
文章目录
Shell 可以看作是一个命令解释器,为我们提供了交互式的文本控制台界面。我们可以通过终端控制台来输入命令,由 shell 进行解释并最终交给内核执行。 本文就分类介绍常用的基本 shell 命令。
命令介绍
Linux命令:
- 用于实现某一类功能的指令或程序
- 命令的执行依赖于解释器程序(例如: /bin/bash)
Linux命令的分类:
- 内部命令:属于Shell解释器的一部分
- 外部命令:独立于Shell解释器之外的程序文件
Linux命令的通用命令格式
Linux命令的通用命令格式
命令字 [选项] [参数]
选项及参数的含义:
-
选项:用于调节命令的具体功能。以
“-”引导短格式选项(单个字
符),例如“-l”, 以“--”引导长格式选项(多个字符),例如“--color”多个短格式选项可以写在一起,只用一个“-”引导,例如“-al” -
参数:命令操作的对象,如文件、目录名等
命令的别名
别名的意义:
- 简化⽐较⻓的惯⽤命令;
- 限制导致严重后果命令的执⾏;
- ⽀持⽤户使⽤习惯。
我们可以使用alisa查看当前所有的命令别名:
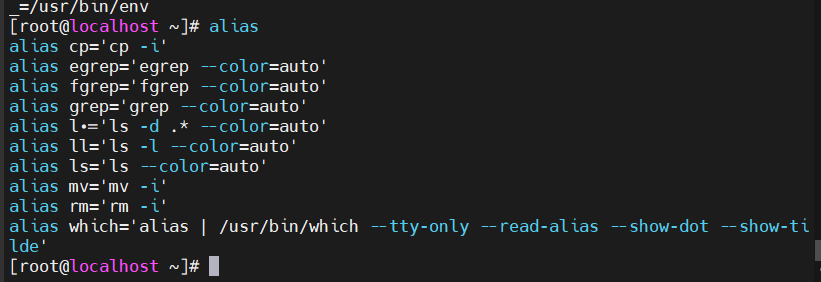
别名的使用
- 为命令添加别名:
alias 别名=‘指令 选项’
- 查看有哪些命令别名
alias
- 取消命令别名
unalias 别名
多命令间的逻辑关系
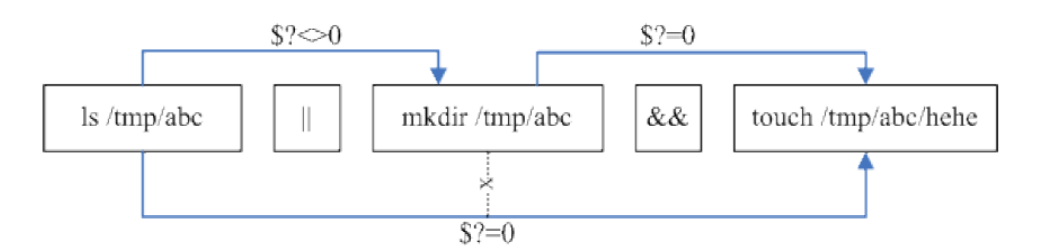
某些情况下,需要一次执行多条命令,常见:
sync;sync;shutdown -h
根据命令间的逻辑关系有以下几种形式:
- (1)cmd;cmd; 指令间不存在相关性
- (2)cmd1 && cmd2 cmd1执行正确则执行cmd2,否则不执行cmd2
- (3)cmd1 || cmd2 cmd1执行错误则执行cmd2,否则不执行cmd2
判断命令执行正确与否,依据变量$?的值,为0表示正确,否则表示不正确。

ls /tmp/abc || mkdir /tmp/abc && touch /tmp/abc/hehe
管道命令
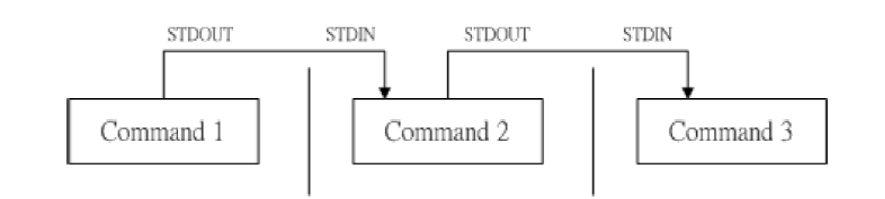
什么是管道命令?
许多Linux命令具有过滤特性,即一条命令执行后产生的结果数据可通过标准输出端口送给后一条命令执行,作为该命令的输入数据,经过连续多次处理得到结果。
Shell提供管道命令“|”将这些命令前后衔接在一起,形成一个管道线。格式
为:命令1|命令2|……|命令n
例:ls /etc的输出内容很多,可以使用 ls /etc | more,分屏显示ls /etc
的结果。
管道命令的限制:
- 管道命令仅处理标准输出,忽略标准错误输出
- 管道命令必须能够接收来自另一个指令的数据作为其标准输入继续处理才可以
常用的管道命令:more、less、cut、sort、grep、,而ls、 cp、mv等不能接收前一个指令的数据,不是管道命令
常用管道命令(截取)
cut命令
语法:
cut [选项] [file 或 标准输入]
说明:用于将同一行的数据进行切分
参数:
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域,逗号分隔
- -c :以字符为单位进行分割, 5-10

grep命令
语法:
grep [选项] 查找模式 [文件名1或标准输入]
说明:grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。
选项:
- -v:列出不匹配的行。
- -c:对匹配的行计数。
- -l:只显示包含匹配模式的文件名。
- -h:抑制包含匹配模式的文件名的显示。
- -n:每个匹配行只按照相对的行号显示。
- -i:对匹配模式不区分大小写。

常用管道命令(排序)
sort命令
语法:
sort [选项] [文件或标准输入]
说明:Linux sort命令用于将文本文件内容加以排序。针对文本文件的内容,以行为单位来排序。
常用参数:
- -b 忽略每行前面开始出的空格字符。
- -f 排序时,将小写字母视为大写字母。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
使用示例:
范例1:将/etc/passwd中的内容以:来分隔,并按照第3栏排序
cat /etc/passwd | sort –t ‘:’ –k 3
范例2:将/etc/passwd中的内容以:来分隔,并按照第3栏数字大小排序
cat /etc/passwd | sort –t ‘:’ –nk 3
uniq命令
语法:
uniq [-ic]
说明:uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort
命令结合使用。
参数:
- -i:忽略大小写字符的不同;
- -c:进行计数;
例:Last账号列出,取出账号栏,进行排序后进去出一位
last | cut –d ‘’ –f1 | sort | uniq
常用管道命令(双向重导向)
输出重定向”>”将输出重定向到文件,如果想要保存到文件的同时,输出执
行结果,可以用双向重导向。
tee命令
语法:
tee [-a] file
说明:tee指令可以前条指令的结果输出到标准输出设备,同时保存成文件。
参数:
- -a:以累加的方式,将数据加入到file中
例: ls –l / | tee –a myfile | more
常用管道命令(字符串转换)
tr命令
语法:
tr [-ds] 字符串
说明:tr命令可以读取命令输出,经过字符串转译后,将结果输出到标准输出
设备。
选项:
- -d:删除信息中的字符串
- -s:取代重复的字符
例:
last | tr ‘[a-z]’‘[A-Z]’ # 替换last输出信息中的
cat /etc/psswd | tr –d ‘:’ # 删除输出内容中的“:”
col命令
语法:
col [-xb]
说明:col命令可以用来过滤控制字符,通常用来将【tab】转成空白。
选项:
- -x:将tab键转换成对等的空格键
例:
cat –A /etc/man_db.conf # 显示所有特殊按键
cat /etc/man_db.conf | col –x | cat –A | more # 替换tab
常用管道命令(分区命令)
split
用法:
split [-bl] file PREFIX
说明:切分大文件
参数:
- -b:后面可接欲区分成的文件大小,可加单位,如b,k,m等
- -l:以行数来进行分区
- PREFIX:代表前导符的意思,可作为分区文件的前导文字
例:
/etc/service文件分成300k一个
cd /tmp; split –b 300k /etc/services services
合并:cat services* >> serviceback
ls -al /etc | split -l 10 - etc #每10条记录一个文件
xargs
用法:
xargs [-0epn] command
说明:产生某个指令的参数,读入stdin的数据,以空格字符或断行字符将文
件分割成argument。
参数:
- -0:将stdin的特殊字符还原成一般字符;
- -e:end of file,后面可以接字符串,xargs分析到这个字符串时,会停止工作。
- -p:在执行每个指令的argument时,都会询问使用者
- -n:后面接次数,每次command指令执行时,需要使用几个参数的意思
1.每次执行id,传入一个参数
cut –d ‘:’ –f 1 /etc/passwd | head –n 3 | xargs–n 1 id
2.查到sync就指令结束
cut –d ‘:’-f 1 /etc/passwd | xargs –e‘sync’–n 1 id
3.找到后,列出详细信息,ls不支持管道,可以用xargs
find /usr/sbin –perm /700 | xargs ls –l
帮助命令
man:获得帮助信息
用于查看Linux系统的手册,是Linux中使用最为广泛的帮助形式。
基本语法
man [命令或配置文件] (功能描述:获得帮助信息)
例如我们查看一下ls 命令的帮助信息:
[root@hadoop101 ~]# man ls
显示说明
若一页显示不完,可以按空格键翻页,也可按上下键滚动。按Q键退出
help:获得 shell 内置命令的帮助信息
一部分基础功能的系统命令是直接内嵌在 shell 中的,系统加载启动之后会随着 shell 一起加载,常驻系统内存中。这部分命令被称为“内置(built-in)命令”;相应的其它命令被称为“外部命令”
Linux中的帮助命令分两种:
-
一种是内建命令:是shell程序的一部分,写在bash的源码builtins里面的,通常在shell程序被加载驻留在系统内存中,解析内部命令不需要创建子进程,因此执行速度快于下面的外部命令,比如history、cd、exit。
-
一种是外部命令:是Linux实用程序的一部分,功能比较强大,不随系统一起被加载到内存中,外部命令虽然不在shell中,但其命令的调用时由shell程序控制的,外部命令是在bash之后额外安装的,通常放在/bin,/usr/bin,/sbin,/usr/sbin等等。比如:ls、vi 等。
我们可以实用type来区分是外部命令还是内建命令:
$ type exit
#显示 exit is a shell builtin
#得到这样的结果说明是内建命令,正如上文所说内建命令都是在 bash 源码中的 builtins 的.def中
$ type vim
#显示 vim is /usr/bin/vim
#得到这样的结果说明是外部命令,正如上文所说,外部命令在/usr/bin or /usr/sbin等等中
$ type ls
#显示 ls is an alias for ls --color=tty
#若是得到alias的结果,说明该指令为命令别名所设定的名称;
基本语法
help 命令(功能描述:获得 shell 内置命令的帮助信息)
例如我们查看cd命令的帮助信息:
[root@hadoop101 ~]# help cd
help命令不带任何参数的话只用于显示内建命令的帮助信息,需要进入到bash中使用(上面有讲过内建命令都在bash源码中)
注意:因此help只能显示内建命令的相关帮助信息显示查询命令的简要说明以及一些参数的使用以及说明,如果加上–help的参数就可以查看外部命令的帮助信息了
$ bash
#进入bash
$ help ls
#不会显示帮助信息
$ ls --help
#建议 ls --help|less 便于查看
#成功查询
常用快捷键
ctrl+c:停止进程ctrl+l:清屏,等同于clear,彻底清屏式resettab:提示上下键:查找执行过的命令
文件目录类命令
pwd:显示当前工作目录的绝对路径
pwd:print working directory 打印工作目录
基本语法
pwd (功能描述:显示当前工作目录的绝对路径)
例如显示当前工作目录的绝对路径
[root@hadoop101 ~]# pwd
/root
ls:列出目录的内容
ls:list 列出目录内容
基本语法
ls [选项] [目录或是文件]
选项说明

例如我们现在查看当前目录的所有内容信息:
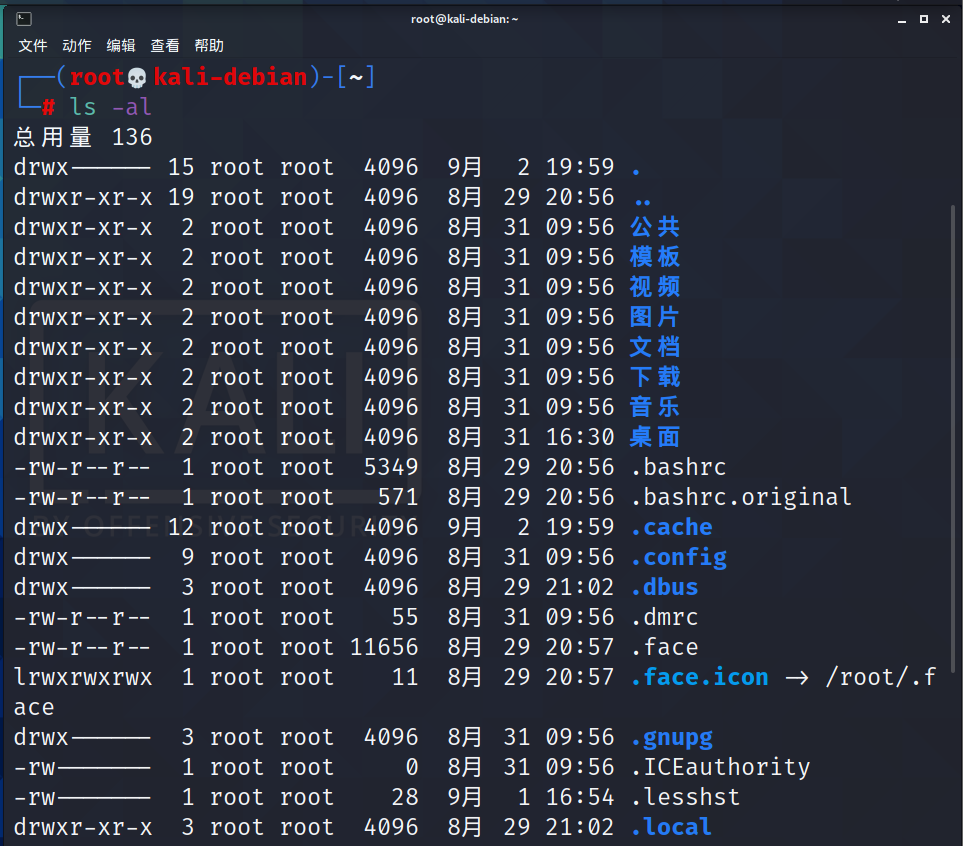
每行列出的信息依次是:
- 文件类型与权限
- 链接数
- 文件属主
- 文件属组
- 文件大小(用byte来表示)
- 建立或最近修改的时间
- 名字
拓展:
- -k 以k字节的形式表示文件的大小;
- -t 以时间排序
- -b 把文件名中不可输出的字符用反斜杠加字符编号的形式列出;
- -d 将目录像文件一样显示,而不是显示其中所包含的文件;
- -e 输出时间的全部信息﹐而不是输出简略信息
- -m 横向输出文件名,并以“,”作分格符
- -n 用数字的UID、GID代替名称在每个文件名后附上一个字符以说明该文件的类型,“*”表示可执行的普通文
- -p或-F:“/”表示目录;“@”表示符号链接;“|”表示FIFOs;“一”表示套接字
- -r 对目录反向排序
- -s 在每个文件名后输出该文件的大小
- -u 以文件上次被访问的时间排序版-x按列输出,横向排序:,
- -1 一行只输出一个文件
- –color=no不显示彩色文件名
cd:切换目录
cd:Change Directory 切换路径
基本语法
cd [参数]
参数说明:

案例实操
(1)使用绝对路径切换到 root 目录
[root@hadoop101 ~]# cd /root/
(2)使用相对路径切换到“公共的”目录
[root@hadoop101 ~]# cd 公共的/
(3)表示回到自己的家目录,亦即是 /root 这个目录
[root@hadoop101 公共的]# cd ~
(4)cd- 回到上一次所在目录
[root@hadoop101 ~]# cd -
(5)表示回到当前目录的上一级目录,亦即是 “/root/公共的”的上一级目录的意思;
[root@hadoop101 公共的]# cd ..
mkdir:创建一个新的目录
mkdir:Make directory 建立目录
基本语法
mkdir [选项] 要创建的目录
选项说明
-p:创建多层目录
接下来我们尝试使用此命令:
- 创建一个目录
- 创建一个多级目录
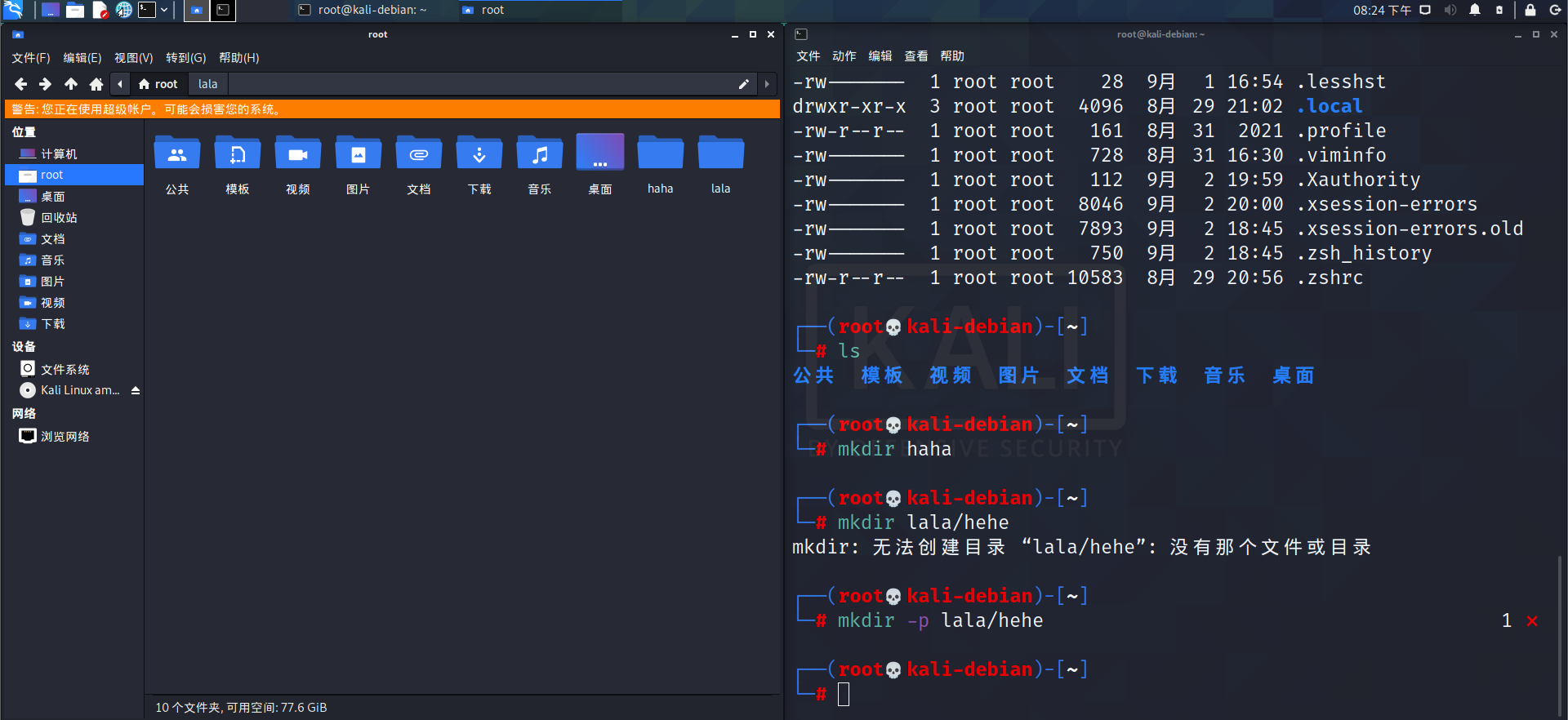
rmdir:删除一个空的目录
rmdir:Remove directory 移除目录
基本语法
rmdir 要删除的空目录
删除文件夹即使多级也可以直接删
例如我们把刚才创建的文件夹删除:

touch:创建空文件
基本语法
touch [选项] 文件名称
例如:
touch还有一个功能就是修改文件时间标签
常用参数选项如下。
- -d yyyymmdd:把文件的存取和修改时间改为yyyy年mm月dd日。
- -a:只把文件的存取时间改为当前时间。
- -m:只把文件的修改时间改为当前时间。

例如:
[root@server1 ~]# touch -d 20180808 aa //将aa文件的存取和修改时间改为2018年8月8日
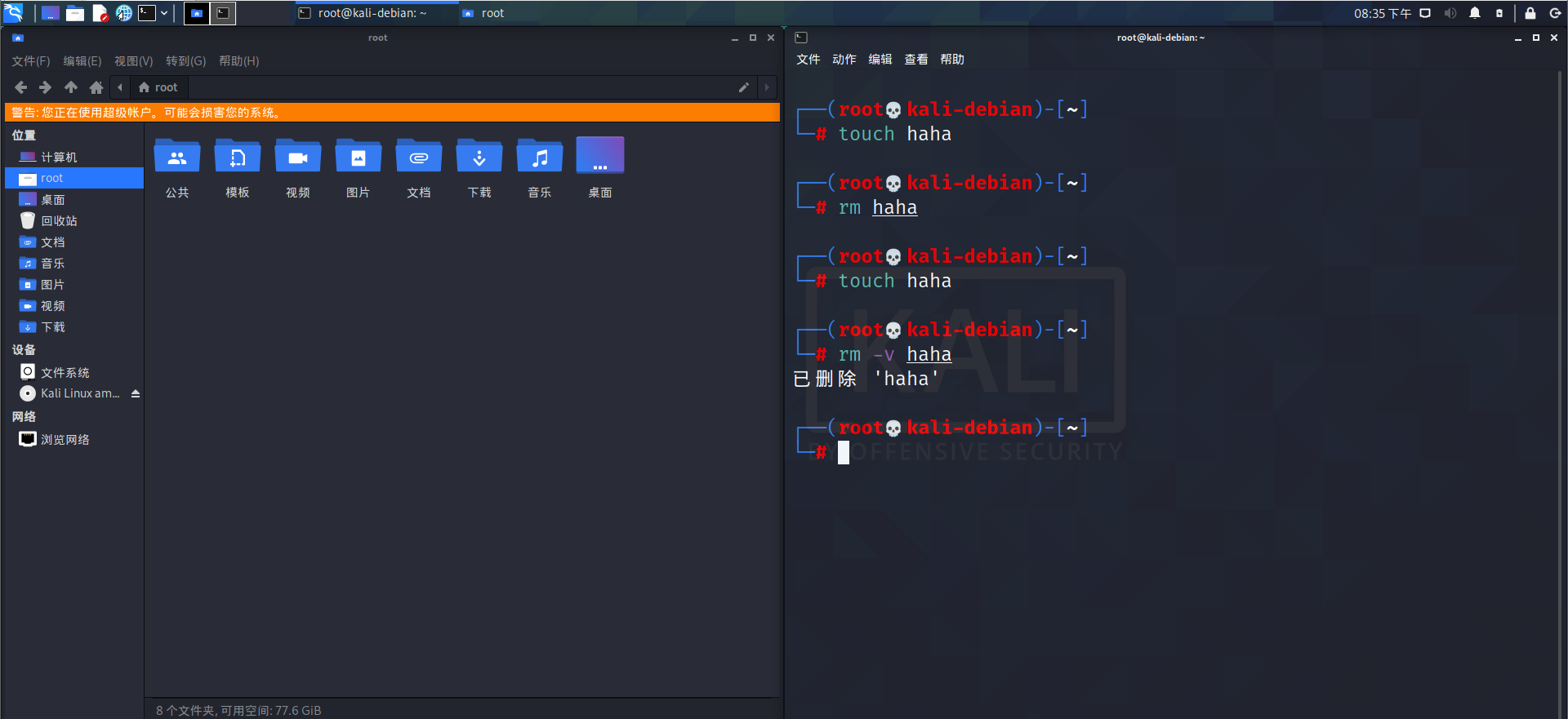
rm:删除文件或目录
基本语法
rm [选项] deleteFile (功能描述:递归删除目录中所有内容)
选项说明

- -i:删除文件或目录时提示用户。
例如:
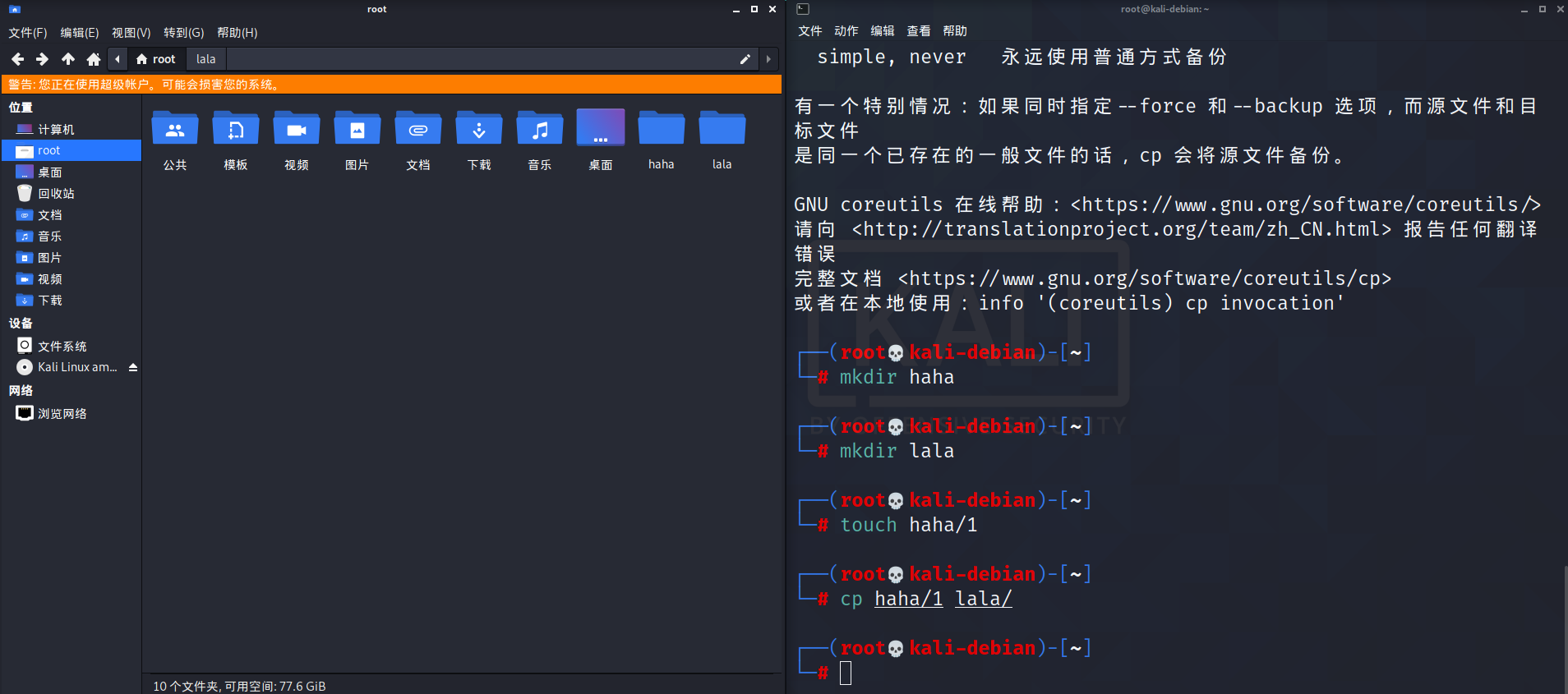
cp:复制文件或目录
基本语法
cp [选项] 源文件或目录 目标文件或目录
选项说明
-r:递归复制整个文件夹(也就是说你只复制一个文件不需要用这个)- -a:尽可能将文件状态、权限等属性照原状予以复制。
- -f:如果目标文件或目录存在,先删除它们再进行复制(即覆盖),并且不提示用户。
- -i:如果目标文件或目录存在,提示是否覆盖已有的文件。

强制覆盖不提示的方法:\cp
例如:
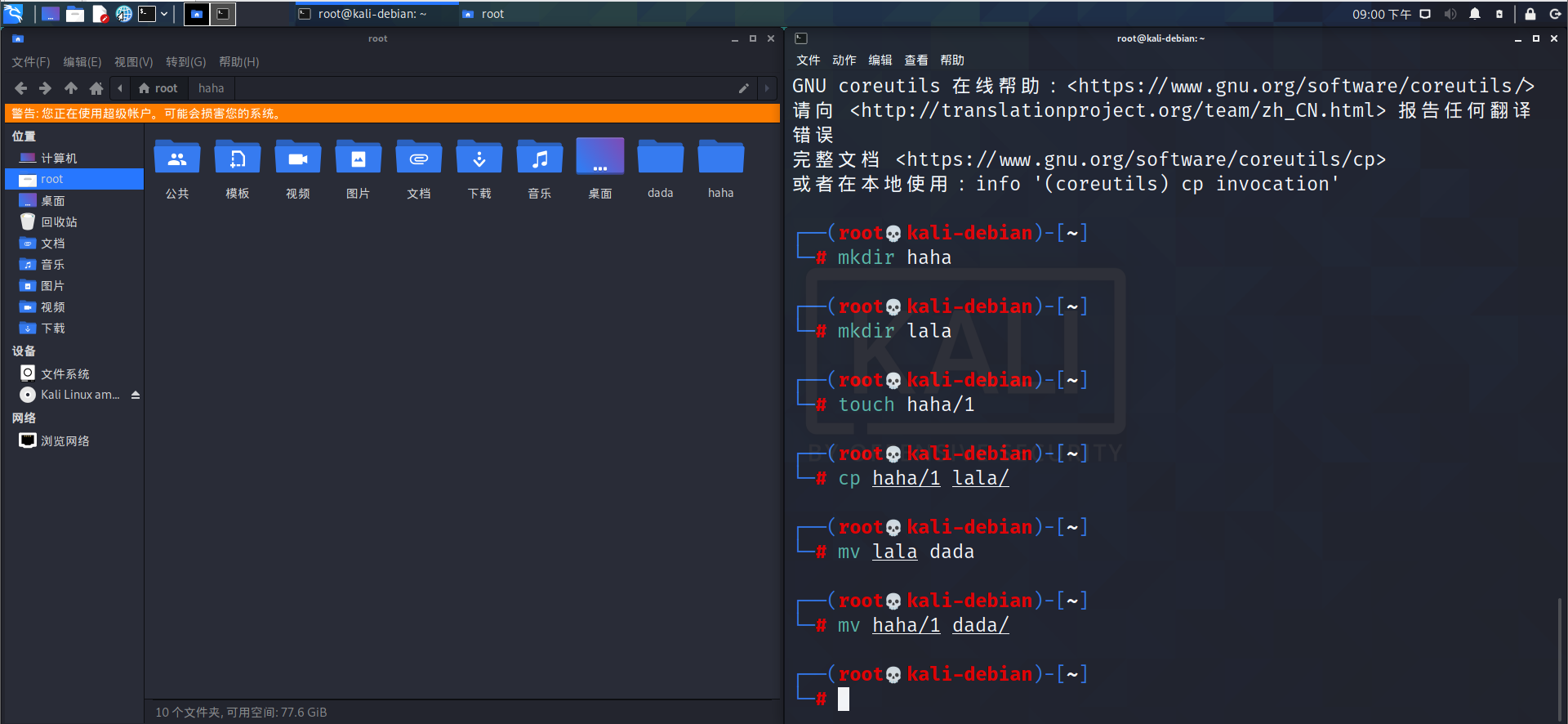
mv:移动文件与目录或重命名
基本语法
mv [选项] 源文件或目录 目标文件或目录
mv oldNameFile newNameFile (功能描述:重命名)
mv /temp/movefile /targetFolder (功能描述:移动文件)
常用选项
- -i:如果目标文件或目录存在,则提示是否覆盖目标文件或目录。
- -f:无论目标文件或目录是否存在,直接覆盖目标文件或目录,不提示。
例如:
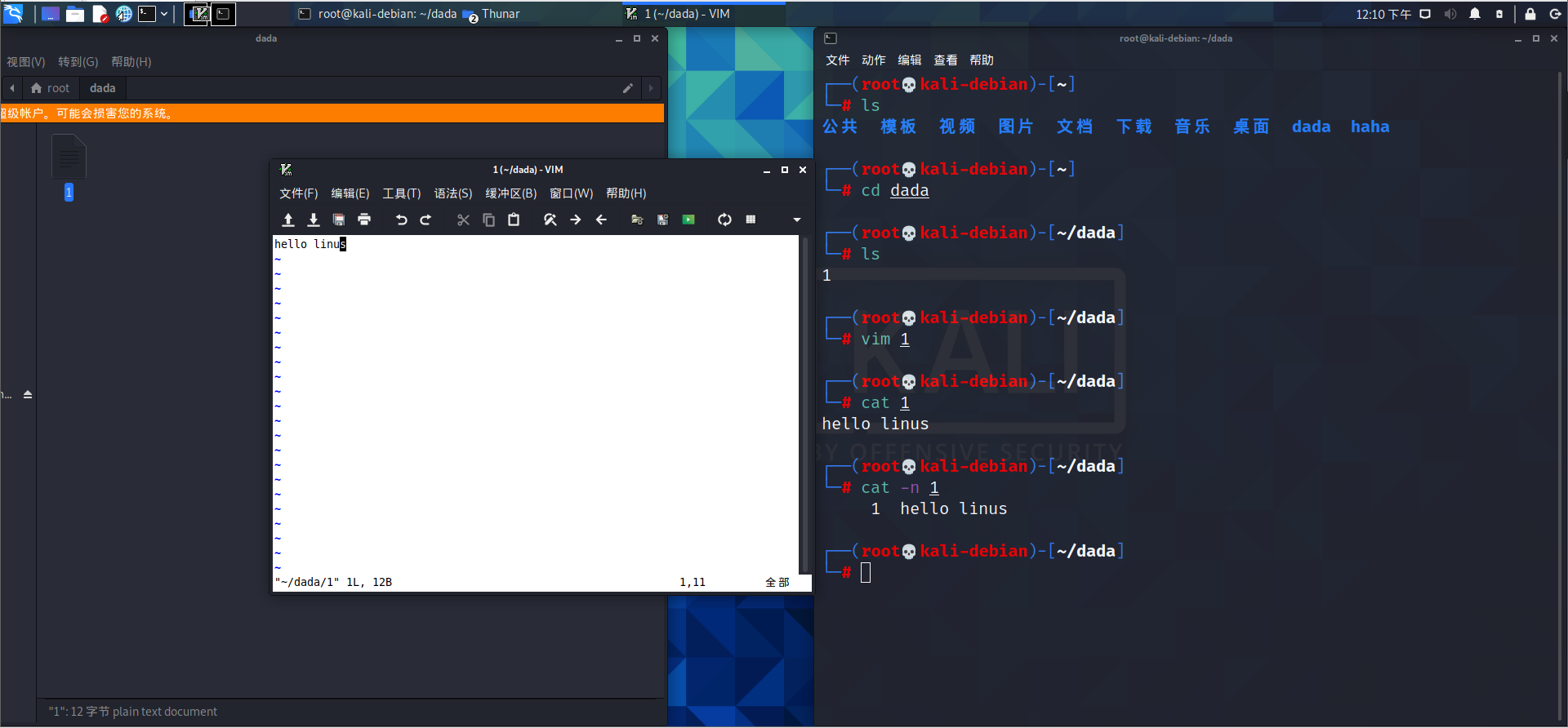
cat:查看文件内容
查看文件内容,从第一行开始显示
基本语法
cat [选项] 要查看的文件
选项说明
-n:显示所有行的行号,包括空行- -b: 和 -n 相似,只不过对于空白行不编号。
- -s:当遇到有连续两行以上的空白行,就代换为一行的空白行。
一般查看比较小的文件,一屏幕能显示全的。
例如:
利用cat命令还可以合并多个文件。如把file1和file2文件的内容合并为file3,
且file2文件的内容在file1文件的内容前面,则命令为:
[root@server1 ~]# cat file2 file1>file3
//如果file3文件存在,则此命令的执行结果会覆盖file3文件中原有内容
more:文件内容分屏查看器
more 指令是一个基于 VI 编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容。more 指令中内置了若干快捷键,详见操作说明。
基本语法
more [选项] 要查看的文件
操作说明
space:代表向下翻一页Enter:代表向下翻一行q:代表立刻离开more,不再显示该文件内容Ctrl+F:向下滚动一屏Ctrl+B:返回上一屏=:输出当前行的行号:f:输出文件名和当前行的行号
选项说明

less:分屏显示文件内容
less 指令用来分屏查看文件内容,它的功能与 more 指令类似,但是比 more 指令更加强大,支持各种显示终端。less 指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示需要加载内容,对于显示大型文件具有较高的效率。
基本语法
less [选项] 要查看的文件
操作说明
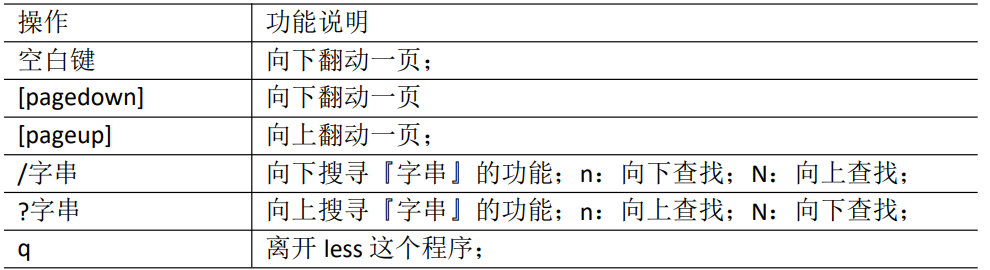
用SecureCRT时[pagedown]和[pageup]可能会出现无法识别的问题。
选项说明

echo:输出内容到控制台
基本语法
echo [选项] [输出内容]
基本选项
-e:支持反斜线控制的字符转换

例如:
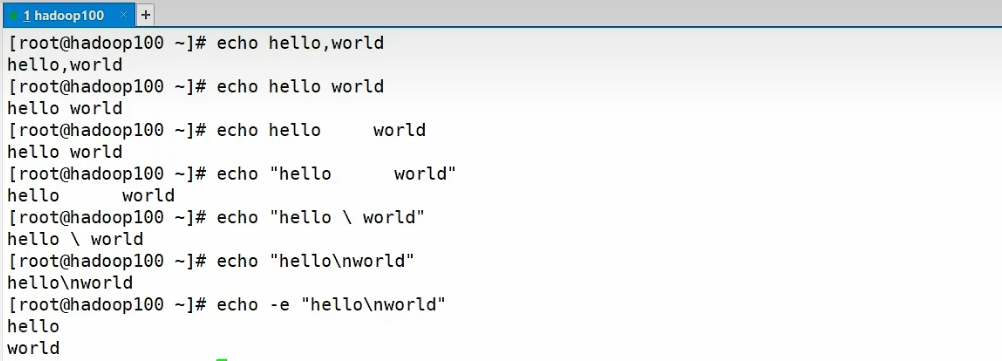
此命令一般搭配
>,>>使用
> 、>>:输出重定向和追加
所谓重定向,就是不使用系统的标准输入端口、标准输出端口或标准错误端口,而进行重新的指定。
输入重定向:重新指定设备\文件来代替键盘作为新的输入;
输出重定向:重新指定设备\文件来代替显示器作为新的输出。
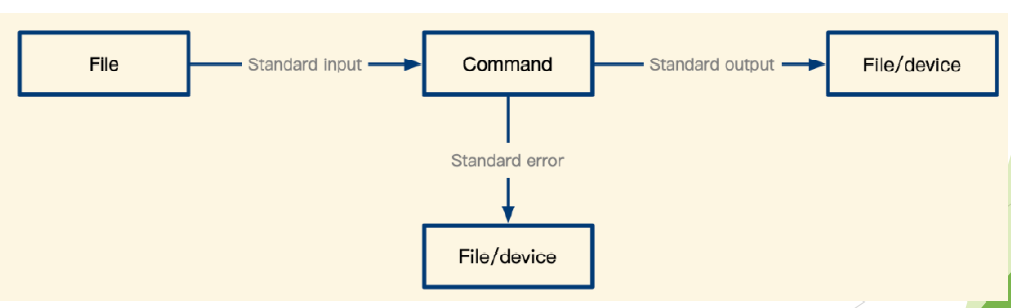
基本语法

输出重定向实现
- 标准输出(stdout):命令运⾏所返回的正确信息;代码为1,使⽤>或>>;
- 标准错误输出(stderr):命令运⾏失败后,所返回的错误信息。代码为2,使⽤2>或2>>;

shell上:
0表示标准输入
1表示标准输出
2表示标准错误输出
默认为标准输出重定向,与 1> 相同
2>&1 意思是把 标准错误输出 重定向到 标准输出.
&>file 意思是把 标准输出 和 标准错误输出 都重定向到文件file中
有人会问怎么去理解这个&?
我们不应该单独去理解,应该把他们整体的重定向符号去理解。
输入重定向实现
标准输⼊(stdin): 代码为0,使⽤<或<<;
- 命令 < 文件: 将指定文件作为命令的输入设备
- 命令 << 分界符: 表示从标准输入设备(键盘)中读入,直到遇到分界符才停止(读入的数据不包括分界符),这里的分界符其实就是自定义的字符串
- 命令 < 文件 1 > 文件 2: 将文件 1 作为命令的输入设备,该命令的执行结果输出到文件 2 中。
常用cat:cat >> new.txt < result.txt
cat >> result.txt << “eof”

输入输出重定向的用途:
- 屏幕输出的信息很重要,而且我们需要将他存下来的时候;
- 背景执行中的程序,不希望他干扰屏幕正常的输出结果时;
- 一些系统的例行命令(例如写在/etc/crontab 中的文件)的执行结果,希望他可以存下来时;
- 一些执行命令的可能已知错误讯息时,想以『2>/dev/null 」将他丢掉时;
- 错误信息与正确信息需要分别输出时。
head:显示文件头部内容
head 用于显示文件的开头部分内容,默认情况下 head 指令显示文件的前 10 行内容。
基本语法
head 文件 (功能描述:查看文件头10行内容)
head -n 5 文件 (功能描述:查看文件头5行内容,5可以是任意行数)
选项说明

- -c num:显示指定文件的前num个字符。
- -num:从倒数第num行开始显示指定文件的内容
tail:输出文件尾部内容
tail 用于输出文件中尾部的内容,默认情况下 tail 指令显示文件的后10行内容。
基本语法
(1)tail 文件 (功能描述:查看文件尾部10行内容)
(2)tail -n 5 文件 (功能描述:查看文件尾部5行内容,5可以是任意行数)
(3)tail -f 文件 (功能描述:实时追踪该文档的所有更新)
选项说明

- -c num:显示指定文件的末尾num个字符。
- +num:从第num行开始显示指定文件的内容
ln:软链接
软链接也称为符号链接,类似于 windows 里的快捷方式,有自己的数据块,主要存放了链接其他文件的路径。
基本语法
ln -s [原文件或目录] [软链接名] (功能描述:给原文件创建一个软链接)
删除软链接: rm -rf 软链接名,而不是 rm -rf 软链接名/
如果使用 rm -rf 软链接名/ 删除,会把软链接对应的真实目录下内容删掉
查询:通过 ll 就可以查看,列表属性第 1 位是 l,尾部会有位置指向
如果此时用pwd显示的是虚拟文件路径,我们可以使用
pwd -P来显示实际的物理路径
例如:
(1)创建软连接
[root@hadoop101 ~]# mv houge.txt xiyou/dssz/
[root@hadoop101 ~]# ln -s xiyou/dssz/houge.txt ./houzi
[root@hadoop101 ~]# ll
lrwxrwxrwx. 1 root root 20 6 月 17 12:56 houzi ->
xiyou/dssz/houge.txt
(2)删除软连接(注意不要写最后的/)
[root@hadoop101 ~]# rm -rf houzi
(3)进入软连接实际物理路径
[root@hadoop101 ~]# ln -s xiyou/dssz/ ./dssz
[root@hadoop101 ~]# cd -P dssz/
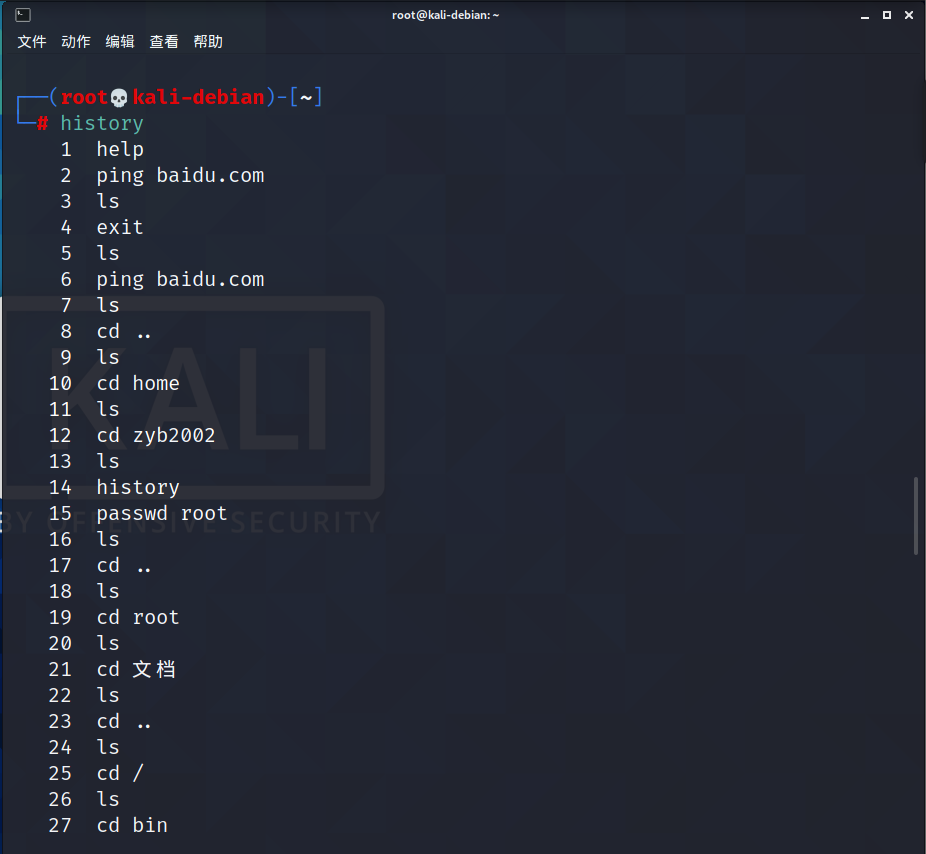
history:查看已经执行过历史命令
基本语法
history [选项] (功能描述:查看已经执行过历史命令)
参数/选项:
- -n: 数字,列出最近n条历史命令;
- -c: 将⽬前shell的所有历史命令清除;
- -a: 将⽬前新增的history命令追加到histfiles中;如果没有指定histfiles,默认写⼊~/.bash_history;
- -r: 将histfiles中的内容读到⽬前shell的histroy中;
- -w: 将⽬前history所记录的内容写⼊histfiles。
历史命令读取和记录的过程:
- 登陆,从~/.bash_history读取;
- 数量: HISTSIZE;
- 登出: 更新~/.bash_history;
- history –w 可强制写入
利用”!”重复执行历史命令:
用法:
!number:执行历史命令中的第number调指令!command:由最近指令向前搜索,找到开头为“command的指令”,并执行!!: 执行上一条指令
例如:
sort:文件内容排序
基本语法
sort [选项] 文件列表
选项说明

例1:将/etc/passwd中的内容以:来分隔,并按照第3栏排序
[liu@localhost yum.repos.d]$ cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
liu:x:1000:1000:liu:/home/liu:/bin/bash
zhangsan:x:1002:1002::/home/zhangsan:/bin/bash
例2:将/etc/passwd中的内容以:来分隔,并按照第3栏数字大小排序
[liu@localhost yum.repos.d]$ cat /etc/passwd | sort -t ":" -nk 3
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
diff:文件比较
用于比较两个文件内容的不同,主要是纯文本文件
基本语法
diff [参数] 源文件 目标文件
常用参数选项
- -a:将所有的文件当作文本文件处理。
- -b:忽略空格造成的不同。
- -B:忽略空行造成的不同。
- -q:只报告什么地方不同,不报告具体的不同信息。
- -i:忽略大小写的变化。

wc:统计指定文件的字节数、字数、行数
基本语法
wc [选项] 文件
常用选项
- -c: 统计字节数
- -l: 统计行数
- -m:统计字符数
- -w:统计字数
时间日期类命令
基本语法
date [OPTION]... [+FORMAT]
选项以及参数说明

date:显示当前时间
基本语法
(1)date (功能描述:显示当前时间)
(2)date +%Y (功能描述:显示当前年份)
(3)date +%m (功能描述:显示当前月份)
(4)date +%d (功能描述:显示当前是哪一天)
(5)date "+%Y-%m-%d %H:%M:%S" (功能描述:显示年月日时分秒)
例如:
date:显示非当前时间
基本语法
(1)date -d '1 days ago' (功能描述:显示前一天时间)
(2)date -d '-1 days ago' (功能描述:显示明天时间)
例如:
date:设置系统时间
基本语法
date -s 字符串时间
(1)设置系统当前时间
[root@hadoop101 ~]# date -s "2017-06-19 20:52:18
cal:查看日历
基本语法
cal [选项] (功能描述:不加选项,显示本月日历)
选项说明

例如:
用户管理类命令
用户账户与群组概念
Linux操作系统是多用户多任务的操作系统,允许多个用户同时登录到系统,使用系统资源。用户账户是用户的身份标识。用户通过用户账户可以登录到系统,并且访问已经被授权的资源。系统依据账户来区分属于每个用户的文件、进程、任务,并给每个用户提供特定的工作环境(例如,用户的工作目录、shell版本以及图形化的环境配置等),使每个用户都能各自不受干扰地独立工作。
Linux系统下的用户分为三种:
普通用户:在系统中只能进行普通工作,只能访问他们拥有的或者有权限执行的文件。超级用户(root):也叫管理员账户,它的任务是对普通用户和整个系统进行管理。超级用户账户对系统具有绝对的控制权,能够对系统进行一切操作系统用户:与系统服务相关,但不能用于登录
群组是具有相同特性的用户的逻辑集合,使用群组有利于系统管理员按照用户的特性组织和管理用户,提高工作效率。
有了群组,在做资源授权时可以把权限赋予某个群组,群组中的成员即可自动获得这种权限。
一个用户账户可以同时是多个群组的成员,其中某个群组是该用户的主群组
(私有群组),其他群组为该用户的附属群组(标准群组)。
用户和群组的基本概念

root用户的UID为0:系统用户的UID从1到999;普通用户的UID可以在创建时由管理员指定,如果不指定,用户的UID默认从1000开始顺序编号。在Linux系统中,创建用户账户的同时也会创建一个与用户同名的群组,该群组是用户的主群组。普通群组的GID默认也是从1000开始编号。
用户账户文件与群组文件
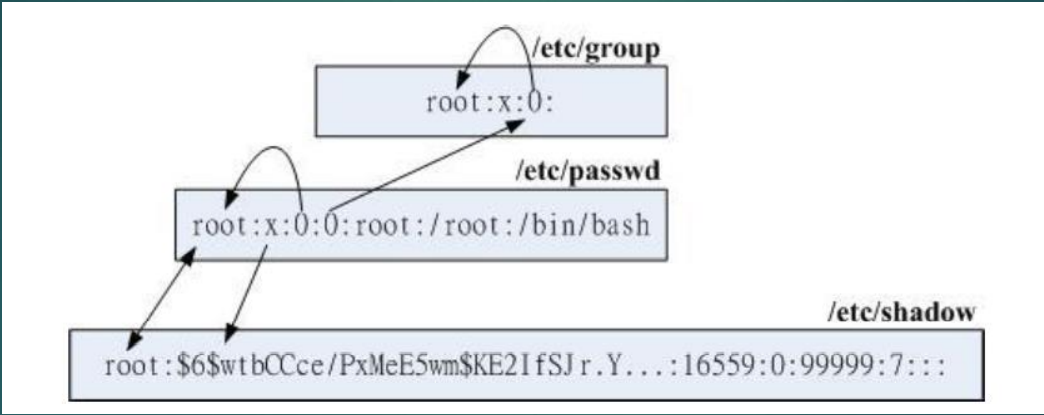
用户登录过程:
- 先找寻 /etc/passwd 里面是否有你输入的帐号?如果没有则跳出,如果有的话则将该帐号对应的 UID 与 GID (在 /etc/group 中) 读出来,另外,该帐号的家目录与 shell 设定也一并读出;
- 进入 /etc/shadow 里面找出对应的帐号与 UID,然后核对一下你刚刚输入的密码与里面的密码是否相符
- 核对成功,就进入 Shell 环境
用户账户文件:
/etc/passwd文件:在Linux系统中,所创建的用户账户及其相关信息(密码除外 ) 均放在 /etc/passwd 配 置 文 件 中 。 用 vim 编 辑 器 ( 或 者 使 用 cat/etc/passwd)打开passwd文件,内容格式如下:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
user1:x:1002:1002::/home/user1:/bin/bash
文件中的每一行代表一个用户账户的资料,可以看到第一个用户是root。然后是一些标准账户,此类账户的shell为/sbin/nologin,代表无本地登录权限。最后一行是由系统管理员创建的普通账户:user1。passwd文件的每一行用“:”分隔为7个域,各域的内容如下:
用户名:加密口令:UID:GID:用户的描述信息:主目录:命令解释器(登录shell)
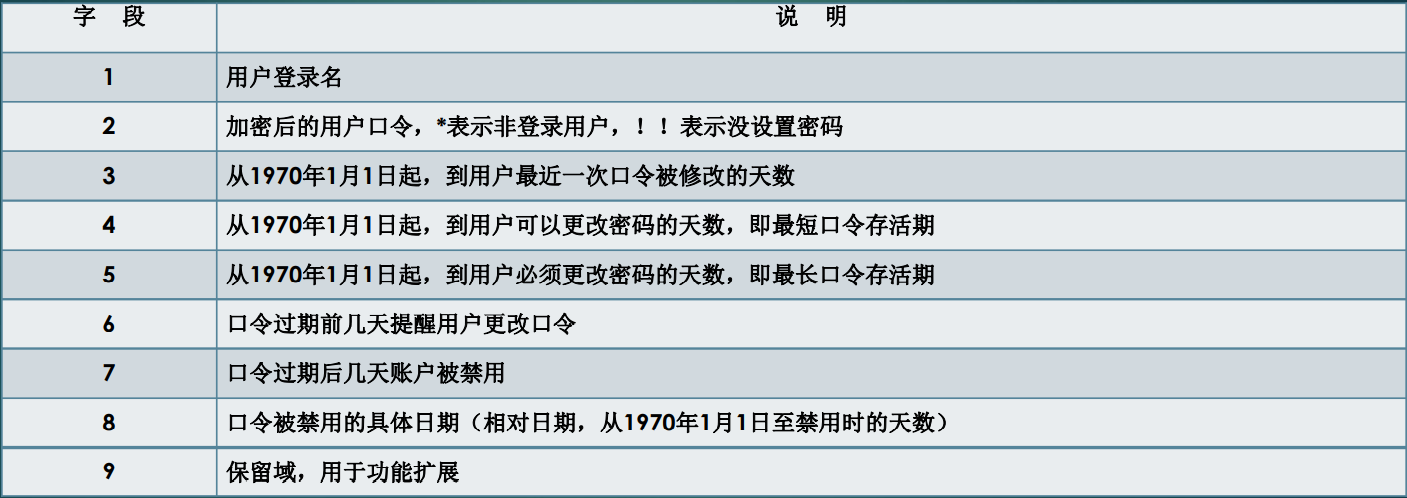
/etc/shadow文件:由于所有用户对/etc/passwd文件均有读取权限,为了增强系统的安全性,用户经过加密之后的口令都存放在/etc/shadow文件中。 /etc/shadow文件只对root用户可读,因而大大提高了系统的安全性。shadow文件的内容形式如下:
root:$6$PQxz7W3s$Ra7Akw53/n7rntDgjPNWdCG66/5RZgjhoe1zT2F00ouf2iDM.AVvRIYoez10hGG7kBHEaah.oH5U1t6OQj2Rf.:17654:0:99999:7:::
bin:*:16925:0:99999:7:::
daemon:*:16925:0:99999:7:::
bobby:!!:17656:0:99999:7:::
user1:!!:17656:0:99999:7:::
shadow文件保存投影加密之后的口令以及与口令相关的一系列信息,每个用
户的信息在shadow文件中占用一行,并且用“:”分隔为9个域,内容如下表:
群组文件:
/etc/group文件:用于存放用户的组账户信息,对于该文件的内容任何用户都可以读取。每个群组账户在group文件中占用一行,并且用“:”分隔为4个域。每一行各域的内容如下(使用cat /etc/group):
root:x:0:
bin:x:1:
daemon:x:2:
bobby:x:1001:user1,user2
user1:x:1002:
各域的内容如下:
群组名称:群组口令(一般为空,用x占位):GID:群组成员列表
root的GID为0,没有其他组成员。group文件的群组成员列表中如果有多个用户账户属于同一个群组,则各成员之间以“,”分隔。在/etc/group文件中,用户的主群组并不把该用户作为成员列出,只有用户的附属群组才会把该用户作为成员列出。例如,用户bobby的主群组是bobby,但/etc/group文件中群组bobby的成员列表中并没有用户bobby,只有用户user1和user2。
/etc/gshadow文件:用于存放群组的加密口令、组管理员等信息,该文件只有root用户可以读取。每个群组账户在gshadow文件中占用一行,并以“:”分隔为4个域。每一行中各域的内容如下:
root:::
bin:::
daemon:::
bobby:!::user1,user2
user1:!::
各域的内容如下:
群组名称:加密后的群组口令(没有就用!):群组的管理员:群组成员列表
/etc/group、/etc/shadow、/etc/passwd 文件关系:
useradd:添加新用户
基本语法
useradd [选项] <username>
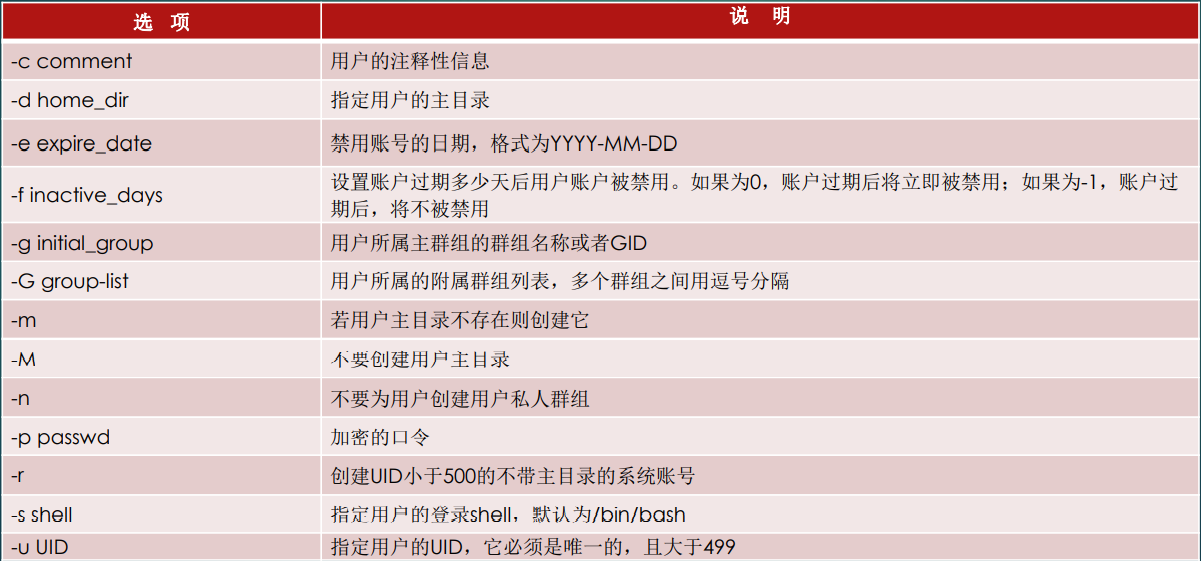
用户名最好不要使用大写,会出问题
例如:
新建用户user3,UID为1010,指定其用户的主目录为/home/user3,用户的shell为/bin/bash,用户的密码为123456,账户永不过期。
[root@server1 ~]# useradd -u 1010 -d /home/user3 -s /bin/bash -p 123456 -f -1 user3
[root@server1 ~]# tail -1 /etc/passwd
user3:x:1010:1000::/home/user3:/bin/bash
账户创建过程
- 在 /etc/passwd 里面建立一行与帐号相关的资料,包括建立 UID/GID/家目录等;
- 在 /etc/shadow 里面将此帐号的密码相关参数填入,但是尚未有密码;
- 在 /etc/group 里面加入一个与帐号名称一模一样的群组名称;
- 在 /home 底下建立一个与帐号同名的目录作为使用者家目录,且权限为 700
passwd:设置用户密码
基本语法
passwd [选项] [username]
用于指定和修改用户账户口令。超级用户可以为自己和其他用户设置口令,而普通用户只能为自己设置口令。
例如:
假设当前用户为root,则下面的两个命令分别为root用户修改自己的口令和root用户修改user1用户的口令:
//root用户修改自己的口令,直接用passwd命令回车即可
[root@server1 ~]# passwd
//root用户修改user1用户的口令
[root@server1 ~]# passwd user1
普通用户修改口令时,passwd命令会首先询问原来的口令,只有验证通过才可以修改。而root用户为用户指定口令时,不需要知道原来的口令。为了系统安全,用户应选择包含字母、数字和特殊符号组合的复杂口令,且口令长度应至少为8个字符。
id:查看用户是否存在
基本语法
id 用户名
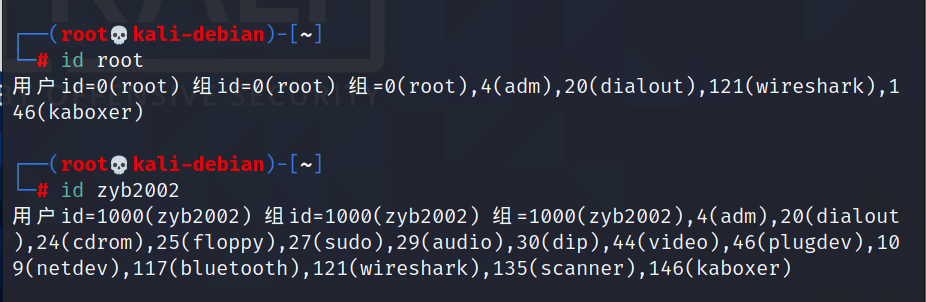
cat /etc/passwd:查看创建了哪些用户
基本语法
cat /etc/passwd
例如:

su:切换用户
su: swith user 切换用户
作用:可以解决切换用户身份的需求,使得当前用户在不退出登录的情况下,顺畅地切换到其他用户
当从root管理员切换到普通用户时是不需要密码验证的,而从普通用户切换成root管理员就需要进行密码验证。
基本语法
su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量)
su - 用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限)
例如:
[root@hadoop101 ~]#su tangseng
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/b
in
[root@hadoop101 ~]#exit
[root@hadoop101 ~]#su - tangseng
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/t
angseng/bin
尽管像上面这样使用su命令后,普通用户可以完全切换到root管理员身份来完成相应工作,但这会暴露root管理员的密码,从而增大了系统密码被黑客获取的概率,因此上述操作并不是最安全的方案。
userdel:删除用户
基本语法
(1)userdel 用户名 (功能描述:删除用户但保存用户主目录)
(2)userdel -r 用户名 (功能描述:用户和用户主目录,都删除)
例如:
(1)删除用户但保存用户主目录
[root@hadoop101 ~]#userdel tangseng
[root@hadoop101 ~]#ll /home/
(2)删除用户和用户主目录,都删除
[root@hadoop101 ~]#useradd zhubajie
[root@hadoop101 ~]#ll /home/
[root@hadoop101 ~]#userdel -r zhubajie
[root@hadoop101 ~]#ll /home/
who:查看登录用户信息
基本语法
(1)whoami (功能描述:显示自身用户名称)
(2)who am i (功能描述:显示登录用户的用户名以及登陆时间)
who am idebian用不了
w:查看当前登录系统用户和详细信息
基本语法
w
sudo:提供额外的权限
作用:sudo命令用于给普通用户提供额外的权限来完成原本root管理员才能完成的任务。
基本语法
sudo [参数] 命令名称
输入当前用户密码 5分钟内不用重复验证
选项说明
普通用户不用知道其它账户密码,就能通过sudo获得额外的权限,但需要在配置文件(/etc/sudoers)中进行配置, 该文件提供集中的用户管理、权限与主机等参数。
要使用root用户身份来进行操作
步骤如下:
[root@hadoop101 ~]#vi /etc/sudoers
修改 /etc/sudoers 文件,找到下面一行(91 行),在 root 下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
anthony ALL=(ALL) ALL
语义:
谁可以使用 允许使用的主机=(以谁的身份) 可执行命令的列表
或者配置成采用 sudo 命令时,不需要输入密码:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
anthony ALL=(ALL) NOPASSWD:ALL
修改完毕,现在可以用 anthony 帐号登录,然后用命令 sudo ,即可获得 root 权限进行操作。
或者我们可以直接把该用户放入到sudo组中(这个组不一定是叫sudo要根据文件中写的来,每个发行版本中的名字不一样):
%代表组,也就是说只要处于sudo组中的用户都可以获得等同于root管理员的权限
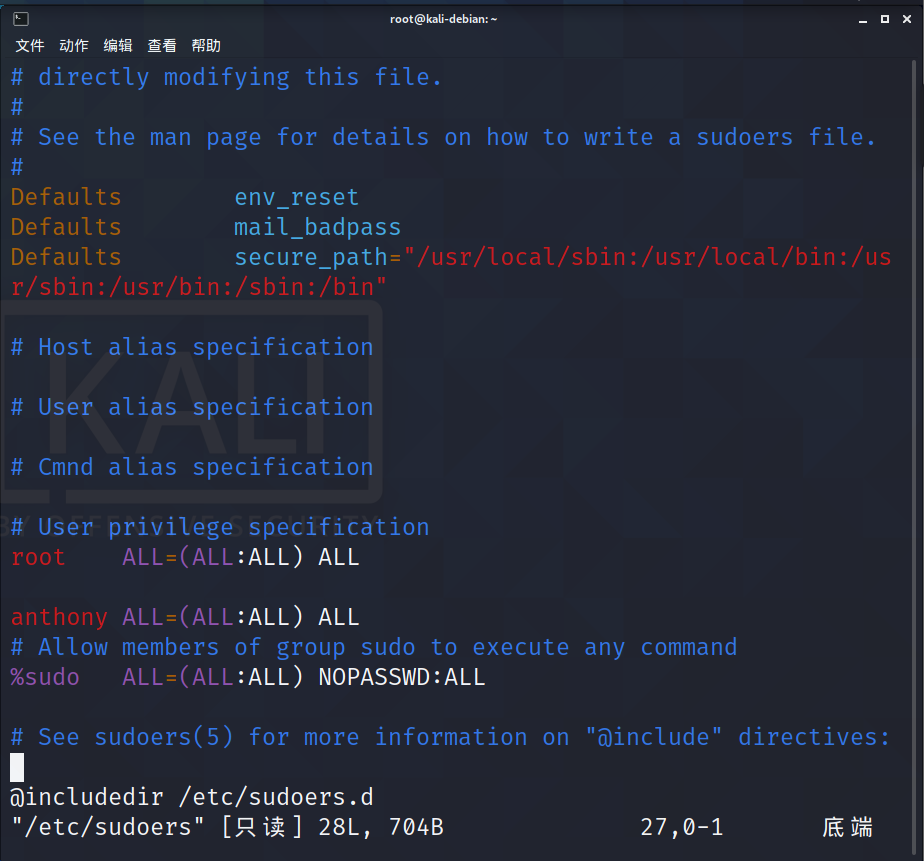

除了上述配置外,还可将用户加入到wheel群组
- visudo 去掉%wheel的注释符号“#”
- 使用命令 usermod –G wheel user3
例如:
在sudoers文件中添加配置,仅仅让user1能够以root身份执行cat命令(绝对路径):
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
user1 ALL=(ALL) /usr/bin/cat
user1 可以root身份执行cat,但执行其它命令仍然没权限:
[user1@thispc ~]$ sudo cat /etc/shadow
root:$6$zLEE8XN2$11ocLeHMcc18Ez4jf.7HP119AkfNC2iS57ZaKt4y4EZkb6SLraoD
bUFza5/xmqC/7k9ENCKrW6dF2NZwAlefr1:18354:0:99999:7:::
[user1@thispc ~]$ sudo ls /root
对不起,用户 user1 无权以 root 的身份在 thispc 上执行 /bin/ls /root。
usermod:修改用户账户信息
基本语法
usermod [选项] 用户名
选项说明
例如
(1)将用户加入到用户组
[root@hadoop101 opt]# usermod -g root zhubaji
(2)将用户user1加入root用户组中,这样扩展组列表中会出现root用户组的字样,而基本组不会受到影响,用-G参数修改用户扩展组ID :
[root@server1 ~]# usermod -G root user1
[root@server1 ~]# id user1
uid=1002(user1) gid=1002(user1) 组=1002(user1),0(root)
(3)用-u参数修改用户的UID
[root@server1 ~]# usermod -u 8888 user1
[root@server1 ~]# id user1
uid=8888(user1) gid=1002(user1) 组=1002(user1),0(root)
(4)修改用户user1的主目录为/var/user1,把启动shell修改为/bin/tcsh,完成后恢复到初始状态,操作如下:
[root@server1 ~]# usermod -d /var/user1 -s /bin/tcsh user1
[root@server1 ~]# tail -3 /etc/passwd
user1:x:8888:1002::/var/user1:/bin/tcsh
newusers:批量创建用户
基本语法
newusers 用户文件
指定包含用户信息的文本文件,文件格式要与/etc/passwd相同
格式;
用户名:x:UID:GID:用户说明:用户的家目录:所用SHELL
注意:
这里的格式必须严格遵守,而且文件能有多的空行,否则也会报错!
例如:
[root@localhost ~]# newusers userlist.txt
[root@localhost tail -n 5 /etc/passwd /etc/shadow
user1:x:2222:2004::/var/user1:/bin/tcsh
zhang:x:2005:2005::/home/zhang:/bin/bash
user3:x:1010:1010::/home/user3:/bin/bash
user4:x:2010:2010::/home/user4:/bin/bash
user5:x:2011:2011::/home/user5:/bin/bash
chpasswd:批量改用户密码
基本语法
cat 密码文件 | chpasswd
密码文件内容为[用户名:密码]
例如;
[root@localhost ~]# cat mima | chpasswd
#mima文件内容
user4:12345
user5:123123
禁用和恢复用户账户
作用:临时禁用一个账户而不删除
方法1:使用passwd命令
[root@server1 ~]# passwd -l user1
锁定用户 user1 的密码
passwd: 操作成功
//利用passwd命令的-u选项解除账户锁定,重新启用user1账户
[root@server1 ~]# passwd -u user1
方法2:使用usermod命令
//禁用user1账户
[root@server1 ~]# usermod -L user1
//解除user1账户的锁定
[root@server1 ~]# usermod -U user1
方法3:修改/etc/passwd文件,passwd域添加“*”
用户组管理类命令
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
groupadd:新增组
基本语法
groupadd 组名
groupdel:删除组
基本语法
groupdel 组
groupmod:修改组
基本语法
groupmod [选项] 组名
选项说明

gpasswd:为群组添加用户
useradd命令创建用户时,会同时创建一个和用户账户同名的群组,称为主群组。当一个群组中必须包含多个用户时,则需要使用附属群组。在附属组中增加、删除用户都用gpasswd命令。
只有root用户和组管理员才能够使用这个命令
基本语法
gpasswd [选项] [用户] [组]
选项说明
例如:
[liu@localhost ~]$ sudo gpasswd -A liu liu
[liu@localhost ~]$ gpasswd -a jone liu
正在将用户“jone”加入到“liu”组中
cat /etc/group:查看创建了哪些组
基本语法
[root@hadoop101 atguigu]# cat /etc/group
拓:初始群组和有效群组
-
创建用户时,用户被分配初始群组GID,加入其它群组后将拥有其它群组的权限。
-
创建文件时, 文件群组为有效群组
- 查看有效群组:groups
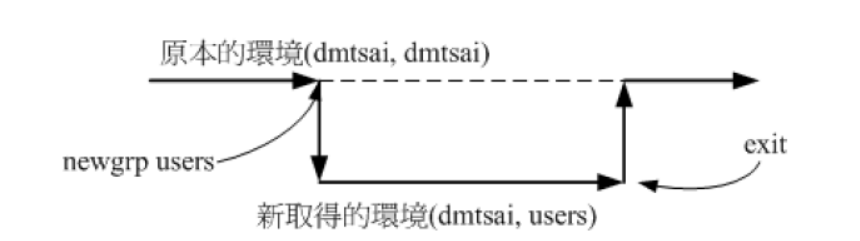
- 切换有效群组: newgrp 群组
原理: 分配另一个shell,用exit回到原shell
文件权限类命令
文件属性概述
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定。
在Linux中我们可以使用如下两条命令来显示一个文件的属性以及文件所属的用户和组:
llls -l
我们随便查看当前目录的文件属性:
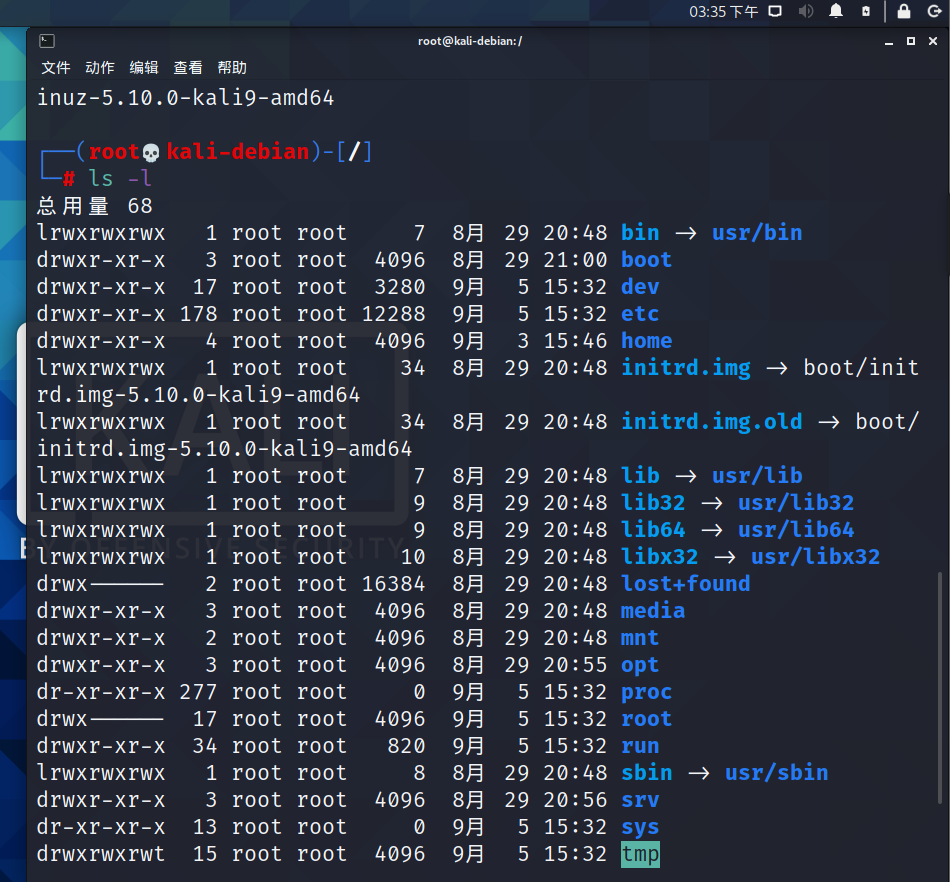
文件基本属性介绍:

- 如果查看的是文件:链接数指的是硬链接个数。
- 如果查看的是文件夹:链接数指的是子文件夹个数。
这里的链接数表示有多少文件名连结到此节点(i-node):
每个文件都会将其权限与属性记录到文件系统的i-node中,不过,我们使用的目录树却是使用文件来记录,因此每个文件名就会连接到一个i-node。这个属性记录的就是有多少不同的文件名连接到相同的一个i-node。
注意:
- 文件大小的单位是bytes
- 文件名字:如果文件名之前多一个
“.”,则代表这个文件为隐藏文件。使用ls –a可以查看隐藏文件
从左到右的 10 个字符表示,如下图所示:

如果没有权限,就会出现减号[ – ]
从左至右用0-9这些数字来表示:
-
0 首位表示类型:在Linux中第一个字符代表这个文件是目录、文件或链接文件等等
-代表普通文件d代表目录l链接文档(link file);- b、c:分别表示该文件为区块设备或其他的外围设备,是特殊类型的文件。
- s、p:这些文件关系到系统的数据结构和管道,通常很少见到。
-
第1-3位确定属主(该文件的所有者)拥有该文件的权限。—User
-
第4-6位确定属组(所有者的同组用户)拥有该文件的权限,—Group
在Linux系统下,账号会附属于一个或多个的群组中。举例来说明:class1、class2、class3均属于projecta这个群组,假设某个文件所属的群为projecta,且该文件的权限为(-rwxrwx—),则class1、class2、class3 3人对于该文件都具有可读、可写、可执行的权限(看群组权限)。但如果是不属于projecta的其他账号,对于此文件就不具有任何权限了
-
第7-9位确定其他用户拥有该文件的权限 —Other
rwx 对于文件和目录的不同解释
(1)作用到文件:
- [ r ]代表可读(read): 可以读取,查看
- [ w ]代表可写(write): 可以修改,但是不代表可以删除该文件,删除一个文件的前提条件是对该文件所在的目录有写权限,才能删除该文件
- [ x ]代表可执行(execute):可以被系统执行
(2)作用到目录:
- [ r ]代表可读(read): 可以读取,ls查看目录内容
- [ w ]代表可写(write): 可以修改,目录内创建+删除+重命名目录
- [ x ]代表可执行(execute):可以进入该目录
chmod:改变权限
基本语法

第一种方式变更权限:
chmod [{ugoa}{+-=}{rwx}] 文件或目录
可能不好理解,我们举几个例子:
+代表添加,例如现有g的权限为---,使用g+r后变为r---代表撤销,例如现有o的权限为r-x,使用o-r后变为--x=代表赋予,例如现有u的权限为---,使用u=rw后变为rw-
第二种方式变更权限:
chmod [mode=421 ] [文件或目录]
u:所有者 g:所有组 o:其他人 a:所有人(u、g、o 的总和)
r=4 w=2 x=1 rwx=4+2+1=7
例如:
(1)修改文件使其所属主用户具有执行权限
[root@hadoop101 ~]# chmod u+x houge.txt
(2)修改文件使其所属组用户具有执行权限
[root@hadoop101 ~]# chmod g+x houge.txt
(3)修改文件所属主用户执行权限,并使其他用户具有执行权限
[root@hadoop101 ~]# chmod u-x,o+x houge.txt
(4)采用数字的方式,设置文件所有者、所属组、其他用户都具有可读可写可执行权限。
[root@hadoop101 ~]# chmod 777 houge.txt
(5)修改整个文件夹里面的所有文件的所有者、所属组、其他用户都具有可读可写可执行权限。
[root@hadoop101 ~]# chmod -R 777 xiyou/
chown:改变所有者
仅root用户可使用
基本语法
chown [选项] [最终用户] [文件或目录] (功能描述:改变文件或者目录的所有者)
选项说明:
-R:递归操作
例如:
chown命令可以同时修改文件的所有者和属组,用“:”分隔。
例如:
将/yy/file文件的所有者和属组都改为test的命令如下所示:
chown test:test /yy/file
如果只修改文件的属组可以使用下列命令:
chown :test /yy/file
修改文件的属组也可以使用chgrp命令。命令范例如下所示:
chgrp test /yy/file
chgrp:改变所属组
基本语法
chgrp [最终用户组] [文件或目录] (功能描述:改变文件或者目录的所属组)
umask:文件默认权限修改
Umask 命令用于指定用户在建立文件和目录时的权限默认值,umask值称作权限掩码。
查看默认权限命令: umask
设置默认权限命令: umask 数字权限
文件、目录默认权限修改方法:
文件的预设权限为-rw-rw-rw-,目录的预设权限为-rwxrwxrwx,普通用户umask默认值为002,root用户为022, 创建文件时在预设权限中减掉umask值对应的权限。
例:umask为002的普通用户创建文件,user、group都没有变化,但others用户要减掉2对应的‘写权限’,变为-rw-rw-r–
SUID、SGID、SBIT:文件特殊权限
SUID
当s这个标志出现在文件所有者的x权限上时,如“-rwsr-xr-x”简称:Set UID
SUID权限仅对二进制程序有效
执行者对该程序需要具有x的可执行权限
执行者将具有该程序所有者的权限
本权限仅在执行该程序的过程中有效
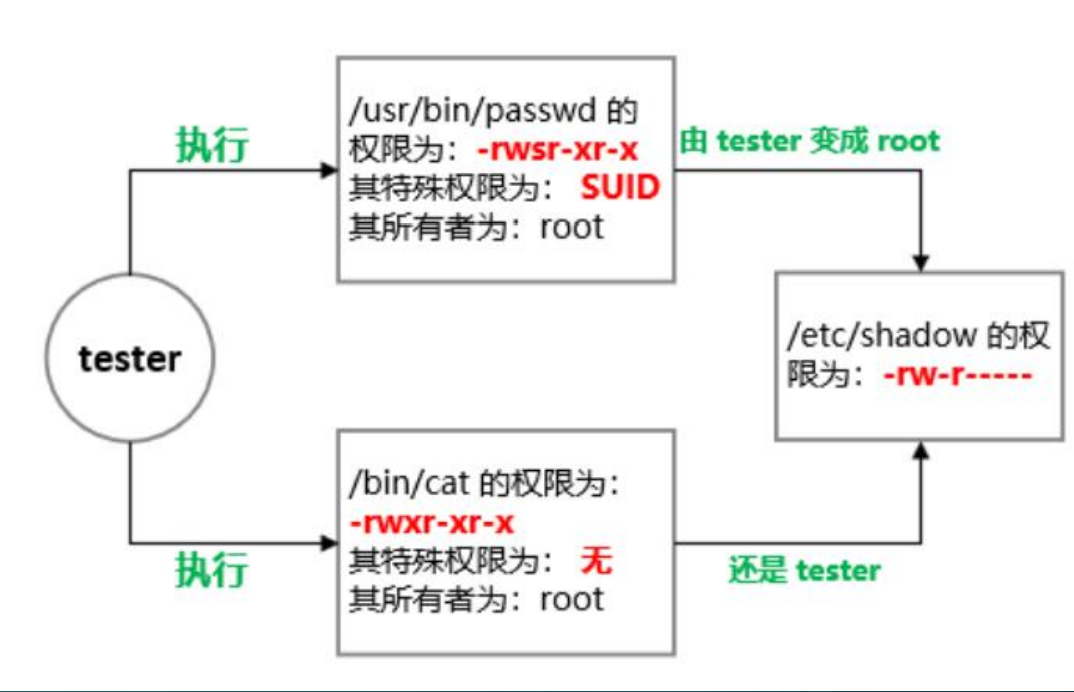
例:tester 用户是如何利用 SUID 权限完成密码修改的:
- tester 用户对于 /usr/bin/passwd 这个程序具有执行权限,因此可以执行passwd 程序
- passwd 程序的所有者为 root
- tester 用户执行 passwd 程序的过程中会暂时获得 root 权限
- 因此 tester 用户在执行 passwd 程序的过程中可以修改 /etc/shadow 文件
SGID
SGID权限仅对二进制程序有效
程序执行者对于该程序来说,需要有x的执行权
执行者在执行过程中将会获得用户组的支持
目录功能:
用户若对于此目录具有r与x权限时,该用户能够进入目录;
用户在此目录下的有效群组,将会变成该目录的群组;
用途:若用户在此目录有w权限,则使用者所建立的新文件,该新文件的群组与此
目录的群组相同。
总结:当用户对某一目录有写和执行权限时,该用户就可以在该目录下建立文件,如果该目录用 SGID 修饰,则该用户在这个目录下建立的文件都是属于这个目录所属的组。
SBIT
用户对该目录具有w、x权限
SBIT 目前只对目录有效,用来阻止非文件的所有者删除文件。
当用户在该目录下创建文件或是目录时,仅有自己和root才有权力删除该文件。
SUID、SGID、SBIT的权限设置
使用更改权限chmod的命令,使用数字更改,原本的权限是三组数字,要设置特殊权限,只需在加上一组数字即可。
-
SUID:4
-
SGID: 2
-
SBIT: 1
符号权限设置法
suid u+s, sgid g+s, SBIT o+t
suid rwsr-xr-x
suid/sgid rwsr-sr-x
sbit rwxr-xr-t
没有执行权限时: suid/sgid rwSr-Sr-T
注意:
设置过程中,我们可能得到设置的结果为 S,T;这个 S, T 代表的就是“空的”!什么意思呢?
SUID 是表示“该文件在执行的时候, 具有文件拥有者的权限”, 但是文件 拥有者都无法执行了, 哪里来的权限给其他人使用? 当然就是空的啦
数字权限设置法:
加上特殊权限SUID: chmod 4755 文件名
加上特殊权限SGID: chmod 2755 文件名
加上特殊权限SBIT: chmod 1755 文件名
加上特殊权限SUID和SGID: chmod 6755 文件名
若仍存疑问,可以看以下文章:
Linux 权限管理篇(五),文件特殊权限: SUID, SGID, SBIT
搜索查找类命令
文件通配符概述
-
星号
*:
匹配任意长度的文件名字符串(包括空字符串) -
问号
?:
匹配任一单字符 -
点字符
.:
当它作为文件名或路径名分量的第一个字符时,必须显式匹配
例:*file匹配file,makefile,不匹配.profile文件
try*c匹配try1.c、try.c、try.basic -
方括号
[ ]
匹配括号内任一字符,也可以用减号指定一个范围
例:[A-Z]*、*.[ch]、[Mm]akefile -
[^]
若中括号内的第一个字符为“^”,则表示反向选择
例:[^abc]表示一定有一个字符,只要是非a、b、c即可
文件名通配符规则与正则表达式的规则不同,应用场合不同。不同种类shell通配符规则会略有些差别
- 假设当前目录下只有
try.c,zap.c,arc.c三文件
键入内容cat *.c,实际执行cat arc.c try.c zap.c(按字典序) - 假设当前目录下有名为
makefile的文件
键入rm m*e, 实际执行rm makefile
find:查找文件或者目录
find 指令将从指定目录向下递归地遍历其各个子目录,将满足条件的文件显示在终端
基本语法
find [搜索范围] [选项] [-print -exec -ok]
选项说明

- -group grpname:查找属于指定组的文件。
- -inum n:查找索引节点号为n的文件。
- -type:查找指定类型的文件。文件类型有:
- b(块设备文件)
- c(字符设备文件)
- d(目录)
- p(管道文件)
- l(符号链接文件)
- f(普通文件)
- -atime n:查找n天前被访问过的文件。“+n”表示超过n天前被访问的文件;“-n”表示n天内被访问的文件,n表示n天之前的[一天之内]被访问过的文件。
- -mtime n:类似于atime,但检查的是文件内容被修改的时间。
- -ctime n:类似于atime,但检查的是文件索引节点被改变的时间。
- -perm mode:查找与给定权限匹配的文件,必须以八进制的形式给出访问权限。
mode表示权限为mode,-mode搜索权限包括mode的文件(范围比mode大),/mode表示搜索符合任何一个权限的文件(范围比mode小)。 - -newer file:查找比指定文件新的文件,即最后修改时间离现在较近。
- -exec command {} ;:对匹配指定条件的文件执行command命令。
- -ok command {} ;:与exec相同,但执行command命令时请求用户确认。
- -print:显示查找结果。
例如:
(1)按文件名:根据名称查找/目录下的filename.txt文件。
[root@hadoop101 ~]# find xiyou/ -name "*.txt"
(2)按拥有者:查找/opt目录下,用户名称为-user的文件
[root@hadoop101 ~]# find xiyou/ -user atguigu
(3)按文件大小:在/home目录下查找大于200m的文件(+n 大于 -n小于 n等于)
[root@hadoop101 ~]# find /home -size +204800



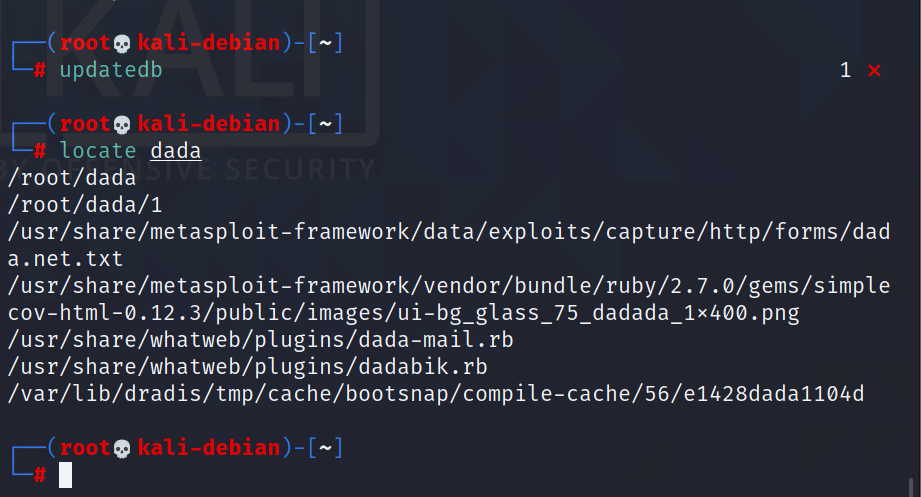
locate:快速定位文件路径
locate 指令利用事先建立的系统中所有文件名称及路径的 locate 数据库实现快速定位给定的文件。Locate 指令无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确度,管理员必须定期更新 locate 。
基本语法
locate 搜索文件
由于 locate 指令基于数据库进行查询,所以第一次运行前,必须使用 updatedb 指令创建 locate 数据库
例如:
whereis:寻找命令的可执行文件所在的位置
基本语法
whereis [选项] [文件名]
选项说明
- -b:只查找二进制文件。
- -m:只查找命令的联机帮助手册部分。
- -s:只查找源代码文件。
grep过滤查找及“|”管道符
管道符
|表示将前一个命令的处理结果输出传递给后面的命令处理
grep与locate、find的区别在于:
locate、find偏重于使用文件名查找文件
grep偏重于按照文件内容查找文件
egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
基本语法
grep 选项 查找内容 源文件
选项说明
- -a 不要忽略二进制数据。
- -A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
- -b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
- -c 计算符合范本样式的列数。
- -C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
- -d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
- -e<范本样式> 指定字符串作为查找文件内容的范本样式。
- -E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
- -f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
- -F 将范本样式视为固定字符串的列表。
- -G 将范本样式视为普通的表示法来使用。
- -h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
- -H 在显示符合范本样式的那一列之前,标示该列的文件名称。
- -i 忽略字符大小写的差别。
- -l 列出文件内容符合指定的范本样式的文件名称。
- -L 列出文件内容不符合指定的范本样式的文件名称。
- -n 在显示符合范本样式的那一列之前,标示出该列的编号。
- -q 不显示任何信息。
- -R/-r 此参数的效果和指定“-d recurse”参数相同。
- -s 不显示错误信息。
- -v 反转查找。
- -w 只显示全字符合的列。
- -x 只显示全列符合的列。
- -y 此参数效果跟“-i”相同。
- -o 只输出文件中匹配到的部分。
例如:
拓:wc命令
打印对每个给定文件的新行、单词和字节计数的结果
压缩和解压类命令
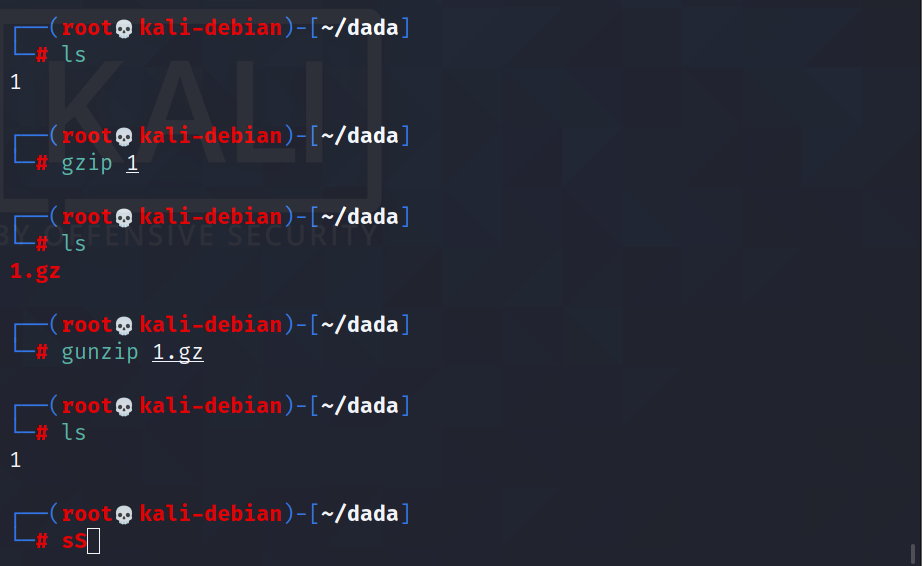
gzip/gunzip:压缩
基本语法
gzip [参数] 待压缩文件名
gzip 文件 (功能描述:压缩文件,只能将文件压缩为*.gz 文件)
gunzip 文件.gz (功能描述:解压缩文件命令)
参数说明
- -c:将压缩的数据输出到屏幕上
- -d:解压缩
- -t: 检验压缩文件的完整性
- -v:显示出源文件/压缩文件的压缩比等信息
- -num:数字代表压缩等级-1最快,压缩比最差,预设为-6.
注意:
- 只能压缩文件不能压缩目录
- 不保留原来的文件
- 同时多个文件会产生多个压缩包
例如:
查看纯文本文件压缩内容:
zcat
zmore
zless
bzip2:压缩
基本语法
bzip2 [参数] 待压缩文件名
也是生成.gz文件
参数说明
- -d:解压缩
- -k: 在压缩或解压缩时保留输入文件(不删除这些文件)
- -v:显示出源文件/压缩文件的压缩比等信息
- -num:数字代表压缩等级-1最快,压缩比最差,预设为6.
查看纯文本文件压缩内容:
bzcat
bzmore
bzless
xz:压缩
基本语法
xz [参数] 待压缩文件名
也是生成.gz文件
参数说明
- -d:解压缩
- -v:显示出源文件/压缩文件的压缩比等信息
- -num:数字代表压缩等级-1最快,压缩比最差,预设为6.
- -t: 测试压缩文件的完整性
- -l: 列出压缩文件中的相关信息
- -k:压缩但不删除,输入文件
- -f:解压强制覆盖文件
查看纯文本文件压缩内容:
xzcat
xzmore
xzcat
zip/unzip:压缩
基本语法
zip [选项] XXX.zip 将要压缩的内容 (功能描述:压缩文件和目录的命令)
unzip [选项] XXX.zip (功能描述:解压缩文件)
选项说明

zip 压缩命令在windows/linux都通用,可以压缩目录且保留源文件。
例如:
(1)压缩 houge.txt 和bailongma.txt,压缩后的名称为mypackage.zip
[root@hadoop101 opt]# touch bailongma.txt
[root@hadoop101 ~]# zip mypackage.zip houge.txt bailongma.txt
adding: houge.txt (stored 0%)
adding: bailongma.txt (stored 0%)
[root@hadoop101 opt]# ls
houge.txt bailongma.txt mypackage.zip
(2)解压 mypackage.zip
[root@hadoop101 ~]# unzip mypackage.zip
Archive: houma.zip
extracting: houge.txt
extracting: bailongma.txt
[root@hadoop101 ~]# ls
houge.txt bailongma.txt mypackage.zip
(3)解压mypackage.zip到指定目录-d
[root@hadoop101 ~]# unzip mypackage.zip -d /opt
[root@hadoop101 ~]# ls /opt/
tar:打包
功能:将多个文件或目录打包在一个文件里,便于传输和保持。
基本语法
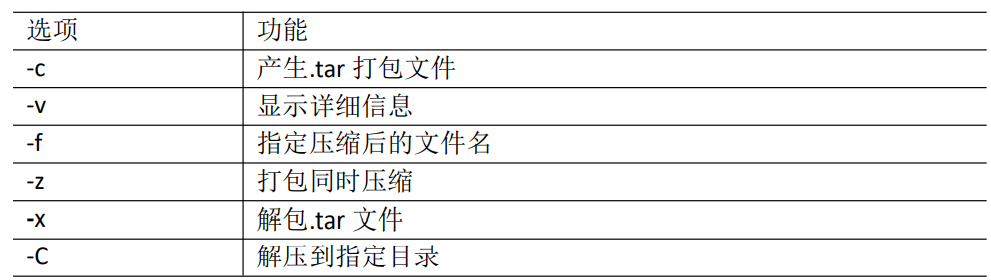
tar [options] 包名 file-list(待归档文件或目录列表)
选项说明
- -t: 列出备份文件的内容,查看已经备份的文件。
- -r:添加文件到归档包文件的尾部
例如:
(1)压缩多个文件
[root@hadoop101 opt]# tar -zcvf houma.tar.gz houge.txt bailongma.txt
houge.txt
bailongma.txt
[root@hadoop101 opt]# ls
houma.tar.gz houge.txt bailongma.txt
(2)压缩目录
[root@hadoop101 ~]# tar -zcvf xiyou.tar.gz xiyou/
xiyou/
xiyou/mingjie/
xiyou/dssz/
xiyou/dssz/houge.txt
(3)解压到当前目录
[root@hadoop101 ~]# tar -zxvf houma.tar.gz (4)解压到指定目录
[root@hadoop101 ~]# tar -zxvf xiyou.tar.gz -C /opt
[root@hadoop101 ~]# ll /opt/

拓:打包和压缩的区别
打包:也称为归档,指的是一个文件或目录的集合,而这个集合被存储在一个文件中。
压缩:是指利用算法将文件进行处理,已达到保留最大文件信息,而让文件体积变小的目的。其基本原理为,通过查找文件内的重复字节,建立一个相同字节的词典文件,并用一个代码表示。比如说,在压缩文件中,有不止一处出现了 “C语言中文网”,那么,在压缩文件时,这个词就会用一个代码表示并写入词典文件,这样就可以实现缩小文件体积的目的。
对文件进行压缩,很可能损坏文件中的内容,因此,压缩又可以分为有损压缩和无损压缩。无损压缩很好理解,指的是压缩数据必须准确无误;有损压缩指的是即便丢失个别的数据,对文件也不会造成太大的影响。有损压缩广泛应用于动画、声音和图像文件中,典型代表就是影碟文件格式 mpeg、音乐文件格式 mp3 以及图像文件格式 jpg。采用压缩工具对文件进行压缩,生成的文件称为压缩包,该文件的体积通常只有原文件的一半甚至更小。需要注意的是,压缩包中的数据无法直接使用,使用前需要利用压缩工具将文件数据还原,此过程又称解压缩。
区别:
- 归档文件没有经过压缩,因此,它占用的空间是其中所有文件和目录的总和。压缩文件也是一个文件和目录的集合,且这个集合也被存储在一个文件中,但它们的不同之处在于,压缩文件采用了不同的存储方式,使其所占用的磁盘空间比集合中所有文件大小的总和要小。
- Linux 下,常用归档命令有 2 个,分别是 tar 和 dd(相对而言,tar 的使用更为广泛);常用的压缩命令有很多,比如 gzip、zip、bzip2 等。*
注意,tar 命令也可以作为压缩命令,也很常用
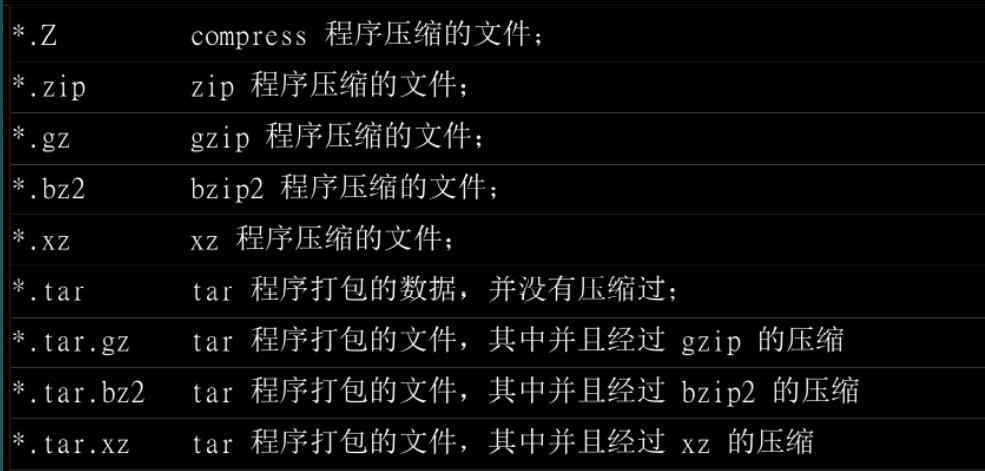
拓:常见的压缩文件扩展名
Linux中有很多可以用于压缩的命令。Linux中常见的压缩文件扩展名如图:
磁盘查看和分区类命令
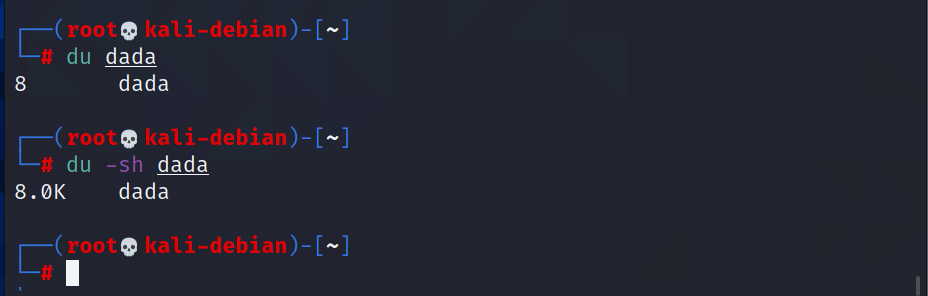
du:查看文件和目录占用的磁盘空间
du: disk usage 磁盘占用情况
基本语法
du 目录/文件 (功能描述:显示目录下每个子目录的磁盘使用情况)
选项说明

例如:
df:查看磁盘空间使用情况
df: disk free 空余磁盘
基本语法
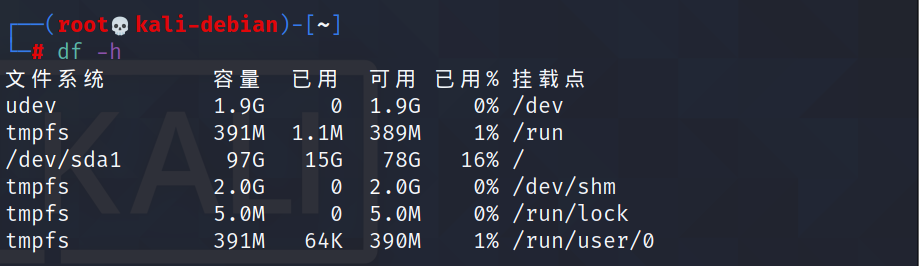
df 选项 (功能描述:列出文件系统的整体磁盘使用量,检查文件系统的磁盘空间占用情况)
选项说明
-h:以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示
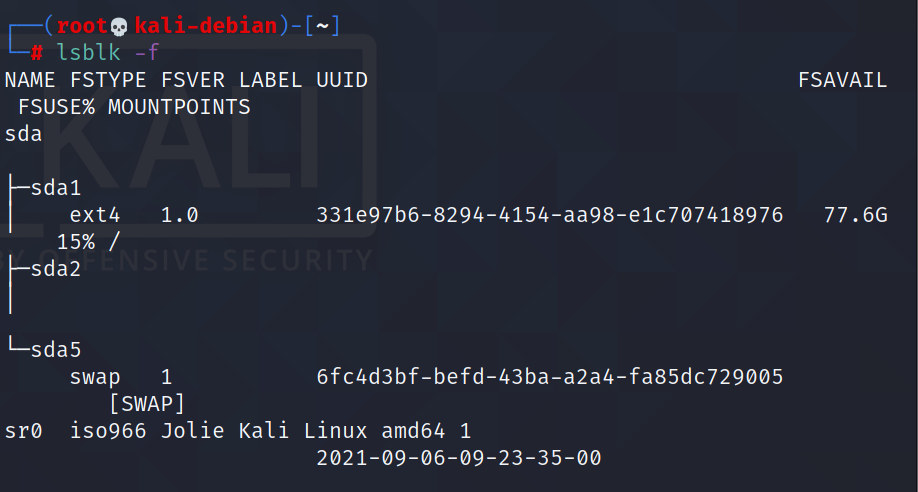
lsblk:查看设备挂载情况
基本语法
lsblk (功能描述:查看设备挂载情况)
选项说明
-f:查看详细的设备挂载情况,显示文件系统信息
例如:
mount/umount:挂载/卸载
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录、一个独立且唯一的文件结构。
Linux中每个分区都是用来组成整个文件系统的一部分,它在用一种叫做“挂载”的处理方法,它整个文件系统中包含了一整套的文件和目录,并将一个分区和一个目录联系起来,要载入的那个分区将使它的存储空间在这个目录下获得。
挂载前准备(必须要有光盘或者已经连接镜像文件)
基本语法
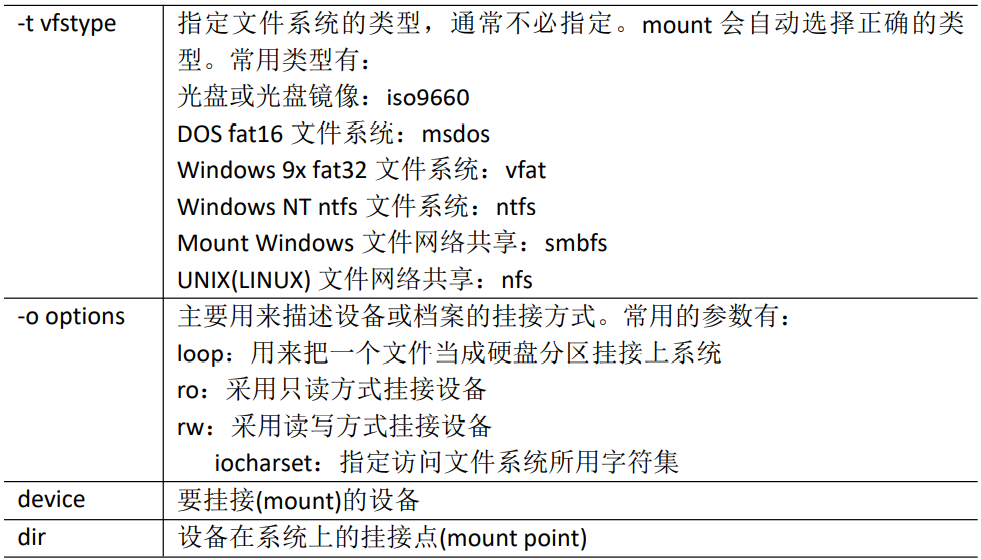
mount [-t vfstype] [-o options] device dir (功能描述:挂载设备)
umount 设备文件名或挂载点 (功能描述:卸载设备)
参数说明
(1)挂载光盘镜像文件
[root@hadoop101 ~]# mkdir /mnt/cdrom/ 建立挂载点
[root@hadoop101 ~]# mount -t iso9660 /dev/cdrom /mnt/cdrom/ 设备/dev/cdrom 挂载到 挂载点 : /mnt/cdrom 中
[root@hadoop101 ~]# ll /mnt/cdrom/
(2)卸载光盘镜像文件
[root@hadoop101 ~]# umount /mnt/cdrom
设置开机自动挂载
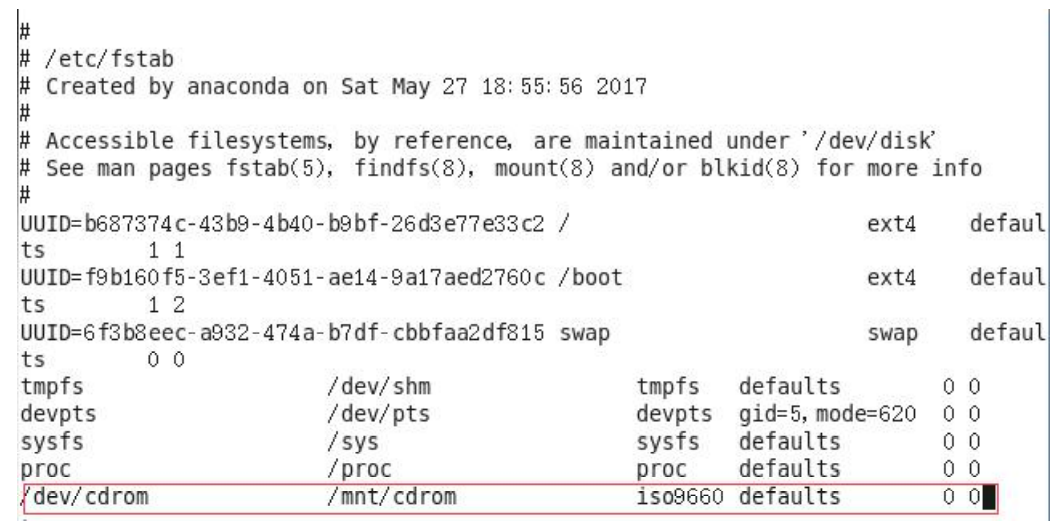
[root@hadoop101 ~]# vi /etc/fstab
添加红框中内容,保存退出:
fdisk:分区
基本语法
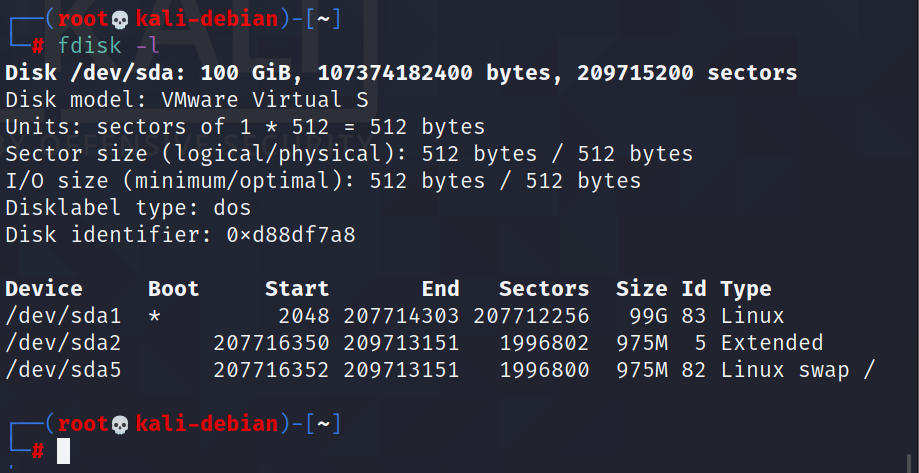
fdisk -l (功能描述:查看磁盘分区详情)
fdisk 硬盘设备名 (功能描述:对新增硬盘进行分区操作)
选项说明
-l:显示所有硬盘的分区列表
该命令必须在 root 用户下才能使用
功能说明
(1)Linux 分区
- Device:分区序列
- Boot:引导
- Start:从X磁柱开始
- End:到Y磁柱结束
- Blocks:容量
- Id:分区类型ID
- System:分区类型
(2)分区操作按键说明
- m:显示命令列表
- p:显示当前磁盘分区
- n:新增分区
- w:写入分区信息并退出
- q:不保存分区信息直接退出
例如我们查看一下系统分区情况:
进程管理类命令
进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体,都有自己的地址空间,并占用一定的系统资源。
ps:查看当前系统进程状态
ps:process status 进程状态
基本语法
ps aux | grep xxx (功能描述:查看系统中所有进程)
ps -ef | grep xxx (功能描述:可以查看子父进程之间的关系)
选项说明
ps aux 显示信息说明
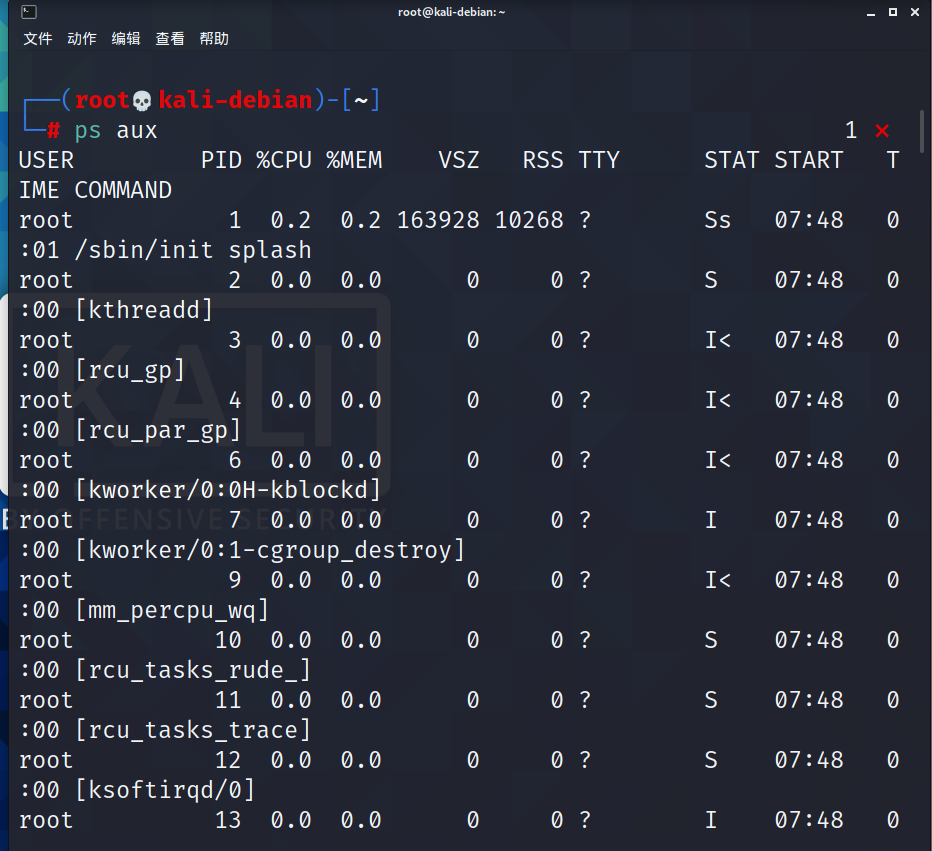
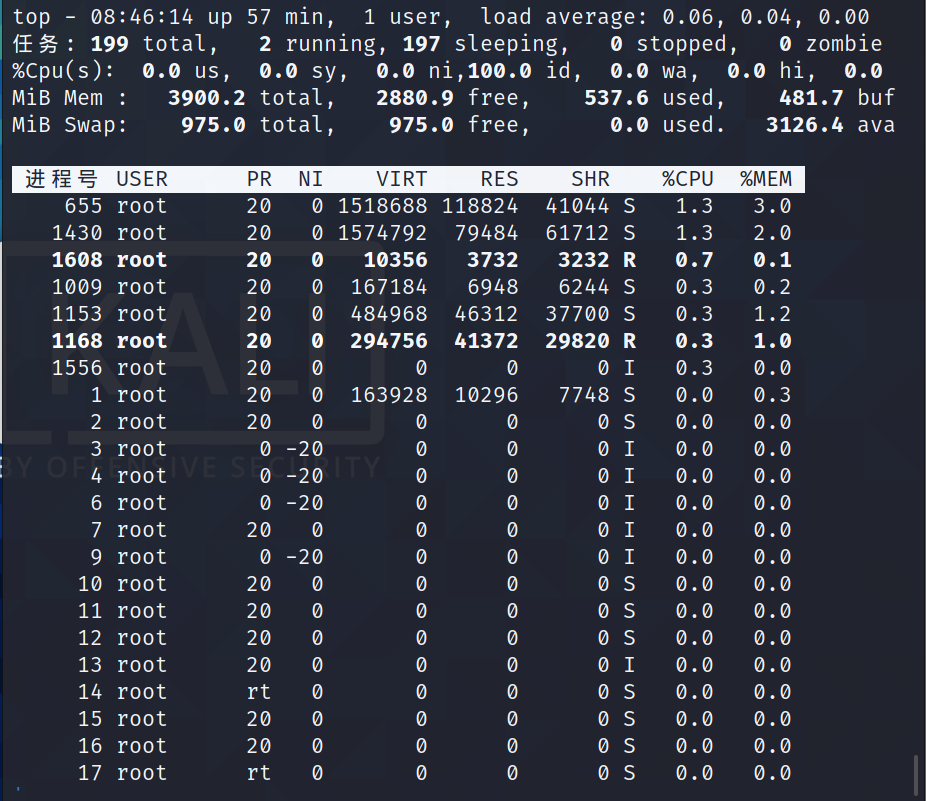
USER:该进程是由哪个用户产生的PID:进程的 ID 号%CPU:该进程占用 CPU 资源的百分比,占用越高,进程越耗费资源;%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;VSZ:该进程占用虚拟内存的大小,单位 KB;RSS:该进程占用实际物理内存的大小,单位 KB;TTY:该进程是在哪个终端中运行的。对于 CentOS 来说,tty1 是图形化终端,tty2-tty6 是本地的字符界面终端。pts/0-255 代表虚拟终端。STAT:进程状态。常见的状态有:R:运行状态、S:睡眠状态、T:暂停状态、Z:僵尸状态、s:包含子进程、l:多线程、+:前台显示START:该进程的启动时间TIME:该进程占用 CPU 的运算时间,注意不是系统时间COMMAND:产生此进程的命令名
ps -ef 显示信息说明

UID:用户 IDPID:进程 IDPPID:父进程 IDC:CPU 用于计算执行优先级的因子。数值越大,表明进程是 CPU 密集型运算,执行优先级会降低;数值越小,表明进程是 I/O 密集型运算,执行优先级会提高STIME:进程启动的时间TTY:完整的终端名称TIME:CPU 时间CMD:启动进程所用的命令和参数
如果想查看进程的 CPU 占用率和内存占用率,可以使用
aux
如果想查看进程的父进程 ID 可以使用-ef
kill:终止进程
基本语法
kill [选项] 进程号 (功能描述:通过进程号杀死进程)
killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用)
选项说明
-9:表示强迫进程立即停止
pstree:查看进程树
kill:终止进程
基本语法
pstree [选项]
选项说明

例如:
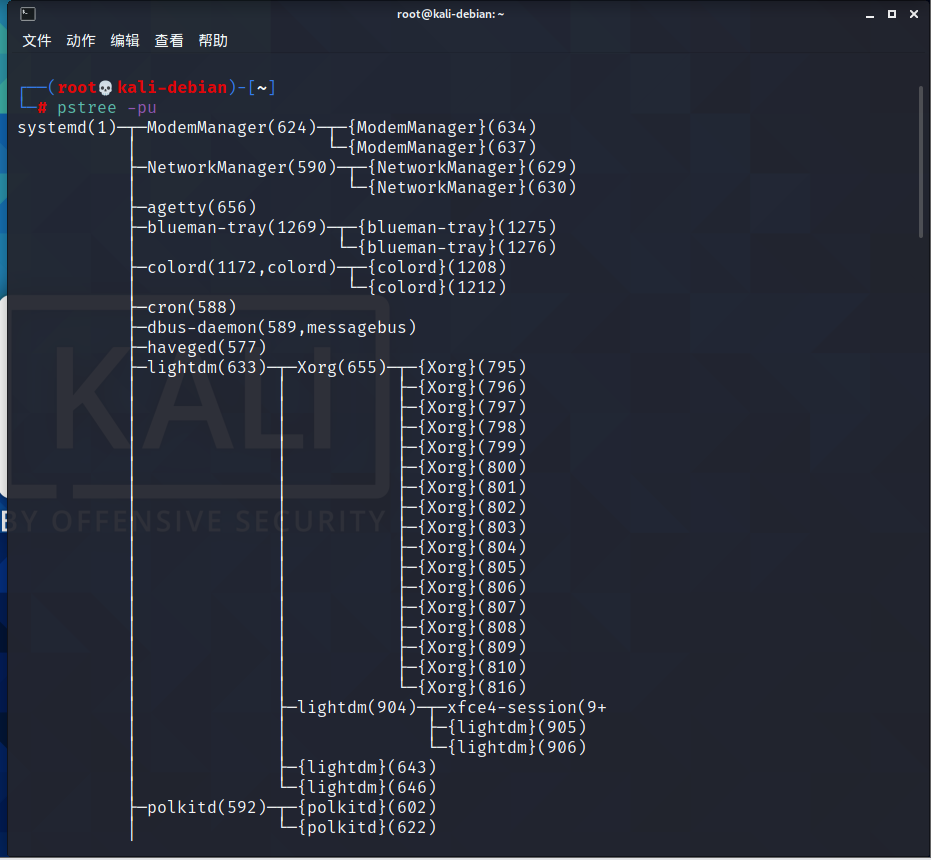
top:实时监控系统进程状态
基本语法
top [选项]
选项说明
-d秒数:指定 top 命令每隔几秒更新。默认是 3 秒在 top 命令的交互模式当中可以执行的命令-i:使 top 不显示任何闲置或者僵死进程-p:通过指定监控进程 ID 来仅仅监控某个进程的状态。
操作说明

查询结果字段解释
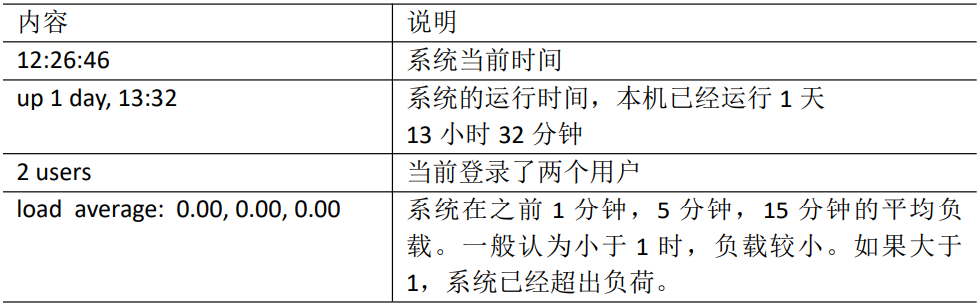
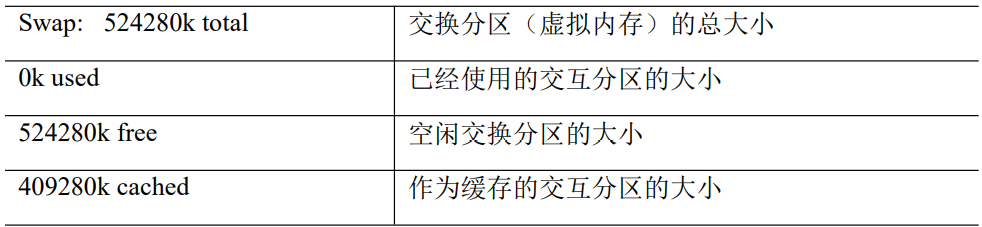
第一行信息为任务队列信息
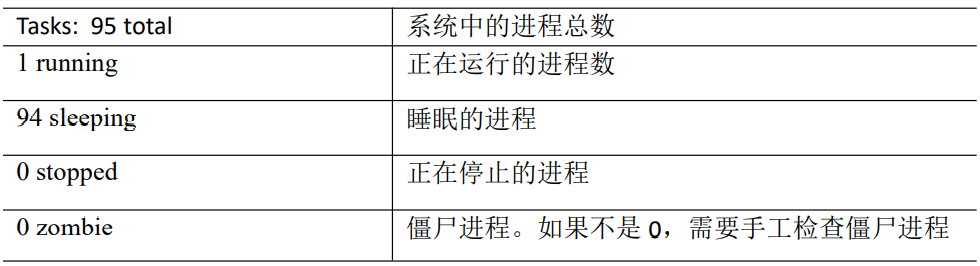
第二行为进程信息
第三行为 CPU 信息


第四行为物理内存信息
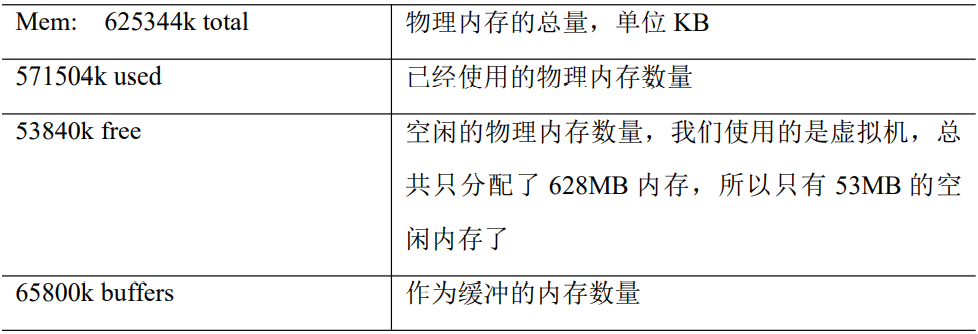
第五行为交换分区(swap)信息
[root@hadoop101 ~]# top -d 1
[root@hadoop101 ~]# top -i
[root@hadoop101 ~]# top -p 2575
执行上述命令后,可以按 P、M、N 对查询出的进程结果进行
netstat:显示网络状态和端口占用信息
基本语法
netstat -anp | grep 进程号 (功能描述:查看该进程网络信息)
netstat –nlp | grep 端口号 (功能描述:查看网络端口号占用情况)
选项说明
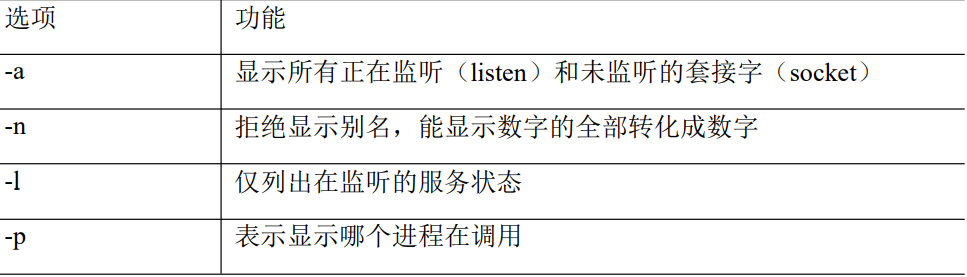
例如:
(1)通过进程号查看sshd进程的网络信息
[root@hadoop101 hadoop-2.7.2]# netstat -anp | grep sshd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
951/sshd
tcp 0 0 192.168.202.100:22 192.168.202.1:57741
ESTABLISHED 3380/sshd: root@pts
tcp 0 52 192.168.202.100:22 192.168.202.1:57783
ESTABLISHED 3568/sshd: root@pts
tcp 0 0 192.168.202.100:22 192.168.202.1:57679
ESTABLISHED 3142/sshd: root@pts
tcp6 0 0 :::22 :::* LISTEN
951/sshd
unix 2 [ ] DGRAM 39574 3568/sshd:
root@pts
unix 2 [ ] DGRAM 37452 3142/sshd:
root@pts
unix 2 [ ] DGRAM 48651 3380/sshd:
root@pts
unix 3 [ ] STREAM CONNECTED 21224 951/ssh
(2)查看某端口号是否被占用
[root@hadoop101 桌面]# netstat -nltp | grep 22
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN
1324/dnsmasq
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
951/sshd
tcp6 0 0 :::22 :::* LISTEN
951/sshd
nice:指定进程调度优先级
nice 命令用于以指定的进程调度优先级启动其他的程序。
以指定的优先级运行命令,这会影响相应进程的调度。如果不指定命令,程序会显示当前的优先级。优先级的范围是从 -20(最大优先级)到 19(最小优先级)。
系统的后台工作中,某些比较不重要的进程在运行,例如备份,由于备份工作相当耗系统资源,这个时候就可以调大备份命令的 nice 值,可以使系统资源更合理使用。
使用场景:在实际应用中,如果要运行一个CPU密集型程序,最好通过nice命令来启动它,这样可以保证其他进程获得更高的优先级,即使服务器或台式机在负载很重的情况下, 也可以快速响应。
语法格式:
nice [OPTION] [COMMAND [ARG]...]
选项说明:
- -n, –adjustment=
对优先级数值加上指定整数 N(默认为 10)。 - –help
显示此帮助信息并退出。 - –version
显示版本信息并退出。
使用示例:
以指定进程优先级启动进程。
nice -n 19 vim &
[1] 24524
1
2
我们看下进程 vim 的 nice 值。
ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 T 0 24524 28730 0 99 19 - 36809 do_sig pts/0 00:00:00 vim
0 R 0 26462 28730 0 80 0 - 38332 - pts/0 00:00:00 ps
4 S 0 28730 28727 0 80 0 - 29184 do_wai pts/0 00:00:00 bash
1
2
3
4
5
从输出可以看到,vim NI 列的值为 19,表明 vim 是按照 nice 为 19 的调度优先级启动的。
renice:指定进程调度优先级

renice命令是与nice关联的一个命令,由re两个字母就知道可以重新调整进程执行的优先级,可以指定群组或者用户名调整优先级等级,并修改隶属于该群组或者用户的所有程序优先级。等级范围为[-20,19]。同样仅系统管理员可以拉高优先级。nice在进程拉起时调整,renice在进程执行时调整。
使用场景:一个紧急进程,需要更多CPU资源时,可以拉低之前运行进程的优先级。
使用实例:

crontab系统定时类命令
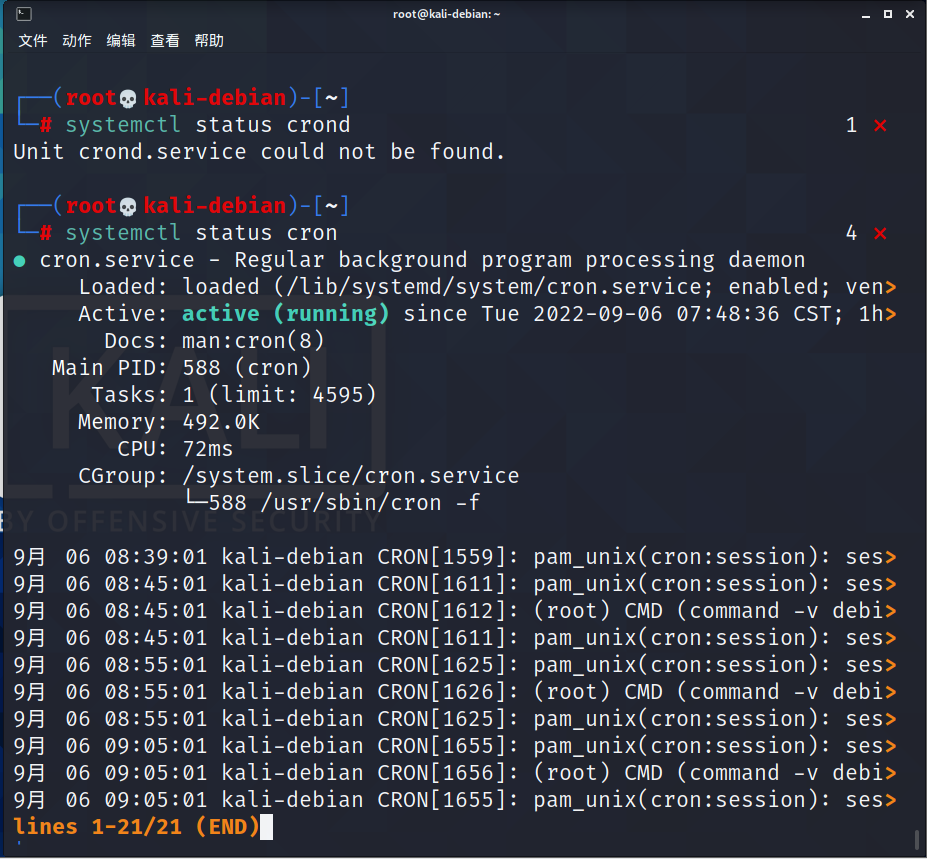
我们使用之前可以先查看服务是否开启:
# systemctl status crond
ubuntu用户不一样:
# systemctl status cron
重新启动 crond 服务
[root@hadoop101 ~]# systemctl restart crond
crontab:定时任务设置
基本语法
crontab [选项]
选项说明

进入 crontab 编辑界面。会打开 vim 编辑你的工作
切换编辑器使用
select-editor。
例如我们可以使用nano编辑器他对新手更加的友好
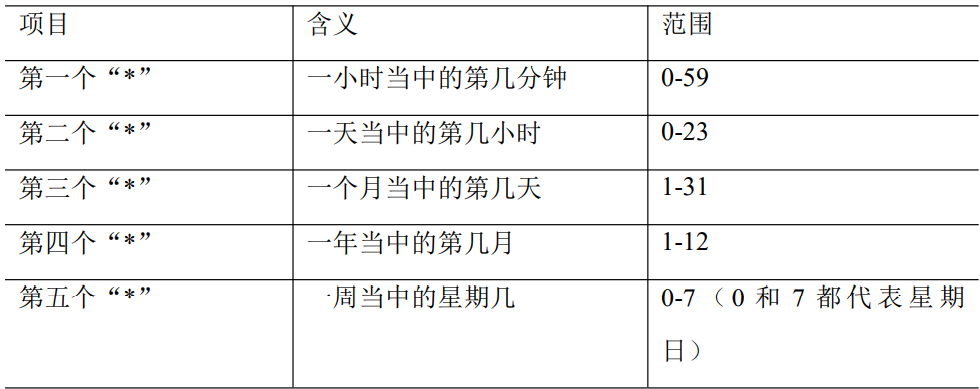
* * * * *执行的任务
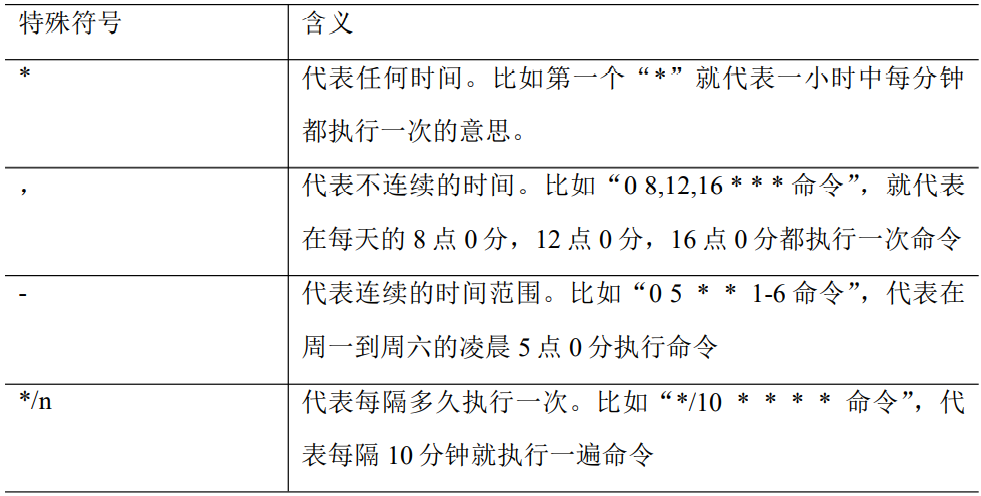
特殊符号
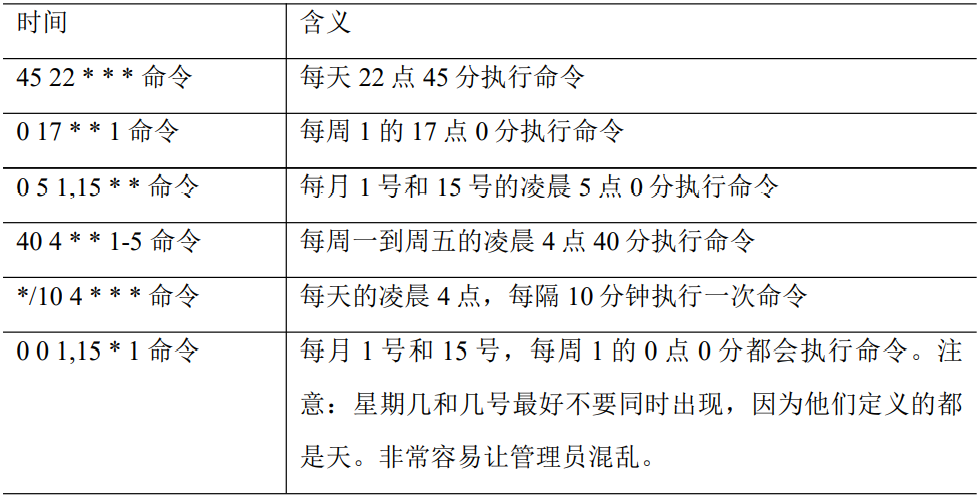
特定时间执行命令
注意:
使用的命令一定要使用完整路径,否则会因为无法读取环境变量而出现部分脚本无法执行问题
如果我们写完定时任务之后想要验证一下是否正确可以借助验证网站:
https://tool.lu/crontab
例如:
每隔 1 分钟,向/root/bailongma.txt 文件中添加一个 11 的数字
*/1 * * * * /bin/echo ”11” >> /root/bailongma.txt
30 21 * * * /usr/local/etc/rc.d/lighttpd restart #每晚的21:30 重启apache
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart #每月1、10、22日的4 : 45重启apache
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart #每周六、周日的1 : 10重启apache
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart #每天18 : 00至23 : 00之间每隔30分钟重启apache
0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart #每星期六的11 : 00 pm重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart #晚上11点到早上7点之间,每隔一小时重启apache
* */1 * * * /usr/local/etc/rc.d/lighttpd restart #每一小时重启apache
0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart #每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart #一月一号的4点重启apache
*/30 * * * * /usr/sbin/ntpdate cn.pool.ntp.org #每半小时同步一下时间
0 */2 * * * /sbin/service httpd restart #每两个小时重启一次apache
50 7 * * * /sbin/service sshd start #每天7:50开启ssh服务
50 22 * * * /sbin/service sshd stop #每天22:50关闭ssh服务
0 0 1,15 * * fsck /home #每月1号和15号检查/home 磁盘
1 * * * * /home/bruce/backup #每小时的第一分执行 /home/bruce/backup这个文件
00 03 * * 1-5 find /home "*.xxx" -mtime +4 -exec rm {} \; #每周一至周五3点钟,在目录/home中,查找文件名为*.xxx的文件,并删除4天前的文件。
30 6 */10 * * ls #每月的1、11、21、31日是的6:30执行一次ls命令
关机重启类命令
在 linux 领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
基本语法
(1)sync (功能描述:将数据由内存同步到硬盘中)
(2)halt (功能描述:停机,关闭系统,但不断电)
因为不断电,所以我们内存中的数据还保存着。我们可以使用这种方式让系统处于一个低水平的维护状态。你可以简单地理解为睡眠模式
(3)poweroff (功能描述:关机,断电)
(3)reboot (功能描述:就是重启,等同于 shutdown -r now)

(4)shutdown [选项] 时间
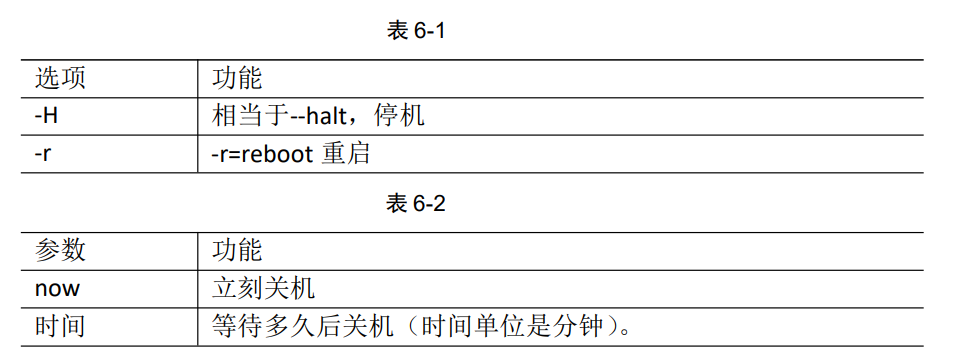
补充选项:
-h/-P关机
注意:Linux 系统中为了提高磁盘的读写效率,对磁盘采取了 “预读迟写”操作方式。当用户保存文件时,Linux 核心并不一定立即将保存数据写入物理磁盘中,而是将数据保存在缓冲区中,等缓冲区满时再写入磁盘,这种方式可以极大的提高磁盘写入数据的效率。但是,也带来了安全隐患,如果数据还未写入磁盘时,系统掉电或者其他严重问题出现,则将导致数据丢失。使用 sync 指令可以立即将缓冲区的数据写入磁盘。
使用
(1)将数据由内存同步到硬盘中
[root@hadoop100 桌面]#sync
(2)重启
[root@hadoop100 桌面]# reboot
(3)停机(不断电)
[root@hadoop100 桌面]#halt
(4)计算机将在 1 分钟后关机,并且会显示在登录用户的当前屏幕中
[root@hadoop100 桌面]#shutdown -h 1
(5)立马关机(等同于 poweroff)
[root@hadoop100 桌面]# shutdown -h now
(6)系统立马重启(等同于 reboot)
[root@hadoop100 桌面]# shutdown -r now
(7)系统取消关机
[root@hadoop100 桌面]# shutdown -c
(8)系统在15点关机
[root@hadoop100 桌面]# shutdown 15:00
(9)reboot相关操作
[root@study ~]# shutdown -h now
立刻关机,其中 now 相当于时间为 0 的状态
[root@study ~]# shutdown -h 20:25
系统在今天的 20:25 分会关机,若在21:25才下达此指令,则隔天才关机
[root@study ~]# shutdown -h +10
系统再过十分钟后自动关机
[root@study ~]# shutdown -r now
系统立刻重新开机
[root@study ~]# shutdown -r +30 'The system will reboot'
再过三十分钟系统会重新开机,并显示后面的讯息给所有在线上的使用者
[root@study ~]# shutdown -k now 'This system will reboot'
仅发出警告信件的参数!系统并不会关机
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/122011.html

