
前言
本文是总结 详细请看下列:
(数据结构与数据类型区别_数据类型和数据结构的区别_IT技术学习的博客-CSDN博客
图解redis的压缩列表_编程界的谢菲尔德的博客-CSDN博客
(283条消息) 图解redis之整数集合_编程界的谢菲尔德的博客-CSDN博客
(283条消息) 图解redis的跳跃表_编程界的谢菲尔德的博客-CSDN博客
(283条消息) 图解redis的字典_编程界的谢菲尔德的博客-CSDN博客
(283条消息) 图解redis之链表的实现_编程界的谢菲尔德的博客-CSDN博客
(283条消息) redis之动态字符串sds的实现_编程界的谢菲尔德的博客-CSDN博客
引言
数据结构
什么是结构
结构是指在一个系统或者材料之中,互相关联的元素的排列、组织。结构按类别可分为等级结构
(有层次的一对多)、网格结构(多对多)、晶格结构(临近的个体互相连接)等。
相互之间存在一种或多种特定关系的数据元素的集合,包括逻辑结构和物理结构。定义了计算机存储、组织数据的方式
逻辑结构
逻辑结构是指数据元素之间的逻辑关系,它独立于数据在计算机的存储方式,可以看作是从具体问题抽象出来的数学模型
逻辑结构又分为:线性结构(有且只有一个开始结点和终端结点;所有结点最多只有一个直接前驱和一个直接后继),非线性结构(对应于线性结构,非线性结构每个结点可以有不止一个直接前驱和直接后继)
线性结构:数组、链表、栈、队列 …
非线性结构:集合、树、图…
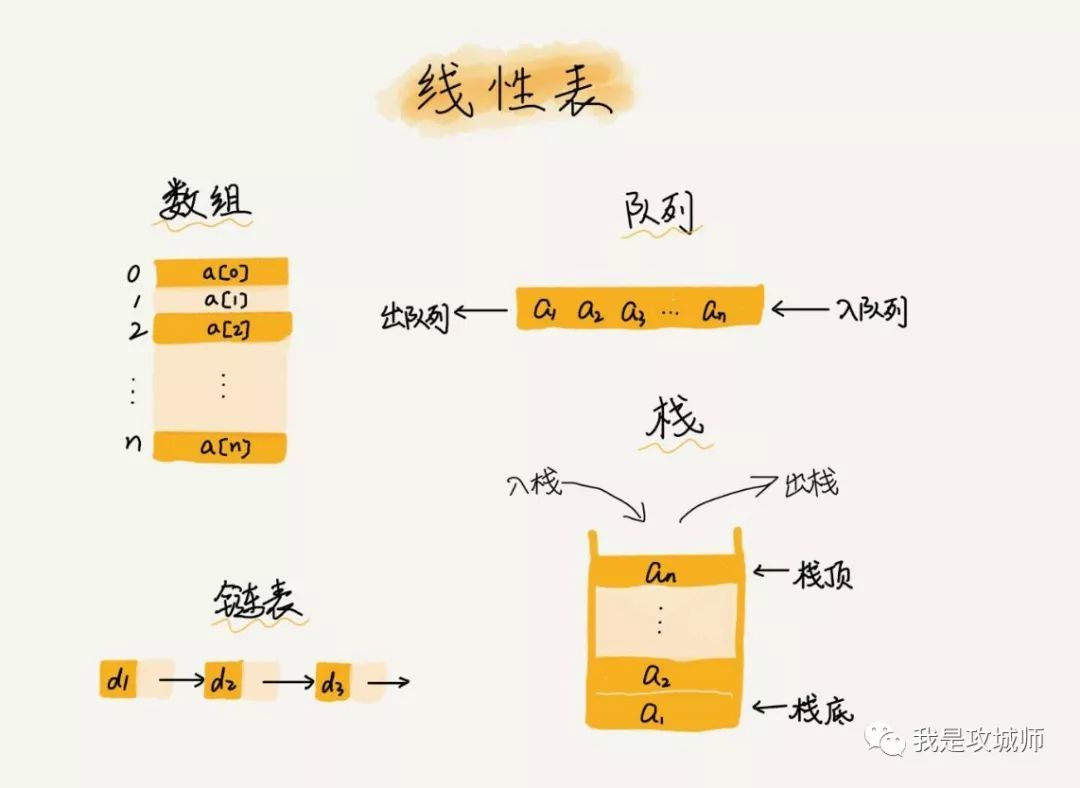
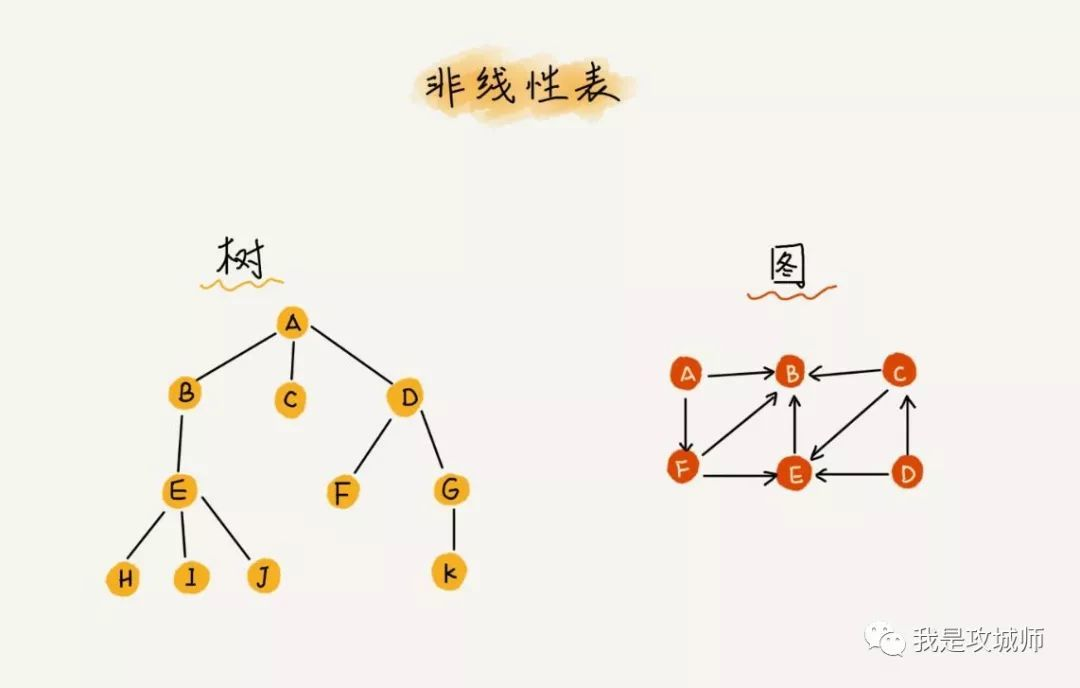
物理结构
物理结构也称存储结构,是逻辑结构用计算机语言的实现,它依赖于计算机语言。
数据的存储结构主要有:顺序存储、链式存储、索引存储、散列存储。
在具体实现存储时,可以选择在内存里开辟连续内存空间或不连续的内存空间,也可以混搭成更复杂的存储方式

顺序存储:存储的物理位置通常情况是连续分布的
链接存储:存储的物理位置未必连续,看实现方式,通过记录相邻元素的物理位置来找到相邻元素
索引存储:类似于树状目录,存储形式看实现方式
散列存储:通过关键字直接计算出元素的物理地址。存储形式看实现方式
数据类型
数据结构:相互之间存在一种或多种特定关系的数据元素的集合,包括逻辑结构和物理结构
数据类型:一个值的集合以及定义在这个值集合上的一组操作(增删改查读写…)的总称
数据类型和数据结构其实是所属关系
据类型有两种,是按照定义中“值的集合”来区分的。一、“值的集合”是数据结构,“数据结构”的集合和在该集合上的一组操作叫做结构类型。二、“值的集合”是基本的原子类型(int、double、char、byte、boolean、指针类型、空类型 …)再加上在该值集合上的操作就是原子类型
总之,数据结构是一种“值的集合”,这种值的集合+值集合上的操作 = 结构类型,而结构类型是数据类型中的一种。

举例redis
string(字符串)
redis的string数据类型由SDS数据结构+API组成
1)常数复杂度获取字符串长度。0(1)
存在一个len的结构成员
2)杜绝缓冲区溢出。
当SDS API需要对SDS进行修改时,API会先检查SDS的空间 是否满足修改所需的要求,如果不满足的话,API会自动将SDS的空间 扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS既不需要手动修改SDS的空间大小
3)减少修改字符串长度时所需的内存重分配次数。
1.空间预分配
如果对SDS进行修改之后,SDS的长度(也即是len属性的值)将 小于1MB,那么程序分配和len属性同样大小的未使用空间,这时SDS len属性的值将和free属性的值相同。
举个例子,如果进行修改之后, SDS的len将变成13字节,那么程序也会分配13字节的未使用空间,SDS 的buf数组的实际长度将变成13+13+1=27字节(额外的一字节用于保存 空字符)。
·如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序 会分配1MB的未使用空间。举个例子,如果进行修改之后,SDS的len将 变成30MB,那么程序会分配1MB的未使用空间,SDS的buf数组的实际 长度将为30MB+1MB+1byte
4)二进制安全。
通过len来判断 是否完结 杜绝“/0″的可能
5)兼容部分C字符串函数
hash(哈希)
hash=字典+压缩列表+API
字典重点:
字典被广泛用于实现Redis的各种功能,其中包括数据库和哈希键。 ·
Redis中的字典使用哈希表作为底层实现,每个字典带有两个哈希 表,一个平时使用,另一个仅在进行rehash时使用。
·当字典被用作数据库的底层实现,或者哈希键的底层实现时, Redis使用MurmurHash2算法来计算键的哈希值。
·哈希表使用链地址法来解决键冲突,被分配到同一个索引上的多个键值对会连接成一个单向链表。
在对哈希表进行扩展或者收缩操作时,程序需要将现有哈希表包 含的所有键值对rehash到新哈希表里面,并且这个rehash过程并不是一 次性地完成的,而是渐进式地完成的。
压缩列表:
压缩列表是一种为节约内存而开发的顺序型数据结构。
·压缩列表被用作列表键和哈希键的底层实现之一。
·压缩列表可以包含多个节点,每个节点可以保存一个字节数组或 者整数值。
·添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引 发连锁更新操作,但这种操作出现的几率并不高
list(列表)
list=list+ziplist
链表被广泛用于实现Redis的各种功能,比如列表键、发布与订 阅、慢查询、监视器等。
·每个链表节点由一个listNode结构来表示,每个节点都有一个指向 前置节点和后置节点的指针,所以Redis的链表实现是双端链表。
·每个链表使用一个list结构来表示,这个结构带有表头节点指针、 表尾节点指针,以及链表长度等信息。
·因为链表表头节点的前置节点和表尾节点的后置节点都指向 NULL,所以Redis的链表实现是无环链表。
·通过为链表设置不同的类型特定函数,Redis的链表可以用于保存 各种不同类型的值
set(集合)
set=整数集合+API
整数集合是集合键的底层实现之一。
·整数集合的底层实现为数组,这个数组以有序、无重复的方式保 存集合元素,在有需要时,程序会根据新添加元素的类型,改变这个数 组的类型。
·升级操作为整数集合带来了操作上的灵活性,并且尽可能地节约 了内存。 ·整数集合只支持升级操作,不支持降级操作。
sort set (有序集合)
sortset=跳跃表+API
跳跃表
·跳跃表是有序集合的底层实现之一。
·Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成,其中 zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度),而 zskiplistNode则用于表示跳跃表节点。
·每个跳跃表节点的层高都是1至32之间的随机数。
·在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点 的成员对象必须是唯一的。 ·跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按 照成员对象的大小进行排序
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/129597.html

