
在敲代码的过程中,大家是否有过这些疑问:
1.在写int a = 1;这样一句代码时,他在内存中是以什么形式存在的?
2.int 、char、short、long…这些类型的存在是有什么用?
3.原码,反码,补码,是什么?为什么要创造出这些?
4.大小端字节序是什么?怎么判读机器大小端?
首先,先来看看我们熟知的内置类型
char //字符数据类型
short //短整型
int //整形
long //长整型
long long //更长的整形
float //单精度浮点数
double //双精度浮点数那么出现这些类型有什么意义呢?
a.类型决定了他开辟空间的大小
b.看待内存空间的视角也会因此不同
如何去理解呢?
我们可以将这些类型先进行一个基本归类:
1.整形家族
int
unsigned int
signed int
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
long
unsigned long [int]
signed long [int]注:这里包括有符号(signed)和无符号(unsigned)之分
有什么意义呢?
当你需要去表示如:升高,体重…等等这种不可能为负数的量时,无符号表示就有意义.
当你需要去表示如:气温,海拔高度,收入支出…等等这些可正可负的量时,有符号表示就有意义.
2.浮点型家族
float
double3.构造类型:
> 数组类型 数组名[常量]
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union指针类型
int* p
char* p
shot* p
long* p
float* p
void* p注:void表示空类型(用于函数返回类型,函数参数,指针类型).
这里有的小伙伴可能就要问了,“C语言没有字符串类型吗?”
字符存储到内存中,实际上是以他的ASCII码值的形式存储到内存中的,所以其本质还是整形,因此被也被归为整形家族.
知道了这些类型
咱就来讲讲这些类型到底是怎么存储在内存中的?
比如
int a = 1;
int b = -1;目前也许我们只知道,一个整形会在内存中开辟4个字节的空间,那怎么存储呢?
这里就不得不说一下原码、反码、补码啦~
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
正数的原码、反码、补码相同
负数需要进行相应的转化
如何转化呢?
原码:将这个数直接以2进制的形式表示出来就是他的原码
反码:将这个数的原码符号不变,其他位按位取反得到反码
补码:反码加一得到补码
如上述例子:
int a = 1;
原码:00000000 00000000 00000000 00000001
反码:00000000 00000000 00000000 00000001
补码:00000000 00000000 00000000 00000001
int b = -1;
原码:10000000 00000000 00000000 00000001
反码:11111111 11111111 11111111 11111110
补码:11111111 11111111 11111111 11111111
这里补充几点:
为什么会有32位呢?
我们知道,一个整形在内存中开辟4个字节的内存空间,那么,可以换算一下,1个字节=8个比特位,那么4个字节就有32个比特位,所以这里就有32位,二进制一位为一个比特位.
最高的那位即为符号位,1表示为负数,0表示为正数
对于整形来说,
数据存放内存中其实存放的是补码。
为什么呢?
不说人话:
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理; 同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
说人话:
电脑只能处理加法,不能处理减法,例如1-1需要表示成1+(-1)
这个时候,1和-1的补码相加,就可以直接表示
1的补码:00000000 00000000 00000000 00000001
-1的补码:11111111 11111111 11111111 11111111
相加: 100000000 00000000 00000000 00000000
相加后的结果位33个比特位
这里由于一个整形只能存下4个字节(32个比特位的内容),所以这里会发生截断;
就好比你需要将一个4米长的棍子放水平放进一个3米长的坑里,这个4米长的棍子必须截断才能水平放入;
故最后因得到
00000000 00000000 00000000 00000000
可以看到,这里很好的展示了通过1+(-1)完美表示了1-1所得结果,体现出补码可以将正负统一。
因此,数据存放内存中存放的是补码。
接下里,我们通过VS2022观察一下int a = 10;在内存中的存储形式

这里先说明一下,这些数据存储进计算机内存的形式本质是二进制,但是他的对外表现形式是十六 进制;
那么int a = 10; 10这个整数写成十六进制是 00 00 00 0a (十六进制一位表示四个二进制位,因此有八个十六进制位)
不对劲,为什么是0a 00 00 00
为什么在内存中确是倒着存放的呢?
这里就不得不提到大小端字节序啦~
何为大端字节序?
何为小端字节序?
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址 中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地 址中。
什么意思呢?
我们假设地址方向

那么刚刚的a变量
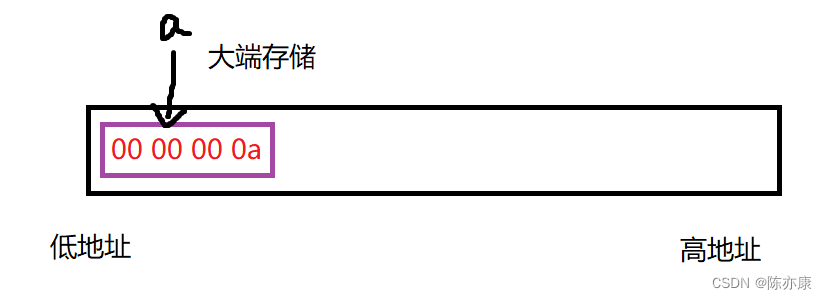
此时便为大端存储
如何理解?
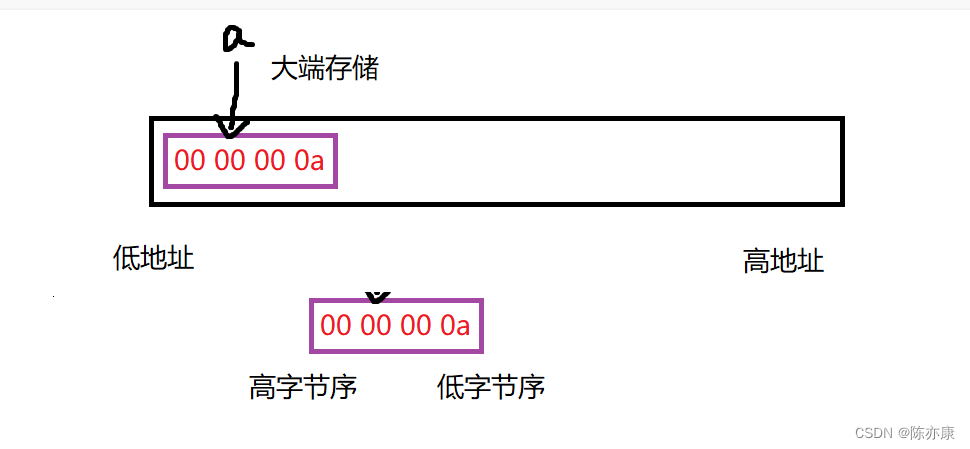
这就是大端存储,将低字节序内容存放在高地址处,高字节序保存在低地址处
小端嘞?
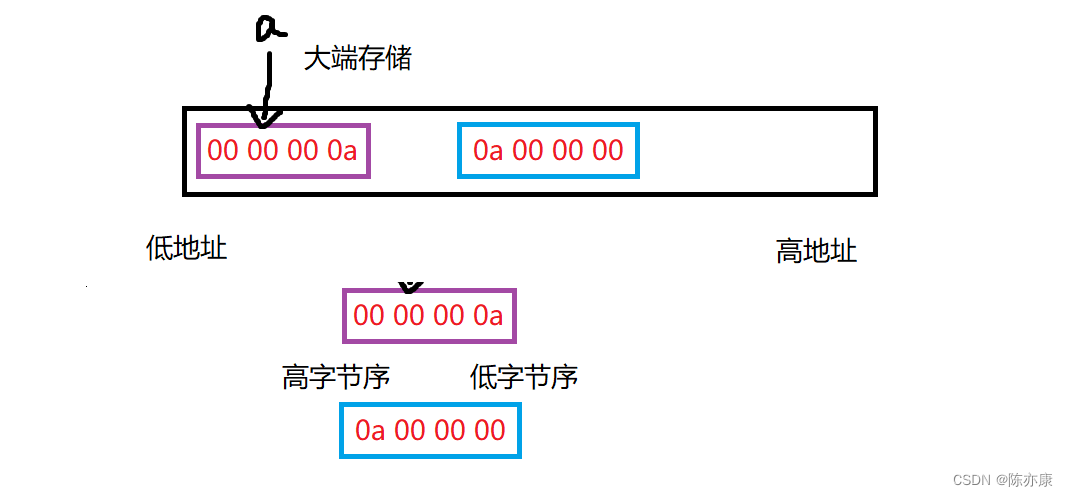
想必这时大家便一目了然啦
这也证明,作者所用的计算机是小端存储,于是便出现了以上情况
注意:大小端的存储形式与编译器无关!与你所用的计算机本身有关,例如大家常用的AMD机型…
最后一个问题啦~
我们该如何用代码的形式判断自己用的机器是大端存储还是小端存储呢(2015年百度面试题)
还记得我们上文讲到的“截断”吗
可以通过创建一个整形变量a = 1,然后将此整形变量存入char类型中
由于char只能存下一个字节大小的内容,所以会发生截断
因此我们可以取出a的地址(首地址,低地址处)用char类型访问整形变量a = 1的第一个字节内容来判断机器是大端存储还是小端存储
第一个字节的内容如果是01,说明机器将低字节序内容放在了低地址处,故为小端存储
第一个字节的内容如果是00,说明机器将低字节内容存放在了高地址处,故为大端存储
代码如下:
#include<stdio.h>
int main()
{
int a = 1;
if (*((char*)&a) == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}主要内容到这里就结束了~
想要提升,可以再往下看看
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
//输出什么?这里补充一点:
char类型的变量在未标注的情况下,默认为signed有符号类型
signed char类型可以表示的范围为-128~+127
解释如下:
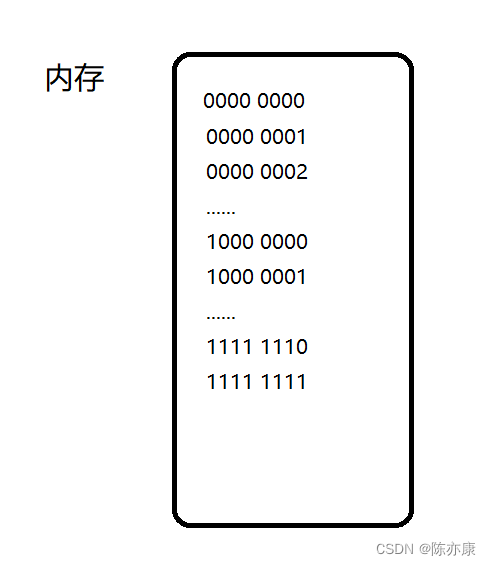
这是char类型在空间里的存储形式
对应十进制数:
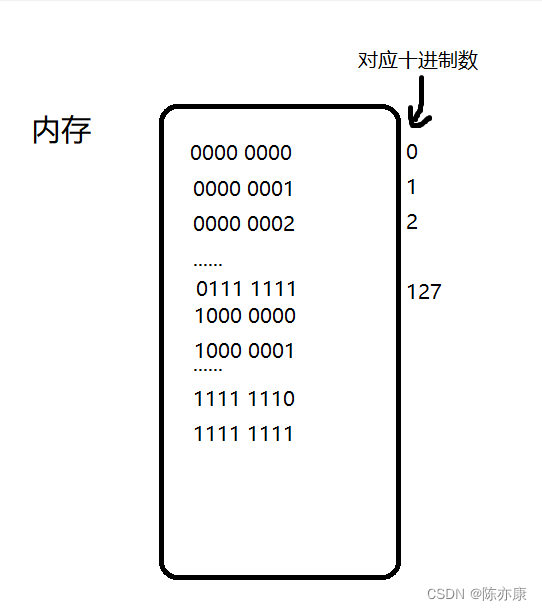
这里要特别注意,由于是signed char类型,所以要注意符号位
这里我们通过符号位不变,其他位按位取反+1的方式(与-1,取反效果一样)得到原码
那么 1111 1111
1000 0000
原码 1000 0001 为-1
同理 1111 1110
1000 0001
原码 1000 0010 为-2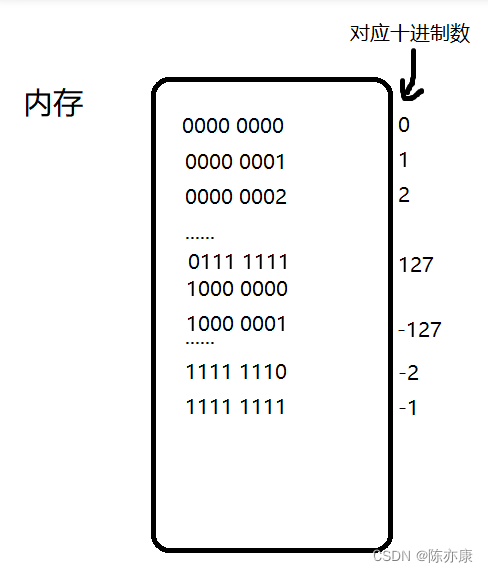
最后要特别注意
1000 0000
取反得到
1111 1111
+1得到
1 0000 0000
这个1 0000 0000怎么算呢?需要截断吗?
其实当我们看到这个数的时候不需要计算,这里规定,这里可以直接将看成-128
故 有符号char类型的取值范围是-128~127
那么同理,无符号char可以推出范围是0~255
这时候我们继续看这道题
char a = -1;
-1存进内存中
原码: 10000000 00000000 00000000 00000001
反码: 11111111 11111111 11111111 11111110
补码: 11111111 11111111 11111111 11111111 (内存中)
由于char类型的变量在空间中占1个字节
故要发生截断
补码: 11111111
接下来需要以%d的形式打印,也就是打印有符号整形
所以此时需要整形提升,看char类型,是有符号类型,故向高位补符号位
补码: 11111111 11111111 11111111 11111111
翻译成原码: 10000000 00000000 00000000 00000001
故此时a 打印-1
同理b打印 -1
那对于无符号的c呢?
unsigned char c = -1;
-1存入内存中
补码: 11111111 11111111 11111111 11111111
由于是char类型只能存放一个字节,发生截断
补码: 11111111
以%d的形式打印一个整形
此时由于c是unsigned char类型,是无符合类型,故高位补0
补码: 00000000 00000000 00000000 11111111
此时最高位是0,是正数
故原码反码补码相同
原码: 00000000 00000000 00000000 11111111
对应十进制数为255
故最终结果为a = -1,b = -1,c = 255;
码字不易~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/124393.html

