
ES
本章知识点
三 ES简介
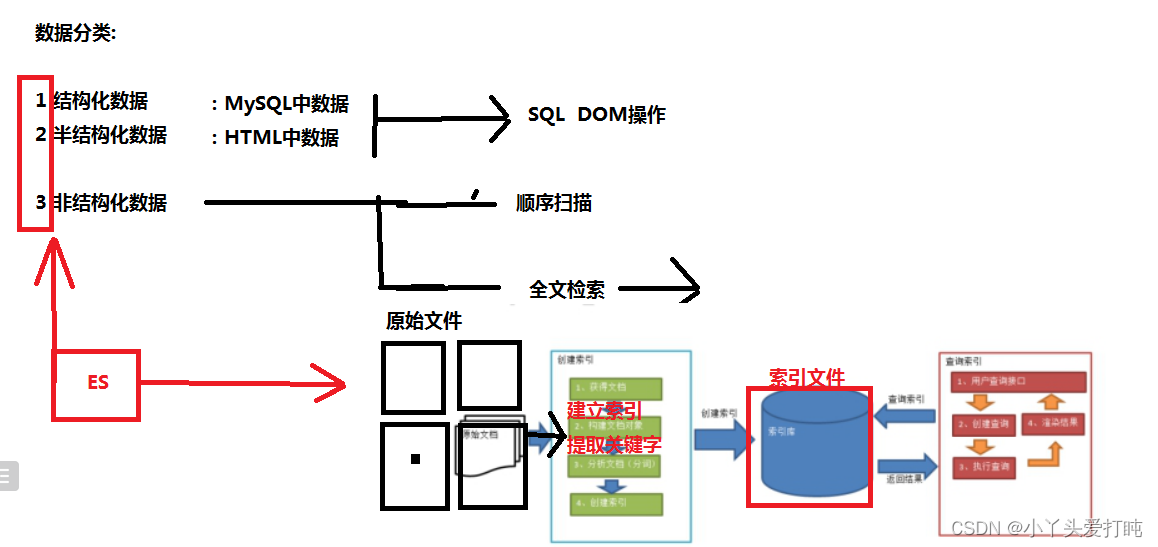
3.1 数据分类
我们生活中的数据总体分为三种:结构化数据,非结构化数据,半结构化数据
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等
半结构化数据,如XML,HTML等。 例如html 可以添加文本 、图片、音视频等内容,但是其是由标签组成。
非结构化数据又一种叫法 ------------------- 全文数据。
3.2 对数据的搜索方式
对结构化数据的搜索:
如对数据库的搜索,用SQL语句。利用表结构 结合SQL.结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和[程序设计语言]
对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。(按照文件的名字 类型 如果搜索的是文件内容)
对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
3.3 非结构化数据的搜索
顺序扫描:比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
如利用windows的搜索也可以搜索文件内容,只是相当的慢。如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。
Linux下的grep命令也是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。
全文检索的基本思路:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
这部分从非结构化数据中提取出的然后重新组织的信息,我们称之 索引。
这种先建立索引,再对索引进行搜索的过程就叫 全文检索(Full-text Search)
3.4 es简介
官网:https://www.elastic.co/cn/
文档教程: https://www.elastic.co/guide/en/elasticsearch/reference/6.0/getting-started.html
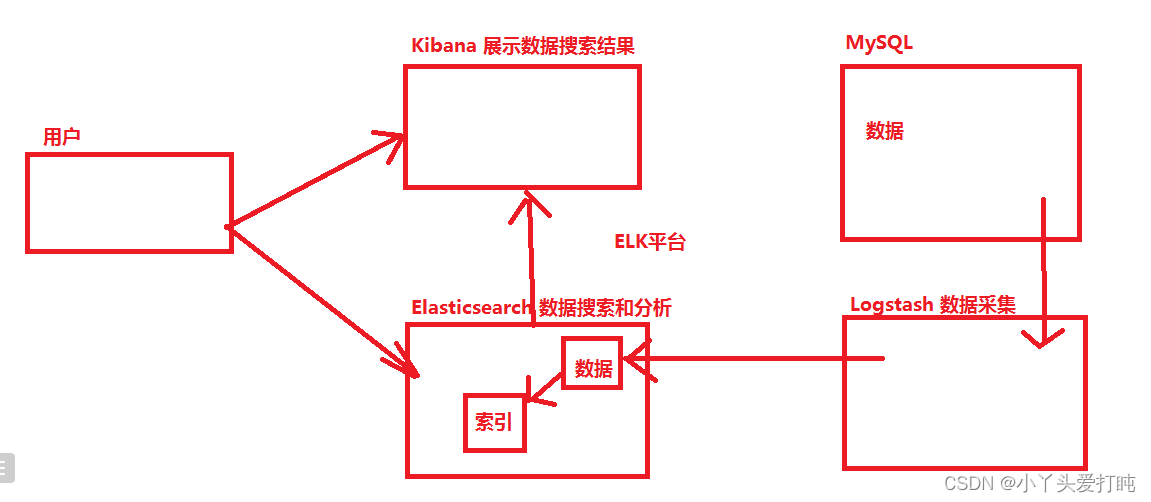
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,Elasticsearch 会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析,并轻松缩放规模。
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
ELK平台
四 ES中的核心概念
4.1 ES作用
Elasticsearch是一个高度可扩展的开源全文本搜索和分析引擎。它使您可以快速,近乎实时地存储,搜索和分析大量数据。它通常用作支持具有复杂搜索功能和要求的应用程序的基础引擎/技术。
以下是一些可用于Elasticsearch的示例用例:
- 您经营一个在线网上商店,您可以在其中允许客户搜索您出售的产品。在这种情况下,您可以使用Elasticsearch存储整个产品目录和库存,并为其提供搜索和自动完成建议。
- 您要收集日志或交易数据,并且要分析和挖掘此数据以查找趋势,统计信息,摘要或异常。在这种情况下,您可以使用Logstash(Elasticsearch / Logstash / Kibana堆栈的一部分)来收集,聚合和解析数据,然后让Logstash将这些数据提供给Elasticsearch。数据放入Elasticsearch后,您可以运行搜索和聚合以挖掘您感兴趣的任何信息。
- 您运行一个价格警报平台,该平台允许精通价格的客户指定诸如“我有兴趣购买特定的电子小工具,并且如果小工具的价格在下个月内从任何供应商处降到$ X以下,我希望收到通知”。 在这种情况下,您可以抓取供应商价格,将其推入Elasticsearch并使用其反向搜索(Percolator)功能将价格变动与客户查询进行匹配,并在找到匹配项后最终将警报发送给客户。50 推送
- 您具有分析/业务智能需求,并且想要快速调查,分析,可视化并对许多数据(即数百万或数十亿条记录)提出临时问题。在这种情况下,您可以使用Elasticsearch存储数据,然后使用Kibana(Elasticsearch / Logstash / Kibana堆栈的一部分)构建自定义仪表板,这些仪表板可以可视化对您重要的数据方面。此外,您可以使用Elasticsearch聚合功能对数据执行复杂的商业智能查询。
4.2 ES中的概念
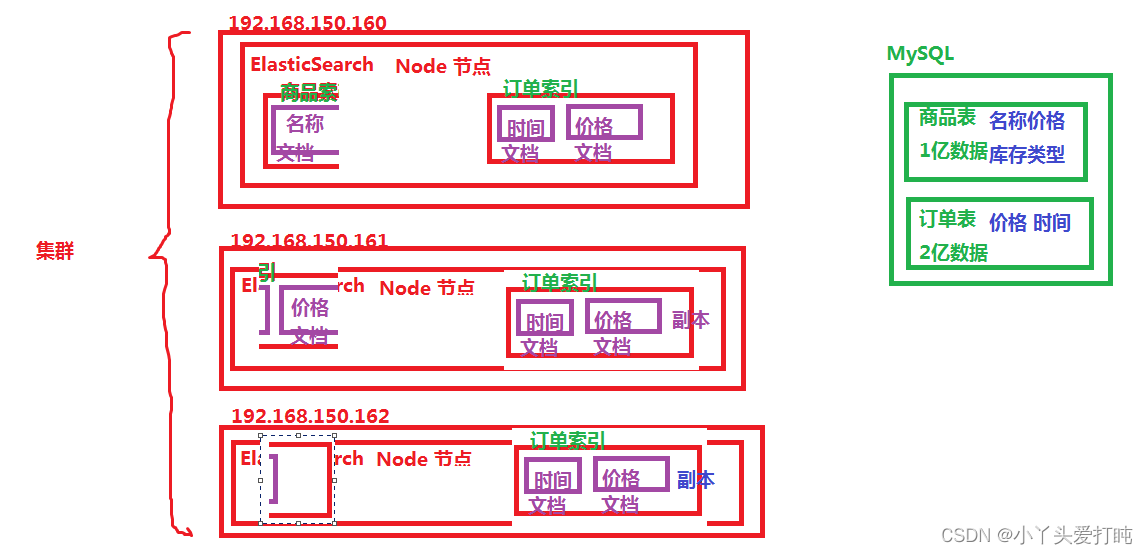
cluster:集群
群集是一个或多个节点(服务器)的集合,这些节点一起保存您的全部数据,并在所有节点之间提供联合索引和搜索功能。集群由唯一名称标识,默认情况下为“ elasticsearch”。此名称很重要,因为如果节点被设置为通过其名称加入群集,则该节点只能是群集的一部分。
确保不要在不同的环境中重复使用相同的集群名称,否则最终可能会导致节点加入错误的集群。例如,您可以将`logging-dev`,`logging-stage`和`logging-prod` 用于开发,登台和生产集群。
请注意,只有一个节点的群集是有效且完全可以的。此外,您可能还具有多个独立的群集,每个群集都有其自己的唯一群集名称。
Node:节点
节点是单个服务器,它是群集的一部分,存储数据并参与群集的索引和搜索功能。就像群集一样,节点由名称标识,该名称默认为在启动时分配给该节点的随机通用唯一标识符(UUID)。如果不想使用默认的节点名称,则可以定义任何节点名称。此名称对于管理目的很重要,在管理中您要识别网络中的哪些服务器与Elasticsearch群集中的哪些节点相对应。
可以将节点配置为通过集群名称加入特定集群。默认情况下,每个节点都设置为加入一个名为的集群`elasticsearch`,这意味着如果您在网络上启动了多个节点,并且假设它们可以相互发现,它们将全部自动形成并加入一个名为的集群`elasticsearch`。
在单个群集中,您可以根据需要拥有任意数量的节点。此外,如果您的网络上当前没有其他Elasticsearch节点在运行,则默认情况下启动单个节点将形成一个名为的新单节点集群`elasticsearch`。
index 索引
索引是具有相似特征的文档的集合。例如,您可以为客户数据创建索引,为产品目录创建另一个索引,为订单数据创建另一个索引。索引由名称标识(必须全为小写),并且对其中的文档执行索引,搜索,更新和删除操作时,该名称用于引用索引。在单个群集中,您可以定义任意多个索引。
document 文档
文档是可以建立索引的基本信息单位。例如,您可以有一个针对单个客户的文档,一个针对单个产品的文档,以及另一个针对单个订单的文档。本文档以[JSON]表示,这是无处不在的Internet数据交换格式。在索引/类型中,您可以存储任意数量的文档。请注意,尽管文档实际上位于索引中,但实际上必须将文档编入索引/分配给索引内的类型。
Shards & Replicas 分片和副本
索引可能存储大量数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文档的单个索引占用了1TB的磁盘空间,可能不适合单个节点的磁盘,或者可能太慢而无法单独满足来自单个节点的搜索请求。
为了解决此问题,Elasticsearch提供了将索引细分为多个碎片的功能。创建索引时,只需定义所需的分片数量即可。每个分片本身就是一个功能齐全且独立的“索引”,可以托管在群集中的任何节点上。
分片很重要,主要有两个原因:
- 它允许您水平分割/缩放内容量
- 它允许您跨碎片(可能在多个节点上)分布和并行化操作,从而提高性能/吞吐量
分片如何分布以及其文档如何聚合回到搜索请求中的机制完全由Elasticsearch管理,并且对您作为用户是透明的。
在随时可能发生故障的网络/云环境中,非常有用,强烈建议您使用故障转移机制,以防碎片/节点因某种原因脱机或消失。为此,Elasticsearch允许您将索引分片的一个或多个副本制作为所谓的副本分片(简称副本)。
复制很重要,主要有两个原因:
- 如果分片/节点发生故障,它可提供高可用性。因此,重要的是要注意,副本分片永远不会与从其复制原始/主分片的节点分配在同一节点上。
- 由于可以在所有副本上并行执行搜索,因此它可以扩展搜索量/吞吐量。
总而言之,每个索引可以分为多个碎片。索引也可以被复制零(意味着没有副本)或更多次。复制后,每个索引将具有主碎片(从中进行复制的原始碎片)和副本碎片(主碎片的副本)。可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您可以随时动态更改副本数,但不能事后更改分片数。
默认情况下,Elasticsearch中的每个索引分配有5个主碎片和1个副本,这意味着如果集群中至少有两个节点,则索引将具有5个主碎片和另外5个副本碎片(1个完整副本),总计每个索引10个碎片。
五 ES集群搭建与应用
5.1 单机ES
克隆一台机器 要求有JDK 修改IP地址 housname 重启
创建一个文件夹目录 : mkdir /home/es
移动到这个目录下: cd /home/es
使用xftp将es的安装包上传到这个路径下
解压当前es安装包: tar -zxvf elasticsearch-6.4.0.tar.gz
配置环境变量
我们先把es的路径复制一下: /home/es/elasticsearch-6.4.0
进入到环境变量的配置文件中: vim /etc/profile
ES_HOME=/home/es/elasticsearch-6.4.0
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.275.b01-0.el7_9.x86_64
PATH=$PATH:$JAVA_HOME/bin:$ES_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME CLASSPATH PATH ES_HOME
重新加载环境变量文件 : source /etc/profile
配置ES
1,创建数据data文件,后面配置用到: mkdir /home/es/elasticsearch-6.4.0/data
(用来存储ES产生的磁盘文件)
2,在/etc/sysctl.conf最后添加(解决:max virtual memory areas vm.max_map_count [65530] is too low错误,vm.max_map_count单个JVM能开启的最大线程数)
vim /etc/sysctl.conf
vm.max_map_count=655360
让文件生效:sysctl -p
3 ,在/etc/security/limits.conf最后添加:(不配置缺省值:1024,解除 Linux 系统的最大进程数和最大文件打开数限制:* 代表针对所有用户 zhangsan表示启动用户名称,与下面创建用户一致 noproc 是代表最大进程数 nofile 是代表最大文件打开数 ES不能使用root账户启动 所以我们需要使用其他用户,其他用户的文件访问权限我们需要开启 此时我们配置的是用户zhangsan的权限 所以我们一会需要创建一个新用户叫zhangsan soft 警告值 hard 上限)
vim /etc/security/limits.conf
zhangsan soft nofile 65536
zhangsan hard nofile 131072
zhangsan soft nproc 4096
zhangsan hard nproc 4096
4 修改节点的配置文件jvm.options
vim /home/es/elasticsearch-6.4.0/config/jvm.options (22行)
-Xms512m
-Xmx512m
原则:最小堆的大小和最大堆的大小应该相等。Elasticsearch可获得越多的堆,并且内存也可以使用更多的缓存。但是需要注意,分配了太多的堆给你的项目,将会导致有长时间的垃圾搜集停留。设置最大堆的值不能超过你物理内存的50%,要确保有足够多的物理内存来保证内核文件缓存。不要将最大堆设置高于JVM用于压缩对象指针的截止值。
5,修改配置文件 ElasticSearch.yml
vim /home/es/elasticsearch-6.4.0/config/elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 集群的名字 多个es如果共属于一个集群 name名字要配置的一样
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 当前节点的名字 同一个集群中 node.name 不能重复
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
# 将来的数据存储到哪个文件夹
path.data: /home/es/elasticsearch-6.4.0/data
#
# Path to log files:
#
path.logs: /home/es/elasticsearch-6.4.0/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#锁定物理内存地址,防止elasticsearch内存被交换出去,也就是避免es使用swap交换分区
bootstrap.memory_lock: false
#是否支持过滤掉系统调用 默认配置文件中没有这个配置 我们需要自己粘上去
bootstrap.system_call_filter: false
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.239.160
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#当启动新节点时,通过这个ip列表进行节点发现,组建集群 写法可以是 ["192.168.239.170","192.168.239.171"]
# 或者这样写 ["host1" , "host2"] 此时指代的是当前电脑的 hosts文件中配置的地址别名
discovery.zen.ping.unicast.hosts: ["es1", "es2","es3"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#通过配置这个参数来防止集群脑裂现象 (集群总节点数量/2)+1 配置代表最少有多少个服务器同意则 当大哥
discovery.zen.minimum_master_nodes: 2
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
6 修改hosts文件 : vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.239.160 es1
192.168.239.161 es2
192.168.239.162 es3
7 创建用户张三 useradd zhangsan
让zhangsan这个用户 能操作 es这个文件夹 chown -R zhangsan:zhangsan es
[root@es-170 home]# ll
total 0
-rw-r--r--. 1 root root 0 Dec 17 15:37 ccc
drwxr-xr-x. 3 zhangsan zhangsan 67 Jan 4 16:24 es
drwxr-xr-x. 2 root root 56 Dec 23 16:30 myshell
drwxr-xr-x. 2 root root 48 Dec 18 15:51 test
drwxr-xr-x. 3 root root 69 Dec 23 17:01 tomcat8
drwx------. 2 zhangsan zhangsan 62 Jan 4 17:03 zhangsan
8 切换用户 : su zhangsan
5.2 集群搭建
克隆当前ES 修改IP地址 houstname 重启 xshell连接
修改 vim vim /home/es/elasticsearch-6.4.0/config/elasticsearch.yml 下的IP地址和node.name
三台电脑都切换到 zhangsan用户 启动
elasticsearch -d
5.3 ES常用地址
当我们运行es之后 就可以 用过 地址栏访问ES状态
我们可以在 linux中使用
curl 192.168.239.160:9200 访问
{
"name" : "node-1",
"cluster_name" : "my-application",
"cluster_uuid" : "rCRURKcRS6aIvu_gkzs0og",
"version" : {
"number" : "6.4.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "595516e",
"build_date" : "2018-08-17T23:18:47.308994Z",
"build_snapshot" : false,
"lucene_version" : "7.4.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
也可以通过浏览器直接访问 也可以使用postman访问
我们可以通过
curl 192.168.239.150:9200/_cat 查看当前es的信息
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master 查询当前集群的主节点
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
curl es1:9200/_cat/nodes?v
curl es1:9200/_cat/health?v
查看集群支持命令:
curl 192.168.23.30:9200/_cat
查看集群是否健康
curl 192.168.23.30:9200/_cat/health
查看master:
curl 192.168.23.30:9200/_cat/master?v
命令支持help:
curl 192.168.23.30:9200/_cat/master?help
查看所有索引:
curl 192.168.23.30:9200/_cat/indices
5.4 ES添加索引
数据类型
核心类型(Core datatype)
字符串:string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;
允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索
(不可用text分词后的模糊检索)。
数值型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
二进制型:binary
我们在es中创建一个索引(相当于我们创建了一个数据库)
创建索引的时候 发送PUT请求 http://192.168.150.160:9200/索引的名称
并且本次请求需要传递JSON数据类型的参数
number_of_shards:每个索引的主分片数,这个配置在索引创建后不能修改。默认值为5
number_of_replicas:每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 3
},
"mappings": {
"hahaha": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"address": {
"type": "keyword"
}
}
}
}
}
此时使用postman发送请求 http://192.168.239.170:9200/test_index
在请求的的body中选择raw选择json 把我们的建索引json参数添加 点击send 如果出现
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test_index"
}
此时我们还可以修改索引
修改索引
PUT /索引名字/_settings
{
"number_of_replicas": 1
}
注意 副本可以改 分片不能改
{"acknowledged":true}
删除索引
DELETE /索引名字 //删除单个索引
DELETE /索引名字1,索引名字2 //删除多个索引
DELETE /index_* //删除以index_开头的索引
DELETE /_all //删除所有索引
{"acknowledged":true}
可以设置下面的属性,使DELETE /_all 失效,必须指定索引名称,才可以删除。
elasticsearch.yml
action.destructive_requires_name: true
5.5 ES中添加数据
添加数据 发送POST请求
http://192.168.239.170:9200/test_index/hahaha/1 最后的1 代表第一条数据
此时还需要通过参数将数据传递到ES中
{
"id":1,
"name":"张三",
"age":18,
"address":"背景"
}
此时会提示添加成功 result= created
{
"_index": "test_index",
"_type": "hahaha",
"_id": "5",
"_version": 1,
"result": "created",
"_shards": {
"total": 4,
"successful": 3,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
5.6 ES中查询数据
GET请求发送
http://192.168.239.160:9200/test_index/hahaha/_search?q=id:5
http://192.168.239.170:9200/test_index/hahaha/_search?q=name:a*
http://192.168.239.170:9200/test_index/hahaha/_search?q=age:18
http://192.168.239.170:9200/test_index/hahaha/_search?q=*:*
复杂的查询
POST请求 http://192.168.239.170:9200/test_index/hahaha/_search
在请求的的body中选择raw选择json 把我们的建索引json参数添加
{
"query": {
"range" : {
"age" : {
"gte": "20",
"lte": "60"
}
}
}
}
点击send 如果出现 查询的结果
{
"took": 23,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.0,
"hits": [
{
"_index": "test_index",
"_type": "hahaha",
"_id": "3",
"_score": 1.0,
"_source": {
"id": 3,
"name": "adsfasdf",
"age": 28,
"address": "shanghai"
}
}
]
}
}
六 Logstash
6.1 安装
选择一个ES上安装 Logstash 170安装
cd /home/es/
使用xftp上传文件
解压当前文件:tar -zxvf logstash-6.4.3.tar.gz
安装logstash-input-jdbc插件 cd /home/es/logstash-6.4.3/bin
执行脚本 ./logstash-plugin install logstash-input-jdbc
cd /home/es/logstash-6.4.3/config
通过XFTP将我们的 mysql.conf 传输到当前文件夹
input {
jdbc {
# 数据库
jdbc_connection_string => "jdbc:mysql://192.168.31.155:3306/test?useSSL=false"
# 用户名密码
jdbc_user => "root"
jdbc_password => "123456"
# jar包的位置 路径不能写错
jdbc_driver_library => "/home/es/logstash-6.4.3/mysql-connector-java-5.1.47.jar"
# mysql的Driver
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#清除第一次同步的时间,日志时间
#clean_run => true
#写sql 例如 select * from t_student
statement_filepath => "/home/es/logstash-6.4.3/config/mysql.sql"
# canel
schedule => "* * * * *"
#索引的类型 分词器类型
type => "monitor_task_video_manual_history"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => "192.168.239.160:9200"
# index名
index => "mysql_index"
# 需要关联的数据库中一个id字段,对应索引的id号
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
新建并编辑SQL文件
vim /home/es/logstash-6.4.3/config/mysql.sql
select * from student
cd.. 到 /home/es/logstash-6.4.3/下 将 数据库连接jar包存放到当前目录下
一切准备就绪: 当前我们是root用户 修改权限
chown -R zhangsan:zhangsan /home/logstash-6.4.3
切换用户 su zhangsan
cd /home/es/logstash-6.4.3/
启动bin/logstash -f config/mysql.conf
测试数据
GET http://192.168.150.160:9200/mysql_index
{
"mysql_index": {
"aliases": {},
"mappings": {
"doc": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"s_address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"s_age": {
"type": "long"
},
"s_gid": {
"type": "long"
},
"s_id": {
"type": "long"
},
"s_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
},
"settings": {
"index": {
"creation_date": "1609835407433",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "Rti17zR-Rc2VsLAZrncTKg",
"version": {
"created": "6040099"
},
"provided_name": "mysql_index"
}
}
}
}
GET 搜索数据
http://192.168.239.150:9200/mysql_index/doc/_search?q=s_name:辛*
七 springboot整合es
7.1 在pom文件中导入依赖
总pom降低一下boot的版本
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
</parent>
在sys中导入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
6.2 添加配置文件
#ES集群的名字
spring.data.elasticsearch.cluster-name=my-application
#ES节点 ip:port ① http请求 9200 JDK 9300
spring.data.elasticsearch.cluster-nodes=192.168.239.170:9300,192.168.239.171:9300,192.168.239.172:9300
6.3 添加实体类(entity domain)
此时我们在es中导入的数据源是 MySQL中的test库里面的student表:s_id s_name s_age s_address.
此时我们根据映射关系创建java对象存储当前每一行的数据
@Data
@Document(indexName = "mysql_index",type = "doc" ,shards=3 ,replicas = 3)
public class ESStudent {
@Id
@JsonProperty("s_id")
private long id;
@JsonProperty("s_name")
private String name;
@JsonProperty("s_address")
private String address;
@JsonProperty("s_age")
private long age;
}
6.4 写一个DAO接口进行查询
package com.aaa.dao;
import com.aaa.entity.Student;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface StudentDAO extends ElasticsearchRepository<Student,Long> { }
此时看一眼继承关系
@NoRepositoryBean
public interface ElasticsearchRepository<T, ID> extends ElasticsearchCrudRepository<T, ID> {
<S extends T> S index(S var1);
<S extends T> S indexWithoutRefresh(S var1);
Iterable<T> search(QueryBuilder var1);
Page<T> search(QueryBuilder var1, Pageable var2);
Page<T> search(SearchQuery var1);
Page<T> searchSimilar(T var1, String[] var2, Pageable var3);
void refresh();
Class<T> getEntityClass();
}
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort var1);
Page<T> findAll(Pageable var1);
}
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
6.5 StudentDAO的使用方式
@RestController
@RequestMapping("/core")
public class StudentController {
@Autowired
private StudentDAO dao;
/**
* 获取所有的学生
* 只能接收get的形式
* @return
*/
@GetMapping("/stu")
public Map listAllStudent(){
QueryBuilder qb = null;
Iterable<Student> search = dao.search(qb);
Iterator<Student> iterator = search.iterator();
List<Student> objects = new ArrayList<>();
while (iterator.hasNext()){
Student next = iterator.next();
objects.add(next);
}
System.out.println(objects);
HashMap<Object, Object> map = new HashMap<>();
map.put("name","zhangsan");
return map;
}
此时我们就可以使用接口里面的CRUD方法对内容进行增删改查 我们重点使用查询方法
6.6 JDK1.8对迭代的优化
@GetMapping("/stu")
public Map listAllStudent(){
List<Student> objects = new ArrayList<>();
QueryBuilder qb = null;
Iterable<Student> search = dao.search(qb);
search.forEach(new Consumer<Student>() {
@Override
public void accept(Student student) {
objects.add(student);
}
});
System.out.println(objects);
HashMap<Object, Object> map = new HashMap<>();
map.put("name","zhangsan");
return map;
}
此时我们使用 forEach这个函数 对Iterable 迭代循环。用到匿名内部类的写法创建了Consumer对象。
forEach是JDK1.8的新方法
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
但是我们new 匿名内部类的写法还是1.7的
new Consumer<Student>() {
@Override
public void accept(Student student) {
objects.add(student);
}
}
此时我们也可以对匿名内部类的写法进行1.8的优化 —————– lambda表达式
@GetMapping("/stu")
public Map listAllStudent(){
List<Student> objects = new ArrayList<>();
QueryBuilder qb = null;
Iterable<Student> search = dao.search(qb);
search.forEach( (Student student) -> objects.add(student) );
System.out.println(objects);
HashMap<Object, Object> map = new HashMap<>();
map.put("name","zhangsan");
return map;
}
6.7 搜索
@Data
public class StudentQuery implements Serializable {
private String name;
private Integer minAge;
private Integer maxAge;
}
创建一个搜索对象 用来接收前端传递过来的搜索的条件
@PostMapping("/stu")
public Map listAllStudent(StudentQuery query){
List<Student> objects = new ArrayList<>();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if(query.getName() != null && !"".equals(query.getName())){
boolQueryBuilder.must( QueryBuilders.wildcardQuery("s_name" , "*"+query.getName()+"*") );
}
if(query.getMinAge() != null ){
boolQueryBuilder.must( QueryBuilders.rangeQuery("s_age").gt(query.getMinAge()) );
}
if(query.getMaxAge() != null ){
boolQueryBuilder.must( QueryBuilders.rangeQuery("s_age").lt(query.getMaxAge()) );
}
Iterable<Student> search = dao.search(boolQueryBuilder);
search.forEach( (Student student) -> objects.add(student) );
System.out.println(objects);
HashMap<Object, Object> map = new HashMap<>();
map.put("name","zhangsan");
return map;
}
6.8 分页功能
@PostMapping("/stu")
public Map listAllStudent(StudentQuery query){
List<Student> objects = new ArrayList<>();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if(query.getName() != null && !"".equals(query.getName())){
boolQueryBuilder.must( QueryBuilders.wildcardQuery("s_name" , "*"+query.getName()+"*") );
}
if(query.getMinAge() != null ){
boolQueryBuilder.must( QueryBuilders.rangeQuery("s_age").gt(query.getMinAge()) );
}
if(query.getMaxAge() != null ){
boolQueryBuilder.must( QueryBuilders.rangeQuery("s_age").lt(query.getMaxAge()) );
}
PageRequest page = PageRequest.of(1, 2);
Iterable<Student> search = dao.search(null,page);
search.forEach( (Student student) -> objects.add(student) );
System.out.println(objects);
HashMap<Object, Object> map = new HashMap<>();
map.put("name","zhangsan");
return map;
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/117992.html

