
安装包准备
操作系统:ubuntu-16.04.3-desktop-amd64.iso
软件包:VirtualBox
安装包:hadoop-3.0.0.tar.gz,jdk-8u161-linux-x64.tar.gz
1. 环境准备
使用VirtualBox和下载的ubuntu镜像文件新建三个Ubuntu操作环境,具体配置如下:
| 用户 | 内存(G) | 磁盘空间(G) | | ——– | —– | ——- | | hadoop01 | 1.5 | 10 | | hadoop02 | 1.5 | 10 | | hadoop03 | 1.5 | 10 |
2. 网络环境准备
点击VirtualBox右侧“全局工具->主机网络管理器”,点击新建,并且勾选DHCP服务器中的启用服务器,其余的按照默认配置点击应用即可,这个过程相当于在VirtualBox中创建了一个名称为vboxnet0的路由器:
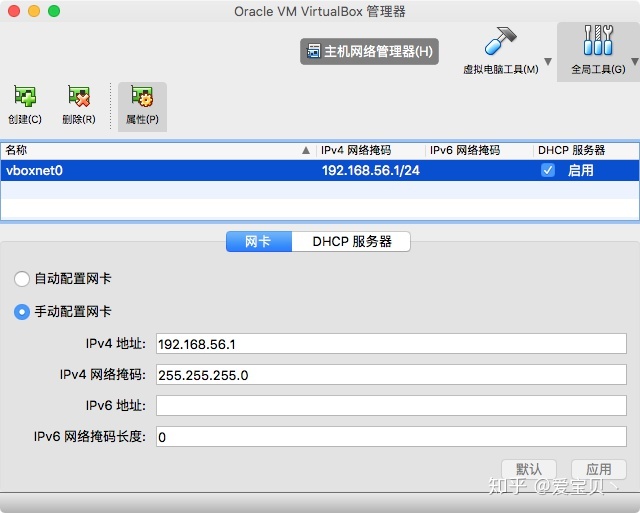

关闭创建的每一台虚拟机,然后分别选中每一台虚拟机,点击“设置->网络->网卡2”,启用网络连接,并且选择连接方式为“仅主机(Host-Only)网络”,界面名称为刚刚创建的vboxnet0。
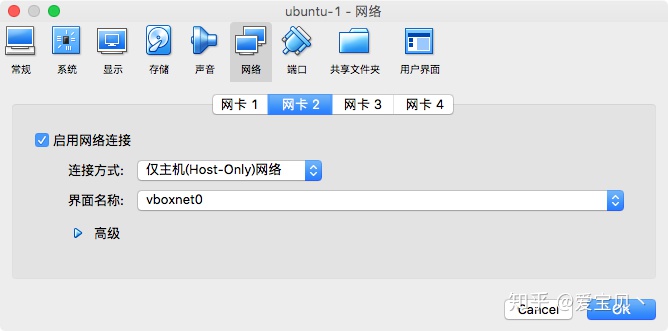
这里需要注意一定要在关闭虚拟机的状态下配置网卡2,因为在运行过程中的虚拟机是不允许配置网卡的。另外,这里网卡1和网卡2的区别在于网卡1用于供给虚拟机连接外部网络的,虚拟机通过网卡1连接VirtualBox,再通过VirtualBox连接外网;网卡2则相当于提供了一个路由器,供给三台虚拟机相互之间以及与主机之间进行连接的。
打开一台虚拟机,执行以下命令安装vim(默认情况下,Ubuntu是不带vim的):
sudo apt-get install -y vim
执行以下命令查看当前网络地址:
ifconfig
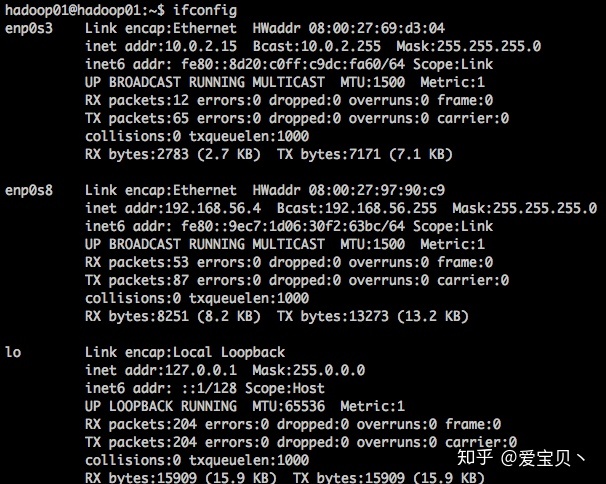
将如下配置添加到/etc/network/interfaces文件中,为当前虚拟机配置静态ip:
auto enp0s8
iface enp0s8 inet static
address 192.168.56.4
netmask 255.255.255.0
gateway 192.168.1.1
dns-nameservers 202.120.111.3
如此按照上述方式对另外两台虚拟机配置网络环境即可。
这里三台虚拟机的用户与ip分别配置如下:
| 用户 | ip | | ——– | ———— | | hadoop01 | 192.168.56.4 | | hadoop02 | 192.168.56.3 | | hadoop03 | 192.168.56.8 |
3. SSH免密登录
由于Ubuntu没有ssh客户端,可以执行如下命令为每台虚拟机安装ssh客户端:
sudo apt-get install -y openssh-server
安装完成后执行如下命令生成ssh公钥:
ssh-keygen -t rsa
该命令执行期间一直按回车即可。公钥生成后会在用户目录~下生成一个.ssh文件夹,里面包含id_rsa和id_rsa.pub两个文件。
将三台虚拟机生成的id_rsa.pub文件中的内容都复制到同一个文件中,命名为authorized_keys,并且将该文件在每台虚拟机的.ssh文件夹下都创建一份,该文件相当于为其中的每个公钥所指代的机器提供ssh登录的权限,由于三台虚拟机的authorized_keys都有各自的公钥,因而其相互之间可以通过ssh免密登录。示例authorized_keys文件如下:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDFez1asGIktruVI53uJHT3s8UZHoIi3X98G5mFV/7+MAs8xXeXV7HbHfi2FfJnMl/qTY/W4VZWdoFLizDBrtUDHTtigVxs5uK4re8qlvSApmqy9Xi0c+qpLKHSeFBpCSqKgngrwE/+DOFnkkTSH/hv6bIpGPTYArpOXdY203vyt6/MM/HKed0WeAcDbCdfKjke4Q2IHi6APghwjML3oD1N0rNGU28SRc8iGdg+vGp6Ajkr034VZCx7fY/BmjYhxPvJ6c5hnVSwqik05xdw2Dh+6eLkiOOnO1LknFw7KdFqa1435sOxxHhar8+ELiKu/mYzVcZMizN0AiPQGxjP96fl hadoop01@hadoop01
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDDCXKskhH0VFzh8KrJt3PmbR/Yxbgv5le4iEdvIPWWXAC7XDuPGrz1XH/ZYlZWauyV/LsMN3qjbeHzyfeuuNuV6Skpy/lofsIO88/XH0NFYcAxQtIQfSLwbOGVWziibOPY+gI8Bnzeb7hAYk10V2cI26hKWMpEHxOu/lCxcNuM5Y+CBs2kx2KzzvwgUjF12P6Jz4+SguCERi+Cz1JQ0YuXHBRLXGgwXMRyYUlC3KxIvyeZzI0+Gpew4nTFFXBoDIEaWn9Ma8+AcHNm9ejnO9ChSCN3zXJf7nnaXKUmi5jyQu88e+qmhDt2Pzj0E/kaKRkxso7e+sgHMBp8eXpJu/eT hadoop02@hadoop02
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCm4yk0TVpfhU0jSf4PMH60fOhMYrxCI9DeG/tcs0LTAUHGatuY3XRd6X3B5tShUlCvr9M1DVRgszk0Nz9VOzgqFsIXUxJLAir4dQIj+nVY0QcyTwzwbqm93YDZfaoYrO9xgEriZ6XVK78bWc8bMWpc9z35Kp4U6ytTQUufVwnsVXgAcBN6rQ/ZZFiJvCwnsZDtNsT/zVNWdrnVMKFbm+0rQHzt+jQEgfunwQeEkj8G21iPMpG9MxuHLmzOx+7XaxNLl/P2oHto8lQJgm0DYLJy6JLPa3rkd+NuBxYoqRxr1A1eC/7f3480bz+HHym5e0dSh8HuG3XJihIoR1SLm1Sd hadoop03@hadoop03
按照上述配置完成之后,可使用如下命令在一台虚拟机上登录另外两台虚拟机(这里hadoop02和hadoop03为目标机器的用户,@符号后的内容为目标机器的ip地址):
ssh hadoop02@192.168.56.3
ssh haddop03@192.168.56.8
这里需要注意,如此配置之后即可按照上述方式使用ssh登录免密登录其他机器,但是这种配置还不完全够,因为在后续使用hive和hbase的过程中,其集群内部是使用如下方式登录的:
ssh hadoop02
ssh hadoop03
这种登录方式其实可以理解为别名登录,其将hadoop02指代为hadoop02@192.168.56.3,在ssh中可以通过配置config文件来设置别名,该config文件放置在.ssh文件夹下即可,具体的配置如下:
Host hadoop02
hostname 192.168.56.3
user hadoop02
Host hadoop03
hostname 192.168.56.8
user hadoop03
4. jdk和Hadoop安装
需要说明的是如下jdk和hadoop安装只是一台虚拟机上的配置,其余两台虚拟机的配置方式与其类似。
将下载的jdk和Hadoop安装包使用tar命令解压,如:
tar -zxvf jdk-8u161-linux-x64.tar.gz
使用ln命令为jdk和hadoop解压包创建软连接,创建软连接的优点在于如果后续需要更改jdk或者Hadoop的版本,只需要把软连接指向新的解压目录即可,而不需要到处更改配置的环境变量,因为环境变量都是基于软连接配置的:
ln -s jdk1.8.0_161 jdk
ln -s hadoop-3.0.0 hadoop
创建软连接之后的目录结构如下所示:
drwxrwxr-x 5 hadoop01 hadoop01 4096 2月 23 17:46 ./
drwxr-xr-x 19 hadoop01 hadoop01 4096 2月 23 20:46 ../
lrwxrwxrwx 1 hadoop01 hadoop01 12 2月 22 22:24 hadoop -> hadoop-3.0.0/
drwxr-xr-x 12 hadoop01 hadoop01 4096 2月 23 10:24 hadoop-3.0.0/
lrwxrwxrwx 1 hadoop01 hadoop01 12 2月 22 22:06 jdk -> jdk1.8.0_161/
drwxr-xr-x 8 hadoop01 hadoop01 4096 12月 20 08:24 jdk1.8.0_161/
编辑用户目录下的.profile文件,在其中加上如下内容:
export JAVA_HOME=/home/hadoop01/xufeng.zhang/jdk
export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export HADOOP_HOME=/home/hadoop01/xufeng.zhang/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CLIENT_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
保存之后,使用如下source命令才能使编辑的环境变量生效:
source ~/.profile
使用java -version命令查看配置的Java运行环境是否正常:
hadoop01@hadoop01:~/xufeng.zhang$ java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
使用hadoop version命令查看Hadoop是否配置正确:
hadoop01@hadoop01:~/xufeng.zhang$ hadoop version
Hadoop 3.0.0
Source code repository https://git-wip-us.apache.org/repos/asf/hadoop.git -r c25427ceca461ee979d30edd7a4b0f50718e6533
Compiled by andrew on 2017-12-08T19:16Z
Compiled with protoc 2.5.0
From source with checksum 397832cb5529187dc8cd74ad54ff22
This command was run using /home/hadoop01/xufeng.zhang/hadoop-3.0.0/share/hadoop/common/hadoop-common-3.0.0.jar
对于另外两台虚拟机,可以按照上述方式进行类似的配置即可。
5. Hadoop集群环境的搭建
Hadoop集群的配置,主要有如下几个文件需要修改:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
core-site.xml的配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.3:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop01/xufeng.zhang/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
hdfs-site.xml的配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.http.address</name>
<value>192.168.56.3:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.56.4:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop01/xufeng.zhang/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop01/xufeng.zhang/hadoop/data/datanode</value>
</property>
</configuration>
mapred-site.xml的配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.56.3:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.56.3:19888</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
这里需要注意的是,yarn.app.mapreduce.am.env,mapreduce.map.env和mapreduce.reduce.env三个参数一定要配上,否则在运行MapReduce任务时会报如下错误:
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
yarn-site.xml的配置
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.56.4</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>192.168.56.4:8888</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CLIENT_CONF_DIR,
$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,
$HADOOP_COMMON_HOME/lib/*,
$HADOOP_HDFS_HOME/*,
$HADOOP_HDFS_HOME/lib/*,
$YARN_HOME/*,
$YARN_HOME/lib/*
</value>
</property>
</configuration>
hadoop-env.sh的配置
这里需要着重强调hadoop-env.sh的配置,因为该配置是比较容易掉的配置,而且在执行任务的过程中没有该配置则会报找不到环境变量的错误。该配置文件中主要需要配置JAVA_HOME参数,如:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/home/hadoop01/xufeng.zhang/jdk
可以看到,在该文件中已经说明了除了OS X操作系统可以部配该变量外,其余的操作系统都需要配置。
如此,单个虚拟机上的Hadoop集群环境配置即完成了,其余的虚拟机集群环境配置和上述操作基本一致。这里有一个简便的方式,即将当前虚拟机上的配置文件拷贝到另外两台虚拟机,并且替换其Hadoop的配置文件,替换后只需要更改其中有关路径的配置,如core-site.xml的hadoop.tmp.dir更改为对应虚拟机的路径即可。
6. 集群启动
集群启动之前需要对集群每个节点的NameNode进行格式化,即初始化NameNode的相关存储环境信息。格式化命令如下:
hadoop namenode -format
格式化完成之后,分别在每台机器上执行如下命令即可启动Hadoop,该命令是Hadoop的sbin目录下的一个命令,在进行环境变量配置时已将其添加到了PATH里了:
start-all.sh
如果需要关闭Hadoop,可执行如下命令:
stop-all.sh
启动完成后可以使用如下命令在每台机器上查看Hadoop是否成功启动了:
jps
各节点的启动信息如下:
hadoop01@hadoop01:~/xufeng.zhang/hadoop/etc/hadoop$ jps
3680 Jps
3154 NodeManager
2627 DataNode
2788 SecondaryNameNode
3381 WebAppProxyServer
3038 ResourceManager
hadoop02@hadoop02:~$ jps
2883 Jps
2035 NameNode
2659 NodeManager
2152 DataNode
hadoop03@hadoop03:~$ jps
2083 DataNode
2759 Jps
2525 NodeManager
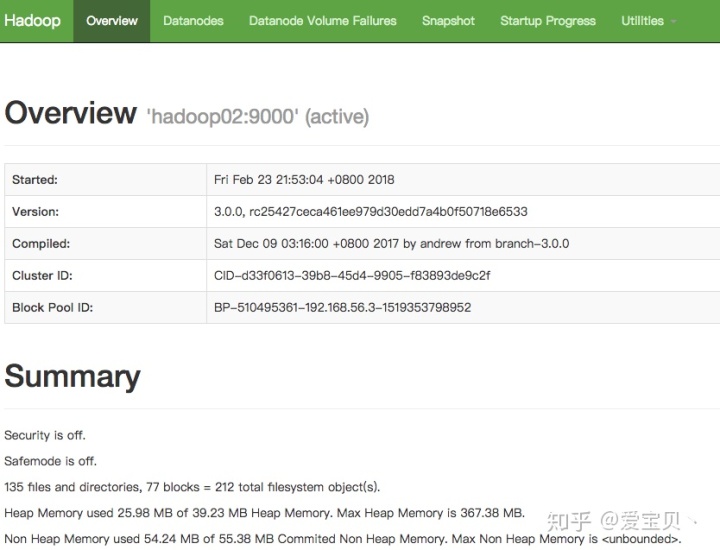
可以看到这里hadoop02机器为主NameNode节点,hadoop01为副NameNode节点;hadoop01,hadoop02和hadoop03都为DataNode节点。这里也可以打开如下链接查看各个节点的运行情况:
http://192.168.56.4:8088/
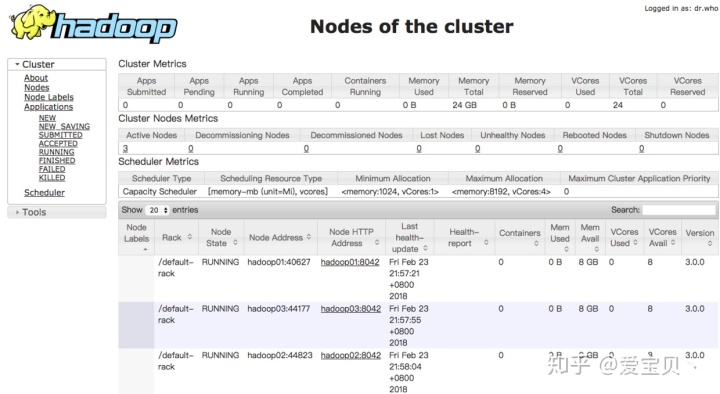
http://192.168.56.3:50070/
7. 结语
本文主要讲解了如何通过虚拟机搭建一个有三个DataName,一个主NameNode和一个SecondaryNameNode的Hadoop集群,并且讲解了在配置过程中可能会出现的问题。本人在集群的搭建过程中出现了很多问题,通过不断的查资料,最终将集群搭建起来并成功运行了MapReduce任务。这里做一个总结,一是分享给阅读者,以减少其出错的概率,二是方便后续自己再次搭建时有资料可查。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/114402.html

