
12 缓存
12.1简介
- 缓存概念Cache
存在内存中的临时数据,
一次查询的结果,暂时存在内存中,下次查询同样的数据时直接走缓存,不走数据库
将用户经常查询的数据放在缓存(内存)中,用户查询数据不从磁盘(关系型数据库文件)查找,可以提高查询效率,解决高并发系统的性能问题
几大的解决三高问题
三高:高可用,高并发,高性能
用户量大时,产生大量请求,加服务器去处理请求,同时产生大量对数据库的读写操作,此时会有读写并发问题,之前是加缓存实现读写分离,读走缓存,写还是走数据库。但一个数据库经不住大量的写请求,需要部署多套数据库服务器来分库分表,一些作为读数据服务器,一些作为写数据服务器,此时有个问题是如何保证多太数据库中数据一致性,需要主从复制哨兵检测,写数据后即刻同步到读数据库
- 作用
减少和数据库交互次数,节省系统开销,读数据开销70%提高系统效率
- 经常查询且不经常改变的数据
12.2 mybaits缓存
- mybaits有一个查询缓存特性,可以方便的定制和配置缓存,提示查询效率
- mybaits缓存定义了两级缓存:一、二级缓存
默认情况下,只有一级缓存开启(SqlSession级别的缓存,即本地缓存)
二级缓存需要手动开启配置,是基于namespace级别(接口级别)缓存
为提高扩展性,mybaits定义了缓存接口Cache,可以通过实现Cache接口来自定义二级缓存。实现了接口Cache的类叫做缓存策略
12.3 一级缓存
- 本地缓存
与数据库同一次回话期间查询到的数据会放在本地缓存中(只有查询的数据)
以后如果需要获取相同数据,直接走缓存,不走数据库
默认开启,无法关闭,在openSqlSession到close之间有效
场景:同一个用户不断的刷新一个页面,第二次刷新是从缓存中提取数据
就是一个map,后续第二次刷新是从缓存中提取数据
- 开启日志
- 测试:同样的查询sql在 sqlSession.close();前在再查一次相同的数据,结果日志可见只查了一次数据库
@Test
public void TestBlog05(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<>();
ArrayList<Integer> views = new ArrayList<Integer>();
views.add(30);
views.add(200);
views.add(500);
map.put("viewsList",views);
List<Blog> result = mapper.selectBlogForeach(map);
System.out.println("结果:"+result.toString());
System.out.println("=================================");
List<Blog> result2 = mapper.selectBlogForeach(map);
System.out.println("结果2:"+result2.toString());
System.out.println("结果相等不?:"+ (result2 == result));
sqlSession.close();
}
Opening JDBC Connection
Created connection 1052195003.
==> Preparing: select * from school.blog WHERE ( views = ? or views = ? or views = ? )
==> Parameters: 30(Integer), 200(Integer), 500(Integer)
<== Columns: id, title, author, create_time, views
<== Row: dd62539ef277429c90764463bba8544d, 客中行, 李白, 2022-06-18 10:48:15, 30
<== Row: 60ef5443f2e34c1086dcf8978a085e87, 恐龙, 李四, 2022-06-18 10:48:57, 200
<== Row: 4c7c9cd3104842a1b6d0522c4b09fba5, 1一亿年, 王五, 2022-06-18 10:49:34, 500
<== Total: 3
结果:[Blog(id=dd62539ef277429c90764463bba8544d, title=客中行, author=李白, createTime=Sat Jun 18 18:48:15 CST 2022, views=30), Blog(id=60ef5443f2e34c1086dcf8978a085e87, title=恐龙, author=李四, createTime=Sat Jun 18 18:48:57 CST 2022, views=200), Blog(id=4c7c9cd3104842a1b6d0522c4b09fba5, title=1一亿年, author=王五, createTime=Sat Jun 18 18:49:34 CST 2022, views=500)]
=================================
结果2:[Blog(id=dd62539ef277429c90764463bba8544d, title=客中行, author=李白, createTime=Sat Jun 18 18:48:15 CST 2022, views=30), Blog(id=60ef5443f2e34c1086dcf8978a085e87, title=恐龙, author=李四, createTime=Sat Jun 18 18:48:57 CST 2022, views=200), Blog(id=4c7c9cd3104842a1b6d0522c4b09fba5, title=1一亿年, author=王五, createTime=Sat Jun 18 18:49:34 CST 2022, views=500)]
结果相等不?:true
Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@3eb738bb]
Returned connection 1052195003 to pool.
- 缓存失效情况
查询不同数据
增删该后原来的数据可能被刷新,导致缓存失效,进行刷新
查询不同的mapper,导致二级缓存都失效了,一级缓存失效
手动清理缓存
sion.clearCache(); //手动清理缓存
12.4 二级缓存
- 二级缓存叫全局缓存,由于一级缓存作用域低了,才引入二级缓存
- 基于namespace级别(接口级别)缓存。
- 工作机制
一次会话查询一条数据,这个数据会先保存在当前会话的一级缓存中,若sqlsession当前会话不关闭
若sqlsession当前会话关闭后,这个一级缓存就没了,将一级缓存中的数据保存到二级缓存中(不同sqlsession操作同一个mapper,sqlsession关闭后都会转存到这个mapper中)
新的会话若要查询信息,就从二级缓存中查
不同的mapper查出的数据会放在自己对应的缓存(map)中
- 默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>
基本上就是这样。这个简单语句的效果如下:
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
-
注意:缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
-
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。
FIFO– 先进先出:按对象进入缓存的顺序来移除它们。
SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
-
默认的清除策略是 LRU。
-
例如:这些属性可以通过 cache 元素的属性来修改。
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
- 这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
-
注意:二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
-
开启缓存步骤:
- 先在mybatis-config显示定义全局开启缓存
<!--全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。默认开启true--> <!--显示的定义出来是为了代码可读性--> <setting name="cacheEnabled" value="true"/>2.需要开启mapper缓存的mapper.xml开启
<!--当前的mapper.xml中使用二级缓存--> <mapper namespace="com.zk.dao.BlogMapper"> <cache/> </mapper>3.单个select也可以开启缓存
<select id="selectBlogIF" parameterType="map" resultType="blog" useCache="true"> </select>
- 测试:用两个SqlSession去查
public void TestBlog03(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<>();
//map.put("title","诗");
map.put("author","李");
map.put("views",200);
List<Blog> blogs = mapper.selectBlogChoose(map);
System.out.println("结果:"+blogs.toString());
sqlSession.close();
SqlSession sqlSession2 = MybatisUtil.getSqlSession();
BlogMapper mapper2 = sqlSession2.getMapper(BlogMapper.class);
List<Blog> blogs2 = mapper2.selectBlogChoose(map);
System.out.println("结果:"+blogs2.toString());
System.out.println("两个对象是否相同:"+(blogs2==blogs));
sqlSession.close();
}
- 结果:只查了一次
Opening JDBC Connection
Created connection 442987331.
==> Preparing: select * from school.blog WHERE author like concat('%', ?,'%')
==> Parameters: 李(String)
<== Columns: id, title, author, create_time, views
<== Row: dd62539ef277429c90764463bba8544d, 客中行, 李白, 2022-06-18 10:48:15, 30
<== Row: 60ef5443f2e34c1086dcf8978a085e87, 恐龙, 李四, 2022-06-18 10:48:57, 200
<== Total: 2
结果:[Blog(id=dd62539ef277429c90764463bba8544d, title=客中行, author=李白, createTime=Sat Jun 18 18:48:15 CST 2022, views=30), Blog(id=60ef5443f2e34c1086dcf8978a085e87, title=恐龙, author=李四, createTime=Sat Jun 18 18:48:57 CST 2022, views=200)]
Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@1a677343]
Returned connection 442987331 to pool.
Cache Hit Ratio [com.zk.dao.BlogMapper]: 0.5
结果:[Blog(id=dd62539ef277429c90764463bba8544d, title=客中行, author=李白, createTime=Sat Jun 18 18:48:15 CST 2022, views=30), Blog(id=60ef5443f2e34c1086dcf8978a085e87, title=恐龙, author=李四, createTime=Sat Jun 18 18:48:57 CST 2022, views=200)]
两个对象是否相同:true
- 问题:缓存中输入输出,网络中使用是通过序列化进行的,所以对实体类加序列化
将readOnly=”true缓存只读去掉后序列化报错:
java.io.NotSerializableException: com.zk.pojo.Blog
设置readOnly=”true只读就不会报这个错,不设置只读就表示可能有读写,读写的缓存会通过序列化返回缓存对象的拷贝,此时需要实体类(这里是Blog)实现Serializable接口或者配置readOnly=true
最后会为false是因为一级缓存内容存到了二级缓存中所以内存地址变化,对比为false
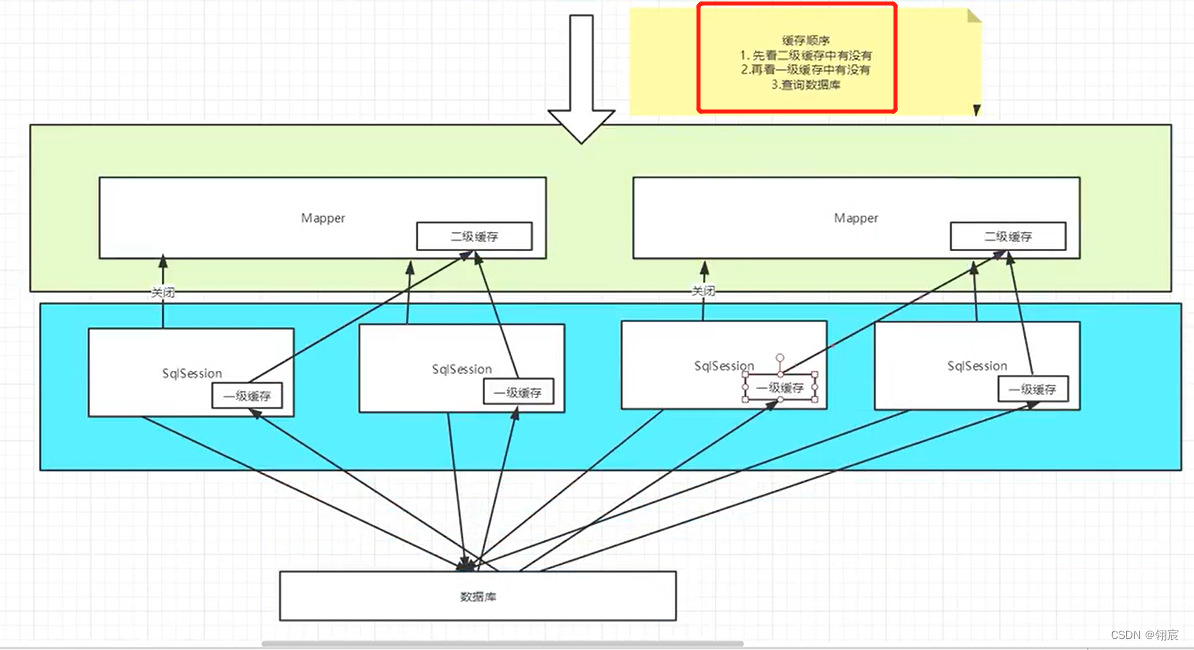
- 上述两个SqlSession例子结果可以证明这个缓存顺序
12.4.自定义缓存EhCache
-
被redis缓存替换
-
mybatis半自动orm框架,hibernate是全自动的orm框架
-
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。
-
Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储,缓存加载器,缓存扩展,缓存异常处理程序,一个gzip缓存servlet过滤器,支持REST和SOAP api等特点。
主要的特性有:
-
使用
-
导报
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.2</version>
</dependency>
- 配置ehcache.xml,使用了laravel门面模式
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd">
<!-- 磁盘缓存位置 -->
<!--
java.io.tmpdir/ehcache - 默认零食文件路径
user.home -用户主目录
user.dir -用户当前工作目录
-->
<diskStore path="./tmpdir/ehcache"/>
<!-- 默认缓存 -->
<!--
name:缓存名称。
maxElementsInMemory:缓存最大个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。
仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。
仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
overflowToDisk:当内存中对象数量达到maxElementsInMemory时,Ehcache将会对象写到磁盘中。
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
maxElementsOnDisk:硬盘最大缓存个数。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。
默认策略是LRU(最近最少使用)。
你可以设置为FIFO(先进先出)
或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
-->
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
</ehcache>
- 在mapper.xml中配置指定的ehcache缓存实现
<mapper namespace="com.zk.dao.BlogMapper">
<!--当前的mapper.xml中使用二级缓存-->
<!-- <cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>-->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
</mapper>
-
自己实现缓存,需实现interface Cache接口
-
redis数据库做缓存K-V
本专栏完
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123916.html

