
2022-09-20更新了文章
一、Queue理解
从一个线程向另一个线程发送数据最安全的方式可能就是使用queue库中的队列了。创建一个被多个线程共享的Queue对象,这些线程通过使用put()和get()操作来向队列中添加或者删除元素。Queue对象已经包含了必要的锁,所以你可以通过它在多个线程间多安全地共享数据。

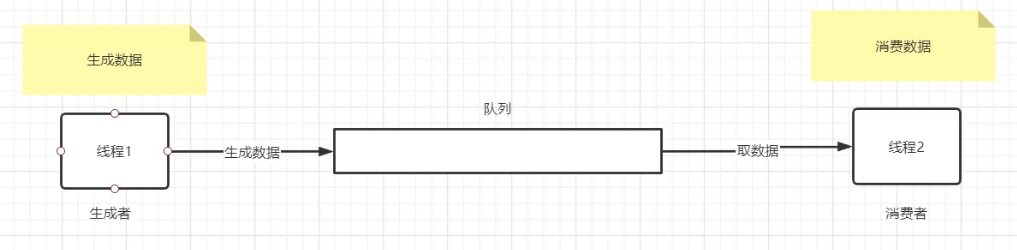
二、原理图
三、生产者和消费者
生产者:生产数据放到队列中
消费者:从队列中获取数据
生产者和消费者都可以有多个
四、代码
#创建一个队列,1代表maxSize
q=queue.Queue(1) #创建一个先进先出的队列
#q=queue.LifoQueue #创建一个后进先出的队列
#q=queue.PriorityQueue #优先级的队列
#定义生产者线程
class Producer(threading.Thread):
def run(self):
global q
count=0
while True:
time.sleep(5)
print("生产线程开始生产数据")
count+=1
msg="产品{}".format(count)
q.put(msg) #默认阻塞
print(msg)
#定义消费者线程
class Consumer(threading.Thread):
def run(self):
global q
while True:
print('消费者线程开始消费线程了')
msg=q.get() #默认阻塞
print('消费线程得到了数据:{}'.format(msg))
time.sleep(2)
if __name__ == '__main__':
t1=Producer()
t2=Consumer()
t1.start()
t2.start()
1、q=queue.Queue(1000) 创建一个先进先出的队列,1000代表maxSize,队列中最多允许1000条数据
2、q=queue.LifoQueue 创建一个后进先出的队列
3、q=queue.PriorityQueue 优先级的队列
4、q.qsize():获取队列的长度
5、q.put(msg) :默认阻塞,如果队列中数据已经满了,会阻塞(进入等待状态);
参数:block,默认为True,表示数据已经进入等待,设为False表示不等待,如果队列中没有空位置,直接抛出异常
参数:timeout:设置等待的时长,如果超过时间还没有空位置,报异常
6、msg=q.get() 队列中获取数据,如果队列为空会阻塞
参数:block,默认为True,表示数据已经进入等待,设为False表示不等待,如果队列中没有数据,直接抛出异常
参数:timeout:设置等待的时长,如果超过时间还没有空位置,报异常
7、q.full():判断队列是否已满,如果已经满了,返回True,否则返回False
8、q.empty():判断队列是否为空,如果为空,返回True,否则返回False
9、q.task_done():向队列发送一个任务执行完毕的信息
10、q.join():等待队列中的任务(数据处理完毕)执行完毕
数据处理完毕判断依据是什么?
1、队列接收到的任务执行完毕的信号,是否等于进入队列中的任务数(数据量)
即:调用put的方法次数和调用task_done方法要一致
2、队列为空
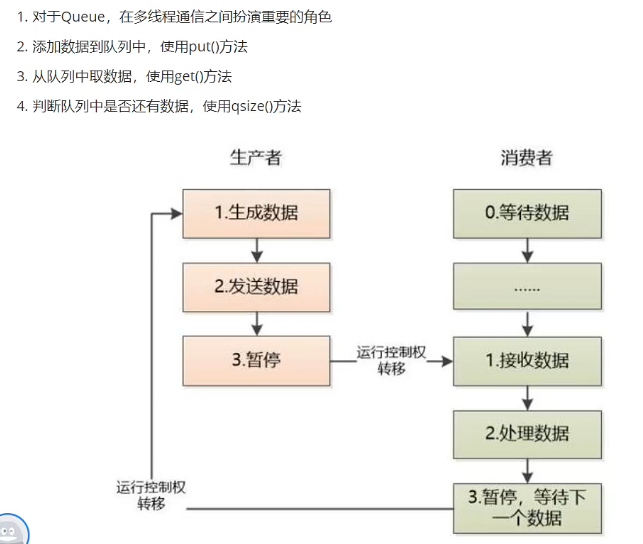
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
生产者消费者模式是通过一个容器(Queue)来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
上面的代码如果不加以人工干预,本代码将会一直执行下去。从输出结果来看,除了最初还有部分剩余产品外,后面只要产品生产出来后就被消费了。这也是可以解释的,因为消费者消费产品的速度要快于生产者生产产品的速度。
五、面试题
1、用一个队列来存储数据
2、创建一个专门生产数据的任务函数,循环生产5次数据,每轮循环,往队列中添加20条数据,每循环一轮暂停1秒
3、创建一个专门处理数据的任务函数 循环获取队列中的数据处理,每秒处理4条数据。
4、创建一个线程生产数据 ,3个线程处理数据
5、统计数据生产并获取完 程序运行的总时长
'''
1、用一个队列来存储数据
2、创建一个专门生产数据的任务函数,循环生产5次数据,每轮循环,往队列中添加20条数据,每循环一轮暂停1秒
3、创建一个专门处理数据的任务函数 循环获取队列中的数据处理,每秒处理4条数据。
4、创建一个线程生产数据 ,3个线程处理数据
5、统计数据生产并获取完 程序运行的总时长
'''
from queue import Queue
import threading
import time
q=Queue()
def work():
for i in range(5):
for j in range(20):
q.put(f'生产数据{j}')
time.sleep(1)
def handle():
while True:
for i in range(4):
try:
data=q.get(timeout=1)
except:
return
else:
print('获取数据:',data)
q.task_done()
time.sleep(1)
if __name__ == '__main__':
st=time.time()
t=threading.Thread(target=work)
t.start()
thread_list=[]
for i in range(3):
t1=threading.Thread(target=handle)
t1.start()
thread_list.append(t1)
#todo 等待数据生产完成
t.join()
for t1 in thread_list:
t1.join()
#todo 等待队列中的数据处理完成
q.join()
print('主线程执行完毕')
st1=time.time()
print('程序执行时间:',st1-st)
执行结果:
获取数据: 生产数据0
获取数据: 生产数据1
获取数据: 生产数据2
获取数据: 生产数据3
获取数据: 生产数据4
获取数据: 生产数据5获取数据: 生产数据6
获取数据: 获取数据: 生产数据7生产数据8
获取数据: 获取数据: 生产数据9
生产数据10
获取数据: 生产数据11
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123603.html

