
MySQL 高级
本章内容
PLSQL编程
3.1、 MySQL练习题
CREATE table Student
(SId varchar(10),Sname varchar(10),Sage datetime,Ssex varchar(10));
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
insert into Student values('02' , '钱电' , '1990-12-21' , '男');
insert into Student values('03' , '孙风' , '1990-12-20' , '男');
insert into Student values('04' , '李云' , '1990-12-06' , '男');
insert into Student values('05' , '周梅' , '1991-12-01' , '女');
insert into Student values('06' , '吴兰' , '1992-01-01' , '女');
insert into Student values('07' , '郑竹' , '1989-01-01' , '女');
insert into Student values('09' , '张三' , '2017-12-20' , '女');
insert into Student values('10' , '李四' , '2017-12-25' , '女');
insert into Student values('11' , '李四' , '2012-06-06' , '女');
insert into Student values('12' , '赵六' , '2013-06-13' , '女');
insert into Student values('13' , '孙七' , '2014-06-01' , '女');
create table Course(CId varchar(10),Cname nvarchar(10),TId varchar(10));
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
create table Teacher(TId varchar(10),Tname varchar(10));
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');
create table SC(SId varchar(10),CId varchar(10),score decimal(18,1));
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 80);
insert into SC values('03' , '01' , 80);
insert into SC values('03' , '02' , 80);
insert into SC values('03' , '03' , 80);
insert into SC values('04' , '01' , 50);
insert into SC values('04' , '02' , 30);
insert into SC values('04' , '03' , 20);
insert into SC values('05' , '01' , 76);
insert into SC values('05' , '02' , 87);
insert into SC values('06' , '01' , 31);
insert into SC values('06' , '03' , 34);
insert into SC values('07' , '02' , 89);
insert into SC values('07' , '03' , 98);
1、查询” 01 “课程比” 02 “课程成绩高的学生的信息及课程分数
select c.*, a.score
from sc a, sc b, student c
where a.sid=b.sid and c.sid=a.sid and a.cid=1 and b.cid=2 and a.score>b.score;
#笛卡尔积形式的连接,不能加上a.cid=b.cid
2、查询同时选” 01 “课程和” 02 “课程的学生
select a.sid
from sc a, sc b
where a.sid=b.sid and a.cid=1 and b.cid=2;
3、查询选修了” 01 “课程但可能没有选修” 02 “课程的学生情况(不存在时显示为 null )
方法一:
select * from
(select * from sc where cid=1) a
left join
(select * from sc where cid=2) b
on a.sid=b.sid;

方法二:
select *
from student a
left join SC b on a.SID = b.SID and b.CID = '01'
left join SC c on a.SID = c.SID and c.CID = '02'
where b.score is not null;
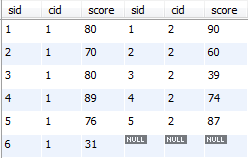
运行结果:没有where子句时,中间表的连接结果如下图,题目要求选修了1号课程,可能没有选修2号课程,所以根据下图的结果,可以得知,只要把选修了1号课程的同学查询出来即可,即where子句中的条件为: b.score is not null
方法三: 这种方法和方法二相同,只是where 子句有所不同,如果想使用方法三,where子句的条件需要修改为b.score>= isnull(c.score),
原因是b.score>isnull(c.score),
假定c.score是null,isnull(c.score)返回的结果为1,那么当b.score=1时,此时b.score>isnull(c.score)不成立,那么这一条记录就会被过滤掉
select a.* , b.score b_score ,c.score c_score from Student a
left join SC b on a.SID = b.SID and b.CID = '01'
left join SC c on a.SID = c.SID and c.CID = '02'
where b.score > = isnull(c.score); #,注意,是>=, 这一句,目的是为了筛选出b表中不为null的成绩,因为isnull(c.score)返回结果只有0和1两种情况
思路解析:
select a.* , b.score b_score ,c.score c_score from Student a
left join SC b on a.SID = b.SID and b.CID = '01'
left join SC c on a.SID = c.SID and c.CID = '02';
isnull( )使用说明:
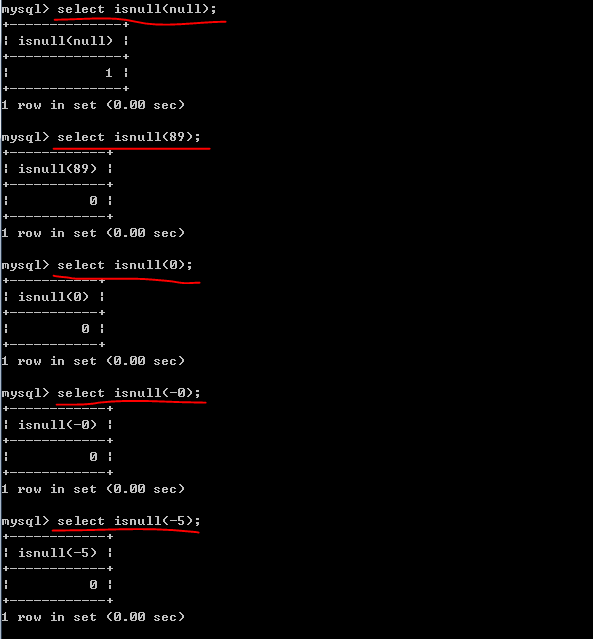
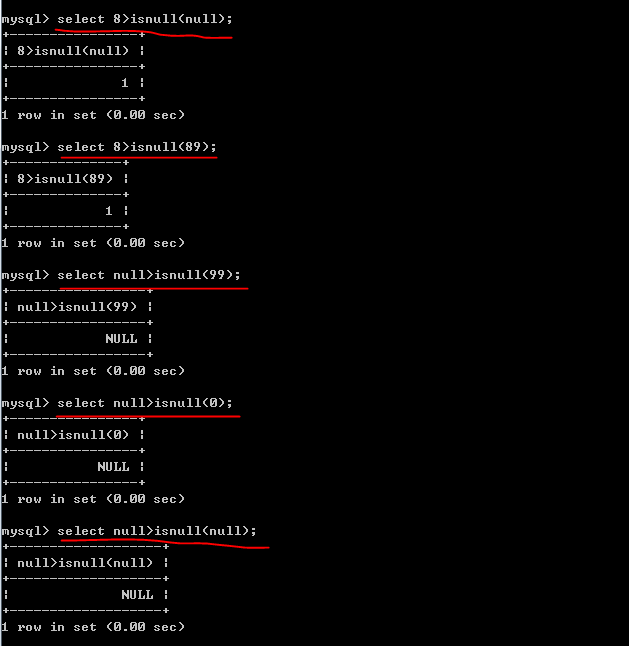
4、查询不存在” 01 “课程但存在” 02 “课程的情况
思路:选修2课程的id号课程中,剔除选修了1课程的id 号
select distinct sid
from sc
where cid=2 and sid not in
(select sid
from sc
where cid=1
);
7、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
select student.sid, student.sname, count(sc.cid) as "选课总数", sum(sc.score) as "总成绩"
from student left join sc on student.sid=sc.sid
group by student.sid ;
8、查询「李」姓老师的数量
#(例子:查询以s开头的老师数量)
select count(*) from teacher where tname like 's%';
9、查询学过「张三」老师授课的同学的信息
(例子:查询学过 jane 老师授课的学生信息)
select student.*
from student, sc, course, teacher
where student.sid=sc.sid and sc.cid=course.cid and course.tid=teacher.tid and teacher.tname='jane';
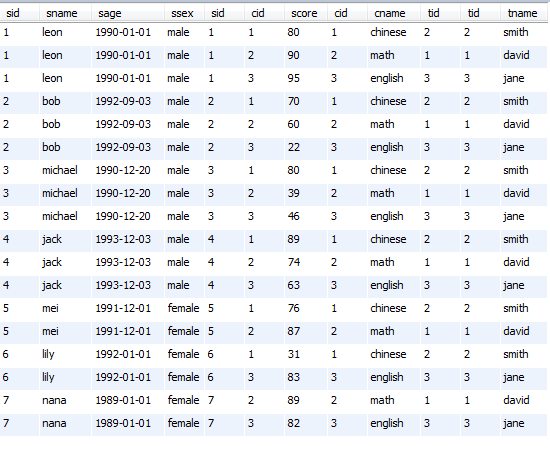
中间表:
select *
from student, sc, course, teacher
where student.sid=sc.sid and sc.cid=course.cid and course.tid=teacher.tid ;
10、查询没有学全所有课程的同学的信息
select student.*
from sc , student
where student.sid=sc.sid
group by sc.sid
having count(sc.cid)<(select count(*) from course); # 查询课程表course中有多少门课
11、查询至少有一门课与学号为” 01 “的同学所学相同的同学的信息
ps:把1号同学排除
select distinct student.*
from student, sc
where student.sid=sc.sid and sc.sid!=1 and sc.cid in (
select distinct cid from sc where sid=1);
12、查询和” 01 “号同学学习的课程 完全相同的其他同学的信息
正确代码:
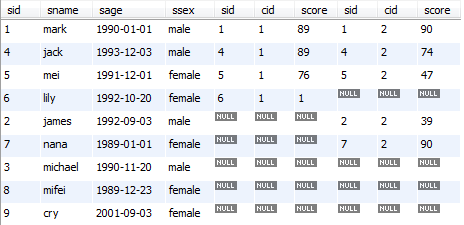
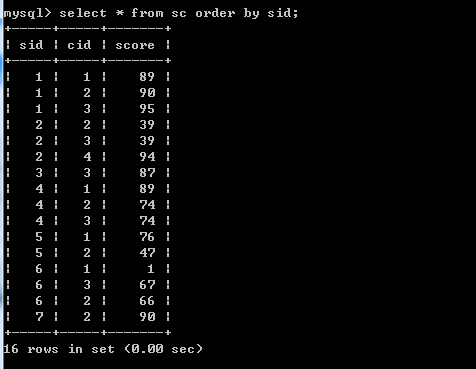
此时SC表如图:可以看到,将sid分组的情况下,除6号同学外,每个同学的成绩记录都是按照cid增序的顺序插入的;只有6号同学的课程插入顺序是1,3,2
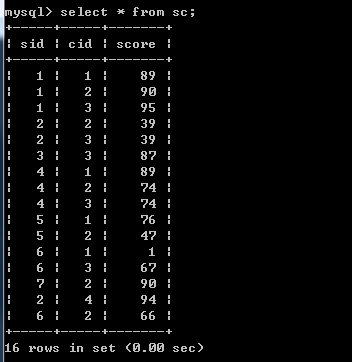
上面这张表不太容易看,对sid按增序排序后,如下图,查看每个同学cid插入的顺序如何,注意:只对sid排序,对cid排序后就不能看出来每个同学cid插入的顺序如何了。
排序后,可以更清楚的看到只有6号同学的课程插入顺序是乱的,不是按照cid增序插入的。
完全正确的代码:
PS:不仅使用了group_concat( )函数,还对group_concat( )函数中的参数进行了排序。
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.*
from
(select sid, group_concat(cid order by cid) as tt from sc where sid=1 group by sid order by cid ) a #1号同学选修的课程
#这里对cid进行了排序,因为group_concat()函数连接cid的值时,默认是按照该值在SC表中的插入顺序进行连接的
left join
( select sid, group_concat(cid order by cid) as rr from sc where sid!=1 group by sid order by cid ) b on a.tt=b.rr
# #除1号同学外,其他同学选修的课程,将两张表进行连接,按照选修课程相同为条件进行连接
join student on b.sid=student.sid;
[ ](javascript:void(0)😉
](javascript:void(0)😉
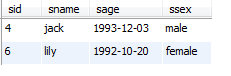
运行结果:
下面代码也有漏洞:group _concat( cid)中不对cid排序,则返回结果如下:
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.*
from
(select sid, group_concat(cid ) as tt from sc where sid=1 group by sid order by cid ) a
left join
( select sid, group_concat(cid ) as rr from sc where sid!=1 group by sid order by cid ) b on a.tt=b.rr
join student on b.sid=student.sid;
[ ](javascript:void(0)😉
](javascript:void(0)😉
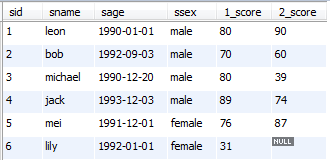
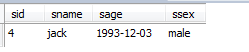
运行结果:只查询出了4号同学
必须要排序的原因: 可以看到,1,4,6号同学选的课程都一样,只是6号同学课程插入时是乱序的,结果造成下面这种情况,连接的结果也是按插入顺序连接的,这样,系统认为1号同学和6号同学的课程是不一样的,所以group_concat( cid )中要对cid排序,即使用group_concat( cid order by cid)
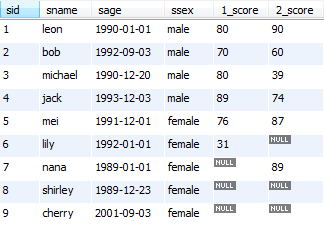
select sid, group_concat(cid) as '选修课程' from sc group by sid;
运行结果:

总结:
按同学分组后,如果每个同学的课程插入记录是顺序增加或顺序降低的,则使用group_concat( )函数时不对参数进行排序,没有问题。
但如果每个同学的课程插入记录是乱序的,则使用group_concat( )函数时必须对参数进行排序。
错误代码: 下面的代码看似正确,其实有漏洞,很有迷惑性
分析: 假定一共有4门课,课程号cid=1,2,3,4; SC表如下,其中1同学、4同学、6同学都选修了1,2,3这三门课,不存在选修了全部课程的同学,这种情况下,使用下面代码解决这道题目没有问题,但是
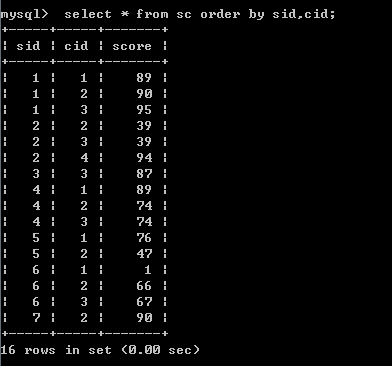
假定表的情况按上述情况,运行下面代码,返回的结果看似是正确的:
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.*
from sc ,student
where student.sid=sc.sid and sc.cid in ( select cid from sc where sid=1) and student.sid!=1
group by sc.sid
having count(*) in (select count(*) from sc where sid=1);
[ ](javascript:void(0)😉
](javascript:void(0)😉
运行结果:
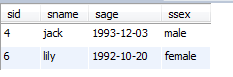
举一个例子揭示上述代码的漏洞:
在上面的那张表中,插入了一条记录,结果就是6号同学选修了全部课程,那么此时,只有4号同学和1号同学选修的课程完全相同
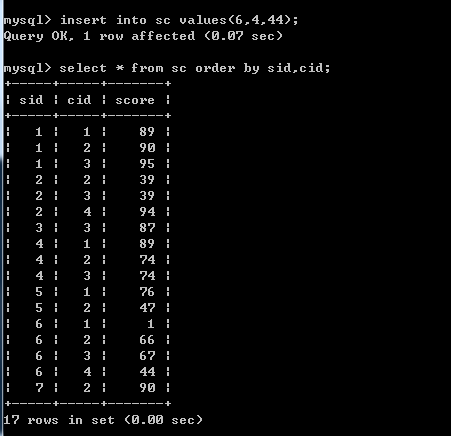
同样运行上面代码,查看运行结果:
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.*
from sc ,student
where student.sid=sc.sid and sc.cid in ( select cid from sc where sid=1) and student.sid!=1
group by sc.sid
having count(*) in (select count(*) from sc where sid=1);
[ ](javascript:void(0)😉
](javascript:void(0)😉
运行结果: 仍然把6号同学给选了出来,此时,正确的结果应当只有第一条
13、查询没学过”张三”老师讲授的任一门课程的学生姓名
(例子:smith老师)
思路:先把学过smith老师课程的学号选出来,然后从student表中剔除这些学号
[](javascript:void(0)😉
select student.*
from student
where sid not in (
select sid from sc ,course, teacher
where sc.cid=course.cid and course.tid=teacher.tid and teacher.tname='smith');
[ ](javascript:void(0)😉
](javascript:void(0)😉
14、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
A:查询出两门以上不及格的学号
[ ](javascript:void(0)😉
](javascript:void(0)😉
select sid
from sc
where score<60
group by sid
having count(*)>=2;
[ ](javascript:void(0)😉
](javascript:void(0)😉
A:完整结果
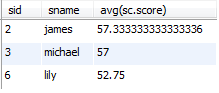
个人理解:我理解的平均成绩某个同学所有选修课程的平均成绩,而不是不及格课程的平均成绩。
例如,2号同学选了3门课,有2门不及格,平均成绩是指3门的平均成绩,而不是2门的。
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.sid, student.sname, avg(sc.score)
from (student join sc on student.sid=sc.sid ) join
(
select sc.sid as esid
from sc
where sc.score<60
group by sc.sid
having count(*)>=2) a
on student.sid=a.esid
group by student.sid
order by student.sid;
[ ](javascript:void(0)😉
](javascript:void(0)😉
运行结果:
15、检索” 01 “课程分数小于 60,按分数降序排列的学生信息
select student.*
from sc,student
where cid=1 and score<60 and sc.sid=student.sid
order by score desc;
16、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
select sc.*, a.avgscore
from sc left join (select sid, avg(score) as avgscore from sc group by sid) a on sc.sid=a.sid
order by a.avgscore desc;
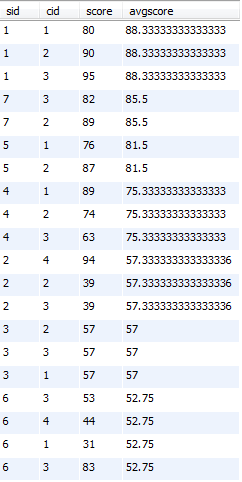
17、查询各科成绩最高分、最低分和平均分
select cid, max(score), min(score), avg(score)
from sc
group by cid;
18、以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
[ ](javascript:void(0)😉
](javascript:void(0)😉
select sc.cid, course.cname,count(sc.sid) as '选修人数', max(sc.score), min(score), avg(score),
(sum(case when score>=60 then 1 else 0 end)/count(sc.sid)) as '及格率',
(sum(case when score>=70 and score<80 then 1 else 0 end) /count(sc.sid)) as '中等率',
(sum(case when score>=80 and score<90 then 1 else 0 end)/count(sc.sid)) as '优良率',
(sum(case when score>=90 then 1 else 0 end)/count(sc.sid)) as '优秀率'
from sc, course
where sc.cid=course.cid
group by sc.cid
order by count(sc.sid) desc, cid ; #按选修人数降序排列,如果人数相同,按课程号cid升序排列
19、按各科成绩进行排序,并显示排名, Score 重复时保留名次空缺
思路:这里不能使用a.score<=b.score
select a.sid ,a.cid, a.score, count(a.score<b.score)+1 as rank
from sc a left join sc b on a.cid=b.cid and a.score<b.score
group by a.cid, a.sid
order by a.cid, a.score desc;
20、按各科成绩进行排序,并显示排名, Score 重复时合并名次
思路:看某个分数在所有分数中,小于等于的有几个
select a.sid ,a.cid, a.score, count( distinct b.score)+1 as rank
from sc a left join sc b on a.cid=b.cid and a.score<b.score
group by a.cid, a.sid
order by a.cid, a.score desc;
或者 如果是a.score<=b.score,则count( distinct b.score) 即可,不用加1
select a.sid ,a.cid, a.score, count( distinct b.score) as rank
from sc a left join sc b on a.cid=b.cid and a.score<=b.score
group by a.cid, a.sid
order by a.cid, a.score desc;
21、查询学生的总成绩,并进行排名,总分重复时保留名次空缺
[ ](javascript:void(0)😉
](javascript:void(0)😉
select a.* ,count(a.cj<b.cj)+1 as rank
from
(select sid , sum(score) as cj from sc group by sid) a
left join
( select sid, sum(score) as cj from sc group by sid) b
on a.cj<b.cj
group by a.sid
order by a.cj desc
;
[ ](javascript:void(0)😉
](javascript:void(0)😉
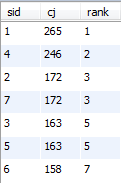
22、 查询学生的总成绩,并进行排名,总分重复时不保留名次空缺
[ ](javascript:void(0)😉
](javascript:void(0)😉
select a.* ,count(distinct b.cj)+1 as rank
from
(select sid , sum(score) as cj from sc group by sid) a
left join
( select sid, sum(score) as cj from sc group by sid) b
on a.cj<b.cj
group by a.sid
order by a.cj desc
;
[ ](javascript:void(0)😉
](javascript:void(0)😉
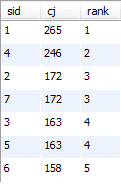
23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 及所占百分比
[ ](javascript:void(0)😉
](javascript:void(0)😉
select sc.cid,cname,count(sid) as '总人数',
concat(round(sum(case when score>=0 and score<60 then 1 else 0 end) /count(sid)*100,2),'%') as '0-60',
concat(round(sum(case when score>=60 and score<70 then 1 else 0 end)/count(sid)*100,2),"%") as '60-70',
concat(round(sum(case when score>=70 and score<85 then 1 else 0 end)/count(sid)*100,2),"%") as '70-85',
concat(round(sum(case when score<=100 and score>=85 then 1 else 0 end )/count(*)*100,2),'%') as '85-100'
from sc join course on sc.cid=course.cid
group by cid;
[ ](javascript:void(0)😉
](javascript:void(0)😉
24、查询各科成绩前三名的记录
思路:先将各科成绩进行排序(这里应该是不保留名次空缺),然后从成绩表SC中选出排名<=3的记录
[ ](javascript:void(0)😉
](javascript:void(0)😉
select * from
(
select a.*, count(distinct b.score) +1 as rank
from sc a
left join sc b
on a.cid=b.cid and a.score<b.score
group by a.cid, a.sid
order by a.cid, a.score desc) c
where c.rank<=3
;
[ ](javascript:void(0)😉
](javascript:void(0)😉
25、查询每门课程被选修的学生数
select cid, count(*) as '选修人数'
from sc
group by cid;
26、查询出只选修两门课程的学生学号和姓名
[ ](javascript:void(0)😉
](javascript:void(0)😉
select sc.sid, student.sname
from student, sc
where student.sid=sc.sid
group by sc.sid
having count(sc.cid)=2;
[](javascript:void(0)😉
27、查询男生、女生人数
select ssex as '性别' , count(*) as '人数'
from student
group by ssex;
28、查询名字中含有「风」字的学生信息
select * from student where sname like '%m%'; #这个是查询姓名含有m的学生信息,m在开头或者中间位置都可以
select * from student where sname like 'm%'; #这个是查询姓名以m开头的学生信息
29、查询同名同姓学生名单,并统计同名人数
select sname , count(*) as '人数'
from student
group by sname;
30、查询 1990 年出生的学生名单
select * from student where sage like "1990%" ;
31、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
select cid, avg(score) as '平均成绩'
from sc
group by cid
order by avg(score) desc, cid;
32、查询平均成绩大于等于 85 的所有学生的学号、姓名和平均成绩
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.sid, student.sname, a.pj
from student join
(select sid, avg(score) as 'pj'
from sc
group by sid
having avg(score)>=85) a
on student.sid=a.sid ;
[ ](javascript:void(0)😉
](javascript:void(0)😉
33、查询课程名称为「数学」,且分数低于 60 的学生姓名和分数
select student.sname, score
from student, sc, course
where student.sid=sc.sid and sc.cid=course.cid and score<60 and cname='math';
34、查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)
select student.sid,student.sname, sc.cid,sc.score
from student left join sc on student.sid=sc.sid
order by student.sid;
| 1 | mark | 1 | 80 |
|---|---|---|---|
| 1 | mark | 3 | 95 |
| 1 | mark | 2 | 90 |
| 2 | james | 2 | 39 |
| 2 | james | 3 | 39 |
| 2 | james | 4 | 94 |
| 3 | michael | 1 | 93 |
| 3 | michael | 3 | 87 |
| 4 | jack | 2 | 74 |
| 4 | jack | 1 | 89 |
| 4 | jack | 3 | 83 |
| 5 | mei | 1 | 76 |
| 5 | mei | 2 | 47 |
| 6 | lily | 4 | 44 |
| 6 | lily | 1 | 41 |
| 6 | lily | 3 | 83 |
| 7 | nana | 3 | 83 |
| 7 | nana | 2 | 89 |
| 8 | mifei | NULL | NULL |
| 9 | cry | NULL | NULL |
35、查询任何一门课程成绩在 70 分以上的姓名、课程名称和分数
select sname, cname ,score
from (sc join student on sc.sid=student.sid) join course on sc.cid=course.cid
where score>70
order by sc.sid;
36、查询不及格的课程
select course.cname, sc.score
from sc join course on sc.cid=course.cid
where sc.score<60;
37、查询课程编号为 01 且课程成绩在 80 分以上的学生的学号和姓名
select student.sid, student.sname
from student ,sc
where student.sid=sc.sid and sc.cid=1 and sc.score>80
order by cid ;
38、求每门课程的学生人数
select cid, count(*) as '该课程的选修人数'
from sc
group by cid;
39、成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
40、成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
PS:这两道题,使用下面同样的代码都能运行出正确结果
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.*, a.score
from sc a left join sc b on a.cid=b.cid and a.score<b.score #对每门课程下的学生成绩排名
join course on a.cid=course.cid
join teacher on course.tid=teacher.tid and tname='张三' #这一行和上一行,是为了筛选张三老师教的课
join student on a.sid=student.sid # 获取学生信息
group by a.cid, a.sid
having count( a.score< b.score)=0 #筛选名次rank=1, count(a.score<b.score)+1=1,两端减去1,简化为count(a.score<b.score)=0
#上面这一行having 子句,这种格式也可以:having count( distinct b.score)=0 ,使用distinct
;
[](javascript:void(0)😉
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
[ ](javascript:void(0)😉
](javascript:void(0)😉
select sc.cid , sc.sid, sc.score
from sc join (select cid, score from sc group by cid, score having count(sid)>=2) a
on sc.cid=a.cid and sc.score=a.score
order by cid ;
[ ](javascript:void(0)😉
](javascript:void(0)😉
或
[](javascript:void(0)😉
select sc.sid, sc.cid , sc.score
from sc join (select sid, score from sc group by sid, score having count(cid)>=2) a
on sc.sid=a.sid and sc.score=a.score
order by sid;
[](javascript:void(0)😉
42、查询每门功成绩最好的前两名
思路:先对每门课程下的成绩排序,然后筛选排名<=2的
[ ](javascript:void(0)😉
](javascript:void(0)😉
select a.cid, a.sid, sname, a.score, count(distinct b.score)+1 as 'rank'
from ( sc a left join sc b on a.cid=b.cid and a.score<b.score) join student on a.sid=student.sid
group by a.cid, a.sid
having rank<=2
order by cid
;
[ ](javascript:void(0)😉
](javascript:void(0)😉
43、统计每门课程的学生选修人数(超过 5 人的课程才统计)
select sc.cid,cname,count(sid) as '选修人数'
from sc join course on sc.cid=course.cid
group by sc.cid
having count(sid)>4;
44、检索至少选修两门课程的学生学号
select sid
from sc
group by sid
having count(cid)>=2;
45、查询选修了全部课程的学生信息
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.*
from sc join student on sc.sid=student.sid
group by sid
having count(*) in (
select count(*) from course);
[ ](javascript:void(0)😉
](javascript:void(0)😉
计算年龄,只按年份来算和按月日来算的区别
46、查询各学生的年龄,只按年份来算
select student.sid, student.sname,student.ssex, year(now())-year(student.sage) as 'age'
from student;
47、按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
[ ](javascript:void(0)😉
](javascript:void(0)😉
select student.sid, student.sname,student.ssex, sage,
timestampdiff(year,sage,now()) as '按月日计算', # 出生月日< 当前日期的月日时,年龄会减一 ,该题目功能是通过这一句实现的,下一句只是为了对比说明两者之间的差别
year(now())-year(sage) as '按年份计算'
from student;
[](javascript:void(0)😉
48、查询本周过生日的学生
select *
from student
where week(concat_ws('-',year(now()),date_format(sborn,'%m-%d')))=week(now());
49、查询下周过生日的学生
select *
from student
where week(concat_ws('-',year(now()),date_format(sborn,'%m-%d')))=week(now())+1;
50、查询本月过生日的学生
select *
from student
where month(student.sage)=month(now());
51、查询下月过生日的学生
select *
from student
where month(student.sage)=month(now())+1;
3.2 、存储过程
3.2.1 存储过程定义
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
3.2.2 存储过程的特点
1、能完成较复杂的判断和运算
2、可编程,灵活
3、SQL编程的代码可重复使用
4、执行的速度相对快一些
5、减少网络之间的数据传输,节省开销
3.2.3 创建一个简单的存储过程
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for lottery
-- ----------------------------
DROP TABLE IF EXISTS `lottery`;
CREATE TABLE `lottery` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`num1` int(10) NULL DEFAULT NULL,
`num2` int(10) NULL DEFAULT NULL,
`num3` int(10) NULL DEFAULT NULL,
`ctime` time(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for oplog
-- ----------------------------
DROP TABLE IF EXISTS `oplog`;
CREATE TABLE `oplog` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`userid` int(20) NOT NULL,
`username` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`action` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`optime` timestamp(0) NULL DEFAULT NULL,
`old_values` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`new_values` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for orders
-- ----------------------------
DROP TABLE IF EXISTS `orders`;
CREATE TABLE `orders` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`order_num` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_date` datetime(0) NULL DEFAULT NULL,
`money` decimal(12, 3) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of orders
-- ----------------------------
INSERT INTO `orders` VALUES (1, '202107070001', '2021-07-16 21:53:55', 200.000);
INSERT INTO `orders` VALUES (2, '202107080002', '2021-07-17 21:54:10', 100.000);
INSERT INTO `orders` VALUES (3, '202107090003', '2021-07-18 21:54:25', 300.000);
-- ----------------------------
-- Table structure for test1
-- ----------------------------
DROP TABLE IF EXISTS `test1`;
CREATE TABLE `test1` (
`id` int(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for users
-- ----------------------------
DROP TABLE IF EXISTS `users`;
CREATE TABLE `users` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int(10) NULL DEFAULT NULL,
`status` int(10) NULL DEFAULT NULL,
`score` int(10) NULL DEFAULT NULL,
`accontid` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of users
-- ----------------------------
INSERT INTO `users` VALUES (1, '张三', 19, 0, 40, '10001');
INSERT INTO `users` VALUES (2, '李四', 15, 1, 0, '10002');
INSERT INTO `users` VALUES (3, '王五', 15, 2, 0, '10001');
INSERT INTO `users` VALUES (4, '马六', 20, 3, 0, '10003');
SET FOREIGN_KEY_CHECKS = 1;
1、创建存储过程的简单语法
create procedure 名称()
begin
.........
end
2、创建一个简单的存储过程
create procedure testa()
begin
select * from users;
select * from orders;
end;
3、调用存储过程
call testa();
3.2.4 存储过程的变量
1、先通过一个简单的例子来学习变量的声明和赋值
create procedure test2()
begin
-- 使用 declare语句声明一个变量
declare username varchar(32) default '';
-- 使用set语句给变量赋值
set username='xiaoxiao';
-- 将users表中id=1的名称赋值给username
select name into username from users where id=1;
-- 返回变量
select username;
end;
2、概括
(1)、变量的声明使用declare,一句declare只声明一个变量,变量必须先声明后使用;
(2)、变量具有数据类型和长度,与mysql的SQL数据类型保持一致,因此甚至还能制定默认值、字符集和排序规则等;
(3)、变量可以通过set来赋值,也可以通过select into的方式赋值;
(4)、变量需要返回,可以使用select语句,如:select 变量名。
3.2.5 变量的作用域
1、变量作用域说明:
(1)、存储过程中变量是有作用域的,作用范围在begin和end块之间,end结束变量的作用范围即结束。
(2)、需要多个块之间传值,可以使用全局变量,即放在所有代码块之前
(3)、传参变量是全局的,可以在多个块之间起作用
2、通过一个实例来验证变量的作用域
需求: 创建一个存储过程,用来统计表users、orders表中行数数量和orders表中的最大金额和最小金额
create procedure test3()
begin
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;
3、如果我们将过程test(3)改为如下:
create procedure test3()
begin
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select userscount,ordercount,maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;
再次调用call test3(); 此时没有信息
4、将userscount,ordercount改为全局变量,再次验证
create procedure test3()
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
begin
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select userscount,ordercount,maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;
过程中变量的作用域,作用范围在begin和end块之间,end结束变量的作用范围即结束
3.2.5 存储过程参数
1、基本语法
create procedure 名称([IN|OUT|INOUT] 参数名 参数数据类型 )
begin
.........
end
2、存储过程的传出参数IN
存储过程的参数类型有:IN,OUT,INOUT,下面分别介绍这个三种类型:
说明:
(1)、传入参数:类型为in,表示该参数的值必须在调用存储过程时指定,如果不显示指定为in,那么默认就是in类型。
(2)、IN类型参数一般只用于传入,在调用过程中一般不作为修改和返回
(3)、如果调用存储过程中需要修改和返回值,可以使用OUT类型参数
通过一个实例来演示:
需求:编写存储过程,传入id,根据id返回name
create procedure test4(userId int)
begin
declare username varchar(32) default '';
declare ordercount int default 0;
select name into username from users where id=userId;
select username;
end;
3、存储过程的传出参数out
需求:调用存储过程时,传入userId返回该用户的name
create procedure test5(in userId int,out username varchar(32))
begin
select name into username from users where id=userId;
end;
set @aaa = "";
-- 调用存储过程时,传入变量
call test5(4, @aaa );
-- 显示变量
select @aaa '名字';
概括:
1、传出参数:在调用存储过程中,可以改变其值,并可返回;
2、out是传出参数,不能用于传入参数值;
3、调用存储过程时,out参数也需要指定,但必须是变量,不能是常量;
4、如果既需要传入,同时又需要传出,则可以使用INOUT类型参数
(3).存储过程的可变参数INOUT
需求:调用存储过程时,传入userId和userName,即使传入,也是传出参数。
create procedure test6(inout userId int,inout username varchar(32))
begin
set userId=2;
set username='';
select id,name into userId,username from users where id=userId;
end;
概括:
1、可变变量INOUT:调用时可传入值,在调用过程中,可修改其值,同时也可返回值;
2、INOUT参数集合了IN和OUT类型的参数功能;
3、INOUT调用时传入的是变量,而不是常量;
3.2.6存储过程条件语句
1、基本结构
(1)、条件语句基本结构:
if() then…else…end if;
(2)、多条件判断语句:
if() then...
elseif() then...
else ...
end if;
2、实例
实例1:编写存储过程,如果用户userId是偶数则返回username,否则返回userId
create procedure test7(in userId int)
begin
declare username varchar(32) default '';
if(userId%2=0)
then
select name into username from users where id=userId;
select username;
else
select userId;
end if;
end;
2、存储过程的多条件语句应用示例
需求:根据用户传入的uid参数判断
(1)、如果用户状态status为1,则给用户score加10分;
(2)、 如果用户状态status为2,则给用户score加20分;
(3)、 其他情况加30分
create procedure test8(in userid int)
begin
declare my_status int default 0;
select status into my_status from users where id=userid;
if(my_status=1)
then
update users set score=score+10 where id=userid;
elseif(my_status=2)
then
update users set score=score+20 where id=userid;
else
update users set score=score+30 where id=userid;
end if;
end;
3.2.7存储过程循环语句
1、while语句
(1)、while语句的基本结构
while(表达式) do
......
end while;
(2)、示例
需求:使用循环语句,向表test1(id)中插入10条连续的记录
create procedure test9()
begin
declare i int default 0;
while(i<10) do
begin
select i;
set i=i+1;
insert into test1(id) values(i);
end;
end while;
end;
2、repeat语句
(1)、repeat语句基本的结构:
repeat...until...end repeat;
(2)、示例
需求:给test1表中的id字段插入数据,从1到10
create procedure test10()
begin
declare i int default 0;
repeat
begin
select i;
set i=i+1;
insert into test1(id) values(i);
end;
until i>=10 -- 如果i>=10,则跳出循环
end repeat;
end;
概括:
until判断返回逻辑真或者假,表达式可以是任意返回真或者假的表达式,只有当until语句为真是,循环结束。
3.3、存储过程游标的使用
3.2.1 游标的概念
游标的概念: 游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是用于临时存储从数据库中提取的数据块。在某些情况下,需要把数据从存放在磁盘的表中调到计算机内存中进行处理,最后将处理结果显示出来或最终写回数据库。这样数据处理的速度才会提高,否则频繁的磁盘数据交换会降低效率。
游标有两种类型:显式游标和隐式游标。在前述程序中用到的SELECT…INTO…查询语句,一次只能从数据库中提取一行数据,对于这种形式的查询和DML操作,系统都会使用一个隐式游标。但是如果要提取多行数据,就要由程序员定义一个显式游标,并通过与游标有关的语句进行处理。显式游标对应一个返回结果为多行多列的SELECT语句。
游标一旦打开,数据就从数据库中传送到游标变量中,然后应用程序再从游标变量中分解出需要的数据,并进行处理。
3.2.2 游标的使用
示例
需求:编写存储过程,使用游标,把users表中 id为偶数的记录逐一更新用户名
create procedure test11()
begin
declare stopflag int default 0;
declare username VARCHAR(32);
-- 创建一个游标变量,declare 变量名 cursor ...
declare username_cur cursor for select name from users where id%2=0;
-- 游标是保存查询结果的临时区域
-- 游标变量username_cur保存了查询的临时结果,实际上就是结果集
-- 当游标变量中保存的结果都查询一遍(遍历),到达结尾,将变量stopflag设置为1,用于循环中判断是否结束
declare continue handler for not found set stopflag=1;
open username_cur; -- 打卡游标
-- 游标向前走一步,取出一条记录放到变量username中
while(stopflag=0) do -- 如果游标还没有结尾,就继续
begin
fetch username_cur into username;
-- 在用户名前门拼接 '_cur' 字符串
update users set name=CONCAT(username,'_cur') where name=username;
end;
end while; -- 结束循环
close username_cur; -- 关闭游标
end;
3.4 、函数
3.4.1 函数的定义
函数与存储过程最大的区别是函数必须有返回值,否则会报错
3.4.2 函数的操作
示例1 :
create function getusername(userid int) returns varchar(32)
reads sql data -- 从数据库中读取数据,但不修改数据
begin
declare username varchar(32) default '';
select name into username from users where id=userid;
return username;
end;
概括:
1.创建函数使用create function 函数名(参数) returns 返回类型;
2.函数体放在begin和end之间;
3.returns指定函数的返回值;
4.函数调用使用select getusername()。
示例2:
需求:根据userid,获取accoutid,id,name组合成UUID作为用户的唯一标识
create function getuuid(userid int) returns varchar(64)
reads sql data -- 从数据库中读取数据,但不修改数据
begin
declare uuid varchar(64) default '';
select concat(accontid,'_',id,'_',name) into uuid from users where id=userid;
return uuid;
end;
3.5、触发器
3.5.1 触发器概念
在触发器中有一个触发事件,触发器是通过这个“触发事件”来执行的(而存储过程的调用或执行是由用户或应用程序进行的)。能够引起触发器运行的操作被称为“触发事件”,如执行DML语句(使用INSERT、UPDATE、DELETE语句对表或视图执行数据处理操作);执行DDL语句(CREATE、ALTER、DROP语句在数据库中创建、修改、删除模式对象);引发数据库系统事件(如系统启动或退出、产生异常错误等);引发用户事件(如登录或退出数据库操作)
3.5.2 触发器关键字
trigger:表示创建触发器的关键字,就如同创建存储过程的关键字“produce”一样
before | after | instead of:表示“触发时机”的关键字。before表示在执行DML等操作之前触发,这种方式能够防止某些错误操作发生而便于回滚或是实现某些业务规则;after表示在DML等操作发生之后发生,这种方式便于记录该操作或做某些事后处理信息;instead of表示触发器为替代触发器。
on:表示操作的数据表、视图、用户模式和数据库等,对它们执行某种数据操作(比如对表执行INSERT、ALTER、DROP等操作),将引起触发器的运行。
for each row:指定触发器为行级触发器,当DML语句对每一行数据进行操作时都会引起该触发器的运行。如果未指定该条件,则表示创建语句级触发器,这时无论数据操作影响多少行,触发器都只会执行一次。
3.5.3 触发器参数
tri_name:触发器的名称,如果数据库中已经存在了此名称,则可以指定“or replace”关键字,这样新的触发器将覆盖掉原来的触发器。
tri_event:触发事件,比如常用的INSERT、UPDATE、DELETE、CREATE、ALTER、DROP等。
table_name | view_name | user_name |db_name:分别表示操作的数据表、视图、用户模式和数据库,对它们的某些操作将引起触发器的运行。
tri_condition:表示触发器条件表达式,只有当该表达式的值为true时,遇到触发事件才会自动执行触发器,使其执行触发操作,否则即便是遇到触发事件也不会执行触发器。
plsql_sentences:PL/SQL语句,它是触发器功能实现的主体
3.5.4 触发器的分类
行级触发器:当DML语句对每一行数据进行操作时都会引起该触发器的运行。
语句级触发器:无论DML语句影响多少行数据,其所引起的触发器仅执行一次。
替换触发器:该触发器是定义在视图上的,而不是定义在表上,它是用来替换所使用实际语句的触发器。
用户事件触发器:是指与DDL操作或用户登录、退出数据库等事件相关的触发器。如,用户登录到数据库或使用ALTER语句修改表结构等。
系统事件触发器:是指在mysql数据库系统的事件中进行触发的触发器
3.5.5触发器案例
示例1
(1)、需求:出于审计目的,当有人往表users插入一条记录时,把插入的userid,username,插入动作和操作时间记录下来。
create trigger tr_users_insert after insert on users
for each row
begin
insert into oplog(userid,username,action,optime)
values(NEW.id,NEW.name,'insert',now());
end;
创建成功后,给uses表中插入一条记录:
insert into users(id,name,age,status,score,accontid) values(6,'小周',23,1,'60','10001');
总结
1、创建触发器使用create trigger 触发器名
2、什么时候触发?after insert on users,除了after还有before,是在对表操作之前(before)或者之后(after)触发动作的。
3、对什么操作事件触发? after insert on users,操作事件包括insert,update,delete等修改操作;
4、对什么表触发? after insert on users
5、影响的范围?for each row
示例2
需求:出于审计目的,当删除users表时,记录删除前该记录的主要字段值
create trigger tr_users_delete before delete on users
for each row
begin
insert into oplog(userid,username,action,optime)
values(OLD.id,OLD.name,'delete',now());
end;
删除users表中的一条记录
delete from users where id=6;
执行成功后,打开oplog表,可以看到oplog表中插入了一条记录
3.6 、其他
3.6.1 、case分支
(1)、基本语法结构
case ...
when ... then....
when.... then....
else ...
end case;
(2)、示例
users表中,根据userid获取status值,如果status为1,则修改score为10;如果status为2,则修改为20,如果status3,则修改为30;否则修改为40。
create procedure testcate(userid int)
begin
declare my_status int default 0;
select status into my_status from users where id=userid;
case my_status
when 1 then update users set score=10 where id=userid;
when 2 then update users set score=20 where id=userid;
when 3 then update users set score=30 where id=userid;
else update users set score=40 where id=userid;
end case;
end;
调用过程 call testcate(1);
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/117994.html

