
单向链表
链表(linked list)是一种在物理上非连续、非顺序的数据结构,由若干节点(node)所组成。
单向链表的每一个节点又包含两部分,一部分是存放数据的变量data,另一部分是指向下一个节点的指针next。
链表的第一个节点被称为头节点,最后一个节点被称为尾节点,尾节点的next指针指向空
如图所示:
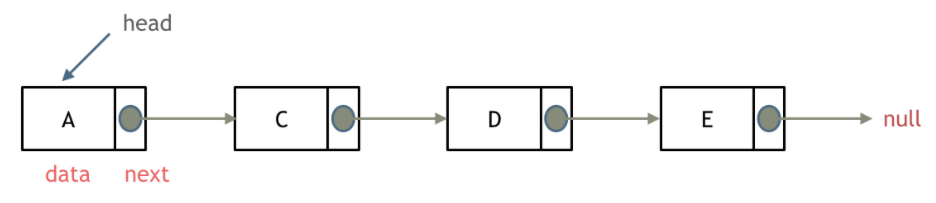

注意:与数组按照索引来随机查找元素不同,对于链表的其中一个节点我们只能通过他的next指针查找到他的下一个节点。
双向链表
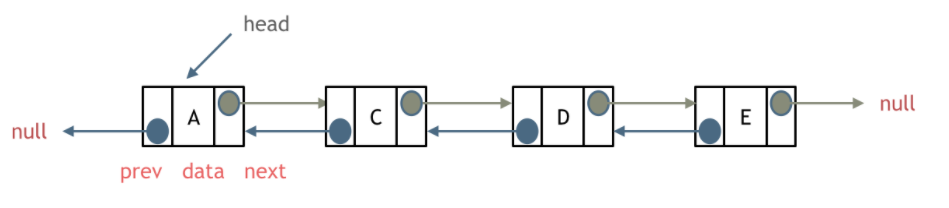
双向链表也叫双向表,是链表的一种,它由多个结点组成,每个结点都由一个数据域和两个指针域组成,数据域用来存储数据,其中一个指针域用来指向其后继结点,另一个指针域用来指向前驱结点。链表的头结点的数据域不存储数据,指向前驱结点的指针域值为null,指向后继结点的指针域指向第一个真正存储数据的结点。
双链表 既可以向前查询也可以向后查询。
如图所示:
环形链表
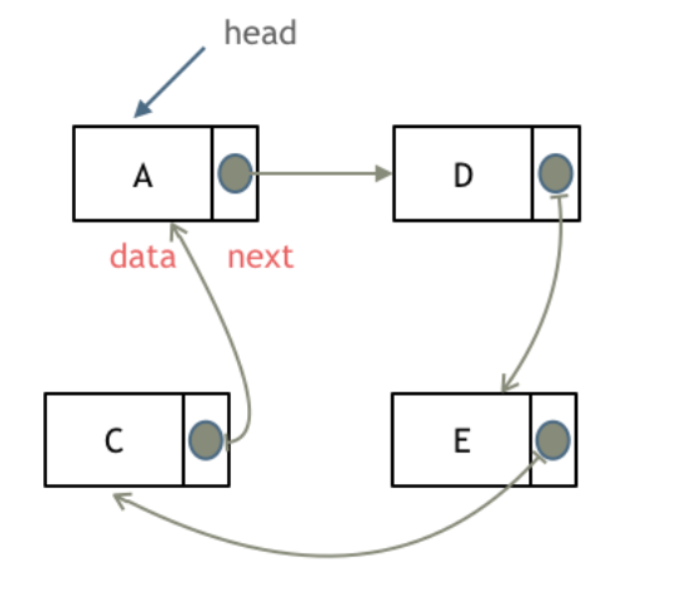
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
如图所示:
链表的定义
单向链表:
java的定义方法:
public class ListNode {
// 结点的值
int val;
// 下一个结点
ListNode next;
// 节点的构造函数(无参)
public ListNode() {
}
// 节点的构造函数(有一个参数)
public ListNode(int val) {
this.val = val;
}
// 节点的构造函数(有两个参数)
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
}
python的定义方式:
class ListNode:
def __init__(self, val, next=None):
self.val = val
self.next = next
链表的存储方式
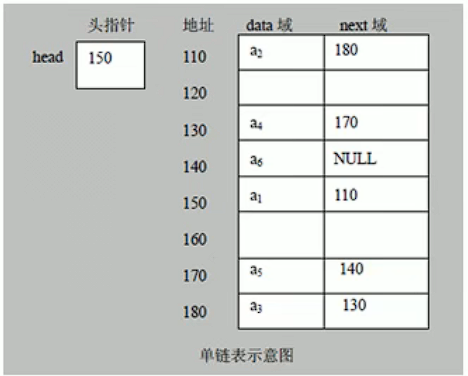
如果说数组在内存中的存储方式是顺序存储,那么链表在内存中的存储方式则是随机存储。
数组在内存中占用了连续完整的存储空间。而链表则采用了见缝插针的方式(实际上分配机制取决于操作系统的内存管理),链表的每一个节点分布在内存的不同位置,依靠next指针关联起来。
好处:可以灵活有效的利用零散的碎片空间。
如图是单链表的存储方式:
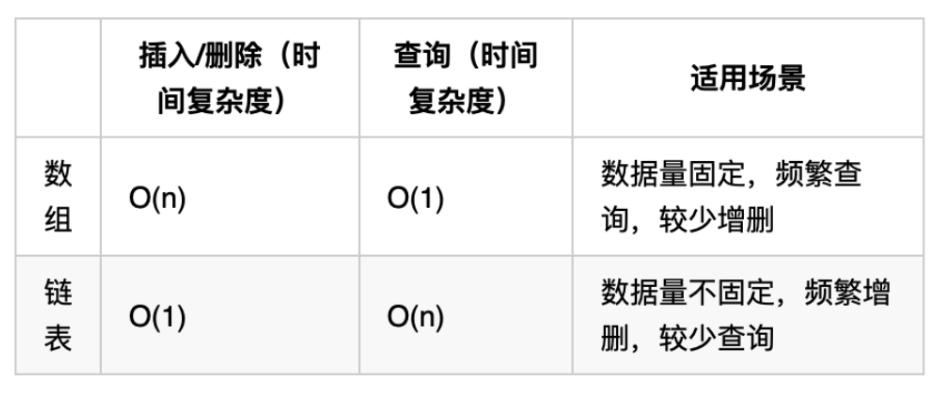
数组与链表的性能分析
①get(int i):每一次查询,都需要从链表的头部开始,依次向后查找,随着数据元素N的增多,比较的元素越多,时间复杂度为O(n)
②insert(int i,T t):每一次插入,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n);
③remove(int i):每一次移除,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n)
相比较顺序表,链表插入和删除的时间复杂度虽然一样,但仍然有很大的优势,因为链表的物理地址是不连续的,它不需要预先指定存储空间大小,或者在存储过程中涉及到扩容等操作,同时它并没有涉及的元素的交换。
相比较顺序表,链表的查询操作性能会比较低。因此,如果我们的程序中查询操作比较多,建议使用顺序表,增删操作比较多,建议使用链表。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/122260.html

