
0、序
face_recognition 宣称是史上最强大,最简单的人脸识别项目。据悉,该项目由软件工程开发师和咨询师 Adam Geitgey 开发,其强大之处在于不仅基于业内领先的 C++ 开源库 dlib 中的深度学习模型,采用的人脸数据集也是由美国麻省大学安姆斯特分校制作的 Labeled Faces in the Wild,它含有从网络收集的 13,000 多张面部图像,准确率高达 99.38%。此外,项目还配备了完整的开发文档和应用案例,特别是兼容树莓派系统。简单之处在于操作者可以直接使用 Python和命令行工具提取、识别、操作人脸。
github该项目的传送门:https://github.com/ageitgey/face_recognition
以下demo相关的图像处理的资源均通过opencv获取摄像头的实时图像数据,则默认已经安装好了opencv及opencv运行所需的相关一些依赖库及组件。
1、环境准备
1.1、安装face_recognition库:
pip3 install face_recognition
1.2、安装dlib库:
wget http://dlib.net/files/dlib-19.17.tar.bz2
tar jxvf dlib-19.17.tar.bz2
cd dlib-19.17
修改在dlib/cuda/目录下的该 cudnn_dlibapi.cpp文件中
gedit dlib/cuda/cudnn_dlibapi.cpp
找到对应的一行代码,进行删除(可以采用注释的方式删除)
forward_algo = forward_best_algo;
//forward_algo = forward_best_algo;
编译安装
sudo python3 setup.py install
1.3、安装数据保存利器pickle
pip3 install pickle
2、Coding

2.1、人脸注册并保存分类数据
import face_recognition
import cv2
import os
import pickle
print(cv2.__version__)
Encodings=[]
Names=[]
image_dir='/home/colin/works/face_recognition_dlib/face_register'
for root, dirs, files in os.walk(image_dir):
print(files)
for file in files:
path=os.path.join(root,file)
print(path)
name=os.path.splitext(file)[0]
print(name)
person=face_recognition.load_image_file(path)
encoding=face_recognition.face_encodings(person)[0]
Encodings.append(encoding)
Names.append(name)
print(Names)
with open('train.pkl', 'wb') as f:
pickle.dump(Names, f)
pickle.dump(Encodings, f)
2.2、实时人脸识别
import os
import face_recognition
import cv2
import time
import numpy as np
import pickle
import image_shop
save_switch = 0
catch_max = 50
Encodings=[]
Names=[]
font = cv2.FONT_HERSHEY_SIMPLEX
#640 480 320 240
def gstreamer_pipeline(
capture_width=640,
capture_height=480,
display_width=640,
display_height=480,
framerate=30,
flip_method=0,
):
return (
"nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), "
"width=(int)%d, height=(int)%d, "
"format=(string)NV12, framerate=(fraction)%d/1 ! "
"nvvidconv flip-method=%d ! "
"video/x-raw, width=(int)%d, height=(int)%d, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! appsink"
% (
capture_width,
capture_height,
framerate,
flip_method,
display_width,
display_height,
)
)
def train_data_load( ):
global Names, Encodings
with open('train.pkl','rb') as f:
Names=pickle.load(f)
Encodings=pickle.load(f)
def catch_face(startX, endX, startY, endY, image):
global save_switch
face_pic = image[startY -50: endY + 50, startX-50 : endX + 50]
face_name = 'Unkown'
if face_pic.size > 0:
face_name = face_recognition_frame(face_pic)
return face_name
def face_recognition_frame(frame):
global Names, Encodings, font
frameSmall =cv2.resize(frame,(0,0),fx=.25, fy=.25)
frameRGB=cv2.cvtColor(frameSmall,cv2.COLOR_BGR2RGB)
facePositions=face_recognition.face_locations(frameRGB,model='cnn')
allEncodings=face_recognition.face_encodings(frameRGB,facePositions)
for (top,right,bottom,left),face_encoding in zip(facePositions,allEncodings):
name='Unkown'
matches=face_recognition.compare_faces(Encodings,face_encoding, tolerance=0.5)
if True in matches:
#first_match_index=matches.index(True)
#name=Names[first_match_index]
face_distance = face_recognition.face_distance(Encodings, face_encoding)
best_match_index = np.argmin(face_distance)
name = Names[best_match_index]
top = top * 4
right = right * 4
bottom = bottom * 4
left = left * 4
if top - 6 > 10:
mark_loc = (left, top-6)
else:
mark_loc = (left, bottom-6)
if name == 'Unkown':
cv2.rectangle(frame, (left, top), (right, bottom), (0,0,255), 2)
cv2.putText(frame, name, mark_loc, font, .5, (255,0,0), 2)
else:
cv2.rectangle(frame, (left, top), (right, bottom), (0,255,0), 2)
cv2.putText(frame, name, mark_loc, font, .5, (0,0,255), 2)
frame = image_shop.mark_add(left, right, top, bottom, frame)
#return name
resImage = frame
return resImage
def CatchVideo(window_name, camera_idx):
global save_switch, catch_switch, catch_max
cv2.namedWindow(window_name)
#CSI Camera for get pipeline
cap = cv2.VideoCapture(gstreamer_pipeline(flip_method=camera_idx), cv2.CAP_GSTREAMER)
while cap.isOpened():
ok, frame = cap.read() #read 1 frame
if not ok:
break
resImage = face_recognition_frame(frame)
#display
cv2.imshow(window_name, resImage)
c = cv2.waitKey(1)
if c & 0xFF == ord('q'):
break
#close
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
print('main menu:\n\t1 -reload face register\n\t2 -run\n\t3 -exit\n')
choose = input("input your choose:")
train_data_load()
CatchVideo("Find face", 0)
2.3、实时遮羞专用
image_shop.py文件实现的效果就是实例演示中的给人脸区域实时的加上那个图片logo,遮羞使用(手动狗头)。
import os
import cv2
import numpy as np
def resize_auto(height, width):
image_exchange = cv2.imread("/home/colin/works/face_recognition_dlib/mark.png")
height_e, width_e = image_exchange.shape[:2]
h = height/height_e
if h <= 0.00:
h = 1.00
w = width/width_e
if w <= 0.00:
w = 1.00
img_rs = cv2.resize(image_exchange, (int(height_e * h * .90), int(height_e * h * .90)), interpolation = cv2.INTER_CUBIC)
return img_rs
def mark_add(startX, endX, startY, endY, image):
mark = resize_auto(abs(endY-startY), abs(endX-startX))
md_h, md_w = mark.shape[:2]
detal_x = abs(endX-startX) - md_w
detal_y = abs(endY-startY) - md_h
if detal_x > 2:
p_x = startX + detal_x/2
p_y = startY + detal_y/2
else:
p_x = startX
p_y = startY
startX_m = int(p_x)
endX_m = int(p_x + md_w)
startY_m = int(p_y)
endY_m = int(p_y + md_w)
if(startX_m > 0 and endX_m > 0 and startY_m > 0 and endY_m > 0
and abs(endX_m-startX_m) == abs(endY_m-startY_m)):
image[startY_m:endY_m, startX_m:endX_m] = mark
return image
3、Demo效果
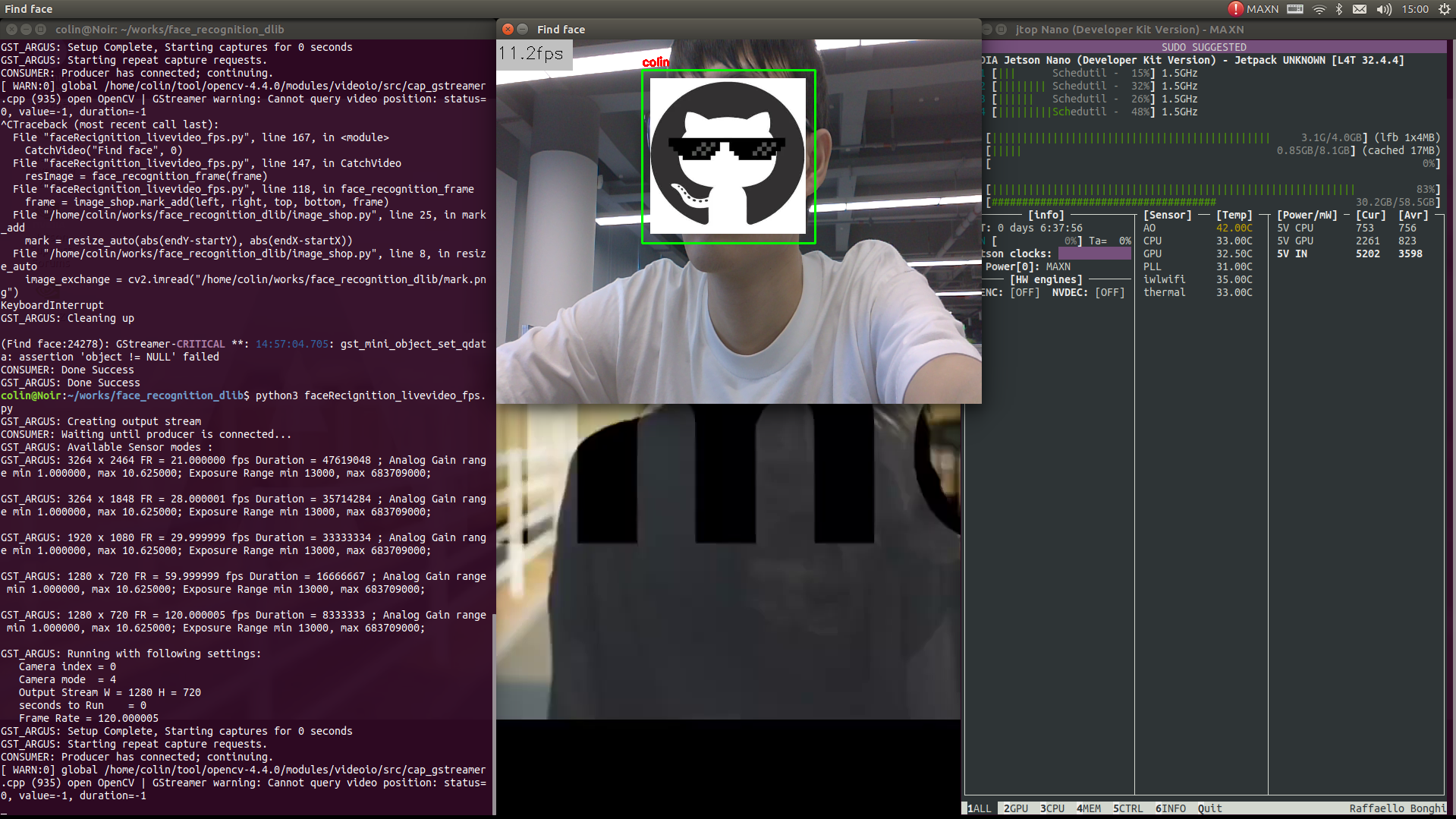
参考附录
1)油管也有个牛逼的老爷子在做jetson nano等相关开源硬件的学习视频
https://toptechboy.com/
2)史上最简单的人脸识别项目登上GitHub趋势榜
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/116969.html

