
终于忙完课了,接着写博客哈哈~
本篇的主要内容:
- 一个测试持久化用的MNIST识别网络模型
- 对TensorFlow持久化代码做了解释
最近在想TensorFlow模型的持久化问题,毕竟每一次训练模型都是有够煎熬的~所以特意学习一下关于模型持久化的内容。
这里使用的例子是MNIST数据集的识别,在此之前,我写了一个简单的神经网络来训练识别,共有一个隐藏层,隐藏层有100个结点,完整的代码如下:
# 一层 100个节点的hidden layer的网络
# 测试和持久化网络结构
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
trainimg = mnist.train.images
trainlabel = mnist.train.labels
testimg = mnist.test.images
testlabel = mnist.test.labels
print('MNIST ready')
n_input = 784
n_output = 10
n_layer = 100
train_epoches = 20
batch_size = 500
with tf.name_scope("Input"):
x = tf.placeholder(tf.float32, [None, n_input], name='inputx')
y = tf.placeholder(tf.float32, [None, n_output], name='inputy')
with tf.name_scope("Parameters"):
weights = tf.Variable(tf.random_normal([n_input, n_layer], stddev=0.1))
biases = tf.Variable(tf.random_normal([n_layer], stddev=0.1))
with tf.name_scope("FC"):
pred_y = tf.add(tf.matmul(x, weights), biases)
with tf.name_scope("Cost"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=pred_y, labels=tf.argmax(y, 1))
cost = tf.reduce_mean(cross_entropy)
optimizer = tf.train.GradientDescentOptimizer(0.05).minimize(cost)
with tf.name_scope("Accuracy"):
temp = tf.equal(tf.argmax(pred_y, 1), tf.argmax(y, 1))
accur = tf.reduce_mean(tf.cast(temp, tf.float32), name="accur")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(train_epoches):
avg_cost = 0
xs , ys = None, None
for i in range(total_batch):
xs, ys = mnist.train.next_batch(batch_size)
_, _cost = sess.run([optimizer, cost], feed_dict={x:xs, y:ys})
avg_cost += _cost
if epoch % 20 == 0:
print("Epoch : ", epoch, " Accuracy : {:.4f}".format(sess.run(accur, feed_dict={x:xs, y:ys})), " Cost : " , avg_cost)
print("Train ready.")
print("Test Accuracy : {:.4f}".format(sess.run(accur, feed_dict={x:testimg, y:testlabel})))
这份代码很粗糙,毕竟构建网络不是本次的重点,最后的在test数据集上识别率大概在97%左右,主要是为了训练地快一点,所以结构很简单,而且划分了很多命名空间,这也是最近学习的内容之一,划分这么多命名空间主要是为了在TensorBoard中可视化的时候清楚一些,在这里意义不是很大。
有一个注意点:可以看到,对于输入数据和标签数据,我都在定义的时候添加了name,对于计算正确率的op也添加了name,这样做是为了之后加载模型的时候方便,因为对于使用保存的模型,我们会用到这几个结点,具体原因稍后解释,这里要注意一下。
那么接下来就是重点了,如何保存训练好的模型呢?通过查资料,TensorFlow中是使用tf.train.Saver()创建的类来保存模型,这个类使用非常简单,只是有一点要注意:在TensorFlow中,变量的是存在于Session中的,所以在这里保存变量的时候,要传入session,这个函数的基本调用是session+文件名,例如,对于上面的模型,我保存的代码是:
saver = tf.train.Saver()
saver.save(sess, "E:/testsav/model")
将训练的结果保存在E:/testsav文件夹下,保存的文件名是:model,这两行代码很直观,所以就不用解释了,这两句代码加在上面代码的session中的最后,当然,最好在保存之后也写一句print,这样就会知道已经保存好了。
保存完成之后,打开保存的文件夹,可以看到四个文件:
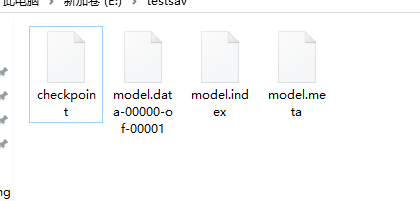
一开始找资料的时候,一些书还有一些博客上,写的是这里会保存成三个文件,后来查了一下,这些资料算是比较老了,在之前版本的TensorFlow中是保存成三个文件了,现在比较新的版本则是保存成四个文件,其实差别也不大,这四个文件的保存内容分别是:
- model.meta:保存模型的图,也就是模型的结构
- model.index,model.data:保存模型的参数,除了保存结构,当然已经训练好的参数也要保存
- checkpoint:这个文件会保存这个文件夹下的模型文件列表,也就是有时候我们会在训练的过程中按时间或者迭代的次数保存保存多个模型,这个文件会进行记录。
到这里,我们的模型算是保存好了(其实也就只有两行代码而已。。。),接下来,我们要在另一个文件里,加载这个已经训练好的模型,然后用MNIST的测试数据集进行测试。
代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 这一部分是准备数据 不重要
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
trainimg = mnist.train.images
trainlabel = mnist.train.labels
testimg = mnist.test.images
testlabel = mnist.test.labels
print('MNIST ready')
sess = tf.Session()
saver = tf.train.import_meta_graph("E:/testsav/model.meta")
saver.restore(sess, tf.train.latest_checkpoint("E:/testsav"))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("Input/inputx:0")
y = graph.get_tensor_by_name("Input/inputy:0")
feed = {x:testimg, y:testlabel}
op_to_restore = graph.get_tensor_by_name("Accuracy/accur:0")
print(sess.run(op_to_restore,feed))
先看一下完整的代码,然后具体来看:
首先,对于已经保存的模型,我们可以想,首先应该拿到模型的结构,没错,首先要加载图:
saver = tf.train.import_meta_graph("E:/testsav/model.meta")
上面说了,meta文件保存的是模型的结构,这是导入模型结构的代码。然后,我们要为这个模型填充训练好的参数,这里要注意一点,变量是依赖于session的,所以要在一个session中使用:
saver.restore(sess, tf.train.latest_checkpoint("E:/testsav"))
这样,在这段代码中,有了图以及训练好的参数,我们的最后目的是为这个模型传入新的数据进行预测(这里是测试,也是相当于新数据吧),首先要获取这个模型中的几个placeholder:
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("Input/inputx:0")
y = graph.get_tensor_by_name("Input/inputy:0")
feed = {x:testimg, y:testlabel}
op_to_restore = graph.get_tensor_by_name("Accuracy/accur:0")
其实就是graph.get_tensor_name()函数的使用,首先使用get_default_graph()函数获得默认的图,这里没有创建新的计算图,所以所有的计算都是在默认图中的,然后,按照变量的名字进行控制,这里要注意通过名字进行获取变量,注意一定要将命名空间写上,这里我将不同的结点放在了不同的命名空间里,这样可视化的结构会更清楚一些。
接下来就是很熟悉的在session中运行,并使用字典的方式填充数据了。
通过运行代码,至少运行很快,嗯,说明确实有效,对吧。
这只是关于TensorFlow持久化模型的一个简单例子,而且这里介绍的只是一些基础操作,更具体的以及更高级的方法以及操作,可以看这些材料:
这篇文档写的很精彩,本文中只是对使用的方式进行了一点解释,这篇文档中还介绍了另外的一些操作,值得一看:
A quick complete tutorial to save and restore Tensorflow models
大佬整理的很条条理:
Tensorflow加载预训练模型和保存模型
此外,也参考了《TensorFlow实战:Google深度学习框架》这本书。
以上~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/116720.html

