
前言
活动地址:CSDN21天学习挑战赛
🚀 个人主页:阿阿阿阿锋的主页_CSDN
🔥 本文属于个人笔记,比较乱
🔥 希望能和大家一起加油,一起进步!

3. 神经网络的学习
摘抄:
-
Python 中如果定义的是简单的函数,可以使用 lambda 表示法。使用 lambda 的情况下,上述代码可以如下实现。
f
=
l
a
m
b
d
a
w
:
n
e
t
.
l
o
s
s
(
x
,
t
)
f = lambda w: net.loss(x, t)
f=lambdaw:net.loss(x,t)
d
W
=
n
u
m
e
r
i
c
a
l
g
r
a
d
i
e
n
t
(
f
,
n
e
t
.
W
)
dW = numericalgradient(f, net.W)
dW=numericalgradient(f,net.W)
-
因为这里使用的数据是随机选择的 mini batch 数据,所以又称为随机梯度下降法(stochastic gradient descent)
收获:
-
python是弱类型的,2-0.0001会是个小数而不会自动给你取整而numpy.array是有类型的,你传入的是整数,那么它的类型就是整型,你传入的是小数,它的类型就是浮点型你像整型数组里传入小数,会进行强制转换
-
某点处的函数值下降最快的方向,取反方向就是函数值上升最快的方向吗?答案应当是肯定的,想二维函数虽然变化方向有很多会不好考虑,但却可以分为两个一维函数来思考,因为两个自变量的变化本来就是相对独立的。
-
学习率就像每次每个自变量移动的距离
-
python中虽然没有函数重载,但代码中可以有重名函数。第一种情况是新定义的代替旧的;第二种情况是类中的和全局的,可类比全局变量和局部变量。
porblem:
- 鞍点:从某个方向上看是极大值,从另一个方向上看则是极小值的点
- 高斯分布
- 神经网络的梯度那一节,权值W的形状是不是有问题?
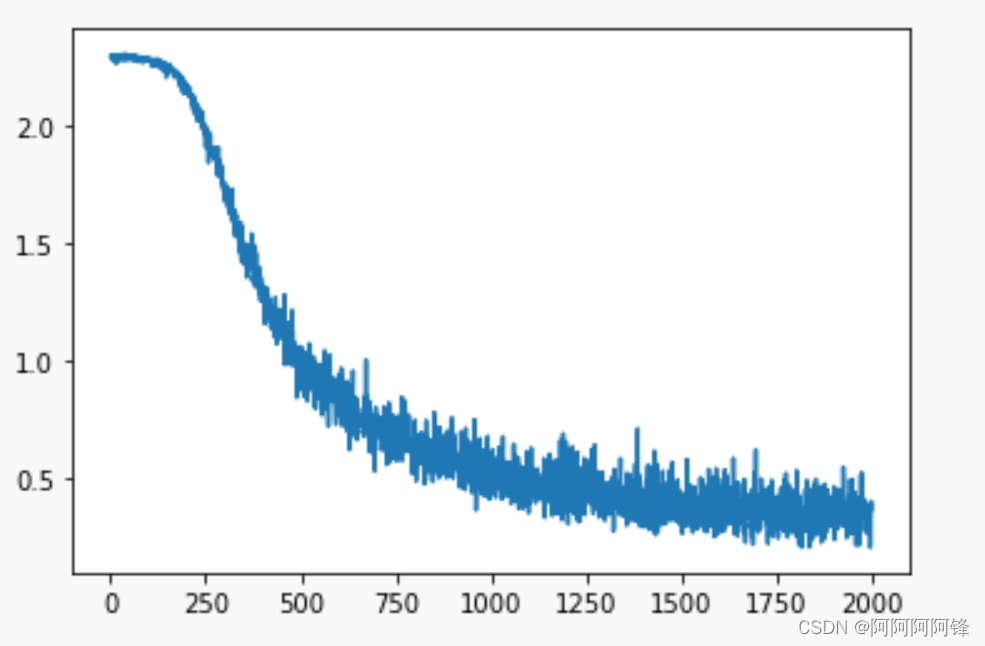
- 为什么随着训练次数的增多,损失的上下波动会变大?

单词:
- dimension 方面
- descent 下降
参考:
深度学习入门:基于Python的理论与实现 (斋藤康毅)
感谢阅读
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/114828.html

