
文章目录
爬虫初体验
首先我们要知道爬虫中最常用的发起请求的第三方库——requests。

requests 的中文文档(https://requests.kennethreitz.org/zh_CN/latest/)
如果我们想在自己的电脑上安装,可以通过在命令行中输入 pip install requests 安装
Requests库
requests.get() 方法
官方文档对他的解释如下:

我们从爬虫的第一步 获取数据 开始,我们来看个例子:
import requests # 导入 requests 模块
res = requests.get('https://wpblog.x0y1.com') # 发起请求
print(res)
# 输出:<Response [200]>
我们使用 requests.get(‘网站地址’) 方法向对应的网站发起了请求,然后我们将返回的结果存到了变量 res 中供后续使用。它的类型是 Response 对象,后面的 200 是状态码,我们后面再细说。
这样我们就发起了一次请求,并将服务器的响应结果存到了变量当中,requests.get() 方法的作用如下图所示:

Response 对象
我们前面通过 requests.get() 方法获取到了网页的数据,作为 Response 对象存到了变量 res,那么我们如何查看它的具体内容呢?
我们先来了解Response对象:

这些还只是Response对象的一部分属性与方法,我们不需要全部掌握,只需要知道以下几个常用的即可:

res.status_code
import requests
res = requests.get('https://wpblog.x0y1.com')
print(res.status_code)
# 输出:200
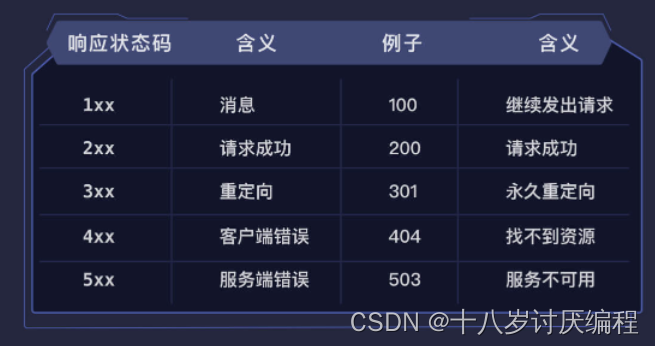
这里的 200 就是响应的状态码,表示请求成功。当请求失败时会有不同的状态码,不同的状态码有不同的含义,常见的状态码如下:
res.text
res.text 返回的是服务器响应内容的字符串形式,也就是文本内容。我们直接看段代码:
import requests
res = requests.get('https://wpblog.x0y1.com')
print(res.text)
上面代码的运行结果(结果太长省略了一部分)是:
<!DOCTYPE html>
<html lang="zh-CN" class="no-js no-svg">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<script>(function(html){html.className = html.className.replace(/\bno-js\b/,'js')})(document.documentElement);</script>
上面是“扇贝编程博客”网站的部分源代码,我们通过浏览器访问该网站获取得的就是它,获取到源代码后浏览器会将其解析成我们最终看到的页面 。博客里文章的数据就在其中。
接下来我们来试试用爬虫下载一个小说——孔乙己,该网址返回的是小说的纯文本格式,源代码和内容是一样的。

如果不熟悉Python的文件操作,此文后有用法解释
下载代码:
import requests
# 获取孔乙己数据
res = requests.get('https://apiv3.shanbay.com/codetime/articles/mnvdu')
# 以写入的方式打开一个名为孔乙己的 txt 文档
with open('孔乙己.txt', 'w') as file:
# 将数据的字符串形式写入文件中
file.write(res.text)
下载的文件将会出现在代码文件所在的目录下
res.content
除了文本内容的下载,爬虫还能下载图片、音频、视频等。我们来看一个下载图片的例子:
import requests
# 获取图片数据
res = requests.get('xxxxxxxxxxxxxxxxxxx')
# 以二进制写入的方式打开一个名为 info.jpg 的文件
with open('info.jpg', 'wb') as file:
# 将数据的二进制形式写入文件中
file.write(res.content)
我们可以看到,和下载小说的步骤几乎一样。区别在于图片是用二进制写入的方式,将数据的二进制形式写入文件当中,而不是字符串形式。
如果你将图片的 res.content 打印出来,结果是像下面这样的一堆看不懂的乱码:
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xdb\x00C\x00\n\x07\x07\t\x07\x06\n\t\x08\t\x0b\x0b\n\x0c\x0f\x19\x10\x0f\x0e\x0e\x0f\x1e\x16\x17\x12\x19$ &%# #"(-90(*6+"#2D26;=@@@&0FKE>J9?@=\xff\xdb\x00C\x01\x0b\x0b\x0b\x0f\r\x0f\x1d\x10\x10\x1d=)#)==================================================\xff\xc2\x00\x11\x08\x02\xa3\x04e\x03\x01\x11\x00\x02\x11\x01\x03\x11\x01
上面的乱码其实是图片的二进制编码,当我们用错误的方式打开,比如用文本形式打开,就会出现如上所示的乱码。
所以 res.text 和 res.content 的区别是:res.text 用于文本内容的获取、下载,res.content 用于图片、音频、视频等二进制内容的获取、下载。
res.encoding
编码是信息从一种形式或格式转换为另一种形式的过程,常见的编码方式有 ASCII、GBK、UTF-8 等。如果用和文件编码不同的方式去解码,我们就会得到一些乱码。
编码发展史
在说爬虫的编码之前,我们先聊一聊编码的发展史。
我们都知道,计算机的底层是二进制。也就是说,计算机只认识 0 和 1。既然如此,计算机是如何展示文字、符号等信息的呢?
聪明的计算机科学家们想到了编码,将数字和文字、符号一一对应即可。比如 0000 对应 a,0001 对应 b,0010 对应 c(举个例子,实际上并不是这样对应的)。
因为英文字母比较少,加上常用的符号等,总共也就 100 多个。计算机科学家们用一个字节中的 7 位(总共 8 位)定义了一套编码,总共 128(2 的 7 次方)个字符,这就是 ASCII 编码。
随着科技的发展,计算机进入了欧洲国家。128 个字符对美国来说是够用的,但欧洲一些国家的语言,比如法语中,字母上方有注音符号,128 个字符就不够用了。因此欧洲国家决定将最后一个闲置的位也利用上,这样欧洲的编码就有 256(2 的 8 次方)个字符了。
但是不同的国家有不同的字母,这就导致前 128 个字符是一样的,后 128 个字符在不同的国家是不一样的。
不久后,计算机便来到了中国。中国的汉字可是有 10 万多个,256 个是远远不够的。中国计算机科学家们便重新定义了一套编码,也就是 GB2312,这套编码包含了 6763 个常用汉字和一些常用符号等。之后为了扩展能显示的汉字内容,还推出了 GBK 等编码标准。
你可能也发现问题了,每个国家都有自己的编码,还都不一样。发封电子邮件给外国人,在他们看来就都是乱码,这可怎么行!
于是,Unicode(统一码)便出现了。Unicode 是一个很大的集合,现在的规模可以容纳 100 多万个符号,并且每个符号的编码都不一样。
但是 Unicode 有个缺点,就是占用字节过多。英文字母本来只需要一个字节就够了,现在为了统一得用 3、4 个字节,很是浪费!因此导致 Unicode 在很长一段时间内无法推广,直到互联网的出现。
聪明的计算机科学家又想到了新的方法,推出了 UTF-8 编码,UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用 1~4 个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 即解决了乱码问题,也解决了字节浪费的问题,是现在最常用的编码方式。

res.encoding 就是爬虫获取到数据的编码格式,requests 库会根据内容推测编码格式是什么,然后将 res.encoding 设成推测的格式,在访问 res.text 时使用该格式解码。
当推测的格式错误时,即出现乱码时,就需要我们手动给 res.encoding 赋值成正确的编码。我们来看下面的例子:
import requests
res = requests.get('https://www.baidu.com')
print(res.text)
将结果打印出来之后从中我们可以看到类似 更多产å 的乱码,它们其实是中文被错误解码导致的。我们来看看 requests 库推测的编码格式是什么:
import requests
res = requests.get('https://www.baidu.com')
print(res.encoding)
# 输出:ISO-8859-1
我们可以看到,requests 库将编码错误地推测成了 ISO-8859-1 格式。国内网站的编码格式一般都是 UTF-8、GBK 或 GB2312。
上述代码中网站的正确编码格式其实是 UTF-8,我们需要手动将编码修改成 UTF-8,便能显示正确的内容了。
附:文件操作
open() 函数是 Python 中的内置函数,用于打开文件,返回值是一个 file 对象。
open() 函数接收的第一个参数为文件名,第二个参数为文件打开模式。打开模式默认为 r,是 read 的缩写,表示只读模式。即只能读取内容,不能修改内容。
常用的打开模式有 :
- w(write,只写模式)
- b(binary,二进制模式)
- a(append,追加模式,表示在文件末尾写入内容,不会从头开始覆盖原文件)。
Tips:在 w 和 a 模式下,如果你打开的文件不存在,那么 open() 函数会自动帮你创建一个。
这些打开模式还能两两组合,比如:rb 表示以二进制格式打开文件用于读取,wb 表示以二进制格式打开文件用于写入,ab 表示以二进制格式打开文件用于追加写入。
需要注意的是,使用 open() 函数打开文件,操作完毕后,最后一定要调用 file 对象的 close() 方法关闭该文件。所以一般我们像下面这样读写文件:
# 读取文件
file = open('文本.txt') # 打开模式默认为 r,可省略
print(file.read()) # 调用 read() 方法读取文件内容
file.close() # 关闭文件
# 写入文件
file = open('文本.txt', 'w') # 写入模式
file.write('xxxx') # 调用 write() 方法写入内容
file.close() # 关闭文件
为了避免忘记调用 close() 方法关闭文件,导致资源占用、文件内容丢失等问题,推荐使用 with ... as ... 语法,它在最后会自动帮你关闭文件。
我们看个例子对比一下:
# 普通写法
file = open('文本.txt', 'w') # 写入模式
file.write('xxxx') # 调用 write() 方法写入内容
file.close() # 关闭文件
# 使用 with ... as ... 写法
with open('文本.txt', 'w') as file:
file.write('xxxx')
可以看到,使用 with … as … 语法后,关闭文件的操作就可以省略了。不仅代码简洁了,也避免了忘记关闭文件的问题。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/122156.html

