
一、聚簇索引和非聚簇索引
1、聚簇索引和非聚簇索引:
我拿查字典做一个比喻,字典的页面就好比是物理排列顺序,物理排列顺序是固定的,查询的方式就好比是索引,区别是聚簇索引就好比是拼音查询,每一个字母查询出来的页面顺序是跟你字母的顺序一致的,a字母查询出来的页面一定是在c字母查询出来的页面前面,而非聚簇索引就好比是笔画查询,笔画少的查出来的页面不一定在笔画多的查出来的页面前面,也就是你通过笔画查询的顺序和页面的顺序并不是一致的。
再举一例:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关。举例来说,你翻到新华字典的汉字“爬”那一页就是P开头的部分,这就是物理存储顺序(聚簇索引);而不用你到目录,找到汉字“爬”所在的页码,然后根据页码找到这个字(非聚簇索引)
索引的叶节点就是数据节点。非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块
2、非聚簇索引我自己的理解:(对应MyISAM)

聚簇索引:(对应Innodb)
3、聚簇索引(以Innodb为例)和非聚簇索引(以MyISAM–>三个文件是分开的为例):
非聚簇索引:
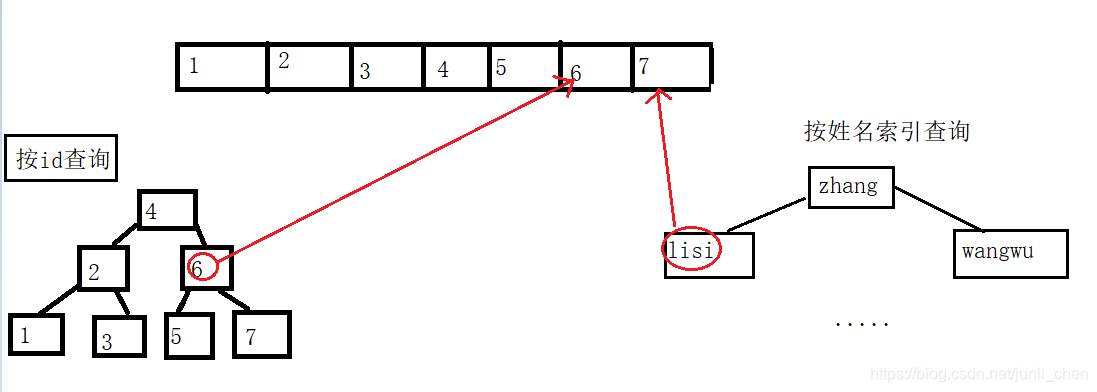
聚簇索引:
4、需要注意的知识点:
(1)、聚簇索引的唯一性
正式聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引,因为物理存储只能有一个顺序。正因为一个表最多只能有一个聚簇索引,所以它显得更为珍贵,一个表设置什么为聚簇索引对性能很关键.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/125176.html

