
1.题目描述
描述
删除给出链表中的重复元素(链表中元素从小到大有序),使链表中的所有元素都只出现一次
例如:
给出的链表为
1
→
1
→
2
1\to1\to2
1→1→2,返回
1
→
2
1 \to 2
1→2.
给出的链表为
1
→
1
→
2
→
3
→
3
1\to1\to 2 \to 3 \to 3
1→1→2→3→3,返回
1
→
2
→
3
1\to 2 \to 3
1→2→3.
数据范围:链表长度满足
0
≤
n
≤
100
0≤n≤100
0≤n≤100,链表中任意节点的值满足
∣
v
a
l
∣
≤
100
∣val∣≤100
∣val∣≤100
进阶:空间复杂度 O(1)O(1),时间复杂度 O(n)O(n)

2.算法设计思路
总体思路:遍历一次链表,过程中删除重复的元素。
算法过程:
- 从头结点开始遍历,终止条件为当前结点的下一个结点为空。
- 对遍历到的结点,与后一个结点的值比较;若值相同,则删除后面那个结点。直到当前结点与后一个结点的值不同时,才继续遍历下一个结点。
- 结点的删除方式:将当前结点的下一个结点修改为当前结点后面第二个结点,并释放删除结点的内存。
复杂度:
- 时间复杂度:
o
(
n
)
o(n)
o(n)
- 空间复杂度:
o
(
1
)
o(1)
o(1)(指除链表本身外,额外用到的空间)
3.算法实现
注:这里并不是完整代码,而只是核心代码的模式
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
class Solution {
public:
/**
*
* @param head ListNode类
* @return ListNode类
*/
ListNode* deleteDuplicates(ListNode* head) {
// write code here
ListNode* p = head;
while(p != nullptr && p->next != nullptr){
if(p->val == p->next->val){
ListNode* t = p->next;
p->next = p->next->next;
delete t;
}
else
p = p->next;
}
return head;
}
};
4.运行结果
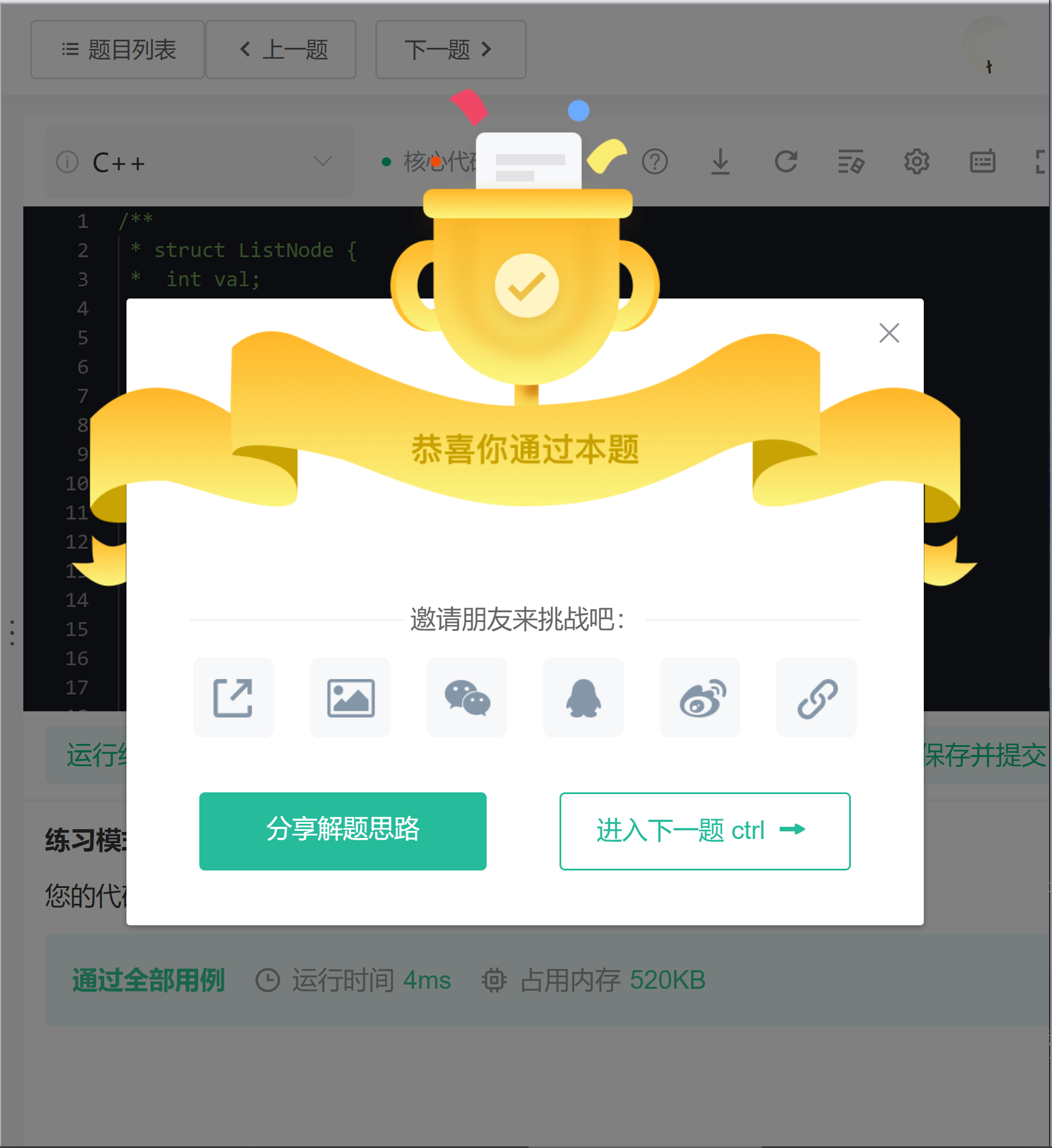
成功通过!
结束语:
今天的分享就到这里啦,快来加入刷题大军叭!
👉点击开始刷题学习👈
感谢阅读
个人主页:清风莫追
CSDN话题挑战赛第2期
参赛话题:学习笔记
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/114804.html

