
1、安装docker
2、拉取 ubuntu镜像
# 如果不指定版本号的话,默认拉取最新的ubuntu版本
docker pull ubuntu
3、创建容器
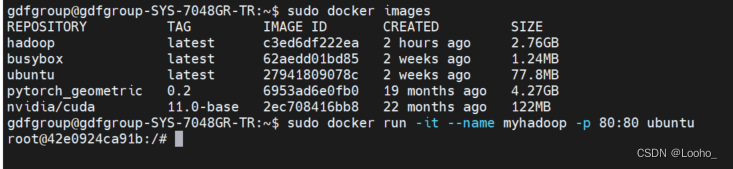
# 1.查看已拉取的镜像
docker images
# 2.创建容器
docker run -it --name myhadoop -p 80:80 ubuntu
# docker run :创建并运行一个容器
# -i: 以交互模式运行容器,通常与 -t 同时使用;
# -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
# --name:给容器起一个名字,比如叫做:myhadoop
# -p:将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是docker容器端口
# ubuntu:容器名称
注意!注意!注意!我是在服务器上搭建的,前面有sudo。你们注意辨别
# 3.更换国内源
sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
sed -i s@/security.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
apt-get clean
apt-get update
4、安装java
apt update
apt install openjdk-8-jdk
java -version # 检查安装成功
update-alternatives --config java # 查看安装路径
5、配置hadoop集群常用工具:vimip、config、ssh
apt install vim
apt install net-tools
apt-get install openssh-server openssh-client
cd
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
echo "service ssh start" >> ~/.bashrc
6、下载hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local/
cd /usr/local/
mv hadoop-3.2.1 hadoop
7、配置环境变量
vim /etc/profile
加入
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 # 这个根据自己的地址添加
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
我在用 docker 的时候发现 /etc/profile 并没有默认开机执行,所以在 ~/.bashrc 里加了一句:
echo "source /etc/profile" >> ~/.bashrc
8、修改hadoop配置文件
# 重定向hadoop配置文件目录
cd $HADOOP_CONF_DIR
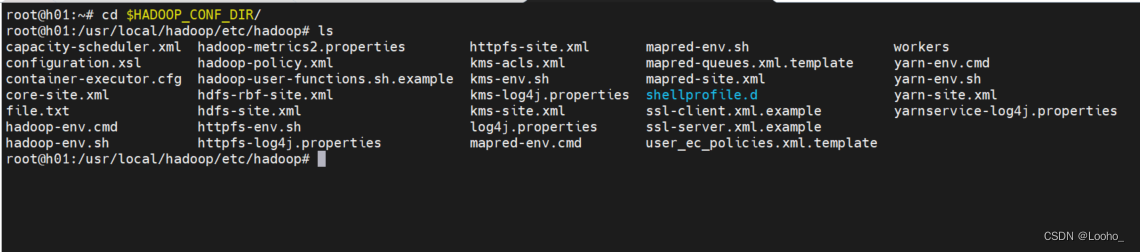
(1)打开hadoop-env.sh,添加下面的语句
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)打开core-site.xml,添加下面的语句
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://h01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
</configuration>
(3)创建文件夹
mkdir /data/hadoop/tmp
mkdir /data/hadoop/hdfs
mkdir /data/hadoop/hdfs/name
mkdir /data/hadoop/hdfs/data
(4)打开hdfs-site.xml,添加下面的语句
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/data/hadoop/hdfs/data</value>
</property>
</configuration>
(5)打开mapred-site.xml,添加下面的语句
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(6)打开yarn-site.xml,添加下面的语句
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
9、提交(保存)docker镜像
docker ps -a # 找到当前容器id
docker commit -m "install haddop" 8a2a24b54e6e hadoop
# 8a2a24b54e6e:容器id
# hadoop:镜像名
10、建立集群
(1)打开3个终端,分别输入以下命令,创建并启动容器
启动 3 个容器
docker run -it -h h01 --name h01 -p 9870:9870 -p 8088:8088 hadoop /bin/bash
docker run -it -h h02 --name h02 hadoop /bin/bash
docker run -it -h h03 --name h03 hadoop /bin/bash
# -h:指定容器的hostname
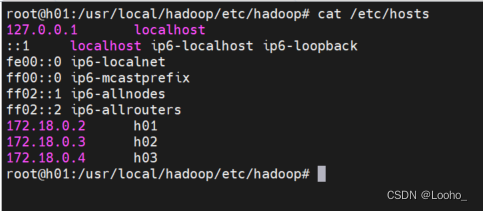
(2)输入 cat /etc/hosts查看当前容器的ip,如查看h01 IP为172.17.0.3
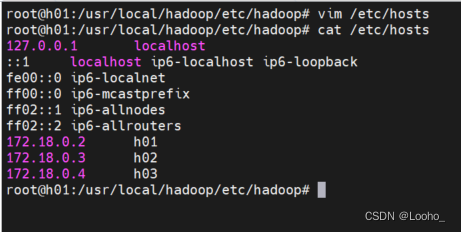
(3)编辑3个容器的hosts,把每一个主机和ip保存进去
(4)在h01主机输入ssh h02 等测试h01能否正常连接h02(这里建议全部ssh一遍,避免后面启动hadoop要输入yes或者报警告)
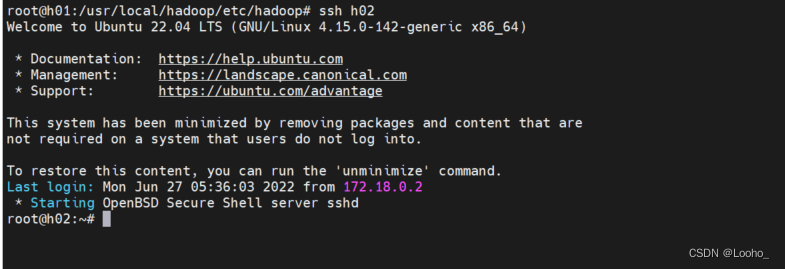
(5)到这里,还差最后一个配置就要完成hadoop集群配置了,打开h01上的workers文件(把原先的默认值localhost删掉,输入三个slave的主机名:h02,h03)
(6)启动hadoop集群
# 第一次第一次启动,务必要format一下namenode,后面再启动就不需要format了
hdfs namenode -format
# 启动集群
start-all.sh
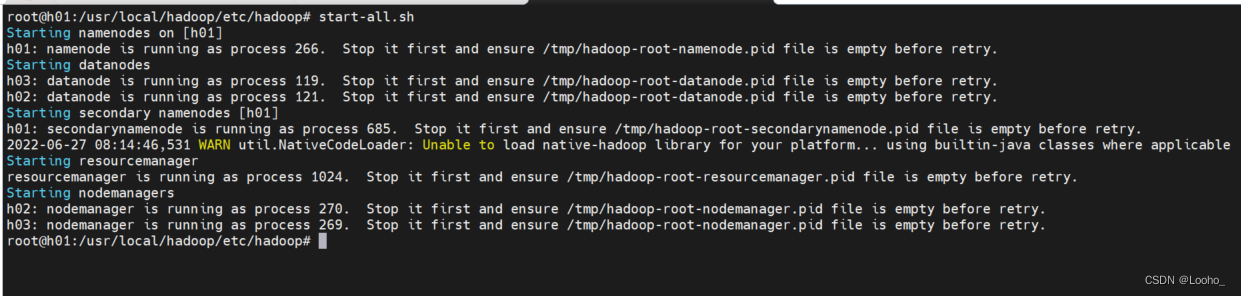
(7)查看各节点状态
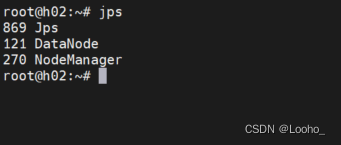
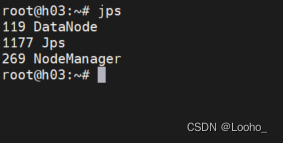
(8)查看文件系统状态
hdfs dfsadmin -report
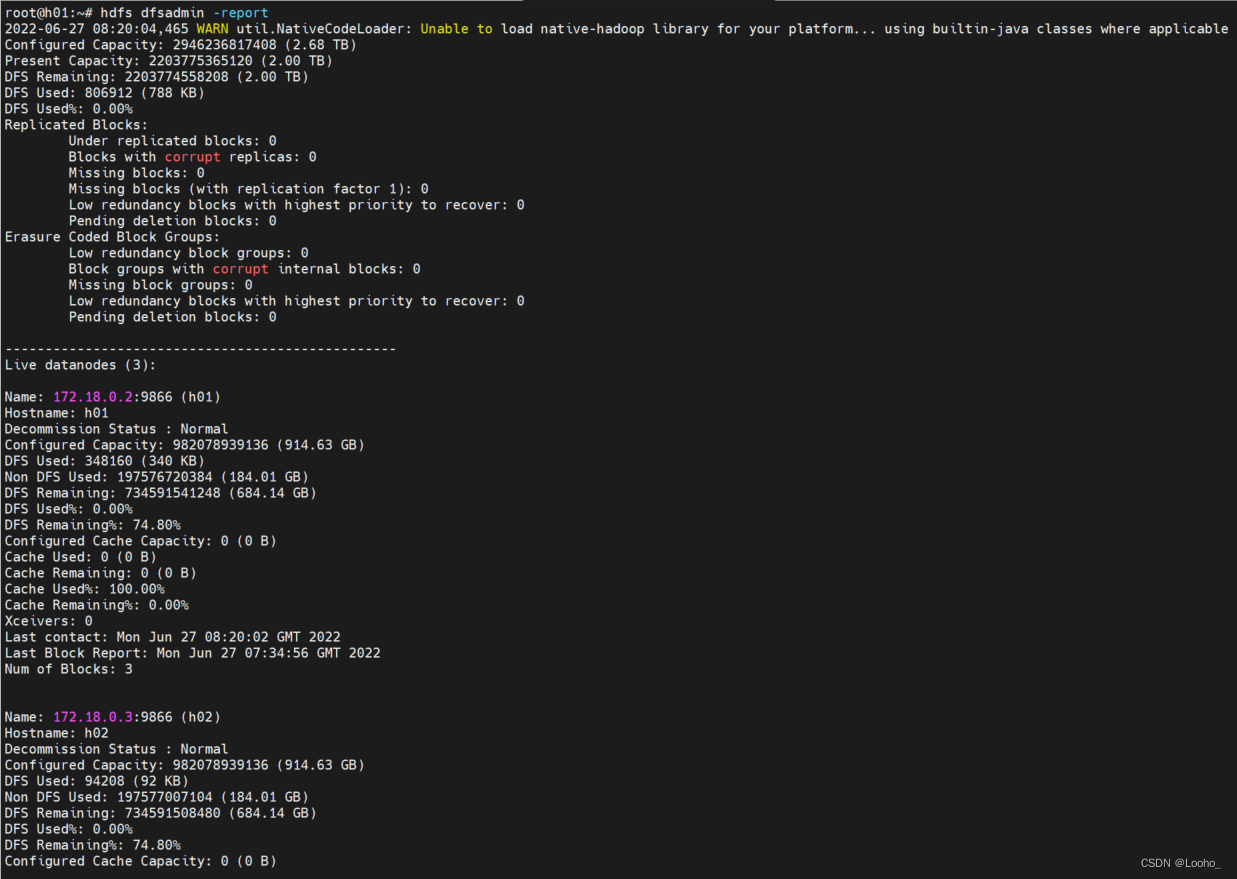
11、测试hadoop
(1)运行内置 WordCount 例子,以 license 作为统计词频的文件
cat $HADOOP_HOME/LICENSE.txt > file.txt
(2)将文件传入 hadoop
hadoop fs -ls /
hadoop fs -mkdir /input
hadoop fs -put file.txt /input
hadoop fs -ls /input
(3)运行hadoop自带的词频统计的例子
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output
(4)显示结果
root@h01:~# hadoop fs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2020-04-07 12:34 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 35324 2020-04-07 12:34 /output/part-r-00000
root@h01:~# hadoop fs -cat /output/part-r-00000
到此你的hadoop的集群环境就配置好啦,一起来环游大数据时代吧
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/114400.html

