
大数据量下,身份证的查询优化
这里是测试练习采用select *,实际场景中还是使用所有字段的形式,这样也可以提高效率
方式一:身份证分别正向、逆向存储,使用like逆序模糊查询,满足最左匹配原则,索引不会失效
- user表数据
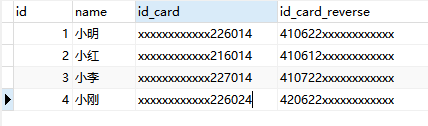
- 添加普通索引


- 查询后六位
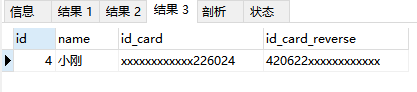
select * from user where id_card_reverse like reverse("%226014");

- 查询后五位
select * from user where id_card_reverse like reverse("%26014");

- 查询后四位
select * from user where id_card_reverse like reverse("%6024");
方式二:身份证号拆分存储
存储身份证有标识性性的后六位
- 数据表user_test
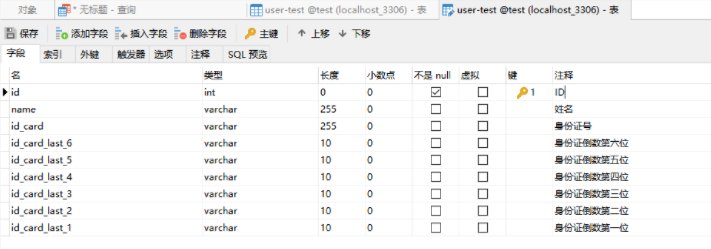

- 添加组合索引

- 查询身份证后两位
select * from user_test where id_card_last_2 = '1' and id_card_last_1 = '4';

- 查询身份证后六位
select * from user_test where id_card_last_6 = '2' and id_card_last_5 = '2' and id_card_last_4 = '6'
and id_card_last_3 = '0' and id_card_last_2 = '1' and id_card_last_1 = '4' ;

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/122953.html

