
目录
一:MyBatis的⾼级映射及延迟加载
前期准备:
模块名:mybatis-010-advanced-mapping
打包⽅式:jar
引⼊依赖:mysql驱动依赖、mybatis依赖、junit依赖、logback依赖
pojo:com.bjpowernode.mybatis.pojo.Student和Calzz
mapper接⼝:com.bjpowernode.mybatis.mapper.StudentMapper和ClazzMapper
引⼊配置⽂件:mybatis-config.xml、jdbc.properties、logback.xml
mapper配置⽂件:com/bjpowernode/mybatis/mapper/StudentMapper.xml和ClazzMapper.xml
编写测试类:com.bjpowernode.mybatis.test.StudentMapperTest和ClazzMapperTest
拷⻉⼯具类:com.bjpowernode.mybatis.utils.SqlSessionUtil
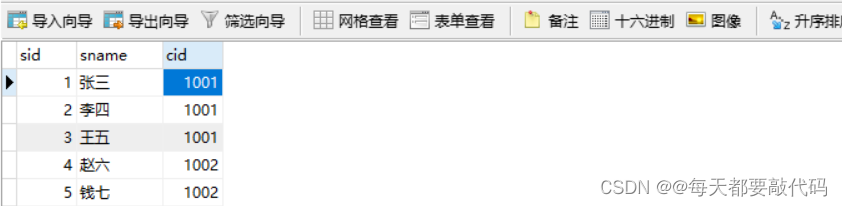
准备数据库表:⼀个班级对应多个学⽣:
班级表:t_clazz


学⽣表:t_student
clazz实体类
package com.bjpowernode.mybatis.pojo;
/**
* @Author:朗朗乾坤
* @Package:com.bjpowernode.mybatis.pojo
* @Project:mybatis
* @name:Clazz
* @Date:2023/1/7 18:18
*/
public class Clazz {
private Integer cid;
private String cname;
public Clazz() {
}
public Clazz(Integer cid, String cname) {
this.cid = cid;
this.cname = cname;
}
@Override
public String toString() {
return "Clazz{" +
"cid=" + cid +
", cname='" + cname + '\'' +
'}';
}
public Integer getCid() {
return cid;
}
public void setCid(Integer cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
}
Student实体类:只定义两个字段;对于cid属性,是为了维护两者关系的属性
package com.bjpowernode.mybatis.pojo;
/**
* @Author:朗朗乾坤
* @Package:com.bjpowernode.mybatis.pojo
* @Project:mybatis
* @name:Student
* @Date:2023/1/7 18:18
*/
public class Student {
private Integer sid;
private String sname;
public Student() {
}
public Student(Integer sid, String sname) {
this.sid = sid;
this.sname = sname;
}
@Override
public String toString() {
return "Student{" +
"sid=" + sid +
", sname='" + sname + '\'' +
'}';
}
public Integer getSid() {
return sid;
}
public void setSid(Integer sid) {
this.sid = sid;
}
public String getSname() {
return sname;
}
public void setSname(String sname) {
this.sname = sname;
}
}
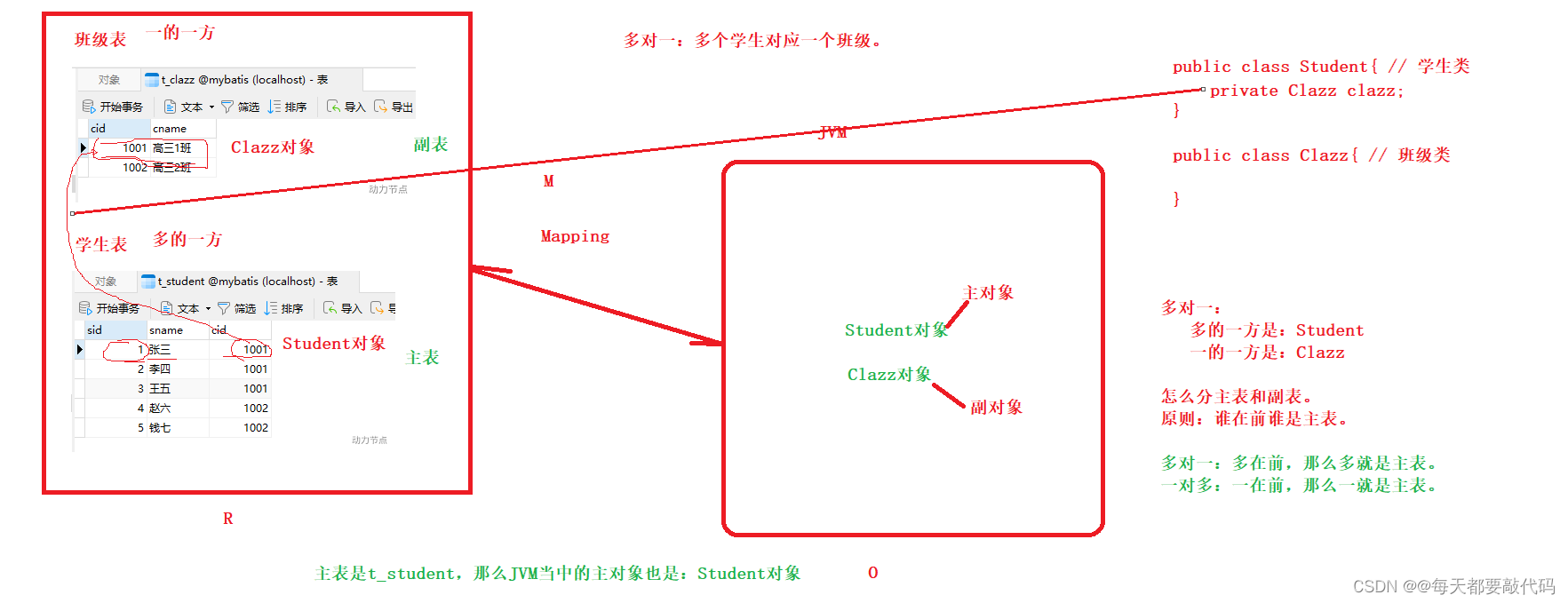
1. 多对⼀
多对一:多的一方在前面,那么多就是主表,一就是副表!例如:多个学生(主表)对应一个班级(副表)!
一的一方在是以属性的方式存在多的一方!
pojo类Student中添加⼀个属性:Clazz clazz; 表示学⽣关联的班级对象,增加setter and getter方法,重写toString方法。
package com.bjpowernode.mybatis.pojo;
/**
* @Author:朗朗乾坤
* @Package:com.bjpowernode.mybatis.pojo
* @Project:mybatis
* @name:Student
* @Date:2023/1/7 18:18
*/
public class Student { // Student是多的一方
private Integer sid;
private String sname;
private Clazz clazz; // Clazz是一的一方
public Student() {
}
public Student(Integer sid, String sname) {
this.sid = sid;
this.sname = sname;
}
@Override
public String toString() {
return "Student{" +
"sid=" + sid +
", sname='" + sname + '\'' +
", clazz=" + clazz +
'}';
}
public Clazz getClazz() {
return clazz;
}
public void setClazz(Clazz clazz) {
this.clazz = clazz;
}
public Integer getSid() {
return sid;
}
public void setSid(Integer sid) {
this.sid = sid;
}
public String getSname() {
return sname;
}
public void setSname(String sname) {
this.sname = sname;
}
}
多对一:多个学生Student对应一个班级Clazz;多种实现⽅式,常⻅的包括三种:
①第⼀种⽅式:⼀条SQL语句,级联属性映射。
②第⼆种⽅式:⼀条SQL语句,association。
③第三种⽅式:两条SQL语句,分步查询(常用的)。
1.1 第⼀种⽅式:使用级联属性映射resultMap
三兄弟之一:StudentMapper接口,编写方法
根据id获取学生Student信息,同时获取学生关联的班级Clazz信息
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Student;
public interface StudentMapper {
/*
* @param id 学生的id
* @return 返回一个Student对象,但是Student对象中含有Clazz对象
*/
Student selectById(Integer id);
}
三兄弟之二:StudentMapper.xml文件,编写sql语句
(1)使用resultMap来指定映射关系,结果映射resultMap有两个参数:
①一个参数是id,指定resultMap的唯一标识,这个id将来在select标签中使用。
②一个参数是type,用来指定POJO类的类名。
(2)在resultMap下还有一个子标签result;
①首先对于有主键的需要配一个id,不是必须的,但可以增加效率;
②下面使用result子标签的property属性和column属性分别指定POJO类的属性名和数据库表中的字段表之间的映射关系;
③对于clazz对象的属性映射,采用“引用.属性”的方式,例如:clazz.cid,clazz.cname;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.StudentMapper">
<!--多对一映射的第一种方式:一条SQL语句,级联属性映射-->
<resultMap id="studentResultMap" type="Student">
<id property="id" column="id"/>
<result property="sid" column="sid"/>
<!--Clazz类中的属性,采用"引用.属性名"的形式访问-->
<result property="clazz.cid" column="cid"/>
<result property="clazz.cname" column="cname" />
</resultMap>
<select id="selectById" resultMap="studentResultMap">
select
s.sid,s.sname,c.cid,c.cname
from
t_student s
left join
t_clazz c
on s.cid = c.cid
where
s.sid = #{sid}
</select>
</mapper>
三兄弟之三:StudentMappeTest类,用来编写测试类
package com.bjpowernode.mybatis.test;
import com.bjpowernode.mybatis.mapper.StudentMapper;
import com.bjpowernode.mybatis.pojo.Student;
import com.bjpowernode.mybatis.utils.SqlSessionUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
public class StudentMapperTest {
@Test
public void testSelectById(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.selectById(1);
// 直接输出Student对象
System.out.println(student);
// 输出每个属性
System.out.println(student.getSid());
System.out.println(student.getSname());
System.out.println(student.getClazz().getCid());
System.out.println(student.getClazz().getCname());
sqlSession.close();
}
}
执行结果:

1.2 第⼆种⽅式:使用association标签
第二种方式,和第一种方式的代码很类似,就是多引入一个association标签,association翻译为关联的意思;相当于resultMap和association的联合使用!
三兄弟之一:StudentMapper接口,编写方法
根据id获取学生Student信息,同时获取学生关联的班级Clazz信息
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Student;
public interface StudentMapper {
/**
* 一条SQL语句,使用association标签的方式
* @param id 学生的id
* @return 学生对象,但是学生对象当中含有班级对象
*/
Student selectByIdAssociation(Integer id);
}
三兄弟之二:StudentMapper.xml文件,编写sql语句
association:翻译为关联,配置两个属性,一个Student对象关联一个Clazz对象
①property属性:提供要映射的POJO类的属性名,这里就是clazz;
②javaType属性:用来指定要映射的java类型,这里就是com.bjpowernode.mybatis.Clazz;
③association配置两个属性以后,也要配置关联对象的Clazz的映射关系,也要使用id标签和result标签进行配置;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.StudentMapper">
<!--一条SQL语句,引入association标签-->
<resultMap id="studentResultMapAssociation" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
<!--使用assocaition标签-->
<association property="clazz" javaType="Clazz">
<!--虽然字段是相同的,但是不能省略不写-->
<id property="cid" column="cid"/>
<result property="cname" column="cname" />
</association>
</resultMap>
<select id="selectByIdAssociation" resultMap="studentResultMapAssociation">
select
s.sid,s.sname,c.cid,c.cname
from
t_student s
left join
t_clazz c
on s.cid = c.cid
where
s.sid = #{sid}
</select>
</mapper>
三兄弟之三:StudentMappeTest类,用来编写测试类
package com.bjpowernode.mybatis.test;
import com.bjpowernode.mybatis.mapper.StudentMapper;
import com.bjpowernode.mybatis.pojo.Student;
import com.bjpowernode.mybatis.utils.SqlSessionUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
public class StudentMapperTest {
@Test
public void testSelectByIdAssociation(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.selectByIdAssociation(2);
// 直接输出Student对象
System.out.println(student);
sqlSession.close();
}
}
执行结果:

1.3 第三种⽅式:分步查询(常用)
分布查询,需要两条SQL语句,这种⽅式常⽤:
①优点⼀是可复⽤。
②优点⼆是⽀持懒加载(延迟加载)
(1)分布查询第一步:先根据学生的sid查询学生信息
①在StudentMapper中编写第一步的查询方法
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Student;
public interface StudentMapper {
// 分布查询第一步:现根据学生的sid查询学生信息
Student selectByIdStep1(Integer id);
}
②在StudentMapper.xml中编写SQL语句,并指明两者之间的关联关系
还是需要association标签:
①property属性:还是提供要映射的POJO类的属性名,这里就是clazz;
②select属性:用来指定另外第二步SQL语句的id,这个id实际上就是namespace+id;通过第二步语句的查询结果,把值赋值给clazz;
③column属性:是把第一条SQL语句查询出来的cid传给第第二条SQL语句,然后第二条语句根据cid进行查询;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.StudentMapper">
<!--这是第一步:根据学生的id查询学生的所有信息,包含cid-->
<resultMap id="studentResultMapByStep" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname" />
<!--使用association标签,指明关联关系-->
<association property="clazz"
select="com.bjpowernode.mybatis.mapper.ClazzMapper.selectByIdStep2"
column="cid"/>
</resultMap>
<select id="selectByIdStep1" resultMap="studentResultMapByStep">
select sid,sname,cid from t_student where sid = #{sid};
</select>
</mapper>
(2)分布查询第二步:根据学生的cid查询班级信息
①在ClazzMapper中编写第二步的查询方法
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Clazz;
public interface ClazzMapper {
// 分布查询第二步:根据cid获取查询信息
Clazz selectByIdStep2(Integer cid);
}
②在ClazzMapper.xml中编写SQL语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.ClazzMapper">
<!--分布查询第二步:根据cid获取班级信息-->
<select id="selectByIdStep2" resultType="Clazz">
select cid,cname from t_clazz where cid = #{id};
</select>
</mapper>
(3)最终StudentMapperTest编写测试,因为Student是主表
package com.bjpowernode.mybatis.test;
import com.bjpowernode.mybatis.mapper.StudentMapper;
import com.bjpowernode.mybatis.pojo.Student;
import com.bjpowernode.mybatis.utils.SqlSessionUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
public class StudentMapperTest {
@Test
public void testSelectByIdStep1(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.selectByIdStep1(3);
System.out.println(student);
sqlSession.close();
}
}
执行结果:

1.4 多对⼀延迟加载
(1)延迟加载的核心是:用到的在查询,暂时访问不到的数据可以先不查询。
(2)作用:提⾼程序的执⾏效率;不用的时候也查性能肯定低,例如笛卡尔积现象
(3)在MyBatis中如何开启延迟加载:association标签当中添加fetchType=”lazy”
例1:不开启延迟加载机制,假如只访问学生表t_student的sname属性,和t_clazz表实际上是没有任何关系的
package com.bjpowernode.mybatis.test;
import com.bjpowernode.mybatis.mapper.StudentMapper;
import com.bjpowernode.mybatis.pojo.Student;
import com.bjpowernode.mybatis.utils.SqlSessionUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
public class StudentMapperTest {
@Test
public void testSelectByIdStep1(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.selectByIdStep1(3);
// System.out.println(student);
// 只访问sname属性
System.out.println(student.getSname());
sqlSession.close();
}
}
执行结果:实际上执行了两个查询语句,效率变低

例2:在asspciation标签中开启延迟机制,就能做到只执行第一条SQL语句,第二条不执行;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.StudentMapper">
<resultMap id="studentResultMapByStep" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname" />
<!--使用association标签,并开启延迟加载机制-->
<association property="clazz"
select="com.bjpowernode.mybatis.mapper.ClazzMapper.selectByIdStep2"
column="cid"
fetchType="lazy"/>
</resultMap>
<select id="selectByIdStep1" resultMap="studentResultMapByStep">
select sid,sname,cid from t_student where sid = #{sid};
</select>
</mapper>
执行结果:同样还是只访问学生表t_student的sname属性,此时就是只查询一张表即可

(4)在association标签中配置fetchType=“lazy”,实际上是局部的设置,只对当前的association关联的SQL语句起作用!
(5)那么怎样在mybatis中如何开启全局的延迟加载呢?需要setting配置,如下:

在核心配置文件mybatis-config.xml文件当中使用setting标签进行配置全局的延迟加载
<!--启⽤全局延迟加载机制-->
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
</settings>(6)开启全局延迟加载之后,所有的SQL都会⽀持延迟加载!但是如果某个SQL你不希望它⽀持延迟加载怎么办呢? 将fetchType设置为eager
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.StudentMapper">
<resultMap id="studentResultMapByStep" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname" />
<!--使用association标签,不开启延迟加载机制-->
<association property="clazz"
select="com.bjpowernode.mybatis.mapper.ClazzMapper.selectByIdStep2"
column="cid"
fetchType="eager"/>
</resultMap>
<select id="selectByIdStep1" resultMap="studentResultMapByStep">
select sid,sname,cid from t_student where sid = #{sid};
</select>
</mapper>
2. ⼀对多
一对多:一的一方在前面,那么一就是主表,多就是副表!例如:一个班级(主表)对应多个学生(副表)!
⼀对多的实现,通常是多的一方以List集合属性的方式出现在⼀的⼀⽅!

pojo类Clazz中添加⼀个属性:List<Student> stu; 表示班级关联的学生对象,增加setter and getter方法,重写toString方法。
package com.bjpowernode.mybatis.pojo;
import java.util.*;
public class Clazz {
private Integer cid;
private String cname;
private List<Student> stus;
public Clazz() {
}
public Clazz(Integer cid, String cname) {
this.cid = cid;
this.cname = cname;
}
@Override
public String toString() {
return "Clazz{" +
"cid=" + cid +
", cname='" + cname + '\'' +
", stus=" + stus +
'}';
}
public List<Student> getStus() {
return stus;
}
public void setStus(List<Student> stus) {
this.stus = stus;
}
public Integer getCid() {
return cid;
}
public void setCid(Integer cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
}
⼀对多的实现通常包括两种实现⽅式:
①第⼀种⽅式:collection
②第⼆种⽅式:分步查询
2.1 第⼀种⽅式:使用collection标签
注:这次t_calss是主表,所以是在ClazzMapper、ClazzMapper.xml、ClazzMapperTest当中完成一些列操作。
三兄弟之一:ClazzMapper接口,编写方法
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Clazz;
public interface ClazzMapper {
// 根据班级编号查询班级信息
Clazz selectByIdCollection(Integer cid);
}
三兄弟之二:ClazzMapper.xml文件,编写sql语句
使用collection标签,和上面使用association标签的第二种方法是很相似的:
①property属性:提供要映射的POJO类的属性名,这里就是stus
②ofType属性:用来指定集合当中的元素类型com.bjpowernode.mybatis.Student
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.ClazzMapper">
<resultMap id="clazzResultMap" type="Clazz">
<id property="cid" column="cid"/>
<result property="cname" column="cname"/>
<!--ofType用来指定集合当中的元素类型-->
<collection property="stus" ofType="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
</collection>
</resultMap>
<select id="selectByIdCollection" resultMap="clazzResultMap">
select
c.cid,c.cname,s.sid,s.sname
from
t_clazz c
left join
t_student s
on c.cid = s.cid
where c.cid = #{cid}
</select>
</mapper>
三兄弟之三:ClazzMappeTest类,用来编写测试类
package com.bjpowernode.mybatis.test;
import com.bjpowernode.mybatis.mapper.ClazzMapper;
import com.bjpowernode.mybatis.pojo.Clazz;
import com.bjpowernode.mybatis.utils.SqlSessionUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
public class ClazzMapperTest {
@Test
public void testSelectByIdCollection(){
SqlSession sqlSession = SqlSessionUtil.openSession();
ClazzMapper mapper = sqlSession.getMapper(ClazzMapper.class);
Clazz clazz = mapper.selectByIdCollection(1001);
System.out.println(clazz);
sqlSession.close();
}
}
执行结果:
查询的结果是stus变量是一个有三个数据的List集合,其中clazz是null属于正常现象,如果clazz还有值,就会与前面的Student形成递归循环

2.2 第⼆种⽅式:分步查询
(1)分布查询第一步:先根据班级编号获取班级信息
①在ClazzMapper中编写第一步的查询方法
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Clazz;
public interface ClazzMapper {
// 分布查询第一步:根据班级编号,获取班级信息
Clazz selectByStep1(Integer cid);
}
②在ClazzMapper.xml中编写SQL语句,并指明两者之间的关联关系
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.ClazzMapper">
<!--分布查询第一步:根据班级的cid获取班级信息-->
<resultMap id="clazzResultMapStep" type="Clazz">
<id property="cid" column="cid"/>
<result property="cname" column="cname"/>
<collection property="stus"
select="com.bjpowernode.mybatis.mapper.StudentMapper.selectByCidStep2"
column="cid" />
</resultMap>
<select id="selectByStep1" resultMap="clazzResultMapStep">
select cid,cname from t_clazz where cid = #{cid}
</select>
</mapper>
(2)分布查询第二步:根据学生的cid查询班级信息
①在StudentMapper中编写第二步的查询方法
package com.bjpowernode.mybatis.mapper;
import com.bjpowernode.mybatis.pojo.Student;
import java.util.List;
public interface StudentMapper {
// 分布查询第二步:根据班级编号查询学生信息
List<Student> selectByCidStep2(Integer cid);
}
②在StudentMapper.xml中编写SQL语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bjpowernode.mybatis.mapper.StudentMapper">
<select id="selectByCidStep2" resultType="Student">
select * from t_student where cid = #{cid}
</select>
</mapper>
(3)最终ClazzMapperTest编写测试,因为Clazz是主表
package com.bjpowernode.mybatis.test;
import com.bjpowernode.mybatis.mapper.ClazzMapper;
import com.bjpowernode.mybatis.pojo.Clazz;
import com.bjpowernode.mybatis.utils.SqlSessionUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
public class ClazzMapperTest {
@Test
public void testSelectByStep1(){
SqlSession sqlSession = SqlSessionUtil.openSession();
ClazzMapper mapper = sqlSession.getMapper(ClazzMapper.class);
Clazz clazz = mapper.selectByStep1(1001);
System.out.println(clazz);
sqlSession.close();
}
}
执行结果:
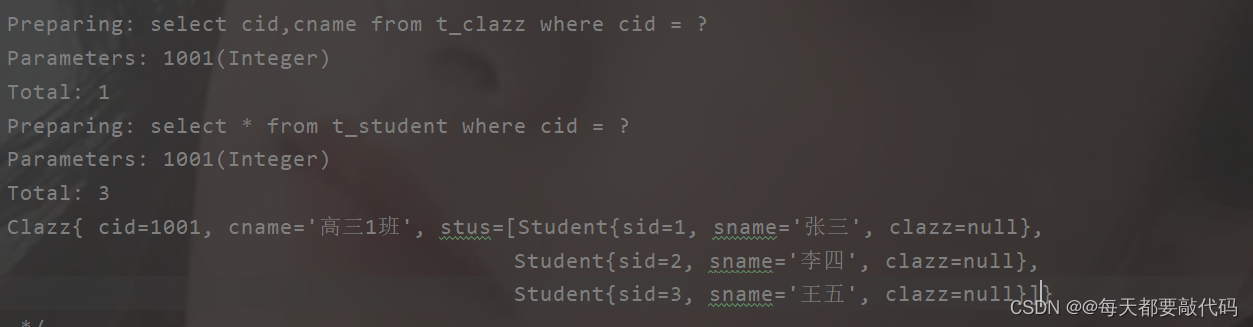
2.3 延迟加载
⼀对多延迟加载机制和多对⼀是⼀样的,同样是通过两种⽅式:
①第⼀种:fetchType=”lazy”;
②第⼆种:修改全局的配置setting,lazyLoadingEnabled=true;
注:如果开启全局延迟加载,想让某个 sql不使⽤延迟加载:fetchType=”eager”。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/128404.html

