
MySQL优化和集群
一 MySQL 调优
1.1 MySQL调优方向
① 表的设计合理化(符合3NF)
② 分表技术(水平分割、垂直分割)
④ 读写[写: update/delete/add]分离
⑤ 存储过程 [模块化编程,可以提高速度]
⑥ 对mysql配置优化 [配置最大并发数my.ini,调整缓存大小]
⑦ mysql服务器硬件升级
⑧ 定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
二 表的设计合理化
2.1 范式
数据库的操作,最基础的就是数据库表的设计要优秀。我们要想设计的数据库表优秀,就要符合3NF(三范式).
范式: 规范的程度。
三范式:第一范式 、第二范式、第三范式。 注意其实范式还有很多,只不过我们开发的时候只遵循到第三范式即可。
我们的范式有一个原则,就是后面的范式一定是满足前面范式要求。也就是说 第二范式肯定是满足第一范式的。
2.2 第一范式 —– 遵循原子性
原子性:原子性即操作不可再分。我们之前遇到过的原子性:
多线程的原子性 执行不能再分,a = a +1; 操作不能再分,所以java中专门有一个原子性的包。
事务的(ACID)原子性特性: 事务中的操作单元不可再分,要么都执行要么都不执行。
数据库范式的第一范式遵循原子性: 数据库列是不能再分的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mCwMJ1dN-1666088195790)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201221085254273.png)]
这样的一个操作就是列再分。例如 address这一列再分成 省、市、县。
我们数据库设计的第一范式要求不能这样做,列不能再分。关系型数据库默认支持第一范式。
但是以下操作也是有问题的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-66Eb9pzX-1666088195791)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201221085808432.png)]
2.2 第二范式—– 唯一性
数据库中的数据要有唯一性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cLoB4vuj-1666088195791)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201221090529637.png)]
2.3 第三范式 —– 减少冗余
冗余:重复的数据 , 减少冗余 尽量的不要出现重复的数据,并不能完全消除冗余。
例如:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sxLgVl5b-1666088195792)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201221091153021.png)]
此时就出现了冗余,班级出现了大量的重复。为什么要减少冗余:我们可以从增删改查的方面去思考。当我们在删除的时候 如果删除了4 5 6三个同学。二年级从此消失。如果要将二年级修改成最强二年级。综合考虑 一点也不优秀。
所以我们需要减少冗余
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v4qoqX74-1666088195792)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201221091649817.png)]
2.4 反三范式
在开发中,我们有一些实际的经验告诉我们,完全的去减少冗余,其实开发效率并不是很高。所以诞生了反三范式:适当的冗余反而能提高开发效率。
2.5 数据库表的设计
首先我们需要分析业务实体。找出对应关系。此时分析并设计
1 对 1 : 一张表 二张表 ( user_login user_info )
1对N : 二张表 通过外键维护关系。外键添加到多的一方( student grade )
N对N : 三张表 通过中间表维护关系。 ( student teacher)
项目写好了 发布到生产环境 在使用的时候 发现很慢
1 在开发之前要考虑的 : 数据库表设计范式 分库分表 等
2 在开发之后要考虑的 : SQL语句
思路: 1 定位慢查询 -- 找出项目中哪个SQL执行的慢
2 explain执行计划 -- 分析这条SQL慢的原因
3 专门治理 -- SQL语句调优
2.6 SQL优化
我们数据库表按照三范式的要求进行操作,能减少大量的问题。但是即使我们按照三范式的要求,有些SQL也是不优秀的,此时我们要对SQL进行优化。那么对哪些sql进行优化呢?此时我们首先要有一个原则,慢的SQL才进行优化。哪些SQL是慢的呢?
所以我们优化SQL的第一件事情就是定位慢查询。
方式1: 在项目的配置文件中 配置 druid 开启慢查询日志
spring.datasource.druid.filters=stat
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=1
方式二:在MySQL中开启慢查询日志
首先我们了解mysql数据库的一些运行状态如何查询
(比如想知道当前mysql运行的时间/一共执行了多少次select/update/delete/ 当前连接)
show status
show status like 'connections';
//显示慢查询次数
show status like 'slow_queries';
此时我们发现 慢查询的此时是0 ,证明我们的SQL一直很优秀!那是不可能的,因为默认慢查询是10s以上的SQL。
我们可以通过这个SQL语句,模拟慢查询
SELECT SLEEP(15)
此时再次执行慢查询的此时SQL 发现有一次。但是 如果我们执行了很多SQL例如有800条,此时查询出来是5条,那么是这800条中的哪五条我们显然是不知道。所以我们光查询有几条是慢查询还不行,此时需要将哪条慢 记录下来。
show variables like 'long_query_time' -- 查询慢查询的时间限制
set long_query_time=1 -- 修改慢查询时间为 1s
在默认情况下,我们的mysql不会记录慢查询,需要在启动mysql时候,指定记录慢查询才可以
C:\ProgramData\MySQL\MySQL Server 5.7\
修改my.ini(mysql安装目录下)文件 在 [mysqld]下面添加:
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
slow_query_log=ON
slow_query_log_file =C:/ProgramData/MySQL/MySQL Server 5.7/slow.log
long_query_time=1
重启mysql 查询慢查询开启状态
show variables like '%slow%'
添加一条sql 测试慢查询记录
select SLEEP(5)
去指定路径下查看日志输出
通过explain执行计划查看SQL本身的特征:
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。 通过explain我们可以获得以下信息:
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
| 信息 | 描述 |
| id | 查询的序号,包含一组数字,表示查询中执行select子句或操作表的顺序 **两种情况** id相同,执行顺序从上往下 id不同,id值越大,优先级越高,越先执行 |
| select_type | 查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询 1、simple ——简单的select查询,查询中不包含子查询或者UNION 2、primary ——查询中若包含任何复杂的子部分,最外层查询被标记 3、subquery——在select或where列表中包含了子查询 4、derived——在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放到临时表中 5、union——如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived 6、union result:UNION 的结果 |
| table | 输出的行所引用的表 |
| type | 显示联结类型,显示查询使用了何种类型,按照从最佳到最坏类型排序 1、system:表中仅有一行(=系统表)这是const联结类型的一个特例。 2、const:表示通过索引一次就找到,const用于比较primary key或者unique索引。因为只匹配一行数据,所以如果将主键置于where列表中,mysql能将该查询转换为一个常量 3、eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于唯一索引或者主键扫描 4、ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,可能会找多个符合条件的行,属于查找和扫描的混合体 5、range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是where语句中出现了between,in等范围的查询。这种范围扫描索引扫描比全表扫描要好,因为它开始于索引的某一个点,而结束另一个点,不用全表扫描 6、index:index 与all区别为index类型只遍历索引树。通常比all快,因为索引文件比数据文件小很多。 7、all:遍历全表以找到匹配的行 注意:一般保证查询至少达到range级别,最好能达到ref。 |
| possible_keys | 指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。查询中如果使用覆盖索引,则该索引和查询的select字段重叠。 |
| key_len | 表示索引中使用的字节数,该列计算查询中使用的索引的长度在不损失精度的情况下,长度越短越好。如果键是NULL,则长度为NULL。该字段显示为索引字段的最大可能长度,并非实际使用长度。 |
| ref | 显示索引的哪一列被使用了,如果有可能是一个常数,哪些列或常量被用于查询索引列上的值 |
| rows | 根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要读取的行数 |
| Extra | 包含不适合在其他列中显示,但是十分重要的额外信息 1、Using filesort:说明mysql会对数据适用一个外部的索引排序。而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成排序操作称为“文件排序” 2、Using temporary:使用了临时表保存中间结果,mysql在查询结果排序时使用临时表。常见于排序order by和分组查询group by。 3、Using index:表示相应的select操作用使用覆盖索引,避免访问了表的数据行。如果同时出现using where,表名索引被用来执行索引键值的查找;如果没有同时出现using where,表名索引用来读取数据而非执行查询动作。 4、Using where :表明使用where过滤 5、using join buffer:使用了连接缓存 6、impossible where:where子句的值总是false,不能用来获取任何元组 7、select tables optimized away:在没有group by子句的情况下,基于索引优化Min、max操作或者对于MyISAM存储引擎优化count(*),不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 8、distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。 |
什么是索引呢?
我们可以这样理解: 有一本字典,我们使用字典的时候肯定不是从第一页开始找。 ——— 全表扫描 (注意数据库中如果不使用索引 我们在查询的时候 就是全表扫描) 。 我们查询字典的时候 肯定是先找目录,然后根据目录瞬间定位数据的所在位置 ,然后直接找到这个问题。—— 索引查询。
所以说 索引就好像是给数据库表中的数据 生成的目录。
为什么通过目录去查询就会跟快呢?因为 索引目录有索引算法。——》 B+树
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IgS9F0sz-1666088195792)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201221103656834.png)]
但是索引也有问题,我们生成的索引文件,随着数据的删除添加而改变。
有的时候 我们需要按照姓名查询。此时又会全表扫描。所以我们需要给查询的列 添加索引。
create procedure test9()
begin
declare i int default 0;
while(i<1000000) do
begin
set i=i+1;
insert into t_index values(null,CONCAT("张",i),18,CONCAT("beijing",i) );
end;
end while;
end;
call test9()
索引分类:主键索引、唯一索引、普通索引、全文索引、组合索引
1、主键索引:即主索引,根据主键pk_clolum(length)建立索引,不允许重复,不允许空值
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
2、唯一索引:用来建立索引的列的值必须是唯一的,允许空值
ALTER TABLE 'table_name' ADD UNIQUE INDEX index_name('col');
3、普通索引:用表中的普通列构建的索引,没有任何限制
ALTER TABLE 'table_name' ADD INDEX index_name('col');
4、全文索引:用大文本对象的列构建的索引
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
5、组合索引:用多个列组合构建的索引,这多个列中的值不允许有空值
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
- 遵循“最左前缀”原则,把最常用作为检索或排序的列放在最左,依次递减,组合索引相当于建立了col1,col1col2,col1col2col3三个索引,而col2或者col3是不能使用索引的。
- 在使用组合索引的时候可能因为列名长度过长而导致索引的key太大,导致效率降低,在允许的情况下,可以只取col1和col2的前几个字符作为索引
ALTER TABLE ‘table_name’ ADD INDEX index_name(col1(4),col2(3));
表示使用col1的前4个字符和col2的前3个字符作为索引
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KuUDGRWZ-1666088195793)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20210725112056941.png)]
2.7索引的实现原理
MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,B+Tree索引,哈希索引,全文索引等等
1、哈希索引:
只有memory(内存)存储引擎支持哈希索引,哈希索引用索引列的值计算该值的hashCode,然后在hashCode相应的位置存执该值所在行数据的物理位置,因为使用散列算法,因此访问速度非常快,但是一个值只能对应一个hashCode,而且是散列的分布方式,因此哈希索引不支持范围查找和排序的功能。
2、全文索引:
FULLTEXT(全文)索引,仅可用于MyISAM和InnoDB,针对较大的数据,生成全文索引非常的消耗时间和空间。对于文本的大对象,或者较大的CHAR类型的数据,如果使用普通索引,那么匹配文本前几个字符还是可行的,但是想要匹配文本中间的几个单词,那么就要使用LIKE %word%来匹配,这样需要很长的时间来处理,响应时间会大大增加,这种情况,就可使用时FULLTEXT索引了,在生成FULLTEXT索引时,会为文本生成一份单词的清单,在索引时及根据这个单词的清单来索引。FULLTEXT可以在创建表的时候创建,也可以在需要的时候用ALTER或者CREATE INDEX来添加:****
[
 ](javascript:void(0)😉
](javascript:void(0)😉
//创建表的时候添加FULLTEXT索引
CTREATE TABLE my_table(
id INT(10) PRIMARY KEY,
name VARCHAR(10) NOT NULL,
my_text TEXT,
FULLTEXT(my_text)
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
[ ](javascript:void(0)😉
](javascript:void(0)😉
//创建表以后,在需要的时候添加FULLTEXT索引
ALTER TABLE my_table ADD FULLTEXT INDEX ft_index(column_name);
全文索引的查询也有自己特殊的语法,而不能使用LIKE %查询字符串%的模糊查询语法
select * from users where MATCH(name) AGAINST('zhang*')
不用 如果涉及到大数据量的模糊搜索 使用ES
注意:
对于较大的数据集,把数据添加到一个没有FULLTEXT索引的表,然后添加FULLTEXT索引的速度比把数据添加到一个已经有FULLTEXT索引的表快。
5.6版本前的MySQL自带的全文索引只能用于MyISAM存储引擎,如果是其它数据引擎,那么全文索引不会生效。5.6版本之后InnoDB存储引擎开始支持全文索引
在MySQL中,全文索引支队英文有用,目前对中文还不支持。5.7版本之后通过使用ngram插件开始支持中文。
在MySQL中,如果检索的字符串太短则无法检索得到预期的结果,检索的字符串长度至少为4字节,此外,如果检索的字符包括停止词,那么停止词会被忽略。
*3、BTree索引和****B+Tree索引*****
BTree索引
BTree是平衡搜索多叉树,设树的度为2d(d>1),高度为h,那么BTree要满足以一下条件:
- 每个叶子结点的高度一样,等于h;
- 每个非叶子结点由n-1个key和n个指针point组成,其中d<=n<=2d,key和point相互间隔,结点两端一定是key;
- 叶子结点指针都为null;
- 非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的数据;
BTree的结构如下:
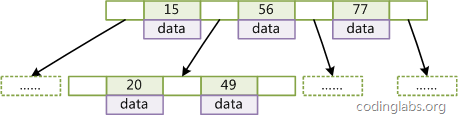
在BTree的机构下,就可以使用二分查找的查找方式,查找复杂度为h*log(n),一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构。
BTree的查询、插入、删除过程可以参考:https://blog.csdn.net/endlu/article/details/51720299
B+Tree索引
B+Tree是BTree的一个变种,设d为树的度数,h为树的高度,B+Tree和BTree的不同主要在于:
- B+Tree中的非叶子结点不存储数据,只存储键值;
- B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址;
- B+Tree的每个非叶子节点由n个键值key和n个指针point组成;
B+Tree的结构如下:
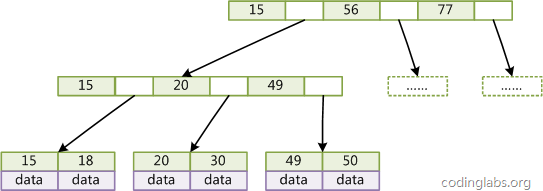
B+Tree对比BTree的优点:
1、磁盘读写代价更低
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
2、查询速度更稳定
由于B+Tree非叶子节点不存储数据(data),因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。
- **带顺序索引的B+TREE****
很多存储引擎在B+Tree的基础上进行了优化,添加了指向相邻叶节点的指针,形成了带有顺序访问指针的B+Tree,这样做是为了提高区间查找的效率,只要找到第一个值那么就可以顺序的查找后面的值。
B+Tree的结构如下:
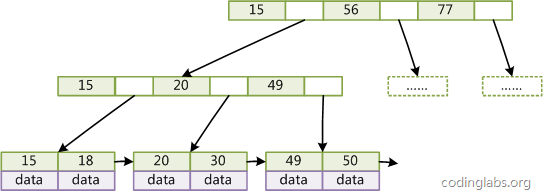
聚簇索引和非聚簇索引
分析了MySQL的索引结构的实现原理,然后我们来看看具体的存储引擎怎么实现索引结构的,MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了非聚簇索引和聚簇索引。
聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序
非聚簇索引的解释是:索引顺序与数据物理排列顺序无关
(这样说起来并不好理解,让人摸不着头脑,清继续看下文,并在插图下方对上述两句话有解释)
首先要介绍几个概念,在索引的分类中,我们可以按照索引的键是否为主键来分为“主索引”和“辅助索引”,使用主键键值建立的索引称为“主索引”,其它的称为“辅助索引”。因此主索引只能有一个,辅助索引可以有很多个。
MyISAM——非聚簇索引
- MyISAM存储引擎采用的是非聚簇索引,非聚簇索引的主索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点的key都存储指向键值对应的数据的物理地址。
- 非聚簇索引的数据表和索引表是分开存储的。
- 非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
- 只有在MyISAM中才能使用FULLTEXT索引。(mysql5.6以后innoDB也支持全文索引)
最开始我一直不懂既然非聚簇索引的主索引和辅助索引指向相同的内容,为什么还要辅助索引这个东西呢,后来才明白索引不就是用来查询的吗,用在那些地方呢,不就是WHERE和ORDER BY 语句后面吗,那么如果查询的条件不是主键怎么办呢,这个时候就需要辅助索引了。
InnoDB——聚簇索引
- 聚簇索引的主索引的叶子结点存储的是键值对应的数据本身,辅助索引的叶子结点存储的是键值对应的数据的主键键值。因此主键的值长度越小越好,类型越简单越好。
- 聚簇索引的数据和主键索引存储在一起。
- 聚簇索引的数据是根据主键的顺序保存。因此适合按主键索引的区间查找,可以有更少的磁盘I/O,加快查询速度。但是也是因为这个原因,聚簇索引的插入顺序最好按照主键单调的顺序插入,否则会频繁的引起页分裂,严重影响性能。
- 在InnoDB中,如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
- 使用主索引的时候,更适合使用聚簇索引,因为聚簇索引只需要查找一次,而非聚簇索引在查到数据的地址后,还要进行一次I/O查找数据。
- 因为聚簇辅助索引存储的是主键的键值,因此可以在数据行移动或者页分裂的时候降低成本,因为这时不用维护辅助索引。但是由于主索引存储的是数据本身,因此聚簇索引会占用更多的空间。
- 聚簇索引在插入新数据的时候比非聚簇索引慢很多,因为插入新数据时需要检测主键是否重复,这需要遍历主索引的所有叶节点,而非聚簇索引的叶节点保存的是数据地址,占用空间少,因此分布集中,查询的时候I/O更少,但聚簇索引的主索引中存储的是数据本身,数据占用空间大,分布范围更大,可能占用好多的扇区,因此需要更多次I/O才能遍历完毕。
下图可以形象的说明聚簇索引和非聚簇索引的区别
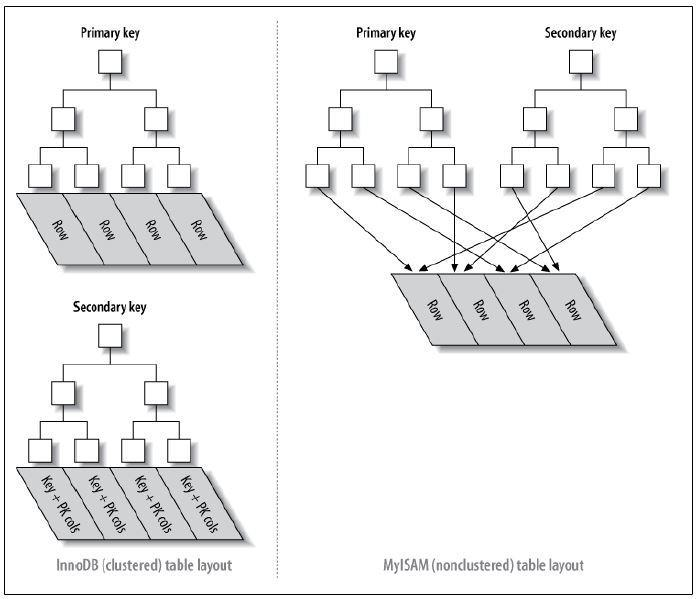
从上图中可以看到聚簇索引的辅助索引的叶子节点的data存储的是主键的值,主索引的叶子节点的data存储的是数据本身,也就是说数据和索引存储在一起,并且索引查询到的地方就是数据(data)本身,那么索引的顺序和数据本身的顺序就是相同的;
而非聚簇索引的主索引和辅助索引的叶子节点的data都是存储的数据的物理地址,也就是说索引和数据并不是存储在一起的,数据的顺序和索引的顺序并没有任何关系,也就是索引顺序与数据物理排列顺序无关。
此外MyISAM和innoDB的区别总结如下:
| MyISAM和innoDB引擎对比 | MyISAM | innoDB |
|---|---|---|
| 索引类型 | 非聚簇 | 聚簇 |
| 支持事务 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 否 | 是(默认) |
| 支持外键 | 否 | 是 |
| 支持全文索引 | 是 | 是(5.6以后支持) |
| 适用操作类型 | 大量select下使用 | 大量insert、delete和update下使用 |
总结如下:
- InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
- MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
- 此外,Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
更多MyISAM和innoDB的区别具体内容参考:MyISAMheinnoDB的区别,包括行级锁死锁的具体分析
什么时候要使用索引?
- 主键自动建立唯一索引;
- 经常作为查询条件在 WHERE 或者 ORDER BY 语句中出现的列要建立索引;
- 作为排序的列要建立索引;
- 查询中与其他表关联的字段,外键关系建立索引
- 高并发条件下倾向组合索引;
- 用于聚合函数的列可以建立索引,例如使用了max(column_1)或者count(column_1)时的column_1就需要建立索引
什么时候不要使用索引?
- 经常增删改的列不要建立索引;
- 有大量重复的列不建立索引;
- 表记录太少不要建立索引。只有当数据库里已经有了足够多的测试数据时,它的性能测试结果才有实际参考价值。如果在测试数据库里只有几百条数据记录,它们往往在执行完第一条查询命令之后就被全部加载到内存里,这将使后续的查询命令都执行得非常快–不管有没有使用索引。只有当数据库里的记录超过了1000条、数据总量也超过了MySQL服务器上的内存总量时,数据库的性能测试结果才有意义。
索引失效的情况:
索引的优化
1、最左前缀
索引的最左前缀和和B+Tree中的“最左前缀原理”有关,举例来说就是如果设置了组合索引<col1,col2,col3>那么以下3中情况可以使用索引:col1,<col1,col2>,<col1,col2,col3>,其它的列,比如<col2,col3>,col2,col3等等都是不能使用索引的。
根据最左前缀原则,我们一般把排序分组频率最高的列放在最左边,以此类推。
2、带索引的模糊查询优化
在上面已经提到,使用LIKE进行模糊查询的时候,’%aaa%’不会使用索引,也就是索引会失效。如果是这种情况,只能使用全文索引来进行优化(上文有讲到)。
3、为检索的条件构建全文索引,然后使用
SELECT * FROM tablename MATCH(index_colum) ANGAINST(‘word’);
4、使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
第三方搜索引擎
select * from student where id = 5
第一步:首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1(选择相对小的表做基础表)。
第二步:接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2
。
第三步:如果是outer join 那么这一步就将添加外部行,left outer jion 就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3 。
第四步:如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。
第五步:应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4,在这有个比较重要的细节不得不说一下,对于包含outer join子句的查询,就有一个让人感到困惑的问题,到底在on筛选器还是用where筛选器指定逻辑表达式呢?on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的。举个简单的例子,有一个学生表(班级,姓名)和一个成绩表(姓名,成绩),我现在需要返回一个x班级的全体同学的成绩,但是这个班级有几个学生缺考,也就是说在成绩表中没有记录。为了得到我们预期的结果我们就需要在on子句指定学生和成绩表的关系(学生.姓名=成绩.姓名)那么我们是否发现在执行第二步的时候,对于没有参加考试的学生记录就不会出现在vt2中,因为他们被on的逻辑表达式过滤掉了,但是我们用left outer join就可以把左表(学生)中没有参加考试的学生找回来,因为我们想返回的是x班级的所有学生,如果在on中应用学生.班级='x'的话,left outer join会把x班级的所有学生记录找回(感谢网友康钦谋__康钦苗的指正),所以只能在where筛选器中应用学生.班级='x' 因为它的过滤是最终的。
第六步:group by 子句将中的唯一的值组合成为一组,得到虚拟表vt5。如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。这一点请牢记。
第七步:应用cube或者rollup选项,为vt5生成超组,生成vt6.
第八步:应用having筛选器,生成vt7。having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
第九步:处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8.
第十步:应用distinct子句,vt8中移除相同的行,生成vt9。事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
第十一步:应用order by子句。按照order_by_condition排序vt9,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
第十二步:应用top选项。此时才返回结果给请求者即用户。
sql语句
①通过变量的方式来设置参数
好:stringsql = "select * from people p where p.id = ? ";
坏:stringsql = "select * from people p where p.id = "+id;
数据库的SQL文解析和执行计划会保存在缓存中,但是SQL文只要有变化,就得重新解析。
“…where p.id = ”+id的方式在id值发生改变时需要重新解析,这会耗费时间。
②不要使用select *
好:string sql = "select people_name,pepole_age from people ";
坏:stringsql = "select * from people ";
使用select *的话会增加解析的时间,另外会把不需要的数据也给查询出来,数据传输也是耗费时间的,
比如text类型的字段通常用来保存一些内容比较繁杂的东西,如果使用select *则会把该字段也查询出来。
③谨慎使用模糊查询
好: string sql = "select * from people p where p.id like 'parm1%' ";
坏: string sql = "select * from people p where p.id like '%parm1%' ";
当模糊匹配以%开头时,该列索引将失效,若不以%开头,该列索引有效。
④不要使用列号
好:string sql = "select people_name,pepole_age from people order by name,age";
坏:string sql = "select people_name,pepole_age from people order by 6,8";
使用列号的话,将会增加不必要的解析时间。
⑤优先使用UNION ALL,避免使用UNION
好:string sql = "select name from student union all select name from teacher";
坏:string sql = "select name from student union select name from teacher";
UNION 因为会将各查询子集的记录做比较,故比起UNION ALL ,通常速度都会慢上许多。一般来说,如果使用UNION ALL能满足要求的话,务必使用UNION ALL。还有一种情况,如果业务上能够确保不会出现重复记录。
⑥在where语句或者order by语句中避免对索引字段进行计算操作
好:string sql = "select people_name,pepole_age from people where create_date=date1 ";
坏:string sql = "select people_name,pepole_age from people where trunc(create_date)=date1";
当在索引列上进行操作之后,索引将会失效。正确做法应该是将值计算好再传入进来。
⑦使用not exist代替not in
好:string sql = "select * from orders where customer_name not exist (select customer_name from customer)";
坏:string sql = "select * from orders where customer_name not in(select customer_name from customer)";
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not exist 的子查询依然能用到表上的索引。
⑧ exist和in的区别
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。因此,in用到的是外表的索引, exists用到的是内表的索引。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:select * from A where cc in (select cc from B)
效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc)
效率高,用到了B表上cc列的索引。
2:
select * from B where cc in (select cc from A)
效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc)
效率低,用到了A表上cc列的索引。
⑨避免在索引列上做如下操作:
◆避免在索引字段上使用<>,!=
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免在索引列上出现数据类型转换(比如某字段是String类型,参数传入时是int类型)
当在索引列上使用如上操作时,索引将会失效,造成全表扫描。
⑩复杂操作可以考虑适当拆成几步
有时候会有通过一个SQL语句来实现复杂业务的例子出现,为了实现复杂的业务,嵌套多级子查询。造成SQL性能问题。对于这种情况可以考虑拆分SQL,通过多个SQL语句实现,或者把部分程序能完成的工作交给程序完成。
三 分表技术(水平分割、垂直分割)
3.1 什么是分表技术
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,我们可以称为子表,每个表都对应三个文件,.MYD数据文件,.MYI索引文件,.frm表结构文件。
这些子表可以分布在同一块磁盘上,也可以在不同的机器上。app读写的时候根据事先定义好的规则得到对应的子表名,然后去操作它。
3.2 分表的方式
水平拆分 、 垂直拆分
3.3 垂直拆分
把原来有很多列的表拆分成多个表,原则是:
(1)把常用、不常用的字段分开放
user_login 、 user_info 、 user_account 、 user_other
我们可以将用户的所有信息 存储到一张表中
id 姓名 年龄 地址 手机号 账号 密码 昵称 邮箱 余额 冻结金额 花呗 网商 段位 驾驶证 身份证 …
此时我们可以垂直查分成几张表
id 账号 密码 user_login
id 姓名 年龄 地址 手机号 user_info
id 昵称 邮箱 余额 冻结金额 花呗 网商 段位 user_account
id 驾驶证 身份证 … user_other
(2)把大字段独立存放在一个表中
id 标题 作者 时间 小说内容
1 三体 xx xx yyyyyy
2 哈哈 yyyy aaa pppppp
此时我们将大数据的列拆分
id 标题 作者 时间 小说简表
id 小说内容 sid 小说内容表
3.4 水平查分
我们有一张数据库表 ,有一亿行所以我们可以这样
id username password email tel … user_2015
id username password email tel … user_2016
id username password email tel … user_2017
id username password email tel … user_2018
id username password email tel … user_2019
id username password email tel … user_2020
业务流程
获取需要哪一年的用户 —》2018
String tableName = “user_” + 年份;
String sql = select * from tableName where 。。。。
水平查分的思路:
(1)按时间结构
如果业务系统对时效性较高,比如新闻发布系统的文章表,可以把数据库设计成时间结构,按时间分有几种结构:
(a)平板式
表类似:
article_201701
article_201702
article_201703
用年来分还是用月可自定,但用日期的话表就太多了,也没这必要。一般建议是按月分就可以。
这种分法,其难处在于,假设我要列20条数据,结果这三张表里都有2条,那么业务上很有可能要求读三次表。如果时间长了,有几十张表,而每张表是0条,那不就是要读完整个系统的表才行么?另外这个结构,要作分页是比较难实现的。
主键:在这个系统中,主键是13位带毫秒的时间戳,不要用自动编号,否则难以通过主键定位到表,也可以在查询时带上时间,但比较烦琐。
(b)归档式
表类似: 100
article_old
article_new
为了解决平板式的缺点,可以采用时间归档式设计,可以看到这个系统只有两张表。一张是旧文章表,一张是新文章表,新文章表放2个月的信息,每天定期把2
个月中的最早一天的文章归入旧表中。这样一方面可以解决性能问题,因为一般新闻发布系统读取的都是新的内容,旧的内容读取少;第二可以委婉地解决功能问
题,比如平板式所说的问题,在归档式中最多也只需要读2张表就完成了。
归档式的缺点在于旧表容量还是相对比较大,如果业务允许,可对旧表中的超旧内容进行再归档或直接清理掉。
(2)按版块结构
如果按照文章的所属版块进行拆表,比如新闻、体育版块拆表,一方面可以使每个表数据量分离,另一方面是各版块之间相互影响可降到最低。假如新闻版块的数据表损坏或需要维护,并不会影响到体育版块的正常工作,从而降低了风险。版块结构同时常用于bbs这样的系统。
板块结构也有几种分法:
(a)对应式
对于版块数量不多,而且较为固定的形式,就直接对应就好。比如新闻版块,可以分出新闻的目录表,新闻的文章表等。
news_category
news_article
sports_category
sports_article
可看到每一个版块都对应着一组相同的表结构,好处就是一目了然。在功能上,因为版块之间还是有一些隔阂,所以需要联合查询的需求不多,开发上比时间结构的方式要轻松。
主键:依旧要考虑的,在这个系统中,主键是版块+时间戳,单纯的时间戳或自动编号也能用,查询时要记得带上版块用于定位表。
(b)冷热式
对应式的缺点是,如果版块数量很大而且不确定,那要分出的表数量就太多了。举个例子:百度贴吧,如果按一个词条一个表设计,那得有多少张表呢?
用这样的方式吧。
tieba_汽车
tieba_飞机
tieba_火箭
tieba_unite
这个表汽车、火箭表是属于热门表,定义为新建的版块放在unite表里面,待到其超过一万张主贴的时候才开对应表结构。因为在贴吧这种系统中,冷门版块
肯定比热门版块多得多,这些冷门版块通常只有几张帖子,为它们开表也太浪费了;同时热门版块数量和访问量等,又比冷门版块多得多,非常有特点。
unite表还可以扩展成哈希表,利用词条的md5编码,可以分成n张表,我算了一下,md5前一位可分36张表,两位即是1296张表,足够了。
tieba_unite_ab
tieba_unite_ac
(3)按哈希结构
哈希结构通常用于博客之类的基于用户的场合,在博客这样的系统里有几个特点,1是用户数量非常多,2是每个用户发的文章数量都较少,3是用户发文章不定
期,4是每个用户发得不多,但总量仍非常之大。基于这些特点,用以上所说的任何一种分表方式都不合适,一没有固定的时效不宜用时间拆,二用户很多,而且还
偏偏都是冷门,所以也不宜用版块(用户)拆。
哈希结构在上面有所提及,既然按每个用户不好直接拆,那就把一群用户归进一个表好了。
blog_aa
blog_ab
blog_ac
如上所说,md5取前两位哈希可以达到1296张表,如果觉得不够,那就再加一位,总数可达46656张表,还不够?
表的数量太多,要创建这些表也是挺麻烦的,可以考虑在程序里往数据库insert之前,多执行一句判断表存在与否并创建表的语句,很实用,消耗也并不很大。
主键:依旧要考虑的,在这个系统中,主键是用户ID+时间戳,单纯的时间戳或自动编号也能用,但查询时要记得带上用户名用于定位表。
四 MySQL的配置优化
table_cache=1024
物理内存越大,设置就越大.默认为2402,调到512-1024最佳。由于每个客户端连接都会至少访问一个表,因此此参数的值与max_connections有关。当某一连接访问一个表时,MySQL会检查当前已缓存表的数量。如果该表已经在缓存中打开,则会直接访问缓存中的表已加快查询速度;如果该表未被缓存,则会将当前的表添加进缓存并进行查询。在执行缓存操作之前,table_cache用于限制缓存表的最大数目:如果当前已经缓存的表未达到table_cache,则会将新表添加进来;若已经达到此值,MySQL将根据缓存表的最后查询时间、查询率等规则释放之前的缓存。
innodb_additional_mem_pool_size=4M
默认为2M
innodb_thread_concurrency=8
你的服务器CPU有几个就设置为几,建议用默认一般为8
key_buffer_size=256M
默认为218,调到128最佳/用于缓存MyISAM表的索引块。决定数据库索引处理的速度(尤其是索引读),批定用于索引的缓冲区大小,增加它可以得到更好的索引处理性能,对于内存在4GB左右的服务器来说,该参数可设置为256MB或384MB。
tmp_table_size=64M
默认为16M,调到64-256最挂
read_buffer_size=4M
默认为64K读查询操作所能使用的缓冲区大小。和sort_buffer_size一样,该参数对应的分配内存也是每连接独享。 对表进行顺序扫描的请求将分配一个读入缓冲区,MySql会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
read_rnd_buffer_size=16M
默认为256K, MySql的随机读(查询操作)缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySql会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
sort_buffer_size=32M
默认为256KSort_Buffer_Size 并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。例如:500个连接将会消耗 500*sort_buffer_size(8M)=4G内存,Sort_Buffer_Size 超过2KB的时候,就会使用mmap() 而不是 malloc() 来进行内存分配,导致效率降低。
join_buffer_size = 8M
联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享。
innodb_buffer_pool_size=105M
InnoDB使用缓冲池来缓存索引和行数据。该值设置的越大,则磁盘IO越少。一般将该值设为物理内存的80%。这对Innodb表来说非常重要。Innodb相比MyISAM表对缓冲更为敏感。MyISAM可以在默认的 key_buffer_size 设置下运行的可以,然而Innodb在默认的 innodb_buffer_pool_size 设置下却跟蜗牛似的。由于Innodb把数据和索引都缓存起来,无需留给操作系统太多的内存,因此如果只需要用Innodb的话则可以设置它高达 70-80% 的可用内存。一些应用于 key_buffer 的规则有 — 如果你的数据量不大,并且不会暴增,那么无需把 innodb_buffer_pool_size 设置的太大了
myisam_max_sort_file_size=100G
mysql重建索引时允许使用的临时文件最大大小,MyISAM表发生变化时重新排序所需的缓冲
query_cache_size=64M
查询缓存大小,用于缓存SELECT查询结果。如果有许多返回相同查询结果的SELECT查询,并且很少改变表,可以设置query_cache_size大于0,可以极大改善查询效率。而如果表数据频繁变化,就不要使用这个,会适得其反.对于使用MySQL的用户,对于这个变量大家一定不会陌生。前几年的MyISAM引擎优化中,这个参数也是一个重要的优化参数。但随着发展,这个参数也爆露出来一些问题。机器的内存越来越大,人们也都习惯性的把以前有用的参数分配的值越来越大。这个参数加大后也引发了一系列问题。我们首先分析一下 query_cache_size的工作原理:一个SELECT查询在DB中工作后,DB会把该语句缓存下来,当同样的一个SQL再次来到DB里调用时,DB在该表没发生变化的情况下把结果从缓存中返回给Client。这里有一个关建点,就是DB在利用Query_cache工作时,要求该语句涉及的表在这段时间内没有发生变更。那如果该表在发生变更时,Query_cache里的数据又怎么处理呢?首先要把Query_cache和该表相关的语句全部置为失效,然后在写入更新。那么如果Query_cache非常大,该表的查询结构又比较多,查询语句失效也慢,一个更新或是Insert就会很慢,这样看到的就是Update或是Insert怎么这么慢了。所以在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。而且在高并发,写入量大的系统,建议把该功能禁掉。
query_cache_limit = 4M
指定单个查询能够使用的缓冲区大小,缺省为1M
定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
一、Innodb存储引擎清理碎片方法
ALTER TABLE tablename ENGINE=InnoDB
六 MySQL集群配置
任何的集群都是为了保证高可用,防止单点故障
| ip地址 | 作用 | 配置 | 其他 |
|---|---|---|---|
| 192.168.239.110 | MySQL 主 | master | 会为主从112 |
| 192.168.239.111 | MySQL 从 | slave从110 | |
| 192.168.239.112 | MySQL 主 | master | 会为主从110 |
| 192.168.239.113 | MySQL 从 | slave从112 | |
| 192.168.239.114 | MyCat | 中间件 |
6.1 安装MySQL
克隆一个linux系统 进入此虚拟机
修改IP地址为 192.168.239.110
修改主机名字 vim /etc/hostname
重启网络 service network restart
使用xshell连接
创建一个 mysql目录 mkdir /home/mysql
进入到这个目录 cd /home/mysql
下载 MySQL源 wget http://repo.mysql.com/mysql-community-release-el6-5.noarch.rpm
安装MySQL源:rpm -ivh mysql-community-release-el6-5.noarch.rpm
查看安装后有效的MySQL源:yum repolist all | grep mysql
下载安装MySQL:yum -y install mysql-community-server
查看MySQL启动状态:service mysqld status
启动MySQL: service mysqld start
连接MySQL : mysql -uroot -p
>show databases;
>use mysql;
>update user set password=password('123456') where user='root';
>update user set host='%' where host='localhost';
>flush privileges;
>exit;
6.2 搭建主从的MySQL服务
A 主从复制
在实际的生产中,为了解决Mysql的单点故障以及提高MySQL的整体服务性能,一般都会采用「主从复制」
例如我们只有一台MySQL服务器,突然之间有一个程序员将数据库锁死了。此时所有人都用不了了。所以我们会对数据库进行备份。
但是备份也有问题。例如我们早上九点备份了,使用了一天里面有了很多新数据,此时宕机了,我们还原备份顶多是今早上九点的。
所以我们可以搭建MySQL的主从集群。有多台电脑都安装MSSQL,实时进行同步,如果有一台宕机了,另一台还有数据。我们就将MySQL分成主数据库master,和从数据库slave。 主从复制的意思就是 从mysql服务器 要复制 主MySQL服务器的内容。
比如:在复杂的业务系统中,有一句sql执行后导致锁表,并且这条sql的的执行时间有比较长,那么此sql执行的期间导致服务不可用,这样就会严重影响用户的体验度。主从复制中分为「主服务器(master)「和」从服务器(slave)」,「主服务器负责写,而从服务器负责读」,Mysql的主从复制的过程是一个「异步的过程」。这样读写分离的过程能够是整体的服务性能提高,即使写操作时间比较长,也不影响读操作的进行。
B 主从复制的原理
Mysql的主从复制中主要有三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread),Master一条线程和Slave中的两条线程。
A master(binlog dump thread)主要负责Master库中有数据更新的时候,会按照binlog格式,将更新的事件类型写入到主库的binlog文件中。并且,Master会创建log dump线程通知Slave主库中存在数据更新,这就是为什么主库的binlog日志一定要开启的原因。
B I/O thread线程在Slave中创建,该线程用于请求Master,Master会返回binlog的名称以及当前数据更新的位置、binlog文件位置的副本。然后,将binlog保存在 「relay log(中继日志)」 中,中继日志也是记录数据更新的信息。
C SQL线程也是在Slave中创建的,当Slave检测到中继日志有更新,就会将更新的内容同步到Slave数据库中,这样就保证了主从的数据的同步。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZVSt0QtF-1666088195795)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201222143356296.png)]
以上就是主从复制的过程,当然,主从复制的过程有不同的策略方式进行数据的同步,主要包含以下几种:
「同步策略」:Master会等待所有的Slave都回应后才会提交,这个主从的同步的性能会严重的影响。
「半同步策略」:Master至少会等待一个Slave回应后提交。
「异步策略」:Master不用等待Slave回应就可以提交。
「延迟策略」:Slave要落后于Master指定的时间。
对于不同的业务需求,有不同的策略方案,但是一般都会采用最终一致性,不会要求强一致性,毕竟强一致性会严重影响性能。
C 搭建MySQL的主从复制
克隆 150 这台服务器
进入克隆的linux系统 修改ip地址 修改 hostname 重启网卡 使用xshell连接
配置清单:150 MySQL 主 151 MySQL 从
在主mysql中配置: vim /etc/my.cnf
日志文件随便起名字 但是log_bin是固定的 server-id当前数据库的唯一标识符 我们一般使用ip地址来设定
:12 log_bin=haha server-id=150
重启MySQL : service mysqld restart
连接MySQL: mysql -uroot -p
查看master状态:show master status;
+-------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------+----------+--------------+------------------+-------------------+
| haha.000001 | 120 | | | |
+-------------+----------+--------------+------------------+-------------------+
在从MySQL中配置: vim /etc/my.cnf
我们的从服务 不需要开启日志文件 只需要添加server-id即可
:12 server-id=111
因为我们的MySQL是克隆的,所以两个MySQL的UUID一样,此时我们需要删除UUID配置信息:
rm -rf /var/lib/mysql/auto.cnf
重启MySQL : service mysqld restart
连接MySQL: mysql -uroot -p
关闭slave: stop slave;
配置从机复制哪台主机:
change master to master_host='192.168.150.140',master_user='root',master_password='123456',master_log_file='haha.000001',master_log_pos=120;
启动slave: start slave;
查看状态:show slave status \G;
6.3 搭建双主双从
克隆 110 系统 两台 分别修改 ip地址为 192.168.239.112 192.168.239.113 修改hostname 重启网卡 使用xshell连接
配置 140 的主服务
修改my.cnf vim /etc/my.cnf
log_bin=hehe
server-id=112
删除UUID :rm -rf /var/lib/mysql/auto.cnf
重启mysql服务: service mysqld restart
连接MySQL: mysql -uroot -p
查看master状态:show master status;
+-------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------+----------+--------------+------------------+-------------------+
| hehe.000001 | 120 | | | |
+-------------+----------+--------------+------------------+-------------------+
配置 141 的从服务
修改my.cnf vim /etc/my.cnf
server-id=113
删除UUID :rm -rf /var/lib/mysql/auto.cnf
重启mysql服务: service mysqld restart
连接MySQL: mysql -uroot -p
停止从服务: stop slave;
配置主服务: change master to master_host='192.168.239.142',master_user='root',master_password='123456',master_log_file='hehe.000001',master_log_pos=120;
开启从服务: start slave;
查看状态: show slave status \G;
配置互为主从
将 140 配置成 142 的主
找到 110 连接到 110 的MySQL 查看其状态
show master status;
+-------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------+----------+--------------+------------------+-------------------+
| haha.000002 | 120 | | | |
+-------------+----------+--------------+------------------+-------------------+
到 112 中配置从服务 连接到 112 的MySQL
停止从服务: stop slave;
配置主服务: change master to master_host='192.168.239.142',master_user='root',master_password='123456',master_log_file='hehe.000001',master_log_pos=291;
开启从服务: start slave;
查看状态: show slave status \G;
此时 112 继续 :show master status;
+-------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------+----------+--------------+------------------+-------------------+
| hehe.000001 | 120 | | | |
+-------------+----------+--------------+------------------+-------------------+
此时跑到 110 中 连接110的MySQL
停止从服务: stop slave;
配置主服务: change master to master_host='192.168.239.142',master_user='root',master_password='123456',master_log_file='hehe.000002',master_log_pos=407;
开启从服务: start slave;
查看状态: show slave status \G;
此时我们双主双从 并且双主互为主从配置完成,但是此时 我们在一个主中进行操作 此时 另一个主的 从服务器响应不到。
我们到 110 和 112 配置文件中添加
vim /etc/my.cnf
在servlet-id 下一行添加 log-slave-updates
重启服务即可 service mysqld restart
6.4 读写分离
A 什么是读写分离
读写分离就是数据的更新(insert udpate delete等等)和 查询(select等)让不同的数据库服务器执行。
数据库读写分离对于大型系统或者访问量(并发量)很高的互联网应用来说,是必不可少的一个重要功能。从数据库的角度来说,对于大多数应用来说,从集中到分布,最基本的一个需求不是数据存储的瓶颈,而是在于计算的瓶颈,即SQL查询的瓶颈,我们知道,正常情况下,InsertSQL就是几十个毫秒的时间内写入完成,而系统中的大多数SelectSQL则要几秒到几分钟才能有结果,很多复杂的SQL,其消耗服务器CPU的能力超强,不亚于死循环的威力。在没有读写分离的系统上,很可能高峰时段的一些复杂SQL查询就导致数据库服务器CPU爆表,系统陷入瘫痪,严重情况下可能导致数据库崩溃。
我们将MySQL进行主从复制的集群搭建,有的数据库是负责读服务,有的负责写服务。换个角度去想,我们是java开发人员,你需要连接数据库 去读写数据,难道你需要自己判断当前SQL是读还是写,然后去访问不同的数据库吗?
此时我们需要在springboot项目中 配置多数据源。想想就很麻烦。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z1YMHgyG-1666088195796)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201222163313920.png)]
所以 阿里巴巴 就推出了一个强大的中间件—— MyCat 。
B MyCat简介 —— Mycat数据库分库分表中间件
活跃的、性能好的开源数据库中间件!
我们致力于开发高性能的开源中间件而努力!
一个彻底开源的,面向企业应用开发的大数据库集群
支持事务、ACID、可以替代MySQL的加强版数据库
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
http://dl.mycat.org.cn/mycat-definitive-guide.pdf
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CT3SP2NH-1666088195796)(…/…/课件/qy134/框架/mysql优化和集群/assets/image-20201222163855268.png)]
C mycat的原理
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
D 搭建MyCat服务中间件
克隆一台空的Linux 修改ip地址为 192.168.239.114 修改hostname 重启网卡 xshell连接
安装JDK
查看JDK是否安装:yum list installed | grep jdk
如果安装了则卸载: yum -y remove 对应JDK版本
查看JDK版本列表:yum search java | grep -i --color jdk
选择版本安装:yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel
查看java版本:java -version
查看环境变量:echo $JAVA_HOME
配置环境变量:vim /etc/profile (G o)
# set java environment
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME CLASSPATH PATH
更新环境变量:source /etc/profile
到home下面创建一个mycat文件夹
mkdir /home/mycat
进入到mycat文件夹
cd /home/mycat
使用wget下载mycat安装包
wget http://dl.mycat.org.cn/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
解压当前的mycat压缩包
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
此时我们的mycat安装成功了
配置mycat的环境变量 vim /etc/profile
MYCAT_HOME=/home/mycat/mycat
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin:$MYCAT_HOME/bin
export JAVA_HOME CLASSPATH PATH MYCAT_HOME
重新加载配置文件 source /etc/profile
修改mycat的配置信息,对接我们搭建的MySQL双主双从集群
修改mycat的配置文件中server.xml
vim /home/mycat/mycat/conf/server.xml
找到33行 将 <property name="serverPort">8066</property>
在配置文件的最后 我们得知 mycat的账号是 root 密码是 123456
修改mycat的配置文件中schema.xml vim /home/mycat/mycat/conf/schema.xml
进入配置文件在底行模式中输入 : 6,32d
<!-- checkSQLschema 设置成true 会将sql语句中的虚拟表名删除
sqlMaxLimit 默认在select * from xxx表 这样的语句中添加limit
select * from xxx表 limit 100
-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" >
</schema>
<!-- database 设定数据库的实际数据库 我的MySQL集群确实有一个数据库是test01 -->
<dataNode name="dn1" dataHost="localhost1" database="test01" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.239.110:3306" user="root"
password="root">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="192.168.239.111:3306" user="root" password="root" />
</writeHost>
<writeHost host="hostM2" url="192.168.239.112:3306" user="root"
password="root">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.239.113:3306" user="root" password="root" />
</writeHost>
</dataHost>
重启 mycat : mycat restart
通过Navicat连接mycat
192.168.239.154 8066 root 123456
修改日记级别为debug: vim /home/mycat/mycat/conf/log4j2.xml
重启mycat: mycat restart
测试写操作 :使用mycat 添加 数据
查看日志:grep insert logs/mycat.log
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection root = DriverManager.getConnection("jdbc:mysql://192.168.239.114:8066/TESTDB", "root", "123456");
PreparedStatement preparedStatement = root.prepareStatement("insert into student (name,age) values ('123',12)");
preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/117993.html

