
HashMap的hash算法
1. HashMap为什么异或原数右移16位计算哈希值?
源码
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
简单的说如果key为null,返回0。否则返回key的hash值异或一个key的hash值右移16位。
我们看一下效果
0000 1010 1000 1000 1010 0011 0111 0100 `原数`
0000 0000 0000 0000 0000 1010 1000 1000 `右移16`
0000 1010 1000 1000 1010 1001 1111 1100 `异或结果`
我们发现,高位16没有发生变化,因为右移16位之后高位都是补0,1异或0还是1,0异或0还是0。
到此我们不能明确的知道,这个异或右移16位有什么作用,我们看一下HashMap如何计算插入位置的。
源码
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
n为容量大小,假设我们现在的容量是起始容量16,则这里的算式就是15&hash值
我们看一下效果
1101 0011 0010 1110 0110 0100 0010 1011 `原数`
0000 0000 0000 0000 0000 0000 0000 1111 `15的二进制`
0000 0000 0000 0000 0000 0000 0000 1011 `结果`
仔细观察上文不难发现,高区的16位很有可能会被数组槽位数的二进制码锁屏蔽,如果我们不做刚才移位异或运算,那么在计算槽位时将丢失高区特征。
也许你可能会说,即使丢失了高区特征不同hashcode也可以计算出不同的槽位来,但是你设想如果两个哈希值的低位差异极小而高位差异很大,导致这两个哈希值计算出来的桶位比较接近,会插入到HashMap的两个位置比较相邻的位置,这样哈希碰撞的概率就变高了!
我们认为一个健壮的哈希算法应该在hash比较接近的时候,计算出来的结果应该也要天差地别,足够的散列,所以这这个高位右移16位的异或运算也是HashMap将性能做到极致的一种体现。
2. HashMap的hash算法为什么使用异或?
异或运算能更好的保留各部分的特征,如果采用&运算计算出来的值会向0靠拢,采用 | 运算计算出来的值会向1靠拢。
3.可以用%取余运算吗?
&运算时二进制逻辑运算符,是计算机能直接执行的操作符,而%是Java处理整形浮点型所定义的操作符,底层也是这些逻辑运算符的实现,效率的差别可想而知,效率相差大概10倍。
HashMap的加载因子
4.加载因子为什么是0.75?
很多人说HashMap的DEFAULT_LOAD_FACTOR = 0.75f是因为这样做满足泊松分布,这就是典型的半知半解、误人子弟、以其昏昏使人昭昭。实际上设置默认load factor为0.75和泊松分布没有关系,而是我们一个随机的key计算hash之后要存放到HashMap的时候,这个存放进Map的位置是随机的,满足泊松分布。
我们来看一下官方对这个加载因子的解释:
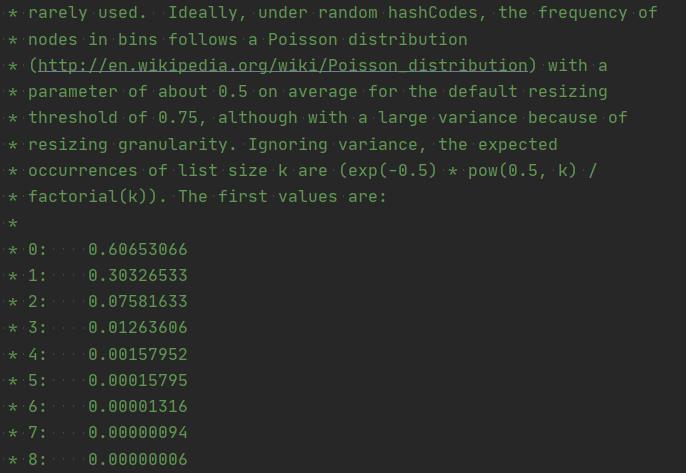
简单翻译一下:理想情况下,在随机hashCodes下,bin中节点的频率遵循Poisson分布(http://en.wikipedia.org/wiki/Poisson_distribution),默认调整大小阈值0.75的平均参数约为,尽管由于调整粒度而差异很大。忽略方差,列表大小k的预期出现次数是(exp(-0.5)* pow(0.5,k)/ * factorial(k))。第一个值是:
-
0:0.60653066
-
1:0.30326533
-
2:0.07581633
-
3:0.01263606
-
4:0.00157952
-
5:0.00015795
-
6:0.00001316
-
7:0.00000094
-
8:0.00000006
其他:少于一百万分之十
也就是说,我们单个Entry的链表长度为0,1的概率非常高,而链表长度很大,比8还要大的概率忽略不计了。
5. 加载因子可以调整吗??
可以调整,hashmap运行用户输入一个加载因子
public HashMap(int initialCapacity, float loadFactor) {
}
6. 加载因子为0.5或者1,会怎么样?能大于1吗
我们凭借逻辑思考,如果加载因子非常的小,比如0.5,那么我们是不是扩容的频率就会变高,但是hash碰撞的概率会低很多,相应的链表长度就普遍很低,那么我们的查询速度是不是快多了?但是内存消耗确实大了。
那么加载因子很大呢?我们想象一下,如果加载因子很大,我们是不是扩容的条件就变的更加苛刻了,hash碰撞的概率变高,每个链表长度都很长,查询速度变慢,但是由于我们不怎么扩容,内存是节省了不少,毕竟扩容一次就翻一倍。
那么加载因子大于1会怎么样,我们加载因子是10,初始容量是16,当桶数达到160时扩容,平均每个链表长度为10,链表并没有长度限制,所以,加载因子可以大于1,但是我们的HashMap如果查询速度取决于链表的长度,那么HashMap就失去了自身的优势,尽管JDK1.8引入了红黑树,但是这只是补救操作。
如果在实际开发中,内存非常充裕,可以将加载因子调小。如果内存非常吃紧,可以稍微调大一点。
HashMap的初始容量
7. 为什么HashMap的初始容量是16?
我们知道扩容是个耗时的过程,有大量链表操作,16作为一个折中的值,即不会存入极少的内容就扩容,也不会在加入大量数据而扩容太多次。16扩容3次就达到128的长度。
其实还有一个很重要的地方,16是2的4次方,我们在看HashMap的源码时,可以看到初始容量的定义方式如下:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
8. 为什么初始容量是2的多次方比较好?
这是我们计算插入位置的算法,n代表的就是容量。假设我们没有设置容量,也没扩容过,那么这个n就是16,n-1=15
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
演示计算过程
1101 0011 0010 1110 0110 0100 0010 1011 `原数`
0000 0000 0000 0000 0000 0000 0000 1111 `15的二进制`
0000 0000 0000 0000 0000 0000 0000 0011 `结果`
我们发现,插入位置实际上又原数的最低的4位决定的,每个位置都有插入的可能。
9. 初始容量如果不是2的次方呢?
HashMap确实提供我们手动设置初始容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
假如我们设置为17,我们看一下计算插入位置的过程,hash & 16
1101 0011 0010 1110 0110 0100 0010 1011 `原数`
0000 0000 0000 0000 0000 0000 0001 0000 `16的二进制`
0000 0000 0000 0000 0000 0000 0000 0000 `结果`
我们发现16的二进制只有一个为1其他都是0,其他数字与上它,不是16就是0。也就是说,这简直是Hash冲突的噩梦。
你将会得到一个Java双单向链表
再举例,初始长度是15 , hash & 14
1101 0011 0010 1110 0110 0100 0010 1011 `原数`
0000 0000 0000 0000 0000 0000 0000 1110 `14的二进制`
0000 0000 0000 0000 0000 0000 0000 0000 `结果`
结果发现,最后一位永远是0,那么0,2,4,6,8,10,12,14这几位就无法插入上了。
这也是2N的性质,2N-1,结果为全是1,插入的位置由原数决定,每个点都有机会插入。
10. HashMap对于你输入非2的次方的数,会怎么样?
当然HashMap不会让你们这么做的,实际上你给定的初始容量,HashMap还会判断是不是2的次幂,如果不是,则给出一个大于给定容量的最小2的次幂的值作为新的容量。
public HashMap(int initialCapacity, float loadFactor) {
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
这也验证了一个重要的编程思想:永远要把客户当成傻子。
HashMap树化
11. 为什么要进行树化?
我们看一下官方的描述
简单翻译一下:
由于TreeNodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们(参见 TREEIFY_THRESHOLD 值)。当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的bin。理想情况下,在随机哈希代码下,bin中的节点频率遵循泊松分布,下面就是list size k 的频率表。
-
0:0.60653066
-
1:0.30326533
-
2:0.07581633
-
3:0.01263606
-
4:0.00157952
-
5:0.00015795
-
6:0.00001316
-
7:0.00000094
-
8:0.00000006
其他:少于一百万分之十
11. 为什么链表长度为8的概率如此之低,还要去树化?
这里科普一个东西:Hash碰撞攻击,就是说,有人恶意的向服务器发送一些hash值计算出来一样,但是又不相同的数据,用我们的Java语言来理解就是:
a.hash()==b.hash() , a.equals(b)==false
这样,我们的HashMap会把这些数据全部加入到同一个位置,即一条链表上,倘若我们的链表长度达到了100,那么可想而知,性能急剧下降。这时我们的红黑树可以缓解这种性能急剧下降的问题,但是最好的解决方案是去拦截这些恶意的攻击。
12. 为什么不选择6进行树化?
我们看一下TreeNode的源码
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
........
}
这是node节点,继承了Map.Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
对比发现:TreeNode每一个数都是一个TreeNode,正如官方所说的,TreeNode大概是普通的2倍,所以我们转换成树结构时会加大内存开销的。
我们发现在加载因子没有修改的前提下,单一条链表的长度大于等于8的概率是非常的低的,所以我们选择8才树化,树化的频率还是很低的,HashMap整体性能受到影响还是比较小的。
如果选择6进行树化,虽然概率也很低,但是也比8大了一千倍,遇到组合Hash攻击时(让你每个链表都进行树化),也会遇到性能下降的问题。
13. 为什么树化之后,当长度减至6的时候,还要进行反树化?
-
长度为6时我们查询次数是6,而红黑树是3次,但是消耗了一倍的内存空间,所以我们认为,转换回链表是有必要的。
-
维护一颗红黑树比维护一个链表要复杂,红黑树有一些左旋右旋等操作来维护顺序,而链表只有一个插入操作,不考虑顺序,所以链表的内存开销和耗时在数据少的情况下是更优的选择。
14. 为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢?
如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
还有一点重要的就是由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
总结
如果实际面试的时候,你能提出一些对 HashMap 的优化的一些思路,也是加分项!比如你说我觉得hash算法可以优化,hash 散列种子可以优化,等等。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/125148.html

