
SQL语句中使用索引,是需要遵守一些准则的,否则极有可能导致索引失效,这篇文章主要就是介绍索引使用过程的一些注意事项。
一、数据准备
建立一张员工表:
DROP TABLE IF EXISTS employees;
CREATE TABLE employees (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
age int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
position varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
hire_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (id),
KEY idx_name_age_position (name,age,position) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
该表除了主键索引外,还有一个联合索引idx_name_age_position,该联合索引字段的顺序是name,age,position,在联合索引中,字段的顺序是非常重要的,这在《索引基础》这边文章中有做过介绍。
然后为该表添加三条数据:
INSERT INTO employees (id, name, age, position, hire_time) VALUES (1, 'LiLei', 22, 'manager', '2022-03-24 18:26:32');
INSERT INTO employees (id, name, age, position, hire_time) VALUES (2, 'HanMeimei', 23, 'dev', '2022-03-24 18:26:39');
INSERT INTO employees (id, name, age, position, hire_time) VALUES (3, 'Lucy', 23, 'dev', '2022-03-24 18:26:45');
二、索引使用
2.1 最左前缀法则
只有联合索引中部分字段参与查询时,也是可以使用该联合索引的,但使用索引的前提是需要满足最左前缀法则,最左前缀法则指的是查询从索引的最左前列开始并且不跳过索引中的列。简单来说就是这部分字段对应的数据记录,在联合索引的B+树结构上有序的,这样才能索引。
以下面三个SQL语句为例(联合索引idx_name_age_position):
1 EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
2 EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
3 EXPLAIN SELECT * FROM employees WHERE position = 'manager';
上面这三个SQL语句,只有第一个可以使用索引,剩余两个都不能没法使用索引。
分析第二个SQL,联合索引是按照name,age,position的顺序进行排序,在name未知时时,age和position并不一定是有序的,所有如果使用索引就需要遍历所有的记录。
而在第三个SQL中,postion列在age和name不确定的情况下,它也不是有序的,如果要使用索引就需要遍历所有联合索引的子节点。
注:第二和第三个SQL没有使用索引的另外一个原因是查询的结果字段,联合索引并不完全具备,所以还需要回表操作,而回表操作是非常耗时,但如果查找的字段联合索引中有,那么这两个SQL也是可能走索引的。
比如把SQL改成下面这样:
EXPLAIN SELECT name FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT name FROM employees WHERE position = 'manager';
所以,需要注意的是,能不能走索引并不完全受限于这些准则,而完全是由MySQL内核通过成本分析来决定是否走索引的。
2.2 不在索引列做任何操作
如果对索引列进行计算、函数、(自动or手动)类型转换会导致索引失效而转向全表扫描
索引失效的原因仍然是通过计算,原本有序的索引可能就变得无序了,无序就意味着要扫描所有记录,当然也就不能使用索引了。
比如下面的SQL:
无操作:
函数操作:

对于这个列子,可能会比较好奇,name列原来是有序的,使用left()函数截取后也还是有序的,为什么不能使用索引呢?
因为有的函数操作后还是有序,而有的函数操作后就是无序的,MySQL内部有那么多函数,不可能每个函数还要记录操作后是否有序,所以MySQL就简单粗暴,只要使用了函数操作,就不能使用索引。
2.3 范围条件右边的列不能使用索引
存储引擎不能使用索引中范围条件右边的列,看下面的SQL:

根据执行计划的key_len字段可以计算出,该SQL只使用了name和age这两个列的索引
上面这条SQL,只有前面两个列使用了索引,而position列没有使用索引,还是看B+树的结果,在name列固定时,age > 22的范围中,age依然是有序的,但此时position列并不一定是有序的,自然就不能使用索引。
所以要从SQL看出能不能使用索引,就看它的条件对应在联合索引中是不是有序的。
2.4 尽量使用覆盖索引
覆盖查询就是只访问索引的查询(索引列包含查询列),减少 select * 语句,可以减少回表操作,自然就能使用索引了。
使用覆盖索引:

未使用覆盖索引:

2.5 少用不等于、not in 、not exists
使用不等于(!=或者<>)、not in 、not exists 的时候可能无法使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引。

2.6 少用is null,is not null
is null,is not null 一般情况下也无法使用索引

2.7 模糊查询通配符不要在前面
like以通配符开头(‘$abc…’)mysql索引失效,因为通配符在前时,完全不知道开头是什么,就只能全表扫描了。
通配符在前,索引失效:
通配符在后,索引生效:

通配符在后索引会生效,是因为这里面涉及到一个索引下推的概念,在后面索引优化部分会详细介绍。
解决通配符在前索引失效的办法:
1、使用覆盖索引,查询字段必须是建立覆盖索引字段
2、如果不能使用覆盖索引则可能需要借助搜索引擎
2.8 字符串不加单引号索引失效
底层会将数字进行转换,变成字符串,类型转换就会导致索引失效。

2.9 少用or或in
用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评 估是否使用索引,详见范围查询优化。or可以改为union,in可以该为between或exists,或者代码里面通过多线程来解决

2.10 缩小查询范围
范围查询时,如果范围太大,也有可能会导致全表扫描,所以尽量缩小查询范围。
为age字段建立一个单值索引,比较查询范围大小对索引的影响:
优化前:

优化后:
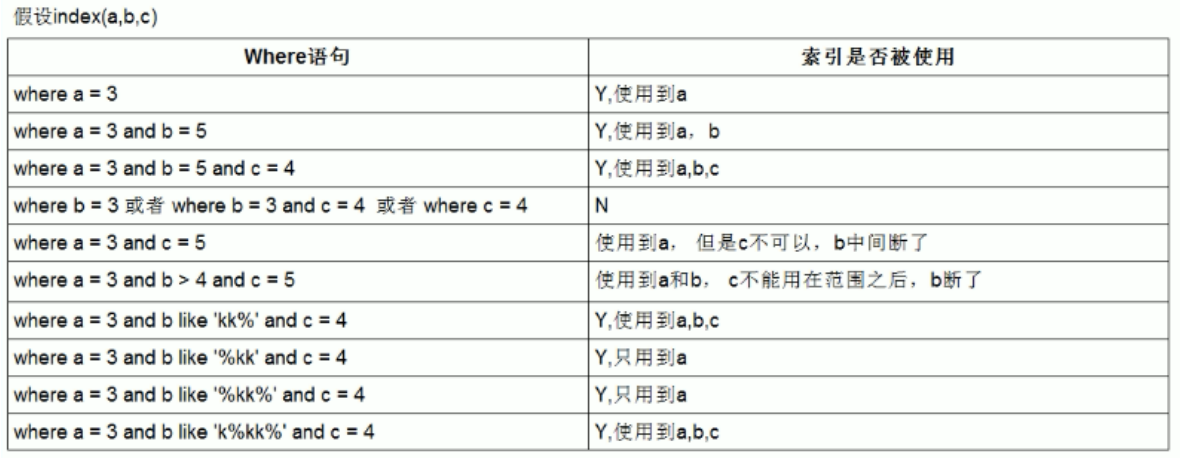
三、索引使用总结
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/112100.html

