
卷积神经网络记录
最近一段时间在学习卷积神经网络的知识,看了很多博客和资料之后,决定自己写一篇记录一下学习地知识,巩固一下所学。
1.卷积神经网络与全连接神经网络的异同
首先来看卷积神经网络之前的网络的异同,两种神经网络结构对比图如下:
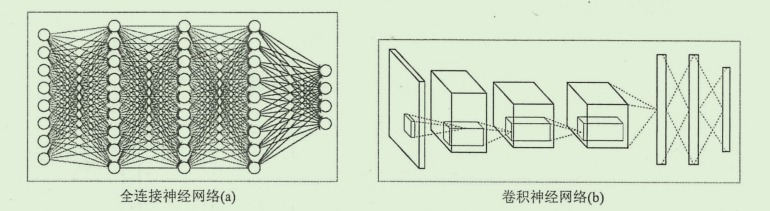
在结构上,两种网络看起来不同,实际上还是很相似的。两者都是通过一层一层的节点组织起来的,在训练过程上也是基本一致。两种神经网络的的区别就在于相邻两层的不同节点之间的连接方式,对于全连接网络(FC),位于相邻两层上的任意两个节点都是连接的,而卷积神经网络(CNN)的相邻两层之间,只有部分节点相连。
那么,为什么会有CNN网络呢? 显然,对于FC,输入数据的所有信息都会得到有效的利用,因为通过全连接的方式,每一点信息都会对训练过程做出“ 贡献 ”, 这是它的优点,但是,当处理图像数据的时候,这就反而成了累赘, 之前使用 FC 处理MNIST数据集,第一层上有 784 个节点,因为我们的图像是 28 * 28 , 仅仅是这样的小图片,需要进行更新的参数已经很多了,显然,对于更大的图片,这样的过程是吃不消的。因此,CNN 应运而生,之后会介绍到 CNN 通过权值共享等等方法,有效地解决了这个问题。
2.卷积神经网络的重要概念
卷积是什么
不管是什么算法,当牵扯到数学层面的时候,都不太好理解 ( ̄m ̄),但是理解之后都会更清楚整个过程。
如果去查卷积的概念,可能会出现这样的定义:
卷积(convolution) 是通过两个函数
f
f
f,
g
g
g 生成第三个函数的一种数学算子,表征函数
f
f
f 与
g
g
g 经过翻转和平移的重叠部分的面积。数学定义如下:
h
(
x
)
=
f
(
x
)
⋅
g
(
x
)
=
∫
f
(
t
)
⋅
g
(
x
−
t
)
d
(
t
)
h(x) =f(x)\cdot g(x)=\int f(t)\cdot g(x-t)d_{(t)}
h(x)=f(x)⋅g(x)=∫f(t)⋅g(x−t)d(t)
不好理解,事实上,在卷积网络上使用的离散卷积,也就是不连续的,它是一种运算方式,也就是按照卷积核,将输入对应位置的数据进行加权和运算,接下来结合卷积核的概念,就会很好理解了。如果想要进一步理解卷积,可以在知乎上查找这一问题:
如何理解CNN中的卷积
其实不知有这一篇文章,另外还有很多问题下的回答都做了解释,这里就不一一列举了。
卷积核的概念
接上面,卷积核是整个网络的核心,训练CNN的过程就是不断更新卷积核参数直到最优的过程。
卷积核的定义:对于输入图像中的一部分区域,进行加权求和的处理,其中这个过程的权重,由一个函数定义,这个函数就是卷积核。(这个地方,在有些资料可能会将卷积核解释为权重矩阵,当然概念其实不是很重要,直接将卷积核理解为一种运算方式就可以了)
下面看图解,这样会更直观的理解这个计算过程:

左边的 Image 是输入的数据,右边是通过卷积核操作之后的结果,定义中,进行处理的小区域就是颜色比较浅的 3*3 的区域, 可以看到这些数据被处理成了右侧输出中的一个小格子。
在这个卷积核中,我们定义:
w
=
[
1
1
1
1
1
1
1
1
1
]
w = \begin{bmatrix} 1 & 1 &1 \\ 1 & 1 & 1\\ 1 & 1 & 1 \end{bmatrix}
w=⎣⎡111111111⎦⎤
b
=
0
b = 0
b=0
我们用这个
w
w
w 的元素分别乘以待处理的区域的每一个元素值,也就是进行内积操作,然后加上bias,取均值:
f
(
x
)
=
1
×
1
+
1
×
1
+
1
×
1
+
1
×
0
+
1
×
1
+
1
×
1
+
1
×
0
+
1
×
0
+
1
×
1
=
6
f(x) = 1\times1+1\times1+1\times1+1\times0+1\times1+1\times1+1\times0+1\times0+1\times1 = 6
f(x)=1×1+1×1+1×1+1×0+1×1+1×1+1×0+1×0+1×1=6
上面的式子忽略了 加上 bias 的过程,因为定义bias等于0嘛,实际中不要忘记加上。然后我们把这个 6 保存在输出的第一个节点上,这样,原来九个节点的信息可以说是被 **“ 压缩”**到了一个点的信息中,那么输出结果的其他 8个 格子呢?其实是同样的方式计算,只是选择的区域不同而已:
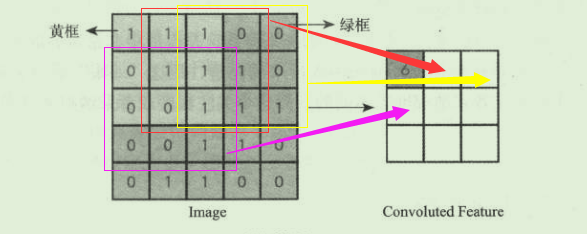
这就相当于,给定了3 * 3 的区域,计算完一个之后,向另一个方向进行 “滑动”,这里滑动的步长是1,这个步长称为 “Stride”,也是很重要的一个参数,对输入数据操作完成之后,我们就得到了右边的输出结果,这个结果也是一张图对吧,我们称之为这个卷积层的 特征图(Feature Map)。
如果感觉还是不清楚,这里还有两张GIF图,更直观:

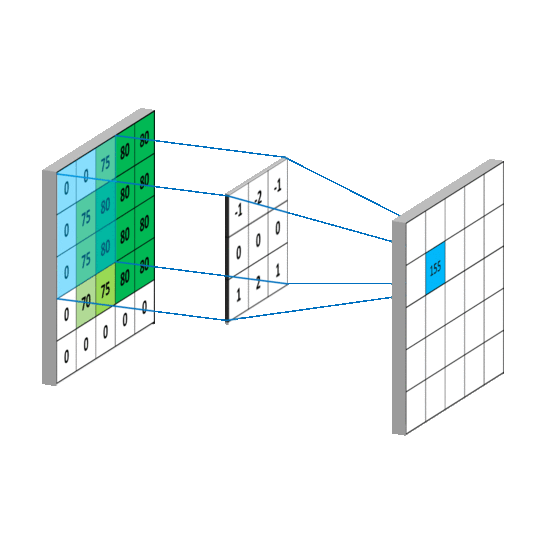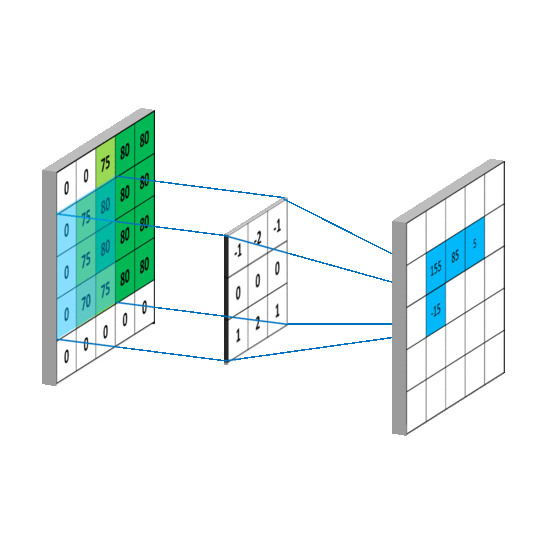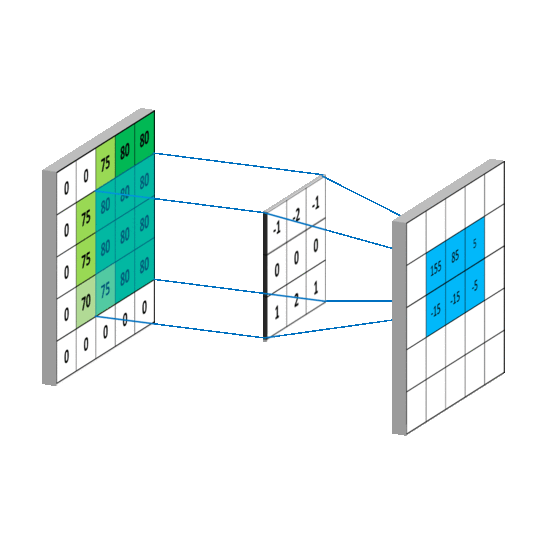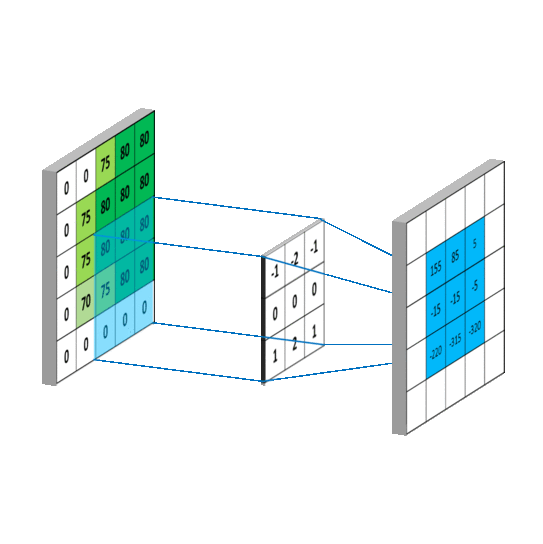
对于整个计算的过程来说,我们可以看到,原来 5*5 的输入图像处理之后变成了 3*3 的特征图,所以可以说,卷积进行的是特征提取的过程。
这就是卷积核的运作方式,如果用函数式来表示这个过程:
f
(
x
)
=
w
x
+
b
f(x) = wx+b
f(x)=wx+b
很眼熟对吧,就像之前的神经元进行的线性变换一样。这个使用卷积核处理的在实际的卷积网络中,一般对于这个函数的输出,还要使用激励函数进行去线性化,在CNN中,最常用的激活函数是 ReLU函数。
3.卷积神经网络的结构
了解了CNN中最重要的卷积核的概念,接着来看CNN的结构:
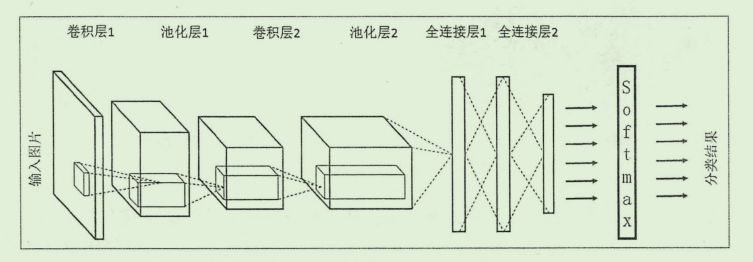
这里最后有一个softmax处理的过程,这是一个分类模型的结构,CNN结构有很多划分,虽然看着不同,但实际上都是大同小异,这张图片比较清楚地展示了CNN 地结构,CNN 网络一般来说,包括这五个部分:
- 输入层 INPUT
- 卷积层 CONV
- 激活函数层 RELU
- 池化层 POOL
- 全连接层 FC
不过注意不要简单地理解所有的卷积网络都是只有五层,对于大部分卷积网络,都会交替地用到中间地四层结构,也就是呈现出一种 卷积层-激活函数层-池化层-卷积层=激活函数层-池化层…地交替结构,当然,对于一些新出现地卷积网络,连池化层都省去了,以上五层结构只是一般会出现的层次。
输入层
整个网络的输入,一般是一张图象地像素矩阵,在上面的图中,可以看到输入是一个立体的结构,这是因为一般的图像都会有一个深度的概念,就像我们一般见到的RGB的彩色图像,就是 a*b*c的形式,其中前两维指定的是图像的长和宽,第三维则是深度,彩色RGB的深度是3,而之前我们见到的MNIST中的黑白图像的深度是 1.
卷积层
这一层的主要部分就是进行卷积操作,前面已经介绍了卷积核的概念,卷积层实际上就是实现了这个卷积核的计算过程,在这一层中,可能会见到以下的几种关键词:
-
滤波器 Filter,我的理解就是实现前面定义的卷积核的神经元。
-
步长 Stride:前面提到了对于一个区域,在进行计算完成之后要进行滑动,滑动的时候的的移动距离也就是这个Stride了
-
填充 Padding: 考虑上面卷积地计算过程,对于图像靠近中间部分的像素,我们可以看出,会被 “重叠” 地计算很多次,相比之下,边缘地像素呢?只被计算了一次,这有点太不公平了啊。怎么让它也能享受到 多次计算呢?就是在边缘填充一些值这样就好了嘛:
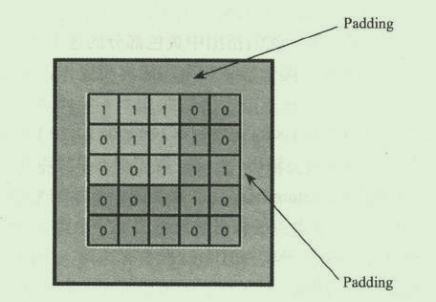
注意这里的填充值都是0,显然Padding的值不是我们需要的,所以不让他们的值影响网络,所以要使用0. 除了保持边界信息,其实还有一个用处:补齐输入数据的差异,也很好理解对吧,如果size不一样,那么在小地图片周围进行填充就可以了。
- 深度 Depth:这里的深度不是指图像,而是指某一层中神经元(滤波器)的个数,这个怎么理解呢?不妨继续看看卷积层处理之后的结果,我们看结构图中,此时输出的不是一张特征图,而是几张特征图组成的一个立体,一个Filter可以将输入图像处理成一张Feature Map,这里说明一下,不同的 Filter 重点处理的特征是不同的,就好像 “各司其职”, 比方说输入一张猫的图像,有的 Filter 对耳朵敏感,有的则是对眼睛敏感,我们想要得到不同的这些特征图,所以设置了多个 Filter ,这样每个 Filter 处理得到一张 Feature Map ,那么多个 Filter 就会得到多个Feature Map, 将这些Feature Map 叠在一起就是输出的立体了,所以可以看到,Filter 与 Feature Map的数量是一样的,这个数量,就是 深度。
除了这些参数之外,我们还要考虑一个问题,其实答案也非常明显,为什么要进行卷积层的处理? 将若干个数据点处理为一个数据,也就是 “特征提取” 的过程了。关于这个特征提取的过程理解,可以关注这个问题,下面的解答很清楚:
激励函数层
也可以把这个单独写成一层吧,实际中,使用激活函数处理往往是与之前的卷积层绑定在一起的,这个作用其实也就是是激活函数的作用了,进行去线性化嘛,在卷积网络中,一般使用的激励函数是 ReLu 函数,注意大多数情况下都不会使用 Sigmoid函数处理。
池化层
池化层(Pooling Layer)虽然名字怪怪的,实际上相比之前的卷积层更好计算,它作用在 Feature Map 上,相当于对输入矩阵的尺寸进一步浓缩,也就是进一步提取特征:
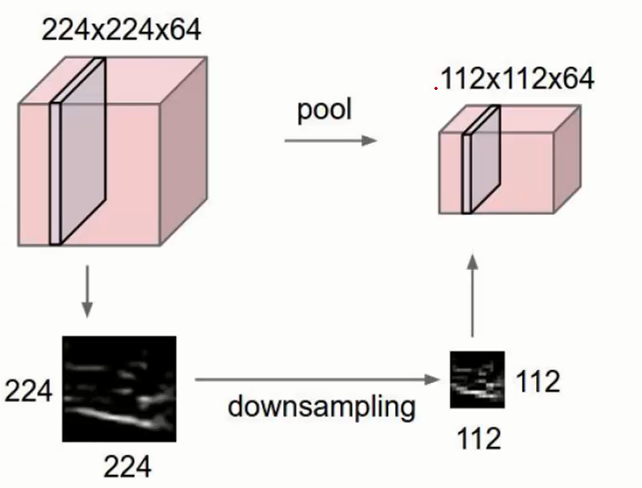
计算类似卷积,通过一个类似Filter的结构进行不断地移动(Stride就等于Filter地长度)只是过程简单多了。对于这个区域地计算,不再是使用加权和地形式,而是采用简单的最大值、平均值的方式,使用最大值的称为最大池化层(max pooling), 使用平均值的称为平均池化层(mean pooling),这是一个最大池化计算的例子:
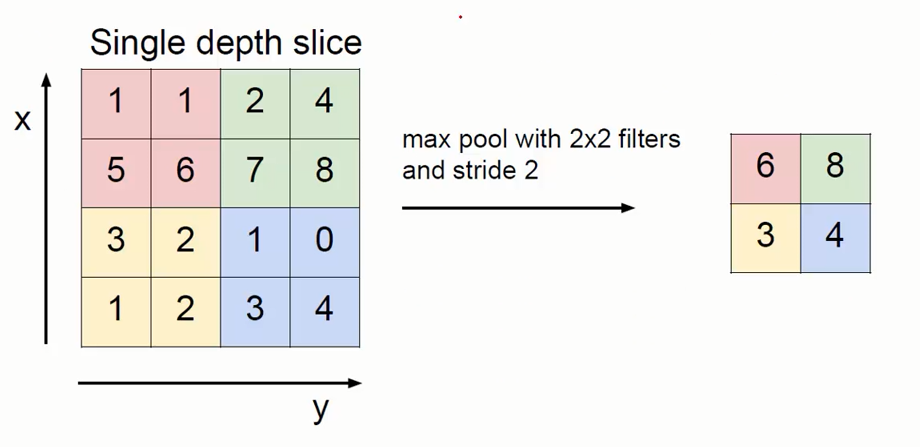
就像在图中 取定 2*2 的区域 ,那么第一个区域的结果就是:
m
a
x
(
1
,
1
,
5
,
6
)
=
6
max(1, 1,5, 6) = 6
max(1,1,5,6)=6
其余的以此类推。
与卷积层一样,我们为什么使用池化层呢?,一般来说,池化层有以下几个功能:
- 对 Feature Map 又进行一次特征提取,这也是减小数据量的操作
- 获取更抽象的特征,防止过拟合,提高泛化性
- 经过这个处理,对输入的微小变化有更大的容忍,也就是说如果数据有一些噪音,那么经过这个特征提取的过程,就一定程度上减小了噪音的影响。
最后一点要注意的是,池化层并非是卷积网络所必需的。一些新的CNN网络设计时候并没有使用池化层。
全连接层
在一开始的结构图中可以看出, CNN网络还有一个特点 : 可能有多轮 卷积层 和池化层的处理,这时候,模型已经将图像输入处理成了信息含量更高的特征,为了实现分类的任务(一般是分类,当然也会有其他的任务),需要使用全连接层来完成分类任务。
4.几个问题
划分了整个结构,卷积网络的计算流程也就梳理了一遍,接下来记录一些我在学习中遇到的一些问题吧,前面只是形式化的一些内容,这里才是干货:
如何计算输出的 Feature Map 的 shape?
设:
- 输入数据的长宽分别是 、h_in、w_in
- Filter 的宽度是 f
- Padding 是
p
p
p
- 输出数据的长宽分别是
h
o
u
t
、
w
o
u
t
h_out、 w_out
hout、wout
- 步长 stride 是
s
s
s
那么输出的特征图的长度可以表示为(宽度的计算方式也是一样的):
h
o
u
t
=
h
i
n
−
f
+
2
p
s
+
1
h_out = \frac{h_in-f+2p}{s}+1
hout=shin−f+2p+1
在证明上,直接根据变化前后边长的等量关系建立方程求解即可。
相较于全连接网络,为什么卷积网络可以更好地处理图像数据?
全连接网络的特点就是所有的输入信息都会对之后的训练都影响,但是对于图像数据,这样是没有意义的,比如对于一张图片,数据呈现的区域特点,比如一张猫的图像,耳朵附近的数据点彼此会有关联,但是尾巴处的信息对耳朵就几乎没有影响了,基于这个,卷积网络有两个很重要的概念:
- 局部感受野
- 权值共享
在上面提到过这两个概念,对于局部感受野,或者说是感受野,是借鉴的生物学上的概念,在这里其实就是指卷积核作用的那个区域,图解:
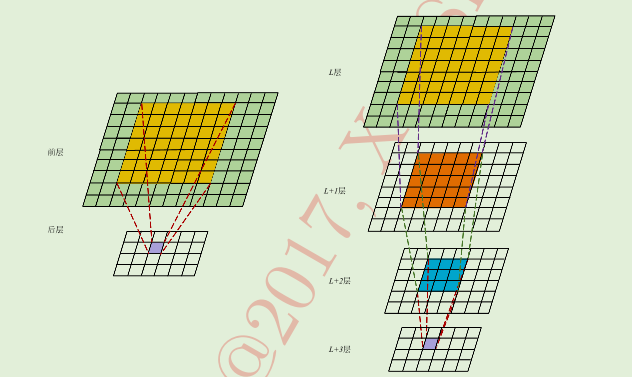
对于后层的结果,就比如桃红色的那个格子,它的感受野就是黄色的那一片,也就是压缩前的那一块区域。局部感受野的特点其实就是我所说的一张图片距离很远的点关联很小,所以我们就相当于从 全连接方式 省下了一部分参数,只进行局部运算,所以参数就少了嘛。
对于“权值共享”, 实际上就是对于一张图像,计算的方式一样,也就是特征提取的方式一样,这个过程就是 我们拿着卷积核的那个框框 ,不断在原输入图像上滑动的过程 ,所有框框内部的数据计算方式一样,这就是 “参数共享”,这样就大大减少了参数值,毕竟权重都是一样的嘛。
当然在使用中,有时候参数还是太多,收敛还是太慢,这时候还有其他的方式,比如dropout等等,随机 “杀死”一些神经元,计算就更快了。
这么看来,卷积计算“提取特征”就像是一个筛子,从原图像上一点一点地移动,把符合条件地区域“筛出来”。
参考资料
在学习的过程中,收藏了一些资料,毕竟我的这次记录,也都是来源于此,在这列出来:
卷积神经网络CNN的总结 :比较全面地总结了整个CNN地基础知识
卷积神经网络地理解:介绍了一些CNN中的问题
如何通俗解释卷积:知乎大佬们对卷积的理解
如何通俗易懂地解释卷积也是对卷积地解释,这里重点说了离散卷积地概念,可以看一看
参考的视频资料是经典的斯坦福机器学习公开课视频和唐宇迪的机器学习视频。
参考的书籍资料:
我在学习TensorFlow,所以很多参考地资料都是来源于TensorFlow中的卷积网络介绍,
《TensorFlow实战:Google深度学习框架》
《白话深度学习与TensorFlow》
这里还要重点推荐一本书:
《解析卷积神经网络——深度学习实践手册》
这本书可能没有实体书,作者是魏秀参,这本书从浅入深,很全面的介绍了CNN,后面还有很多实用中使用的技巧,这本书脱离了某种框架,着重是在原理上介绍,写的很好,我还在学习中,推荐给大家。网上应该会有很多资源。
以上~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/116723.html

