更多的是考虑单节点的事物隔离;而MongoDB更多的是考虑多节点的情况下事务的保证,主要分为:写事务(writeConcern)和读事务(readPreference、readConcern)。
1、writeConcern
writeConcern描述了一次写请求的确认级别
{w:<value>, j:<boolean>, wtimeout:<number>}
w:决定一个写操作落到多少个节点上才算成功
- 0(默认):发起写操作,不关心是否成功;
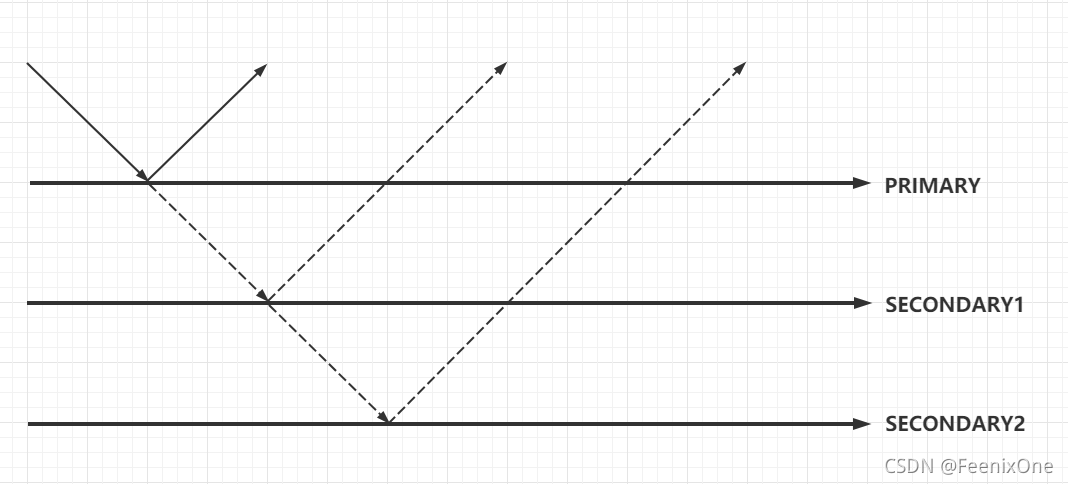
- 1~集群最大数据节点数:写操作数据需要全部复制到配置节点上才算成功;
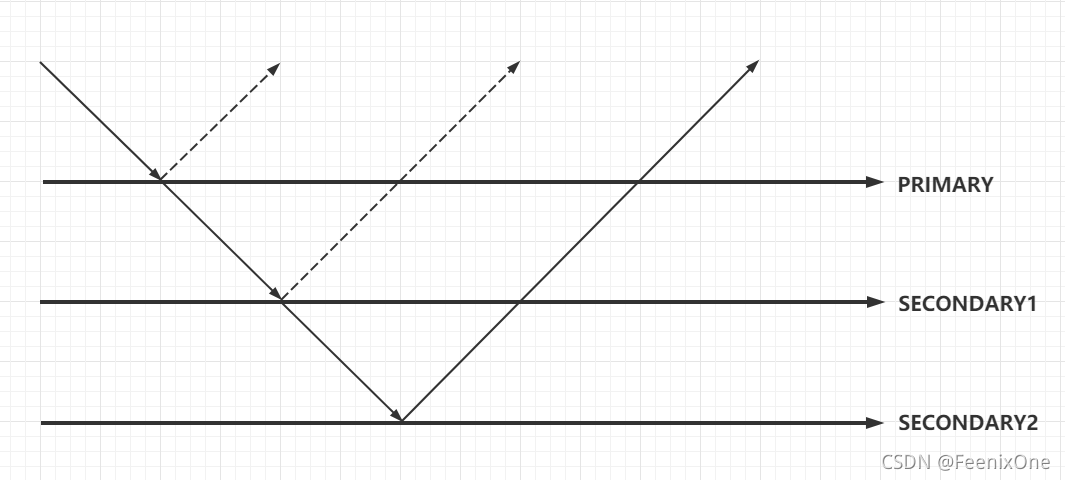
- majority:写操作需要被复制到大多数节点上才算成功。
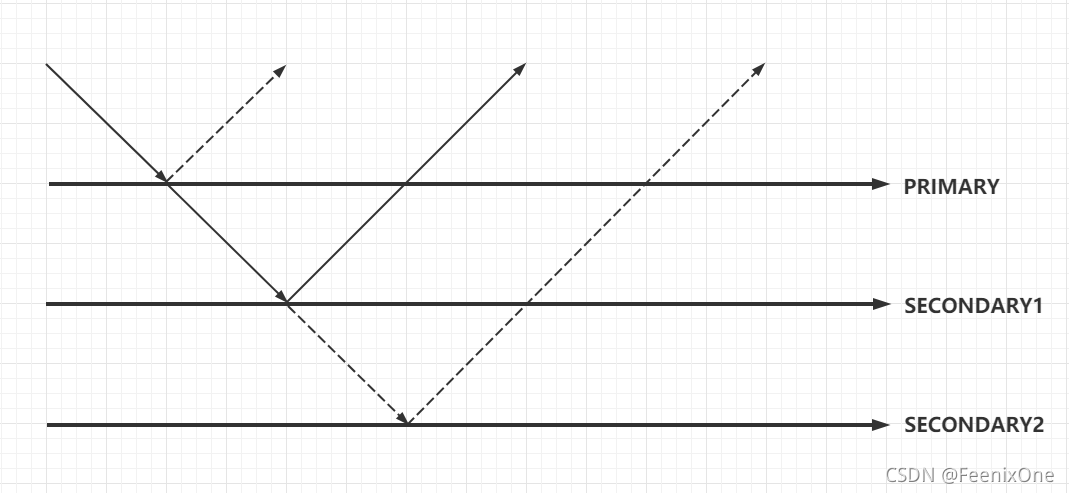
j:每个节点日志是否落到磁盘
- true:刷到磁盘
- false:仅留在内存中
wtimeout:线程阻塞等待返回客户端时间,超过这个时间以后无论有没有达到配置中的要求都返回客户端成功。wtimeout的默认值是0,如果不设置,当不满足写入节点数条件的时候,会无限期阻塞等待。
接下来我们简单验证一下这几个参数是如何控制MongoDB副本集事务:
配置延迟节点,模拟网络延迟:

目前副本其中有三个节点,手动将第3个节点成员设置网络延迟:
conf = rs.conf()
conf.members[2].secondaryDelaySecs=10
conf.members[2].priority=0
rs.reconfig(conf)
看一下网络延迟是否设置成功:

数据库清空后,重新进行数据插入演示:
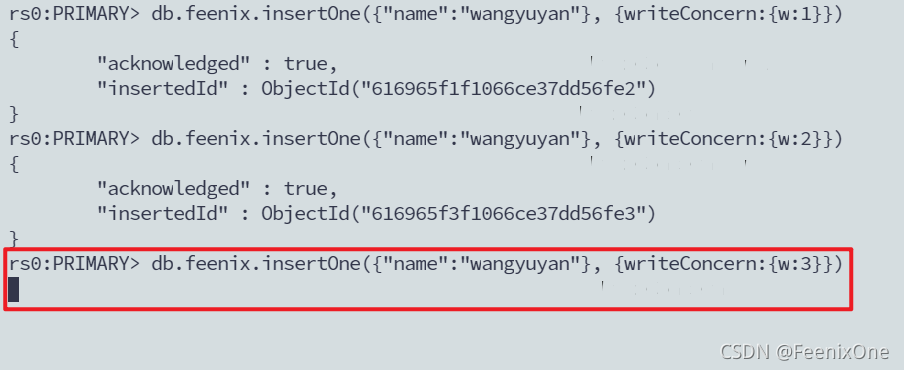
当 w:3 时,因为要等待第3个成员节点同步完数据以后才能返回客户端插入成功,所以当数据插入以后没有像 w:1 和 w:2 时立马返回成功,而是进入了阻塞等待,直到10秒钟之后才返回客户端插入成功。
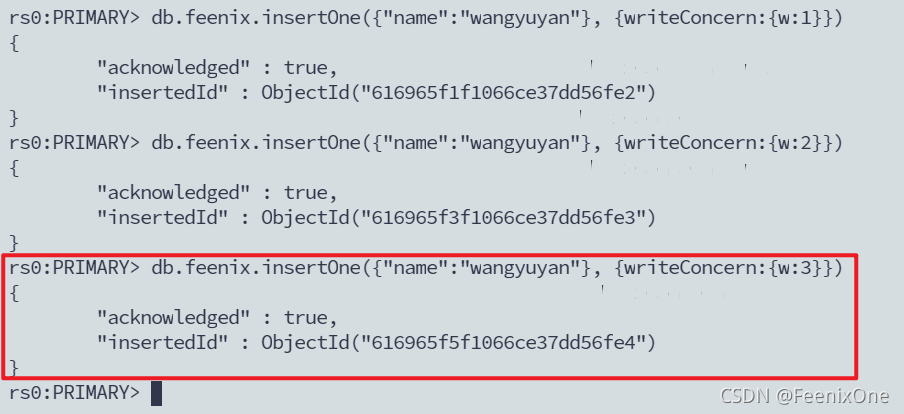
而 w:majority 却并不受到影响,因为已经有两台写入成功,第3排有没有写入成功已经不重要了。

当设置了 wtimeout:5000 时,即便规定时间之内第3台还没有同步数据,但是此时还是要返回给前端结果,只不过在返回的时候更加详细的说明了返回的情况。这算不上是一种报错,只能说是一种警告,因为副本其中的数据在经过一段时间以后,最终还是趋向于一致性。

writeConcern增加了写操作的延迟时间,但不会影响系统吞吐量,也不会显著增加服务器压力,因为写操作最终都会同步到所有节点上,只是影响了写操作的响应时间。综合所有场景来看,majority写延迟是最优,而在实际生产环境中,企业也多将w设置成majority。
2、readPreference
readPreference决定读取的数据来自哪个数据节点,可选值:
- primary(默认):只读取主节点
- primaryPreferred:优先读取主节点,如果不可用则选择从节点;
- secondary:只读取从节点;
- secondaryPreferred:优先读取从节点,如果从节点不可用则读取主节点;
- nearest:读取最近的节点。
使用场景:
- 适用于主从复制延迟很低或者基本无延迟场景,譬如用户下订单后马上跳转到订单详情页:primary / primaryPreferred
- 适用于不太要求时效性场景,譬如查询历史订单:sencondary / sencondaryPreferred
- 适用于时效性不高,但是资源需求量大,避免影响线上资源,譬如业务监控报表统计:sencondary
- 适用于国际化业务,数据中心同步的数据:nearest
注:以上配置只能控制读取一类节点,比如读取secondary。但是secondary中可能有N个节点,还不能达到精准读取,如果想要实现控制精准读取,可以设置副本集tag:
members[n].tags={“<tag1>”:”<string1>”, “<tag2>”:”<string2>”, …..}
譬如:conf=rs.conf(), conf.members[1].tags={region:”south”, datacenter:”A”}
使用方法:
- Mongo Shell:db.collection.find().readPref(“secondary”)
- MongoDB驱动API:MongoCollection.withReadPreference(ReadPreference readPref)
- MongoDB连接字符串(推荐使用):mongodb://<ip>:<port>,<ip>:<port>/test?connect=replicaSet&secondaryOk=true&replicaSet=rs0&readPreference=sencondary
3、readConcern
readConcern决定当前节点上的数据那些是可读取的,类似于关系型数据库的隔离级别,可选值:
- available:可读取所有可用的数据
- local(默认):可读取所有可用且属于当前分片的数据
- majority:可读取在大多数节点上提交完成的数据
- linearizable:线性化读取数据
- snapshot:取最近快照中心的数据
available 和 local 在副本集中二者是没有区别的,主要的区别体现在分片集群上。譬如一个 chunk 正在从 shard1 向 shard2 迁移,再迁移过程中部分数据会在两个 shard 中同时存在,但是 shard1 仍然是 chunk 的负责方,config 中记录的信息 chunk 仍属于 shard1。此时如果读取 shard2 中数据:
available >>>>> 可读取 shard2 上所有数据,包括正在迁移的 chunk
local >>>>> 只读取原来 shard2 上负责的数据,正在迁移的 chunk 属于 shard1 负责则不可读取
majority 相当于关系型数据库的READ COMMITED
linearizable 和 majority 最大差别是保证绝对的操作线性顺序,在写操作自然时候发生后的读操作,一定可以读到之前的写,相当于关系型数据库的 Serializable
开启 readConcern 后,snapshot 存在内存中,增加了 cache 维护压力,对心梗会有一定的损耗,性能大约降低30%左右。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/111938.html

