
大家回想一下自己第一次接触Gradle是什么时候? 相信大家也都是和我一样,在我们打开第一个AS项目的时候, 发现有很多带gradle字样的文件:setting.gradle, build.gradle,gradle.warpper,以及在gradle文件中各种配置, 这些都是啥wy啊。。
特别对于一些小公司开发人员,因为接触架构层面的机会很少,可能在使用AS几年后都不一定对Gradle有太多深入了解,这是实话,因为笔者就是这么过来的。。
而Gradle又是进阶高级开发的必经之路。
好了,接下来进入正题,此系列笔者会由浅入深的方式,带领大家来了解下,Gradle背后究竟有哪些奥秘。
Gradle定义:
很多开发喜欢把Gradle简单定义为一种构建工具,和ant,maven等作用类似, 诚然Gradle确实是用来做构建,但是如果简单得把Gradle拿来做构建,就太小看Gradle了.
笔者更愿意将Gradle看做一种编程框架。在这个框架中,你可以做很多ant,maven等常用构建工具做不了的事情, 如将自己的任务task集成到构建生命周期中,完成文件拷贝,脚本编写等操作。
Gradle优缺点:
相较早期的构建工具:ant,maven等。
优点如下:
-
1.使用DSL Grovvy语言来编写::了解ant的同学应该都知道:ant使用的是xml配置的模式,而Gradle使用的是
表达性的Groovy来编写, Groovy同时支持面向对象和面向过程进行开发,这个特性让Groovy可以写出一些脚本的任务,这在传统ant,maven上是不可能实现的 -
2.基于java虚拟机::
Groovy是基于jvm的语言,groovy文件编译后其实就是class文件,和我们的java一样。
所以在gradle构建过程中,我们完全可以使用java/kotlin去编写我们的构建任务以及脚本,极大的降低我们学习的成本。
-
3.Gradle自定义task:可以构建自己的任务,然后挂接到gradle构建
生命周期中去,这在ant,maven上也是不可能实现的, -
4.扩展性好:gradle将关键配置扔给我们开发者,开发者配置好任务后,无需关心gradle是如何构建的。
缺点:
用过gradle都知道,低版本gradle的项目在高版本的gradle中经常出现很多莫名其妙的错误,
向后兼容性较差。
介绍了那么多,下面正式来讲解今天的主角:Groovy
Groovy语法详解
因为我们的Groovy和java很类似,所以这里我们以和java的差异性进行展开,这样可以更好的去理解groovy语法
1.编程方式
java:面向对象
groovy:面向对象和过程
groovy不仅可以和java一样面向对象进程编程,也可以创建面向过程的脚本开发:
package variable
int i1 = 1
double d1 = 1
println(i1.class)
println(d1.class)
2.语法简洁
-
2.1:
分号:groovy默认行尾不加分号 -
2.2:
public:默认属性为public,而我们的java是protected -
2.3:
setter/getter:groovy默认给我们类内部属性,创建setter和getter方法,外部只需要使用属性名访问即可 -
2.4:
字符串:groovy支持三种类型的字符串表达式定义-
单引号:不能使用+号代替,如果你确定这个字符串只是使用,不会更改那么你可以这么定义//单引号定义不可更改内容 def s1 = 's1' //使用转移字符://s'a'2 def s2 = 's\'a\'2' -
双引号: 在字符串内部可以使用${}引用外部元素,这个外部元素可以是任何属性或者操作方法def s6 = "2+3 is ${2+3}" -
三引号:支持自动换行
一般我们会使用前两种,最后一种很少用
-
-
2.5:使用弱声明:
def,编译过程会自动类型检测,这个属性和kotlin的val/var很像。def str = "this is groovy str"
3.方法
3.1: 方法定义
groovy中:使用def声明方法的返回值,如果没有返回值,则默认返回一个null
def echo(){
return "echo this"
}
3.2:方法参数:
groovy传入的参数可以省略参数类型,且可以设置参数默认值,有默认值调用的时候可以省略带默认值的参数
def echo(message,name = '123'){
return "echo:"+message +name
}
调用:echo("hello groovy")
3.3:方法返回值
使用return返回,如果省略return,则返回的是最后方法最后一行
def echo(){
"echo this"
}
println echo()
结果:"echo this"
3.4:方法调用流程
groovy方法调用不像我们java,其内部给我们创建了很多判断的分支,支持在运行期动态添加方法 下面是groovy方法调用流程图:
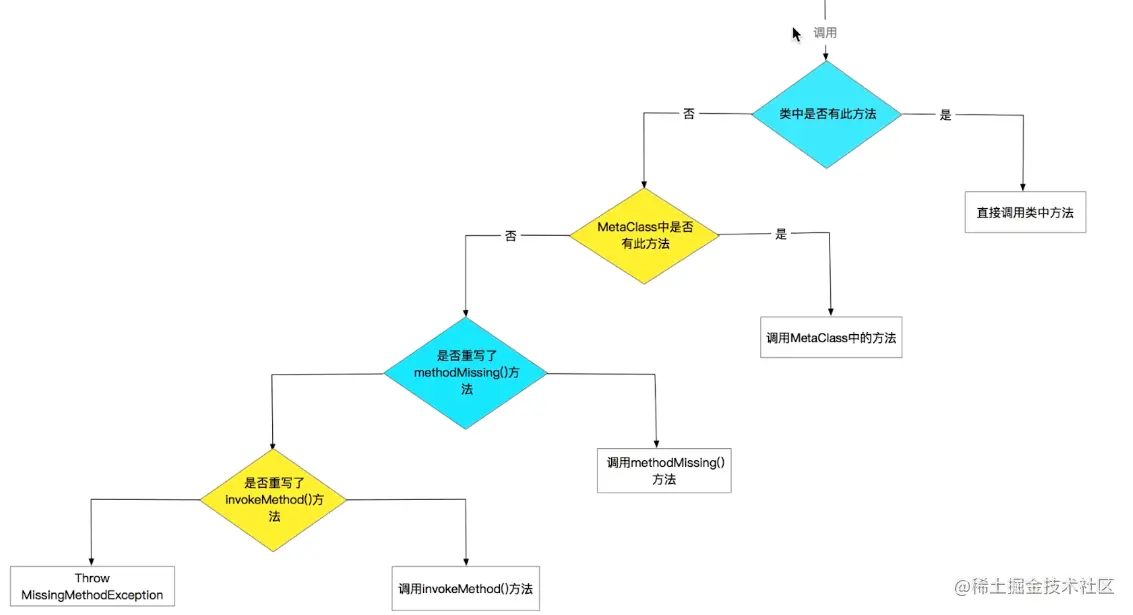
-
3.4.1:
invokeMethod:对于类中所有调用方法:包括已定义和未定义方法,都会走到这个invokeMethod方法中,需要实现:GroovyInterceptable接口这个方法可以在我们方法执行器做一些方法类型参数等判断
class Person implements GroovyInterceptable{ def name def age def score @Override Object invokeMethod(String methodName, Object args) { return "this method name is $methodName" } def helloGroovy(){ return "hello $name" } } 调用: def per = new Person(name: 'lily') println per.helloGroovy() println per.helloGroovy1() 结果: this method name is helloGroovy this method name is helloGroovy1
可以看到所有的方法都被分派到invokeMethod且没有执行后续流程:这个和我们java运行期动态代理模式有点类似,我们可以在invokeMethod中实现一些AOP的架构,如打印所有方法的统一日志等。
-
3.4.2:
methodMissing:对于未定义的方法,如果重写这个methodMissing,则会调用这个方法Object methodMissing(String name, Object args) { println "methodMissing : $name" }
最新版本groovy未发现这个方法,应该是被去掉了。不过这个对于我们开发关系不大
- 3.4.3:
元编程metaClass:可以在运行期注入属性和方法包括静态方法,这个特性就比较厉害了,对于一些第三方类库,可以使用这个方式在运行期动态创建方法,相当于对类库进行了一次扩展
学习过kotlin的都知道:扩展函数和扩展属性,差不多是这个用法
注入属性:
class Person implements{
def name
def age
}
//注入属性
Person.metaClass.sex = 'male'
def person1 = new Person(name: 'yuhb',age: 29)
println person1.sex
结果:male
注入方法:
//注入方法,使用闭包
Person.metaClass.sexUpperCase = { ->
sex.toUpperCase()
}
println person1.sexUpperCase()
结果:MALE
4.集合
4.1:集合分类
groovy中集合有三种:
列表List:对应java中的List
def list = [1, 2, 3, 4,5,6]
映射Map:对应java中的Map
def map = [key1:'value',key2:'value2']
注意:map中的key默认都是String类型的字符串,即使我们自己没加,编译器也会给我们加上
范围Range:groovy中独有
def range = [1..100]
range其实就是指定了一个list的范围,而不需要一个一个列出来
如下使用:
/******switch case*****/
println getGrade(87)
def getGrade(def number){
def result
switch (number){
case 0..<60:
result = "不及格"
break
case 60..<80:
result = "及格"
break
case 80..100:
result = "优"
break
default:
result = "不确定"
break
}
result
}
4.2:集合遍历
所有集合都可以使用each和eachWithIndex进行遍历,当然也可以使用java中的for循环,但在groovy中一般不这么用
class Stu{
def name
def age
@Override
String toString() {
return "name:$name age:$age"
}
}
def students = [
1:new Stu(name: 'lily',age: 12),
2:new Stu(name: 'lucy',age: 13),
3:new Stu(name: 'tom',age: 14),
4:new Stu(name: 'sara',age: 15)
]
/**1.遍历**/
students.each {
println it.value.toString()
}
/**带索引遍历**/
students.eachWithIndex{ Map.Entry<Integer, Stu> entry, int i ->
println "index:$i key:$entry.key value:$entry.value "
}
4.3:查找
groovy中查找提供了find和findAll方法,用法如下:
//find查找一项
def stu1 = students.find {
it.value.age>12
}
println stu1.value
//findAll查找所有项
def stus = students.findAll {
it.value.age>12
}
//count:统计个数
def stuCount = students.count {
it.value.age>12
}
//多重查找
def stu2 = students.findAll {
it.value.age>12
}.collect {
it.value.name
}
4.4:分组:
使用groupBy关键字
def group = students.groupBy {
return it.value.age>12?"大":"小"
}
4.5:排序:
使用sort
def sort = students.sort {student1,student2 ->
student1.value.age == student2.value.age?0:student1.value.age < student2.value.age?-1:1
}
5.闭包
闭包在我们groovy中起着很大比重,如果想要学好groovy,闭包一定得掌握好, 在我们build.gradle其实就有很多闭包使用: 如:
android{
sourceSets {
main{
jniLibs.srcDirs = ['libs']
}
}
}
这里面的 android {} 其实就是一个闭包结构,其内部的sourceSets{}又是闭包中的闭包,可以看到闭包在我们的gradle中无处不在.
学好闭包真的很关键
常用闭包方式:
{'abc'}
{ -> 'abc'}
{ -> "abc"+$it}
{ String name -> 'abc'}
{ name -> "abc${name}"}
{ name,age -> "abc${name}"+age}
5.1:闭包的定义及基本方法
-
闭包概念:其实就是一段代码段,你把闭包想象为java中的回调Callback即可, 闭包在Groovy中是groovy.lang.Closure的实例,可以直接赋值给其他变量. -
闭包的调用:
def closer = {1234}
closer()
closer.call()
闭包参数:带参数的闭包 使用 -> 如果是一个参数可以直接使用it代替和kotlin中的lambda类型类似
def closerParam = { name,age ->
println "hello groovy:${name}:${age}"
'return hei'
}
def result = closerParam("lily",123)
闭包返回值:闭包返回值 如果没有定义return则直接返回最后一句话的返回值
println result //打印结果:return hei
5.2:闭包使用详解
- 5.2.1:与
基本类型结合使用:
//upto:实现阶乘
int x= fab_upTo(5)
println(x)
int fab_upTo(int number){
int result = 1
1.upto(number,{result*=it})
return result
}
//downto:实现阶乘
int x1= fab_downTo(5)
println(x1)
int fab_downTo(int number){
int result = 1
number.downto(1){result*=it}
return result
}
//times:实现累加
int x2 = cal(101)
println(x2)
int cal(int number){
def result = 0;
number.times {
result+=it
}
return result
}
- 5.2.2:与
String结合使用
String str = "the 2 and 3 is 5"
//each:遍历查找,返回值是str自己
println str.each {temp ->
print temp.multiply(2)
}
//find查找一个符合条件的
println str.find {
it.isNumber()
}
//findAll查找所有符合条件的,返回的是一个集合
println str.findAll {
it.isNumber()
}
//any表示查找只要存在一个符合的就是true
println str.any { s ->
s.isNumber()
}
//every表示全部元素都要符合的就是true
println str.every {
it.isNumber()
}
//将所有字符进行转化后,放到一个List中返回
def list = str.collect {
it.toUpperCase()
}
println(list)
-
5.2.3:与
数据结构结合使用: 这部分操作和与String结合使用类似,不再讲解 -
5.2.4:与
文件结合使用 这部分在讲解到文件操作的时候,再进行具体讲解
5.3:闭包进阶详解
- 5.3.1:闭包关键变量:
this,owner,delegate
情况1:一般情况:
def scriptCloser = {
println "scriptCloser:this:${this}"
println "scriptCloser:owner:${owner}"
println "scriptCloser:delegate:${delegate}"
}
调用:scriptCloser()
结果:
scriptCloser:this:variable.Closer@58a63629
scriptCloser:owner:variable.Closer@58a63629
scriptCloser:delegate:variable.Closer@58a63629
可以看到一般情况下:三种都是相等的:都代表当前闭包对象
情况2:我们来看下面的情况:闭包中有闭包
def nestClosure = {
def innerClosure = {
println "innerClosure:this:"+this.getClass()
println "innerClosure:owner:${owner.getClass()}"
println "innerClosure:delegate:${delegate.getClass()}"
}
innerClosure()
}
nestClosure()
结果:
innerClosure:this:class variable.Closer
innerClosure:owner:class variable.Closer$_run_closure10
innerClosure:delegate:class variable.Closer$_run_closure10
看到在闭包中调用闭包:
this还是执行外部的Closer对象,而
owner和delegate变为了Closer的内部闭包对象
情况3:最后来看一种情况:使用delegate委托
class Student{
def name
def pretty = {println "my name is ${name}"}
void showName(){
pretty.call()
}
}
class Teacher{
def name
}
Student stu1 = new Student(name: 'yuhb')
Teacher tea1 = new Teacher(name: 'lily')
//改变委托delegate
stu1.pretty.delegate = tea1
stu1.showName()
//设置委托策略
stu1.pretty.resolveStrategy = Closure.DELEGATE_FIRST
stu1.showName()
结果:
my name is yuhb
my name is lily
通过上面三种情况:
总结出:
this:指向最外部的Closer对象owner:执行当前闭包的Closer对象,特指当前,所以对闭包中的闭包,指向内部的闭包delegate:这个是闭包的代理对象,如果有单独配置这个delegate,且设置了委托策略 =DELEGATE_FIRST, 则闭包中的所有内部属性都会优先使用delegate中的对象
下面我们就来讲解闭包的委托策略
- 5.3.2:闭包
委托策略
闭包中给我提供了以下策略:
//优先使用ower中的属性
public static final int OWNER_FIRST = 0;
//优先使用delegate中的属性
public static final int DELEGATE_FIRST = 1;
//只是有owner中的属性
public static final int OWNER_ONLY = 2;
//只是有delegate中的属性
public static final int DELEGATE_ONLY = 3;
//使用this中的属性
public static final int TO_SELF = 4;
通过5.3.1中的例子,我们也可以看出Groovy默认使用的是OWNER_FIRST的委托策略
6.文件
groovy文件操作完全兼容java的文件操作,但groovy集成了自己的高阶使用方式
- 读文件:
withReader
def file = new File('../../hello_groovy.iml')
def buf1 = file.withReader {reader ->
char[] buf = new char[100]
reader.read(buf)
buf
}
println buf1
- 写文件:
withWriter
//写文件:withWriter:实现文件拷贝操作
def result = copy('../../hello_groovy1.iml','../../hello_groovy.iml')
println result
def copy(String desFilePath,String srcFilePath){
try {
File desFile = new File(desFilePath)
if(!desFile.exists()){
desFile.createNewFile()
}
File srcFile = new File(srcFilePath)
if(!srcFile.exists()){
return false
}else{
srcFile.withReader {reader ->
def lines = reader.readLines()
desFile.withWriter {writer ->
lines.each {line ->
writer.write(line+'\r\n')
}
}
return true
}
}
}catch(Exception e){
return false
}
}
- 读对象:
withObjectInputStream readObject
Groovy不仅可以写文件,还可以写入和读取对象操作
//读对象
def ob1 = readObject('../../person.bin')
println ob1
def readObject(String srcFilePath){
try {
File desFile = new File(srcFilePath)
if(!desFile.exists()){
return false
}
desFile.withObjectInputStream {
def person = it.readObject()
println person.name
}
return true
}catch(Exception e){
return false
}
}
- 写对象:
withObjectOutputStream writeObject
//写对象:
Person person = new Person(name: 'uihb',age: 32)
saveObject(person,'../../person.bin')
def saveObject(Object obj,String desFilePath){
try {
File desFile = new File(desFilePath)
if(!desFile.exists()){
desFile.createNewFile()
}
if(obj != null){
desFile.withObjectOutputStream {
it.writeObject(obj)
}
}
}catch(Exception e){
return false
}
}
7.Json
- 7.1:Object转Json字符串转
//1.Object 转JSon
def personList = [
new Person(name: 'lily',age: 12),
new Person(name: 'lucy',age: 14),
new Person(name: 'kare',age: 18)
]
def jsonPerson = JsonOutput.toJson(personList)
println JsonOutput.prettyPrint(jsonPerson)
- 7.2:Json字符串转Object
//2.JSon转Object
def jsonSlurper = new JsonSlurper()
def obj = jsonSlurper.parseText(jsonPerson)
println(obj[0].name)
从网络获取Json数据操作:
这里引入OkHttp
def getNetWork(String url){
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url(url)
.get()
.build();
Call call = client.newCall(request)
call.enqueue(new Callback() {
@Override
void onFailure(Request _request, IOException e) {
}
@Override
void onResponse(Response response) throws IOException {
def res = new String(response.body().bytes())
println res
JsonSlurper jsonSlurper1 = new JsonSlurper()
Version objetres = (Version)jsonSlurper1.parseText(res)
println objetres.ecode
}
})
sleep(10000)
}
class Version{
int ecode
String emsg
CurrentVersion data
}
class CurrentVersion{
String currentVersion
}
8.XML
java中处理xml:使用的一般是dom文档驱动处理或者sax事件驱动处理
groovy处理xml:
- 8.1:groovy中如何解析xml: 使用XmlSlurper进行解析
final String xml = '''
<response version-api="2.0">
<value>
<books id="1" classification="android">
<book available="20" id="1">
<title>疯狂Android讲义</title>
<author id="1">李刚</author>
</book>
<book available="14" id="2">
<title>第一行代码</title>
<author id="2">郭林</author>
</book>
<book available="13" id="3">
<title>Android开发艺术探索</title>
<author id="3">任玉刚</author>
</book>
<book available="5" id="4">
<title>Android源码设计模式</title>
<author id="4">何红辉</author>
</book>
</books>
<books id="2" classification="web">
<book available="10" id="1">
<title>Vue从入门到精通</title>
<author id="4">李刚</author>
</book>
</books>
</value>
</response>
'''
//开始解析:XmlSlurper
def xmlSluper = new XmlSlurper()
def response = xmlSluper.parseText(xml)
println response.value.books[0].book[0].title
println response.value.books[1].book[0].@available
//xml遍历:遍历所有的李刚的书名
def list = []
response.value.books.each { books->
books.book.each { book ->
if(book.author == '李刚'){
list.add(book.title)
}
}
}
println list.toListString()
打印结果:
[疯狂Android讲义, Vue从入门到精通]
这里我们找到所有的李刚的书名
- 8.2:
xml节点遍历
深度遍历:遍历所有的李刚的书名
def depFirst = response.depthFirst().findAll { book ->
return book.author.text() == '李刚' ? true : false
}.collect { book ->
book.title
}
println depFirst.toListString()
打印结果:[疯狂Android讲义, Vue从入门到精通]
广度遍历
def name1 = response.value.books.children().findAll { node ->
node.name() =='book' && node.@id == '2'‘
}.collect { node ->
node.title
}
println name1
打印结果:[第一行代码]
- 8.3:
groovy中如何创建一个xml:使用MarkupBuilder
需求:生成xml格式数据
/**
* 生成xml格式数据
* <langs type='current' count='3' mainstream='true'>
<language flavor='static' version='1.5'>Java</language>
<language flavor='dynamic' version='1.6.0'>Groovy</language>
<language flavor='dynamic' version='1.9'>JavaScript</language>
</langs>
*/
//根据类动态生成xml文件
StringWriter sw = new StringWriter()
MarkupBuilder mb = new MarkupBuilder(sw)
Langs langs = new Langs(
type: 'current',count:3,mainstream:true,
languages: [
new Language(flavor: 'static',version:'1.5',value: 'Java'),
new Language(flavor: 'dynamic',version:'1.6.0',value: 'Groovy'),
new Language(flavor: 'dynamic',version:'1.9',value: 'JavaScript')
]
)
mb.langs(type: langs.type,count:langs.count,mainstream:langs.mainstream){
langs.languages.each { _lang ->
language(flavor:_lang.flavor,version:_lang.version,_lang.value)
}
}
println sw.toString()
saveFile(sw.toString(),'../../release.xml')
def saveFile(String source,String desFilePath){
try {
File desFile = new File(desFilePath)
if(!desFile.exists()){
desFile.createNewFile()
}
desFile.withWriter {
it.write(source)
}
return true
}catch(Exception e){
return false
}
}
class Langs {
String type
int count
boolean mainstream
def languages = []
}
class Language {
String flavor
String version
String value
}
查看文件release.xml
<langs type='current' count='3' mainstream='true'>
<language flavor='static' version='1.5'>Java</language>
<language flavor='dynamic' version='1.6.0'>Groovy</language>
<language flavor='dynamic' version='1.9'>JavaScript</language>
</langs>
9.Groovy实战:
下面我用一个Groovy实战项目来总结前面所讲的内容: 项目需求:从网络上获取当前版本信息,然后使用groovy脚本将获取到的版本信息写入到本地文件中
-
1.
groovy环境搭建下载最新版本的Intellij IDEA:笔者使用的版本:20220103版本 -
2.
创建groovy工程:
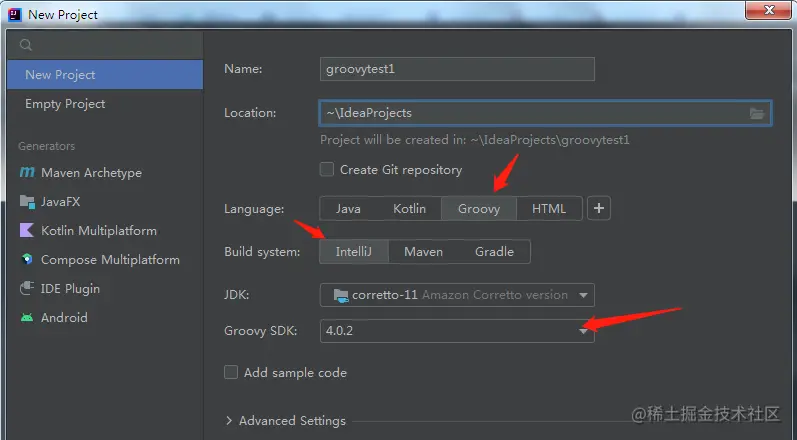
- 3.
添加OkHttp网络请求库
这里我们为了方便,使用了我们android中常用的网络请求库OkHttp

- 4.
完整代码如下:
package var
import groovy.json.JsonOutput
import groovy.json.JsonSlurper
import groovy.xml.MarkupBuilder
import okhttp3.OkHttpClient
import okhttp3.Request
/**
* 生成xml格式数据
* <langs type='current' count='3' mainstream='true'>
<language flavor='static' version='1.5'>Java</language>
<language flavor='dynamic' version='1.6.0'>Groovy</language>
<language flavor='dynamic' version='1.9'>JavaScript</language>
</langs>
*/
//本地PC:url地址
def url = 'http://127.0.0.1/api/v3/apiTest/getTestJson'
OkHttpClient client = new OkHttpClient()
Request request = new Request.Builder()
.url(url)
.get()
.build()
//1.获取response
def res = client.newCall(request).execute()
def resStr = new String(res.body().bytes())
//2.使用JsonSlurper将jsonstr转换为Object类对象
JsonSlurper js = new JsonSlurper()
Langs langs = js.parseText(resStr)
//Langs langs = js.parseText(resJson)
//3.将Object转换为xml格式字符串:MarkupBuilder
StringWriter sw = new StringWriter()
MarkupBuilder mb = new MarkupBuilder(sw)
mb.langs(type: langs.type,count:langs.count,mainstream:langs.mainstream){
langs.languages.each { _lang ->
language(flavor:_lang.flavor,version:_lang.version,_lang.value)
}
}
//4.将xml数据写入文件
saveFile(sw.toString(),'../../release.xml')
/**
* 写入文件操作
* */
def saveFile(String source,String desFilePath){
try {
File desFile = new File(desFilePath)
if(!desFile.exists()){
desFile.createNewFile()
}
desFile.withWriter {
it.write(source)
}
return true
}catch(Exception e){
return false
}
}
//json实体对象
class Langs {
String type
int count
boolean mainstream
def languages = []
}
class Language {
String flavor
String version
String value
}
这里结合我们前面讲解的关于文件操作,xml和json等数据格式操作,从网络上读取json数据,写入xml格式到我们本地项目的路径,大家可以根据我们前面所讲自己去实现一个类似的逻辑,多动手,相信你对groovy会有更深的理解。
总结:
本篇主要讲解了我们使用groovy语言的基本用法,因为也是基于jvm的语言,对于有java基础的同学学起来应该会很轻松 后面会继续讲解其他关于Gradle的关键知识,敬请期待。
作者:高级攻城狮
链接:https://juejin.cn/post/7129336080112812039
来源:稀土掘金
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/118838.html

