
客户端发送多个请求到服务器,服务器处理请求,有一些可能要与数据库进行交互,服务器处理完毕后,再将结果返回给客户端。
这种架构模式对于早期的系统相对单一,并发请求相对较少的情况下是比较适合的,成本也低。但是随着信息数量的不断增长,访问量和数据量的飞速增长,以及系统业务的复杂度增加,这种架构会造成服务器相应客户端的请求日益缓慢,并发量特别大的时候,还容易造成服务器直接崩溃。很明显这是由于服务器性能的瓶颈造成的问题,那么如何解决这种情况呢?
我们首先想到的可能是升级服务器的配置,比如提高CPU执行频率,加大内存等提高机器的物理性能来解决此问题,但是我们知道摩尔定律的日益失效,硬件的性能提升已经不能满足日益提升的需求了。最明显的一个例子,天猫双十一当天,某个热销商品的瞬时访问量是极其庞大的,那么类似上面的系统架构,将机器都增加到现有的顶级物理配置,都是不能够满足需求的。那么怎么办呢?
上面的分析我们去掉了增加服务器物理配置来解决问题的办法,也就是说纵向解决问题的办法行不通了,那么横向增加服务器的数量呢?这时候集群的概念产生了,单个服务器解决不了,我们增加服务器的数量,然后将请求分发到各个服务器上,将原先请求集中到单个服务器上的情况改为将请求分发到多个服务器上,将负载分发到不同的服务器,也就是我们所说的负载均衡。
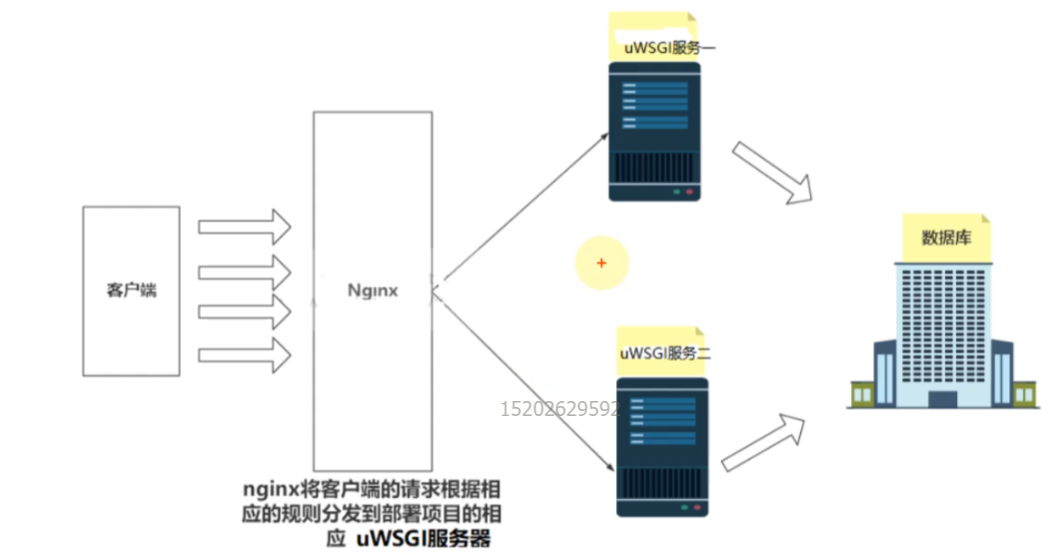

nginx/tengine处理的是静态请求,假设客户端发送了100个请求,其中有20个请求时静态请求,80个是动态请求;静态请求nginx会自己处理,通过location进行匹配,匹配成功之后直接找到目录,进行访问;80个动态请求可能会请求后端python写的程序(flask写的resource资源),而nginx不会直接处理,通过反向代理转给其中的一台uwsgi服务器(uwsgi的服务器就是跑的我们写的python项目,当然还会去数据库进行一些相关的操作)操作完成的数据,也就是后端的响应会返回到nginx,nginx收到的数据会返回到我们的客户端,这就是动态请求。
那么问题来了,如果这80个请求全部交给一台uwsgi服务器来处理,那么单台服务器的压力比较大,处理请求非常慢;其实就是选择错了负载均衡算法导致的。
负载均衡完美的解决了单个服务器硬件性能瓶颈的问题,但是随着而来的如何实现负载均衡呢?客户端怎么知道要将请求发送到那个服务器去处理呢?
Nginx 服务器是介于客户端和服务器之间的中介,通过上一篇博客讲解的反向代理的功能,客户端发送的请求先经过 Nginx ,然后通过 Nginx 将请求根据相应的规则分发到相应的服务器。
主要配置指令为上一讲的 uwsgi_pass 指令以及 upstream 指令。负载均衡主要通过专门的硬件设备或者软件算法实现。通过硬件设备实现的负载均衡效果好、效率高、性能稳定,但是成本较高。而通过软件实现的负载均衡主要依赖于均衡算法的选择和程序的健壮性。均衡算法又主要分为两大类:
静态负载均衡算法:主要包括轮询算法、基于比率的加权轮询算法或者基于优先级的加权轮询算法。
动态负载均衡算法:主要包括基于任务量的最少连接优化算法、基于性能的最快响应优先算法、预测算法及动态性能分配算法等。
静态负载均衡算法在一般网络环境下也能表现的比较好,动态负载均衡算法更加适用于复杂的网络环境。
①、普通轮询算法
这是Nginx 默认的轮询算法。
先将项目配置到uwsgi1和uwsgi2服务器中,并且运行起来。app.py为运行文件

修改run.ini文件
1 [uwsgi]
2 socket =0.0.0.0:5000
3 chdir = /home/py_project/flask_8/
4 wsgi-file = /home/py_project/flask_8/app.py
5 callable = app
6 processes = 1
7 threads = 8
8 stats = 0.0.0.0:9191
9 pidfile = /home/uwsgi.pid
10 daemonize = /home/py_project/flask_8/logs/uwsgi.log
11 lazy-apps = true
12 master-fifo = /opt/mt-search/web-service/mfifo
13 touch-chain-reload = true
启动uwsgi服务器
uwsgi --ini run.ini
查看uwsgi进程
ps -aux | grep uwsgi
其中第一个为管理进程,永远只有一个
[root@mylinux2 flask_8]# ps -aux | grep uwsgi
root 2106 0.0 0.2 165244 7672 ? S 3月17 0:16 /usr/local/python-3.8/bin/uwsg --ini run.ini
root 13427 0.0 0.1 690060 6068 ? Sl 3月18 0:00 /usr/local/python-3.8/bin/uwsg --ini run.ini
root 21712 0.0 0.0 112824 980 pts/1 R+ 15:52 0:00 grep --color=auto uwsgi
我拷贝第一台服务器中的项目文件到第二台中,目的是方便、不用配置其他的内容
scp -r py_project/ root@192.168.17.4:/home
-r:递归,将py_project目录下的所有目录和文件都拷贝
root:用户名
192.168.17.4:目标服务器ip地址
/home:将文件拷贝到哪里
这样我就有2台uwsgi服务器了,将2台uwsgi服务器启动起来
有了uwsgi服务器,接下来就需要配置nginx
在nginx.conf文件中进行配置location
不能配置root目录了,毫无意义,因为运行的是python文件,需要反向代理uwsgi_pass
include:uwsgi_params:引入uwsgi_params文件
如果想要引入其他配置文件中的内容必须使用include引入
location / {
include uwsgi_params; #导入文件
uwsgi_pass mycom; #基于uwsgi协议
#proxy_pass 基于http协议
}
proxy_pass 基于http协议
uwsgi_pass mycom 基于uwsgi协议(我们配置的socket就是uwsgi的协议)
配置负载服务器集群:当超过1个服务器,一定要配置upstream;而且upstream是在server外面配置的,不能在里面配置;mycom是随便写的
端口是run.ini中配置的端口
upstream mycom{ # 普通轮询算法
server 192.168.17.3:5000; #负载服务器集群
server 192.168.17.4:5000;
}
配置完成后,
nginx -t
检测文件是否配置正确
总的配置如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream mycom{ # 普通轮询算法
server 192.168.17.3:5000; #负载服务器集群
server 192.168.17.4:5000;
}
server {
listen 80;
server_name www.server1.com;
location / {
include uwsgi_params; #导入文件
uwsgi_pass mycom; #基于uwsgi协议
#proxy_pass 基于http协议
}
}
}
此时,客户端已经没有办法再去访问uwsgi服务器了,只能访问nginx服务器,nginx服务器的端口是80
不断的访问:http://192.168.17.3/t,得到响应结果如下,
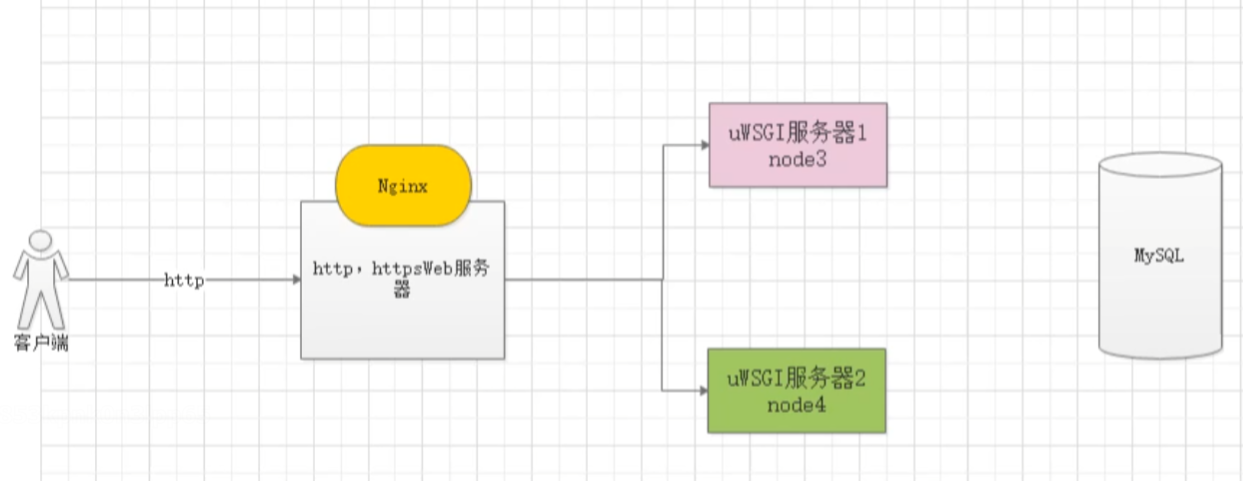
请求原理图如下:
upstream mycom{ # 普通轮询算法
server 192.168.17.3:5000; #负载服务器集群
server 192.168.17.4:5000;
}
②、基于比例加权轮询
上述两台uWSGI服务器基本上是交替进行访问的。但是这里我们有个需求:
需求:由于uWSGI一服务器的配置更高点,我们希望该服务器接受更多的请求,而 uWSGI二 服务器配置低,希望其处理相对较少的请求。
那么这时候就用到了加权轮询机制了。
nginx.conf 配置文件如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream mycom{ #加权轮询算法
server 192.168.17.3:5000 weight=2; #负载服务器集群
server 192.168.17.4:5000 weight=1;
}
server {
listen 80;
server_name www.server1.com;
location / {
include uwsgi_params; #导入文件
uwsgi_pass mycom; #基于uwsgi协议
#proxy_pass 基于http协议
}
}
}
③、基于IP路由负载
我们知道一个请求在经过一个服务器处理时,服务器会保存相关的会话信息,比如session,但是该请求如果第一个服务器没处理完,通过nginx轮询到第二个服务器上,那么这个服务器是没有会话信息的。
最典型的一个例子:用户第一次进入一个系统是需要进行登录身份验证的,首先将请求跳转到uWSGI1服务器进行处理,登录信息是保存在uWSGI1 上的,这时候需要进行别的操作,那么可能会将请求轮询到第二个uWSGI2上,那么由于uWSGI2 没有保存会话信息,会以为该用户没有登录,然后继续登录一次,如果有多个服务器,每次第一次访问都要进行登录,这显然是很影响用户体验的。
这里产生的一个问题也就是集群环境下的 session 共享,如何解决这个问题?
通常由两种方法:
第一种方法是选择一个中间件,将登录信息保存在一个中间件上,这个中间件可以为 Redis 这样的数据库。那么第一次登录,我们将session 信息保存在 Redis 中,跳转到第二个服务器时,我们可以先去Redis上查询是否有登录信息,如果有,就能直接进行登录之后的操作了,而不用进行重复登录。
第二种方法是根据客户端的IP地址划分,每次都将同一个 IP 地址发送的请求都分发到同一个 uWSGI 服务器,那么也不会存在 session 共享的问题。
而 nginx 的基于 IP 路由负载的机制就是上诉第二种形式。大概配置如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream mycom{ #ip的哈希算法
ip_hash;
server 192.168.17.3:5000; #负载服务器集群
server 192.168.17.4:5000;
}
server {
listen 80;
server_name www.server1.com;
location / {
include uwsgi_params; #导入文件
uwsgi_pass mycom; #基于uwsgi协议
#proxy_pass 基于http协议
}
}
}
客户端访问http://192.168.17.3/t,永远访问的同一台uwsgi服务器
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123375.html

