
文章目录
一元三次方程的根
1. 题目描述
有形如:
a
x
3
+
b
x
2
+
c
x
+
d
=
0
ax^3+bx^2+cx+d=0
ax3+bx2+cx+d=0 这样的一个一元三次方程。
给出该方程中各项的系数(a,b,c,d 均为实数),并约定该方程存在三个不同实根(根的范围在-100至100之间),且根与根之差的绝对值>=1。要求由小到大依次在同一行输出这三个实根(根与根之间留有空格),并精确到小数点后2位。
提示: 记方程f(x)=0,若存在2个数x1和x2,且x1 < x2,f(x1)*f(x2) < 0,则在(x1,x2)之间一定有一个根。
输入一行,包含四个实数a,b,c,d,相邻两个数之间用单个空格隔开。
输出一行,包含三个实数,为该方程的三个实根,按从小到大顺序排列,相邻两个数之间用单个空格隔开,精确到小数点后2位。
样例输入
1.0 -5.0 -4.0 20.0
样例输出
-2.00 2.00 5.00
2. 问题分析与算法设计思路
1)基本思路
我使用的根的存在定理来解这个问题。对于方程
f
(
x
)
=
0
f(x)=0
f(x)=0,如果
f
(
x
1
)
∗
f
(
x
2
)
<
0
f(x_1)*f(x_2)<0
f(x1)∗f(x2)<0,则在 x1 和 x2 之间至少存在一个实根。注意根的存在定理反过来不一定成立,即
f
(
x
1
)
∗
f
(
x
2
)
>
0
f(x_1)*f(x_2)>0
f(x1)∗f(x2)>0不能说明 x1 和 x2 之间就没有根。
利用根的存在定理,我们就可以递归地对指定区间进行二分搜索。通过搜索我们将得到根的近似解。如何确定达到了需要的近似精度呢?
1)区间内有根存在,且区间长度小于指定精度
2)某点处函数值为 0
2)小心浮点数存储方式的影响
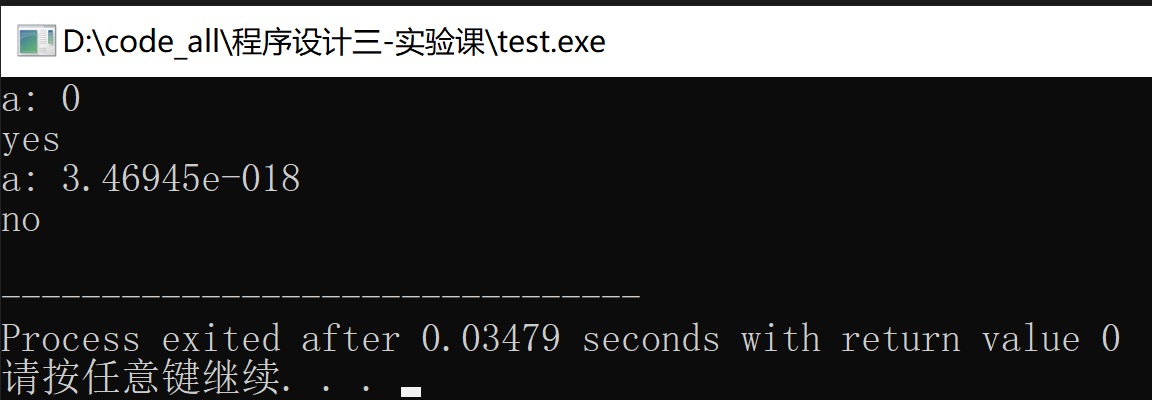
注意小数在计算机中存储的是一个近似值,直接判断浮点数相等是不安全的行为。可参考下面的程序代码。我们可以改用判断:
该浮点数与 0 的差的绝对值,是否小于某个微小值(自己设定)
#include<iostream>
using namespace std;
int main(){
double a = 0;
cout<<"a: "<<a<<endl;
if(a == 0)
cout<<"yes"<<endl;
else
cout<<"no"<<endl;
a = a + 0.05;
a = a - 0.02;
a = a - 0.03;
cout<<"a: "<<a<<endl;
if(a == 0)
cout<<"yes"<<endl;
else
cout<<"no"<<endl;
return 0;
}
运行结果

3)如何判断:一个区间是否值得继续搜索
在判断要不要对一个区间进行搜索时,由于根的存在定理的逆命题不成立,我们无法单纯地依靠它进行判断。不过可以设定一个阈值:当区间缩小到某个程度后仍然不能满足根的存在定理时,我们就认为这个区间中将不会有方程的根。
具体的区间阈值大家可以自由选取、多做尝试。我这里使用的是 1 (可能有点草率,但也通过了测试数据)。
3. 算法实现
#include<iostream>
using namespace std;
double result[3]={};//存放方程的根
int count=0;//已经找到的方程的根的数量
//前向推导函数值
//bug:之前x的类型使用的int
double fx(double can[4], double x){
return can[0]*x*x*x + can[1]*x*x + can[2]*x + can[3];
}
//绝对值
double jdz(double x){
if(x < 0) x = -x;
return x;
}
void find_gen(double first, double end, double can[4]){
if(count >= 3) return;
double mid = (first + end) / 2;
double mid_p = 0;
double fx1 = fx(can, first);
double fx2 = fx(can, end);
double fx0 = fx(can, mid);
bool cheng = (fx1>0.0001 && fx2>0.0001) || (fx1<0.0001 && fx2<0.0001);
if(jdz(fx0) - 0 < 0.0001){
result[count++] = mid;
mid_p = 0.01;
}
// printf("first %.4lf, end %.4lf, mid %.4lf\n",first, end, mid);
// printf("fx1 %.4lf, fx2 %.4lf, cheng %d\n", fx1, fx2, cheng);
// printf("result: %.4lf, %.4lf, %.4lf\n\n", result[0], result[1], result[2]);
//符合根的存在定理说明有根,但不符合并不能说明没有根
if(cheng == 0 || end - first > 1) {
if(end - first < 0.01) {
result[count++] = mid;
return;
}
find_gen(first, mid - mid_p, can);
find_gen(mid + mid_p, end, can);
}
}
int main(){
double can[4] = {};
cin>>can[0]>>can[1]>>can[2]>>can[3];
// cout<<"参数:"<<can[0]<<' '<<can[1]<<' '<<can[2]<<' '<<can[3]<<endl;
find_gen(-100.0, 100.0, can);
cout<<result[0]<<' '<<result[1]<<' '<<result[2]<<endl;
return 0;
}
4. 运行结果

5. 算法分析
在对有序数组的搜索中,二分搜索是一种高效的方法。对长度为n的数组的搜索,时间复杂度为:
o
(
l
o
g
(
n
)
)
o(log(n))
o(log(n))。
与数组的二分搜索的不同之处:
我们通常仅需从数组中找到一个值,因此每次搜索,剩余的搜索空间将变为原来的一半;而一个方程却可以有多个根。在决定是否放弃一个搜索区间时,我没有很合适的判断标准。
因此,前面说的搜索到区间长度小于某个阈值的方法,其实更像是在遍历。只有在某个确定有根存在的、长度已经小于阈值的区间上,才更像是一次二分搜索。
由“递归中的遍历本质”产生的优化方法:
鉴于该递归算法中实际上隐藏着一个遍历阶段,而递归程序本身又是一种时间开销大的写法。其实我们还可以干脆一点:就使用循环遍历+对存在根的小区间二分搜索。有兴趣的小伙伴可以自己尝试一下!
于是,在考虑该算法的时间开销时,可以分为两个阶段:遍历阶段和二分阶段。
遍历阶段的时间复杂度和初始搜索区间长度以及设定的阈值有关;而二分阶段的时间复杂度和设定的阈值以及要求的结果精度有关。也就是说,输入的规模仅仅是影响算法时间开销的一个因素。因此,时间复杂度的分析超出了我的分析能力,就先不具体分析了叭!😅
感谢阅读
个人主页:清风莫追
CSDN话题挑战赛第2期
参赛话题:学习笔记
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/114810.html

