
一、场景分析
今天来爬一下我个人的博客,将我的文章标题和地址归纳到一个Excel中,方便查看。
wshanshi能有什么坏心思呢?她只是…想总结下自己文章和相关的地址而已…

二、界面简单分析:
开发都懂得,打开调试模式。选择Elements,然后找到存放文章的盒子,如下图。
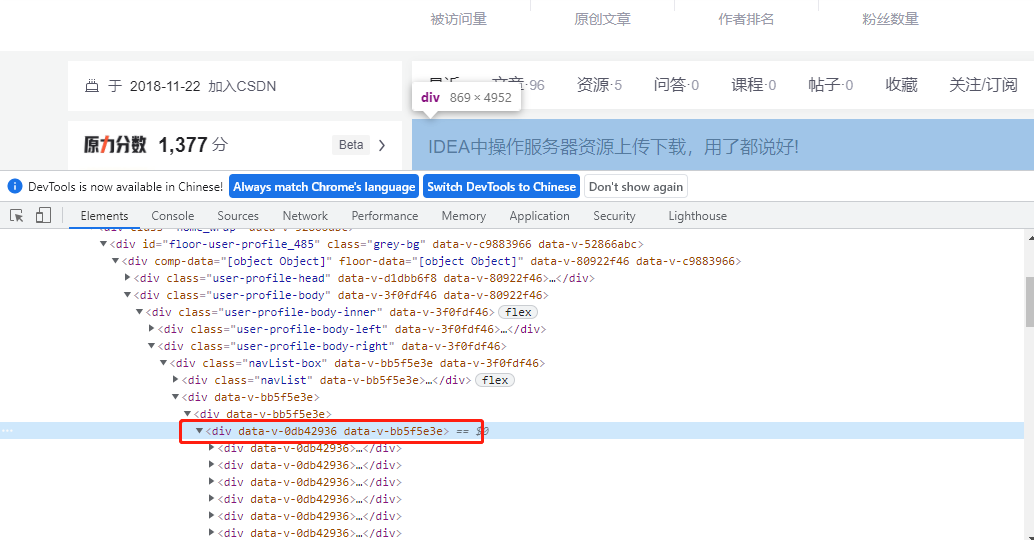
分析后发现,每个盒子对应存放一个文章相关的信息。

仔细再看,可以发现所有的article标签的class都是同一个。
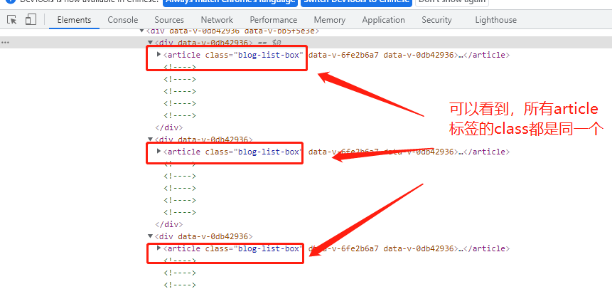
哎呦,都长一样,这就好整了。通过类选择器结合标签,一下就能拿到了。

点开任意一个文章div,会发现里面里面有文章超链接,标题,描述信息。
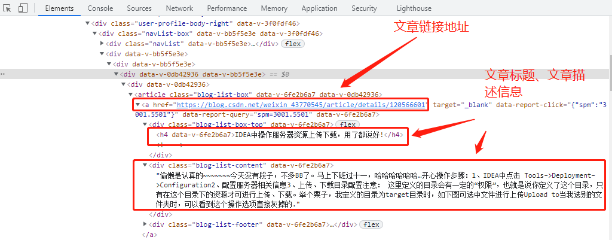
结合此次操作的终极目标,得出了以下操作步骤。

场景也分析完了,就开搞白。
楼主将用两种方法(Python、Java)进行个人文章的数据收集。干就完事…

三、Python实现方式
示例版本:Python 3.8
安装包:requests、beautifulsoup4、pandas
库包安装命令(windows下)
pip install requests
pip install beautifulsoup4
pip install pandas
3.1、常用的库说明
3.1.1、Requests
什么是Requests?Requests有什么优点、缺点?
中文网地址:https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
3.1.2、Beautiful Soup 4.4.0
说明: 是一个可以从HTML或XML文件中提取数据的Python库。
中文网地址:https://beautifulsoup.readthedocs.io/zh_CN/latest/
3.1.3、Pandas
说明:强大的 Python 数据分析支持库
中文网址:https://www.pypandas.cn/docs/
具体使用详情认准官网happy啊,此处不多做介绍!!!
3.2、代码示例
直接贴代码:获取的文章标题、文章链接进行整合,导出到 .csv文件。
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import pandas as pd
import openpyxl
import re
import os
def is_in(full_str, sub_str):
return full_str.count(sub_str) > 0
def blogOutput(df,url):
# if file does not exist write header
if not os.path.isfile(url):
df.to_csv(url, index = False)
else: # else it exists so append without writing the header
df.to_csv(url, mode = 'a', index = False, header = False)
if __name__ == '__main__':
target = 'https://blog.csdn.net/weixin_43770545'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
res = requests.get(target,headers=headers)
#div_bf = BeautifulSoup(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
#定义输出数组
result=[]
for item in soup.find_all("article",{"class":"blog-list-box"}):
#提取文章标题
#print(item.find("h4").text.strip())
#提取文章地址链接
#print(item.find("a").get('href'))
data = []
data.append(item.find("h4").text.strip())
data.append(item.find("a").get('href'))
result.append(data)
df = pd.DataFrame(result,columns=['文章标题', '文章地址'])
# 调用函数将数据写入表格
blogOutput(df, 'F:/blog_result.csv')
print('输出完毕')
编码完成后,就跑起来哇。如下图所示,Run(快捷键F5)。

提示输出完毕,可查看导出的文件。

可以的,拿到数据了!!!Python方法就演示这么多(毕竟俺不擅长),下面看Java老哥。

四、Java实现方式
Java操作使用Jsoup库,实质操作Dom。
易百教程网址(友情链接):https://www.yiibai.com/jsoup/jsoup-quick-start.html
4.1、环境、库包
Jsoup Maven:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
4.2、代码示例
定义BlogVo类
public class BlogVo implements Serializable {
/**
* 文章标题
*/
private String title;
/**
* 文章地址
*/
private String url;
@Excel(colName = "文章标题", sort = 1)
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
@Excel(colName = "文章标题", sort = 2)
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
service接口
/**
* 获取提取的博客信息
*
* @return
*/
List<BlogVo> getBlogList();
/**
* 导出csv文件
*
* @param httpServletResponse
* @throws Exception
*/
void export(HttpServletResponse httpServletResponse) throws Exception;
serviceImpl实现类
@Override
public List<BlogVo> getBlogList() {
List<BlogVo> list = new ArrayList<>();
try {
Document document = Jsoup.connect("https://blog.csdn.net/weixin_43770545").timeout(20000).get();
Elements e = document.getElementsByClass("blog-list-box");
Elements h4 = e.select(".blog-list-box-top").select("h4");
Elements a = e.select(".blog-list-box").select("a");
List<String> h4List = new ArrayList<>();
List<String> aList = new ArrayList<>();
h4.forEach(item -> {
h4List.add(item.text());
});
a.forEach(item -> {
String href = item.attr("href");
aList.add(href);
});
for (int i = 0; i < h4List.size(); i++) {
BlogVo blogVo = new BlogVo();
blogVo.setTitle(h4List.get(i));
blogVo.setUrl(aList.get(i));
list.add(blogVo);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
@Override
public void export(HttpServletResponse httpServletResponse) throws Exception {
new ExcelExportUtils().export(BlogVo.class, getBlogList(), httpServletResponse, "blog");
}
controller控制层
/**
* 导出csv文件
*
* @param response
* @throws Exception
*/
@GetMapping("/getExport")
public void getExport(HttpServletResponse response) throws Exception {
demoService.export(response);
}
自定义注解类(Excel )
package com.wshanshi.test.entity;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Excel {
public String colName(); //列名
public int sort(); //顺序
}
工具类(导出)
package com.wshanshi.test.util;
import com.wshanshi.test.entity.Excel;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.formula.functions.T;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedOutputStream;
import java.lang.reflect.Method;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
/**
* 导出工具类
*/
public class ExcelExportUtils {
public void ResponseInit(HttpServletResponse response, String fileName) {
response.reset();
//设置content-disposition响应头控制浏览器以下载的形式打开文件
response.setHeader("Content-Disposition", "attachment;filename=" + fileName + ".csv");
//让服务器告诉浏览器它发送的数据属于excel文件类型
response.setContentType("application/vnd.ms-excel;charset=UTF-8");
response.setHeader("Prama", "no-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
}
public void POIOutPutStream(HttpServletResponse response, HSSFWorkbook wb) {
try {
BufferedOutputStream out = new BufferedOutputStream(response.getOutputStream());
wb.write(out);
out.flush();
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
public void export(Class<?> objClass, List<?> dataList, HttpServletResponse response, String fileName) throws Exception {
ResponseInit(response, fileName);
Class excelClass = Class.forName(objClass.toString().substring(6));
Method[] methods = excelClass.getMethods();
Map<Integer, String> mapCol = new TreeMap<>();
Map<Integer, String> mapMethod = new TreeMap<>();
for (Method method : methods) {
Excel excel = method.getAnnotation(Excel.class);
if (excel != null) {
mapCol.put(excel.sort(), excel.colName());
mapMethod.put(excel.sort(), method.getName());
}
}
HSSFWorkbook wb = new HSSFWorkbook();
POIBuildBody(POIBuildHead(wb, "sheet1", mapCol), excelClass, mapMethod, (List<T>) dataList);
POIOutPutStream(response, wb);
}
public HSSFSheet POIBuildHead(HSSFWorkbook wb, String sheetName, Map<Integer, String> mapCol) {
HSSFSheet sheet01 = wb.createSheet(sheetName);
HSSFRow row = sheet01.createRow(0);
HSSFCell cell;
int i = 0;
for (Map.Entry<Integer, String> entry : mapCol.entrySet()) {
cell = row.createCell(i++);
cell.setCellValue(entry.getValue());
}
return sheet01;
}
public void POIBuildBody(HSSFSheet sheet01, Class<T> excelClass, Map<Integer, String> mapMethod, List<T> dataList) throws Exception {
HSSFRow r = null;
HSSFCell c = null;
if (dataList != null && dataList.size() > 0) {
for (int i = 0; i < dataList.size(); i++) {
r = sheet01.createRow(i + 1);
int j = 0;
for (Map.Entry<Integer, String> entry : mapMethod.entrySet()) {
c = r.createCell(j++);
Object obj = excelClass.getDeclaredMethod(entry.getValue()).invoke(dataList.get(i));
c.setCellValue(obj == null ? "" : obj + "");
}
}
}
}
}
PostMan测试导出,效果如下。
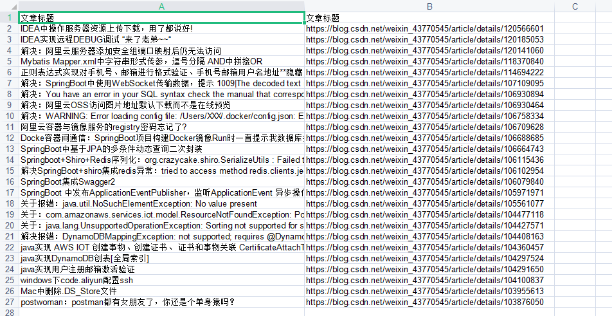
哎呦,可以。

数据虽然导出了,但是发现一个问题。数据少了?之前用python取到的数据明明是九十多条。为啥这次只请求到了20多条?有点怪哦。

仔细看了下界面,原来是因为页面换为了慢加载。当你滑到最下方的时候请求分页的。

嗷嗷,原来是这样啊。不过,既然看到了接口,那就…用postMan调下白。
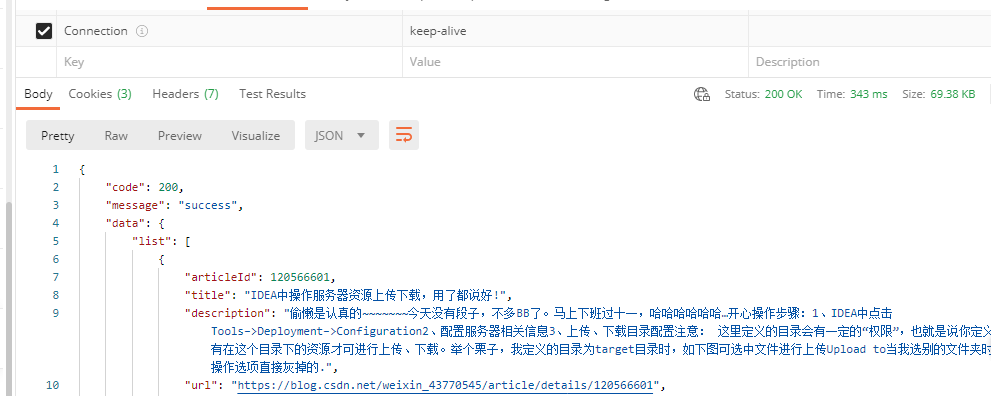
我giao,这径直拿到数据了啊…

So,还有一种方法。就是直接Http请求这个接口,把分页的条数设置大点就好了。
示例代码如下:
public List<BlogVo> blogHttp() {
List<BlogVo> list = new ArrayList<>();
String s = HttpClientUtils.doGetRequest("https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=300&businessType=blog&orderby=&noMore=false&username=weixin_43770545", null, null, null);
RespDTO blogDTO = JSON.parseObject(s, RespDTO.class);
DataEntity data = blogDTO.getData();
data.getList().forEach(item -> {
BlogVo blogVo = new BlogVo();
blogVo.setUrl(item.getUrl());
blogVo.setTitle(item.getTitle());
list.add(blogVo);
});
return list;
}
效果如下,自己尝试哈。你懂得…

害,就先这样吧!别学坏哈…

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/115762.html

