
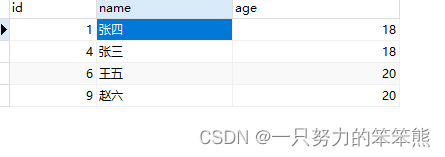
数据准备
/*创建stu数据表*/
CREATE TABLE `stu` (
`id` int(10) NOT NULL,
`name` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
/*插入demo数据*/
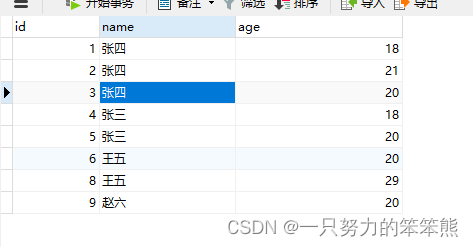
INSERT into stu(id,name,age)
VALUES
(1,'张四',18),
(2,'张四',21),
(3,'张四',20),
(4,'张三',18),
(5,'张三',20),
(6,'王五',20),
(7,'王五',20),
(8,'王五',29),
(9,'赵六',20),
(10,'张四',20);
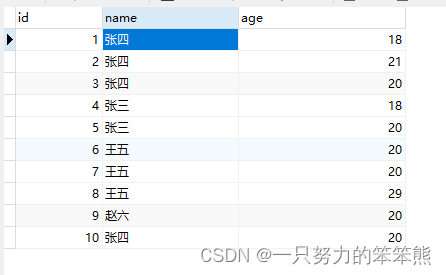
单字段重复
场景:名字重复的数据,只保留一条记录
- 查询重复行
SELECT name,COUNT(name)
FROM stu
GROUP BY name
HAVING COUNT(name) > 1;
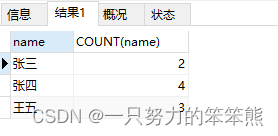
2. 查询name重复行,id最小值
SELECT
name,min(id)
FROM
stu
WHERE
NAME IN (
SELECT
NAME
FROM
stu
GROUP BY
NAME
HAVING
COUNT(name) > 1
)
GROUP BY name
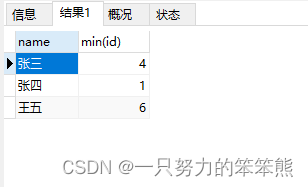
3. 删除重复行(重复记录只保留id最小值)
DELETE
FROM
stu
WHERE
id NOT IN
(SELECT
tmp.mid
FROM
(
SELECT
MIN(id) mid
FROM
stu
GROUP BY
NAME
) tmp
)
执行后数据表记录:
多字段重复
场景:名字和年龄都重复的数据,只保留一条记录
- 查询重复行
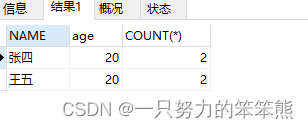
SELECT NAME,age,COUNT(*)
FROM stu
GROUP BY NAME,age
HAVING COUNT(*) > 1
SELECT
*
FROM
stu
WHERE
(name, age) IN (
SELECT
NAME,
age
FROM
stu
GROUP BY
NAME,
age
HAVING
COUNT(*) > 1
)
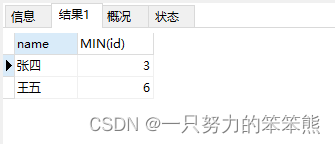
2. 查询name重复行,id最小值
SELECT
name,MIN(id)
FROM
stu
WHERE
(name, age) IN (
SELECT
NAME,
age
FROM
stu
GROUP BY
NAME,
age
HAVING
COUNT(*) > 1
)
GROUP BY name,age
3. 删除重复行(重复记录只保留id最小值)
DELETE
FROM
stu
WHERE
id NOT IN (
SELECT
temp.mid
FROM
(
SELECT
MIN(id) mid
FROM
stu
GROUP BY
NAME,
age
) temp
)
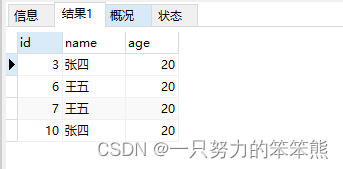
执行后数据表记录:
使用DELETE JOIN语句删除重复的行
- 保存id最小值记录
DELETE
stu1
from stu stu1 INNER JOIN stu stu2
where stu1.id > stu2.id
AND stu1.name = stu2.name
执行后数据表结果:
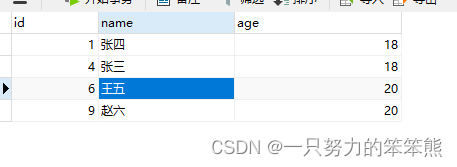
- 保存id最大值记录
DELETE
stu1
from stu stu1 INNER JOIN stu stu2
where stu1.id < stu2.id
AND stu1.name = stu2.name
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/119770.html

