
文章目录
Shell字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号
str='this is a string'
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号
your_name="runoob"
str="Hello, I know you are \"$your_name\"! \n"
echo -e $str
输出结果:
Hello, I know you are "runoob"!
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
拼接字符串
your_name="runoob"
# 使用双引号拼接
greeting="hello, "$your_name" !"
greeting_1="hello, ${your_name} !"
echo $greeting $greeting_1
# 使用单引号拼接
greeting_2='hello, '$your_name' !'
greeting_3='hello, ${your_name} !'
echo $greeting_2 $greeting_3
输出结果:
hello, runoob ! hello, runoob !
hello, runoob ! hello, ${your_name} !
有的同学可能会对greeting_2有所疑问,它用的不是单引号吗,为什么可以使用变量?
因为它外部的一对单引号和内部的一对单引号形成了双引号,所以也可以使用变量
获取字符串长度
string="nefu"
echo ${#string} # 输出 4
变量为数组时,${#string} 等价于 ${#string[0]}:
string="nefu"
echo ${#string[0]} # 输出 4
提取子字符串
我们将NEFU is a good university中的NEFU提取出来:
string="NEFU is a good university"
echo ${string:0:4}
# 输出 unoo
string:0:4:代表从字符串的第0索引往后截取四位
查找子字符串
我们在NEFU is a good university中查找g和u的位置(哪个字母先出现就计算哪个):
string="NEFU is a good university"
echo `expr index "${string}" gu` # 输出 11
注意:
- 返回的是位置不是索引
- 这里的
${string}一定要用双引号括起来
否则:
echo `expr index ${string} gu`
相当于
echo `expr index NEFU is a good university gu`
Shell数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似于 C 语言,数组元素的下标由 0 开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于 0。
定义数组
在 Shell 中,用括号来表示数组,数组元素用”空格”符号分割开。定义数组的一般形式为:
数组名=(值1 值2 ... 值n)
例如:
array_name=(value0 value1 value2 value3)
或者
array_name=(
value0
value1
value2
value3
)
还可以单独定义数组的各个分量:
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
${数组名[下标]}
例如:
valuen=${array_name[n]}
使用 @ 符号可以获取数组中的所有元素,例如:
echo ${array_name[@]}
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}
Shell注释
以 # 开头的行就是注释,会被解释器忽略。
例如:
#NEFU
如果在开发过程中,遇到大段的代码需要临时注释起来,过一会儿又取消注释,怎么办呢?
每一行加个#符号太费力了,可以把这一段要注释的代码用一对花括号括起来,定义成一个函数,没有地方调用这个函数,这块代码就不会执行,达到了和注释一样的效果。
例如:
#第一种
:<<EOF
注释内容...
注释内容...
注释内容...
EOF
#第二种
:<<'
注释内容...
注释内容...
注释内容...
'
#第三种
:<<!
注释内容...
注释内容...
注释内容...
!
流程控制
if判断
基本语法
单分支
if [ 条件判断式 ];then
程序
fi
或者
if [ 条件判断式 ]
then
程序
fi
写成一行(适用于终端命令提示符):
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi
多分支
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
else
程序
fi
末尾的 fi 就是 if 倒过来拼写,后面还会遇到类似的
注意:
- [ 条件判断式 ],中括号和条件判断式之间 必须有空格
- if后要有空格
现在我们来尝试使用一下它:
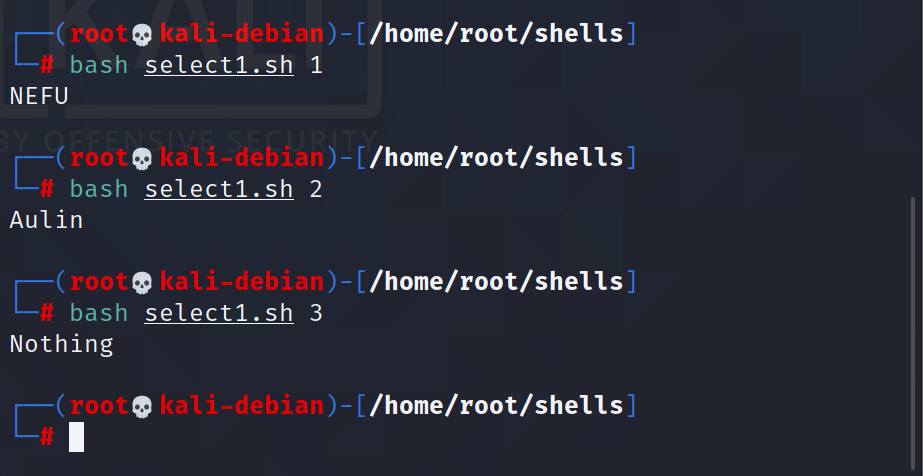
输入一个数字,如果是 1,则输出 NEFU,如果是 2,则输出 Aulin,
如果是其它,什么也不输出。
首先我们创建一个脚本:
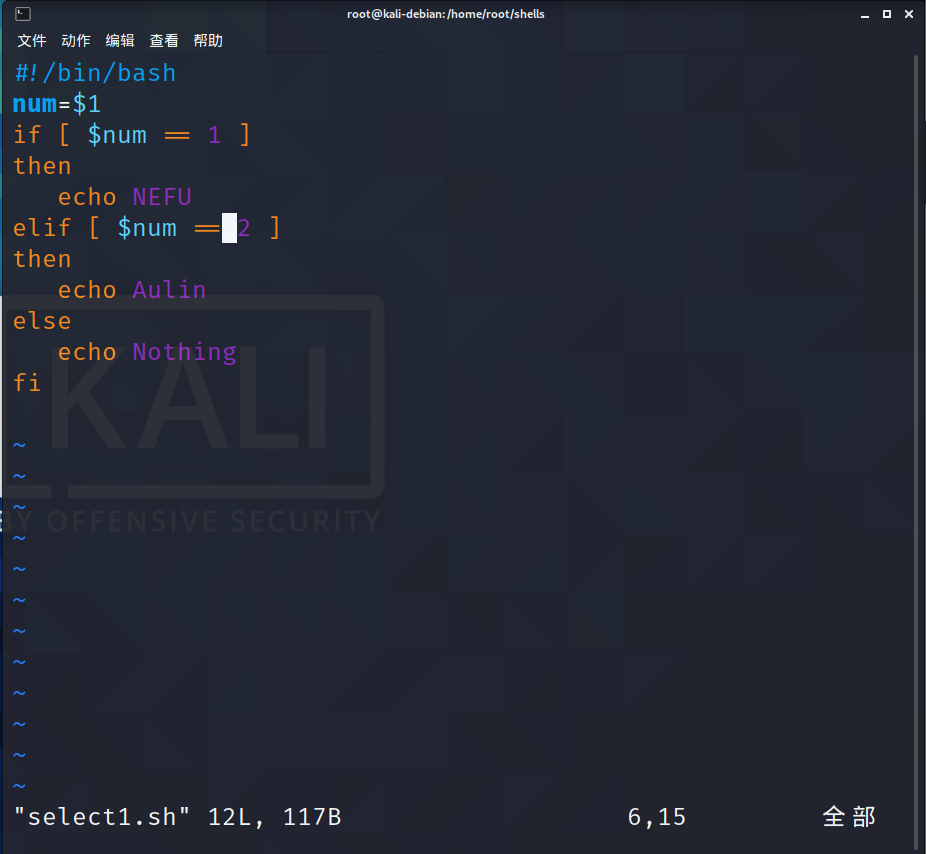
然后我们再传入数字:
注意:
if else 的 […] 判断语句中大于使用 -gt,小于使用 -lt。
if [ "$a" -gt "$b" ]; then
...
fi
如果使用 ((…)) 作为判断语句,大于和小于可以直接使用 > 和 <。
if (( a > b )); then
...
fi
注意:这里使用变量的时候不需要加
$
case语句
基本语法
case $变量名 in
"值 1")
如果变量的值等于值 1,则执行程序 1
;;
"值 2")
如果变量的值等于值 2,则执行程序 2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
注意:
- case 行尾必须为单词
in,每一个模式匹配必须以右括号)结束。 - 双分号
;;表示命令序列结束,相当于 java 中的 break - 最后的
*)表示默认模式,相当于 java 中的default
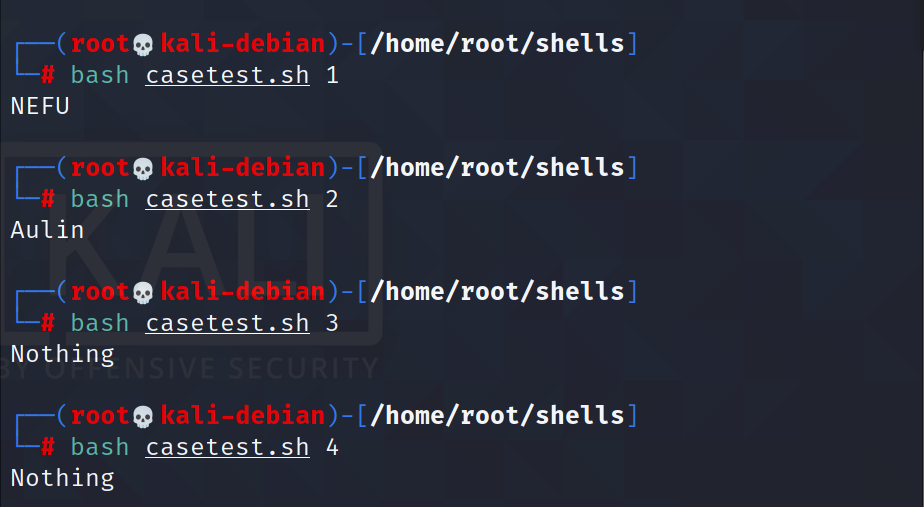
接下来我们使用这种语法完成上面if判断中的案例:
还是创建一个脚本:
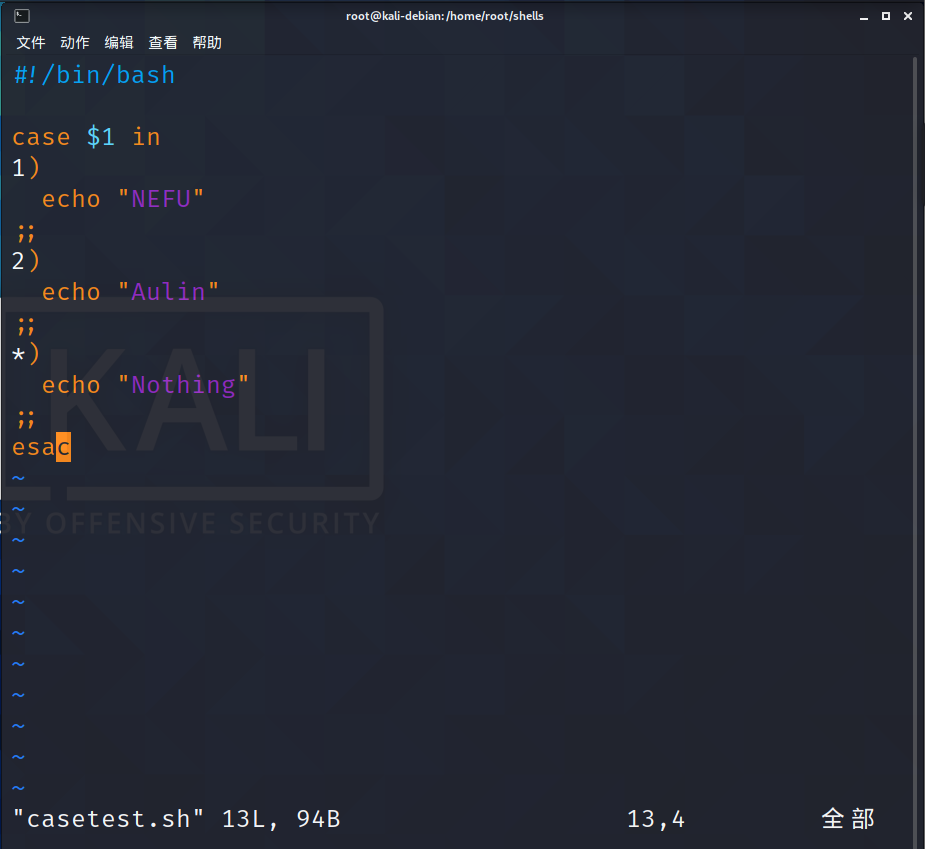
然后我们向脚本中传入不同的参数:
for 循环
基本语法1
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
我们使用这种语法完成1~100的加和:
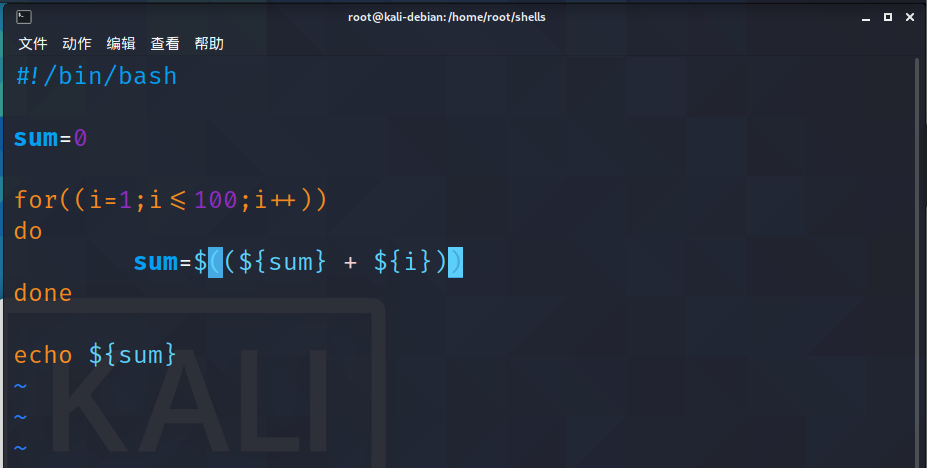
执行脚本:

基本语法2
for 变量 in 值 1 值 2 值 3…
do
程序
done
我们使用这种方式打印出a,b,c三个字母:

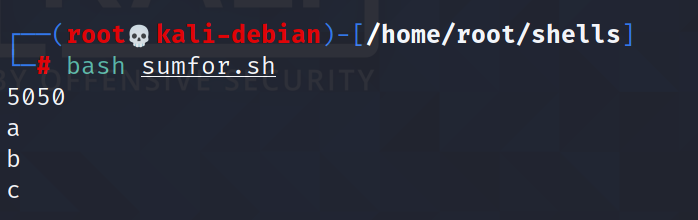
比较$*和$@区别
$*和$@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 $2 …$n的形式输出所有参数。
[root@hadoop101 shells]$ touch for3.sh
[root@hadoop101 shells]$ vim for3.sh
#!/bin/bash
echo '=============$*============='
for i in $*
do
echo "ban zhang love $i"
done
echo '=============$@============='
for j in $@
do
echo "ban zhang love $j"
done
[root@hadoop101 shells]$ chmod 777 for3.sh
[root@hadoop101 shells]$ ./for3.sh cls mly wls
=============$*=============
banzhang love cls
banzhang love mly
banzhang love wls
=============$@=============
banzhang love cls
banzhang love mly
banzhang love wls
当它们被双引号“”包含时,$*会将所有的参数作为一个整体,以“$1 $2 …$n”的形式输出所有参数;$@会将各个参数分开,以“$1” “$2”…“$n”的形式输出所有参数。
[atguigu@hadoop101 shells]$ vim for4.sh
#!/bin/bash
echo '=============$*============='
for i in "$*"
#$*中的所有参数看成是一个整体,所以这个 for 循环只会循环一次
do
echo "ban zhang love $i"
done
echo '=============$@============='
for j in "$@"
#$@中的每个参数都看成是独立的,所以“$@”中有几个参数,就会循环几次
do
echo "ban zhang love $j"
done
[atguigu@hadoop101 shells]$ chmod 777 for4.sh
[atguigu@hadoop101 shells]$ ./for4.sh cls mly wls
=============$*=============
banzhang love cls mly wls
=============$@=============
banzhang love cls
banzhang love ml
banzhang love wls
while 循环
基本语法
while [ 条件判断式 ]
do
程序
done
我们使用while循环完成1~100的加和:
与if中一样这里的
[]可以用(())代替,这样我们使用比较符的时候更加方便
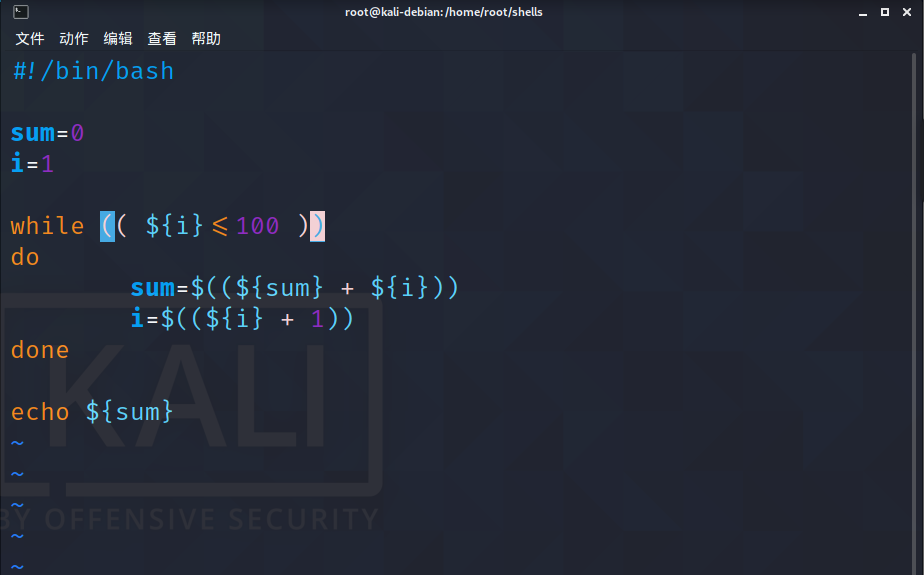
输出结果:

until循环
当判断式条件不成立时执行
until [ 条件判断 ]
do
程序段落
done
break循环控制
break语句用于从for、while、until循环中退出,停止循环的执行。
break语句的语法如下所示:
break [n]
n代表嵌套循环的层级,如果指定了n,break将退出n级嵌套循环。默认n=1如果没
有指定n或n不大于等于1,则退出状态码为0,否则退出状态码为n。
continue循环控制
continue语句用于跳过循环体中剩余的命令直接跳转到循环体的顶部,而重新开始循环的下一次重复。continue语句可以应用于for、while或until循环。continue语句的语法如下所示:
continue [n]:
把n层循环剩余的代码都去掉,但是循环的次数不变。默认n=1。
break和continue对比
#!/bin/sh
for i in a b c d
do
echo -n $i
for j in 1 2 3 4 5 6 7 8 9 10
do
if [ $j -eq 5 ];then
break或continue
fi
echo –n “ $j”
done
echo
done
break结果:
a 1 2 3 4
b 1 2 3 4
c 1 2 3 4
d 1 2 3 4
break 2的结果:
a 1 2 3 4
continue结果:
a 1 2 3 4 6 7 8 9 10
b 1 2 3 4 6 7 8 9 10
c 1 2 3 4 6 7 8 9 10
d 1 2 3 4 6 7 8 9 10
continue 2的结果:
a 1 2 3 4b 1 2 3 4c 1 2 3 4d 1 2 3 4
read 读取控制台输入
基本语法
read (选项) (参数)
选项:
- p:指定读取值时的提示符;
- t:指定读取值时等待的时间(秒)如果-t 不加表示一直等待
参数:
- 变量:指定读取值的变量名
案例实操
[root@hadoop101 shells]$ touch read.sh
[root@hadoop101 shells]$ vim read.sh
#!/bin/bash
read -t 7 -p "Enter your name in 7 seconds :" NN
echo $NN
[root@hadoop101 shells]$ ./read.sh
Enter your name in 7 seconds : NEFU
NEFU
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/122007.html

