

1.输入日期, 判断这一天是这一年的第几天?
import datetime
def dayofyear():
year = input("请输入年份: ")
month = input("请输入月份: ")
day = input("请输入天: ")
date1 = datetime.date(year=int(year),month=int(month),day=int(day))
date2 = datetime.date(year=int(year),month=1,day=1)
return (date1-date2).days+1
2 请反转字符串 “aStr”
print("aStr"[::-1])
3 将字符串 “k:1 |k1:2|k2:3|k3:4”,处理成字典
str1 = "k:1|k1:2|k2:3|k3:4"
def str2dict(str1):
dict1 = {}
for iterms in str1.split('|'):
key,value = iterms.split(':')
dict1[key] = value
return dict1
#字典推导式
d = {k:int(v) for t in str1.split("|") for k, v in (t.split(":"), )}
4.请按alist中元素的age由大到小排序
alist = [{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}]
def sort_by_age(list1):
return sorted(alist,key=lambda x:x['age'],reverse=True)
5 写一个列表生成式,产生一个公差为11的等差数列
print([x*11 for x in range(10)])
6 下面代码的输出结果将是什么?
list = ['a','b','c','d','e']
print(list[10:])
代码将输出[],不会产生IndexError错误,就像所期望的那样,尝试用超出成员的个数的index来获取某个列表的成员。例如,尝试获取list[10]和之后的成员,会导致IndexError。然而,尝试获取列表的切片,开始的index超过了成员个数不会产生IndexError,而是仅仅返回一个空列表。这成为特别让人恶心的疑难杂症,因为运行的时候没有错误产生,导致Bug很难被追踪到。
list = ['a','b','c','d','e']
print(list[10])
IndexError: list index out of range
7 给定两个列表,怎么找出他们相同的元素和不同的元素?
list1 = [1,2,3]
list2 = [3,4,5]
set1 = set(list1)
set2 = set(list2)
print(set1 & set2)
print(set1 ^ set2)
8.请写出一段python代码实现删除list里面的重复元素?
l1 = ['b','c','d','c','a','a']
l2 = list(set(l1))
print(l2)
9.python中内置的数据结构有几种?
a. 整型 int、 浮点型 float、 复数 complex
b. 字符串 str、 列表 list、 元组 tuple
c. 字典 dict 、 集合 set
10 python如何实现单例模式?请写出两种实现方式?
单例模式:只有一个实例(对象)当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
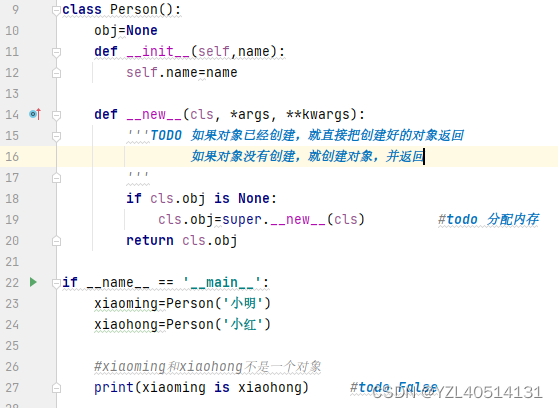
11.反转一个整数,例如-123 –> -321
class Solution(object):
def reverse(self,x):
if -10<x<10:
return x str_
x = str(x)
if str_x[0] !="-":
str_x = str_x[::-1]
x = int(str_x)
else: str_x = str_x[1:][::-1]
x = int(str_x)
x = -x
return x if -2147483648<x<2147483647 else 0
if __name__ == '__main__':
s = Solution()
reverse_int = s.reverse(-120)
print(reverse_int)
12 设计实现遍历目录与子目录,抓取.pyc文件
import os
def get_files(dir,suffix):
res = []
for root,dirs,files in os.walk(dir):
for filename in files:
name,suf = os.path.splitext(filename)
if suf == suffix:
res.append(os.path.join(root,filename))
print(res)
get_files("./",'.pyc')
13 一行代码实现1-100之和
count = sum(range(0,101))
print(count)
14 is和==有什么区别?
is:比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象。是否指向同一个内存地址
== : 比较的两个对象的内容/值是否相等,默认会调用对象的eq()方法
15 交换两个变量的值
a, b = b, a
16 简述read、readline、readlines的区别?
read 读取整个文件
readline 读取下一行
readlines 读取整个文件到一个迭代器以供我们遍历
详细文章查看:https://blog.csdn.net/YZL40514131/article/details/125609673
17 Python中pass语句的作用是什么?
在编写代码时只写框架思路,具体实现还未编写就可以用pass进行占位,是程序不报错,不会进行任何操作。
18 什么是lambda函数? 有什么好处?
lambda 函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数
1.lambda函数比较轻便,即用即仍,很适合需要完成一项功能,但是此功能只在此一处使用,连名字都很随意的情况下
2.匿名函数,一般用来给filter,map这样的函数式编程服务
3.作为回调函数,传递给某些应用,比如消息处理
19 Python中yield的用法?
yield就是保存当前程序执行状态。 你用for循环的时候,每次取一个元素的时候就会计算一次。用yield的函数叫generator,和iterator一样,它的好处是不用一次计算所有元素,而是用一次算一次,可以节省很多空间,generator每次计算需要上一次计算结果,所以用yield,否则一return,上次计算结果就没了
20 Python异步使用场景有那些?
1、 不涉及共享资源,获对共享资源只读,即非互斥操作
2、 没有时序上的严格关系
3、 不需要原子操作,或可以通过其他方式控制原子性
4、 常用于IO操作等耗时操作,因为比较影响客户体验和使用性能
5、 不影响主线程逻辑
21 可变类型和不可变类型
可变类型—>不可 hash 类型
列表 list
字典 dict
集合 set
不可变类型–>可hash类型
整数 int
字符串 str
浮点数 float
布尔类型 bool
1,当进行修改操作时,可变类型传递的是内存中的地址,也就是说,直接修改内存中的值,并没有开辟新的内存。
2,不可变类型被改变时,并没有改变原内存地址中的值,而是开辟一块新的内存,将原地址中的值复制过去,对这块新开辟的内存中的值进行操作。
>>> str1='qwe'
>>> id(str1)
1285056283760
>>> str1='qwe'+'tyu'
>>> id(str1)
1285058827120
>>> list=[1,2,3,4,5]
>>> id(list)
1285058745344
>>> list.append(6)
>>> id(list)
1285058745344
22 字典推导式:
a、请运用字典推导式,把字符串 “k:1 |k1:2|k2:3|k3:4”,处理成字典
str="k:1 |k1:2|k2:3|k3:4"
d={item.split(":")[0]:int(item.split(":")[1]) for item in str.split("|")}
print(d)


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123210.html

