
概述
课程地址:飞桨AI Studio:Python小白到精通——第四章:自动通知-邮箱里的小秘书
这一节课程讲了函数以及问题拆分的思想,使用的一个“自动爬取网站的新通知,并发送到自己邮箱”的例子。(我并没有用过那个邮箱,不好调试代码,因此这部分没太清楚)
本节的课后作业是利用爬虫写个北京地铁查询程序,查询网站:https://www.bjsubway.com/station/xltcx/,本次作业直接给出了可运行的源代码,我可以少花点脑子了,但是阅读源代码也还是挺消耗脑力的,因为源代码中并没有很多细节的解释。这次阅读过程还算流畅(可能代码本身就比较简单?)
问题记录
1、报错文件不存在,如何创建一个文件
在使用下面这段代码进行文件写入操作时,发生了报错:[Errno 2] No such file or directory,说文件不存在。
size = os.path.getsize('./' + '网页源码.txt')
if size == 0:
text = get_subway_page()
with open('./' + '网页源码.txt', 'w') as f:
f.write(text)
那怎么创建一个文件呢?可以在前面加入这段代码,在使用open()打开文件时,如果文件不存在,就会自动新建一个。
f = open('./' + '网页源码.txt', 'w')
f.close()
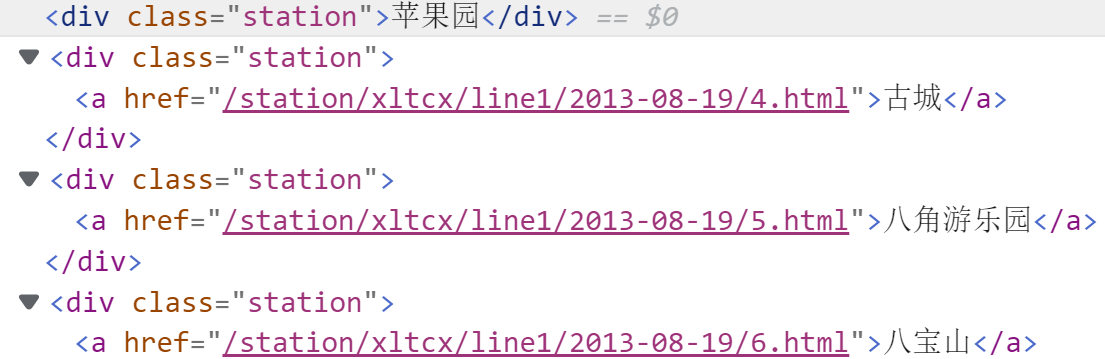
2、1号线/八通线的“苹果园”站点显示不出
在北京地铁的网站上,第一个站点是“苹果园”,但是课程给出的源代码中缺了这个站点。后面看了网站的html发现那一个站点的代码结构不一样,而课程的源代码中并没有考虑它。
小结
这一节以爬虫程序的例子讲解函数和问题拆分的思想。但我有时感觉,分得太细,模块就会变得很多,各种模块之间的调用关系就会变得复杂,此时程序同样也不太容易读懂。
程序代码
注:代码来自飞桨课程
# 1.取网页html
def get_webpage(url):
r = requests.get(url)
r.encoding = 'gbk' # 编码格式
return r.text
def get_subway_page():
url = 'https://www.bjsubway.com/station/xltcx/'
text = get_webpage(url)
return text
# 2.定位
def is_line_start_line(line):
mark = '<div class="subway_num'
if mark in line:
return True
else:
return False
def get_line_number(line):
right = line.rfind('<') # rfind()是什么
left = line.find('>')
return line[left + 1: right]
def is_target_line(line, line_num):
if is_line_start_line(line) and get_line_number(line) == line_num:
return True
else:
return False
def is_end_of_line_block(line):
mark = '<div class="line_name">'
if mark in line:
return True
else:
return False
def get_target_line_info_block(page, line_num):
target_lines = []
start_record = False
for line in page.split('\n'): # page.split()是什么
if is_target_line(line, line_num):
start_record = True
continue
if start_record and is_end_of_line_block(line):
break
if start_record:
target_lines.append(line)
return target_lines
def contain_station_info(line):
mark = '/station/xltcx/' # ?? 苹果园不一样
return mark in line
# 3.取信息部分
def get_station_info(line):
left_mark = 'html">'
left_index = line.find(left_mark) + len(left_mark)
right_mark = '</a>'
right_index = line.rfind(right_mark) # rfind()与find()返回值
return line[left_index: right_index]
def get_stations(line_info_lines):
stations = []
for line in line_info_lines:
if contain_station_info(line):
stations.append(get_station_info(line))
return stations
def composing_get_line_station(line_name, text=None):
if text is None: text = get_subway_page() # 已经有html源码就不用去网页爬取了
lines = get_target_line_info_block(text, line_name)
stations = get_stations(lines)
return stations
# 主程序
# -- step-00:创建文件
f = open('./' + '网页源码.txt', 'w')
f.close()
# -- step-01:获取网页源码,并写入文件
size = os.path.getsize('./' + '网页源码.txt')
if size == 0:
text = get_subway_page()
with open('./' + '网页源码.txt', 'w') as f:
f.write(text)
# -- step-02:从文件读取源码
with open('./' + '网页源码.txt', 'r') as f:
text = f.read()
# -- step-03:使用源码进行线路查询
road1 = composing_get_line_station('2号线', text)
print(road1)
完
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/114777.html

