
提示
Elasticsearch 的底层是开源库 Lucene。但是没法直接使⽤ Lucene,必须⾃⼰写代码去调⽤它的接⼝。
思考
我们如何对接 Elasticsearch服务端?
解决⽅案
Haystack
一、Haystack介绍和安装配置
1、Haystack介绍
a、Haystack 是在Django中对接搜索引擎的框架,搭建了⽤户和搜索引擎之间的沟通桥梁。
我们在Django中可以通过使⽤ Haystack 来调⽤ Elasticsearch 搜索引擎
b、Haystack 可以在不修改代码的情况下使⽤不同的搜索后端(⽐如Elasticsearch、Whoosh、Solr等等)
2、Haystack安装
$ pip install django-haystack
$ pip install elasticsearch==2.4.1
3、Haystack注册应⽤和路由
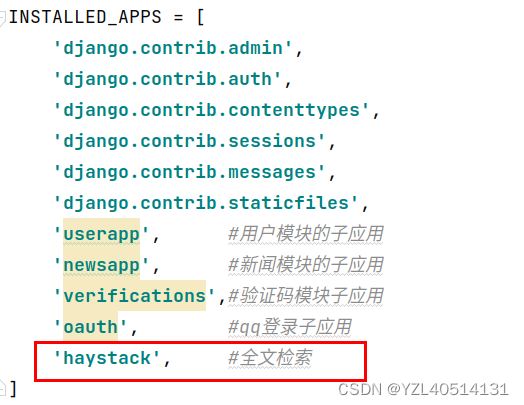
根路由
re_path(r'^search/', include('haystack.urls')),
4、Haystack配置
在配置⽂件中配置Haystack为搜索引擎后端
# Haystack
HAYSTACK_CONNECTIONS = {
'default':
{ 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://192.168.17.129:9200/', # Elasticsearch服务器ip地址,端⼝号固定为9200
'INDEX_NAME': 'mangguo_indexes', # Elasticsearch建⽴的索引库的名称
},
}
# 当添加、修改、删除数据时,⾃动⽣成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
重要提示:
HAYSTACK_SIGNAL_PROCESSOR 配置项保证了在Django运⾏起来后,有新的数据产⽣时,Haystack仍然可以让Elasticsearch实时⽣成新数据的索引
二、Haystack建⽴数据索引
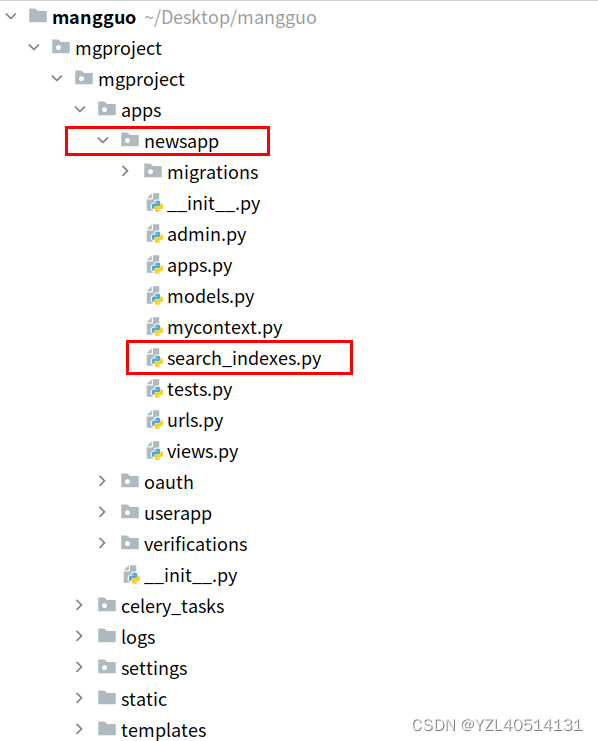
1、创建索引类
a、通过创建索引类,来指明让搜索引擎对哪些字段建⽴索引,也就是可以通过哪些字段的关键字来检索数据。
b、本项⽬中对article信息进⾏全⽂检索,所以在newsapp应⽤中新建search_indexes.py⽂件(文件名是固定的),⽤于存放索引类。
from haystack import indexes
from .models import Article
class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
"""Article索引数据模型类"""
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
"""返回建⽴索引的模型类"""
return Article
def index_queryset(self, using=None):
"""返回要建⽴索引的数据查询集"""
return self.get_model().objects.order_by('-id')
ArticleIndex
- 在ArticleIndex建⽴的字段,都可以借助Haystack由Elasticsearch搜索引擎查询。
- 其中text字段我们声明为document=True,表名该字段是主要进⾏关键字查询的字段
- text字段的索引值可以由多个数据库模型类字段组成,具体由哪些模型类字段组成,我们⽤use_template=True表示后续通过模板来指明。
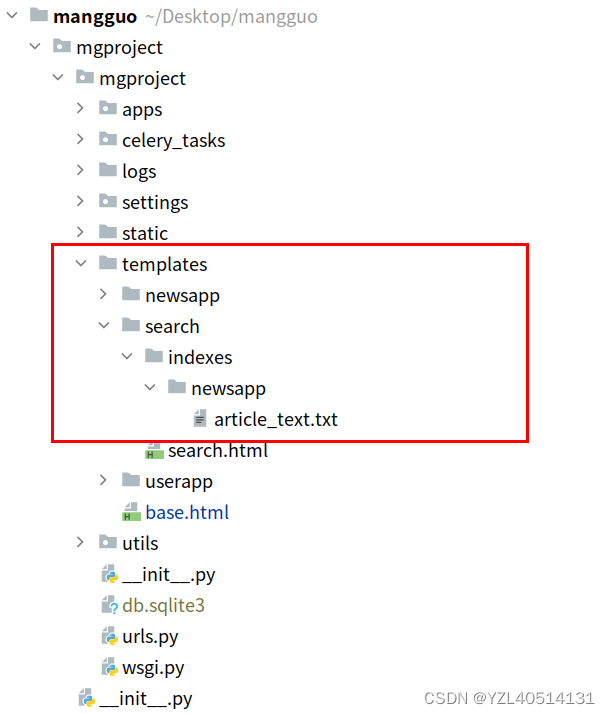
2、创建text字段索引值模板⽂件
- 在templates⽬录中创建text字段使⽤的模板⽂件
- 具体在
templates/search/indexes/newsapp/article_text.txt⽂件中定义(包名和文件名是固定的)

{{object.title}}
{{object.content}}
-
模板⽂件说明:当将关键词通过text参数名传递时
- 此模板指明Article的title、content作为text字段的索引值来进⾏关键字索引查询。。
3、⼿动⽣成初始索引
python manage.py rebuild_index

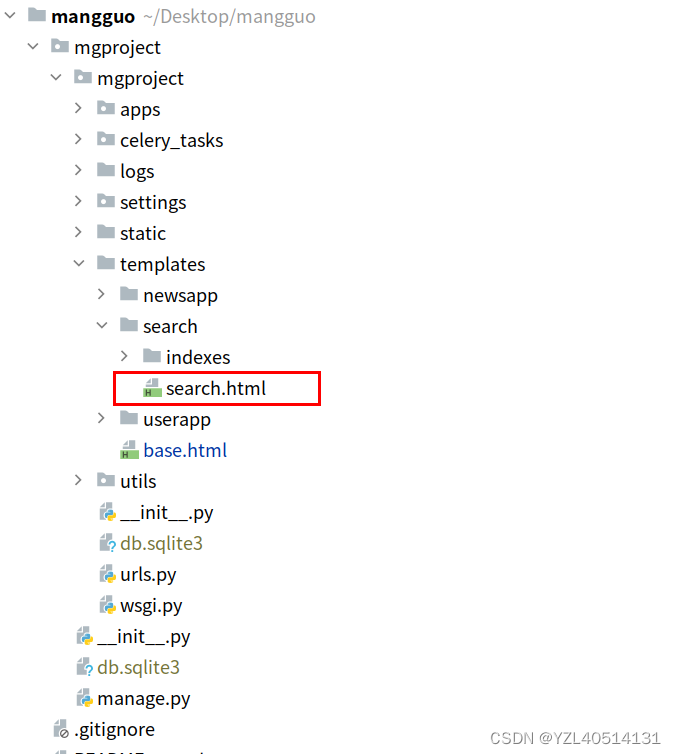
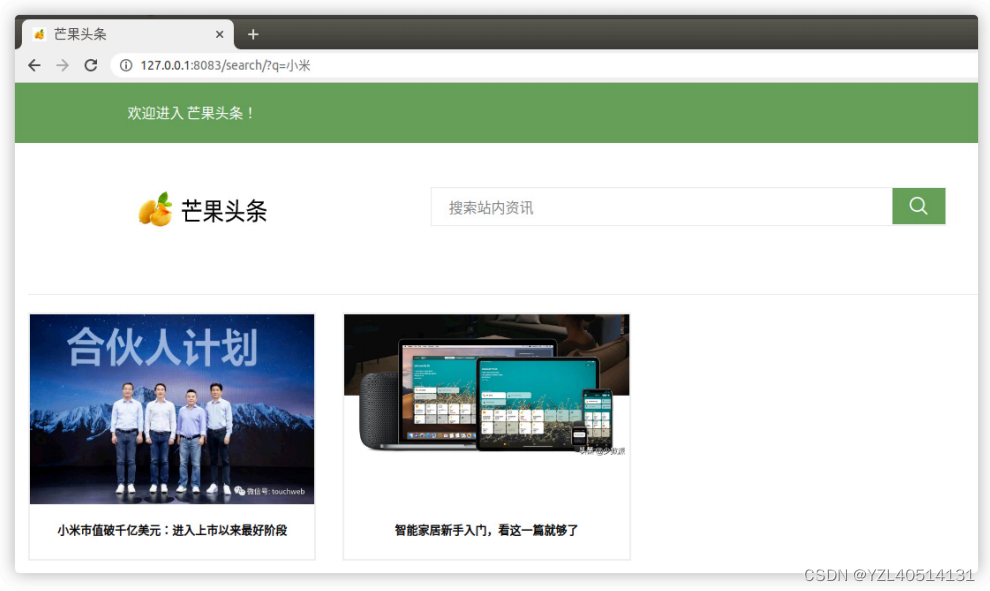
三、全⽂检索测试
1、准备商品搜索结果⻚⾯
templates/search/search.html
search.html⽂件作⽤就是接收和渲染全⽂检索的结果。
2、渲染⽂章搜索结果
请求⽅法:GET
请求地址:/search/
请求参数:q
query:搜索关键字
paginator:分⻚paginator对象
page:当前⻚的page对象(遍历page中的对象,可以得到result对象)
result.object: 当前遍历出来的Article对象。
<ul class="row list-products auto-clear equal-container product-grid">
{% for result in page.object_list %}
<li class="product-item col-lg-3 col-md-4 col-sm-6 col-xs-6 col-ts-12 style-1">
<div class="product-inner equal-element" >
<div class="product-thumb" style="height: 220px;">
<div class="thumb-inner">
<a href="#">
<img src="{{ result.object.default_img.url }}" alt="img">
</a>
</div>
</div>
<div class="product-info">
<h5 class="product-name product_title" >
<a href="#">{{ result.object.title }}</a>
</h5>
</div>
</div>
</li>
{% else %}
<P>未查询到结果</P>
{% endfor %}
</ul>
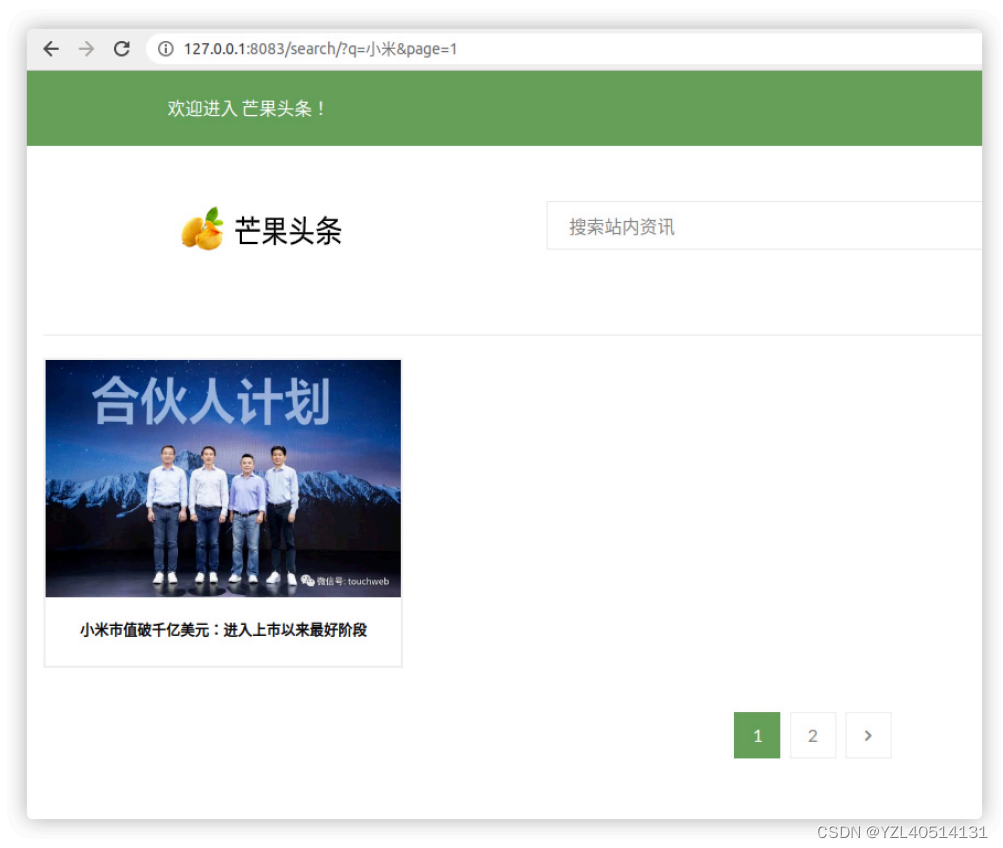
3、Haystack搜索结果分⻚
1、设置每⻚返回数据条数
# dev.py
# 设置搜索结果⻚⾯每⻚显示记录数
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 1

2、准备搜索⻚分⻚器
<div class="pagination clearfix style2">
<div class="nav-link">
{% if page.has_previous() %}
<a href="/search/?q={{ query }}&page={{ page.number - 1 }}" class="page-numbers"><i class="icon fa fa-angle-left" aria-hidden="true"></i></a>
{% endif %}
{% for num in range(1,page.paginator.num_pages + 1) %}
<a href="/search/?q={{ query }}&page={{ num }}" class="page-numbers {% if page.number == num %}current{% endif %}">{{ num }}</a>
{% endfor %}
{% if page.has_next() %}
<a href="/search/?q={{ query }}&page={{ page.number + 1 }}" class="page-numbers"><i class="icon fa fa-angle-right" aria-hidden="true"></i></a>
{% endif %}
</div>
</div>
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123296.html

