
目录
2.1、HashTable锁粒度粗,ConcurrentHashMap锁粒度细
2.2、ConcurrentHashMap只有写操作加锁,读操作不加锁
2.3、ConcurrentHashMap充分利用了CAS特性
2.4、ConcurrentHashMap和HashTable的扩容方式也不一样
2.5、HashMap key允许为null,其他两个都不可以
回答思路
先考虑线程安全,再考虑锁粒度,多线程下的优化;
一、线程安全角度
HashMap本身不是线程安全的,多线程下更多的使用是HashTable,ConcurrentHashMap;
HashTable只是在关键方法上加了synchronized,相当于针对HashTable本身加锁;ConcurrentHashMap相对于HashTable做出了一些优化和改进:对读方式没有加锁(但使用了volatile保证从内存中读取数据),只对写操作使用synchronized进行加锁,但不是对整个对象进行加锁,而是对每个哈希桶进行加锁;(如下图)
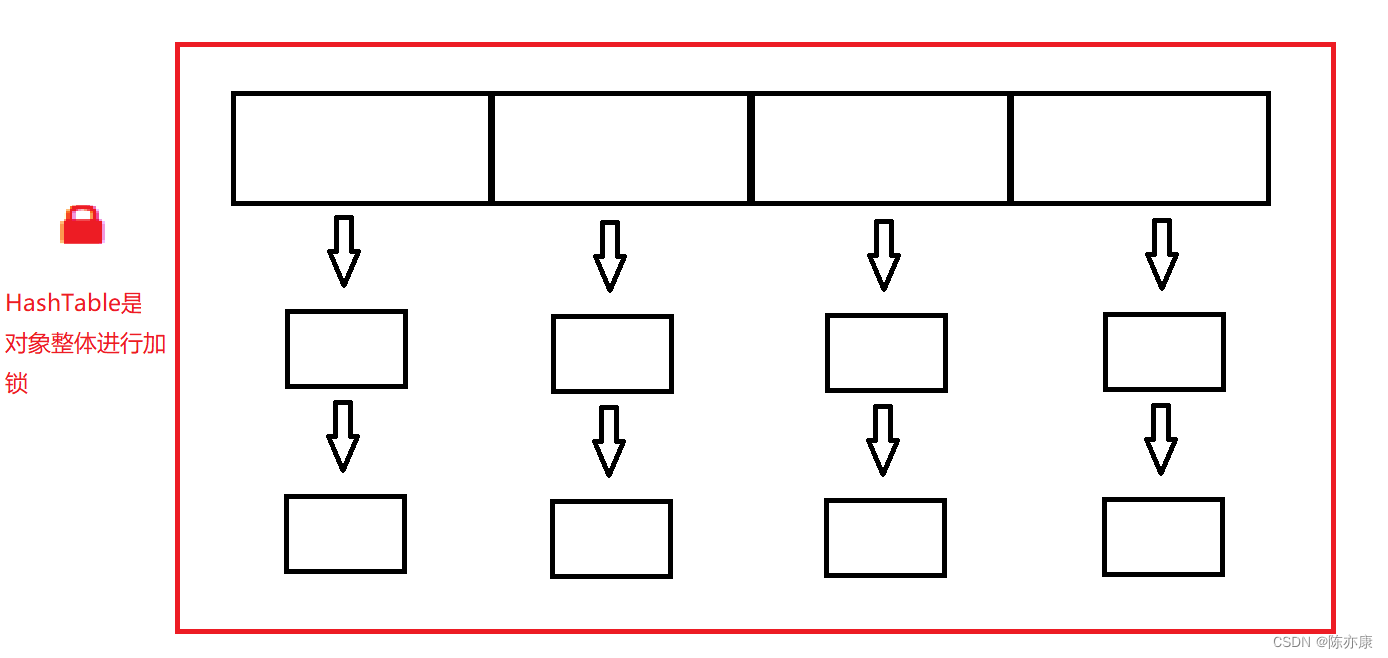

二、线程优化,锁粒度角度
2.1、HashTable锁粒度粗,ConcurrentHashMap锁粒度细
HashTable只有一把锁,是在方法上加synchronized,相当于对this加锁,也就是对哈希表本身加锁;
ConcurrentHashMap中,每个哈希桶都有自己的锁,大大降低了锁冲突,提高了性能;
2.2、ConcurrentHashMap只有写操作加锁,读操作不加锁
ConcurrentHashMap在设计的时候还慎重的考虑到了:若一个线程读,一个线程修改,这种操作的线程安全问题;ConcurrentHashMap保证了读数据一定是读到整段数据,不会发生读到的是修改了一半的数据;另外,读操作中也广泛的使用volatile来保证及时读到数据;
2.3、ConcurrentHashMap充分利用了CAS特性
对于ConcurrentHashMap来说,设计的时候就是能不加锁就不加锁,大部分都是通过CAS来实现的,比如:维护元素个数,实现轻量级锁;核心就是:尽可能降低锁冲突的概率(所冲突对性能影响很大)
2.4、ConcurrentHashMap和HashTable的扩容方式也不一样
HashTable扩容方式:
put元素时,发现负载因子超过阈值,就会触发扩容——申请一个更大的数组,然后讲旧数据搬运到新数组上;
缺陷:旧数组元素越多,搬运的开销越大;
ConcurrentHashMap扩容方式:
扩容的时候,旧数组和新数组会同时存在一段时间,每次操作哈希表的时候都会把旧内存的一些元素搬运到新数组中,直到全部搬运完才释放旧数组的空间(查询元素时,旧和新一起查;插入元素时,直接往新的上插入;删除元素,直接删了,不用搬运);
2.5、HashMap key允许为null,其他两个都不可以
emm…这个虽然也是区别,但是不是很关键,面试的时候根据情况来答就ok~

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/124321.html

