
压缩列表(ziplist)是列表键和哈希键的底层实现之一。
当一个列 表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是 长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层 实现
举例:
redis> RPUSH lst 1 3 5 10086 "hello" "world"
(integer)6
redis> OBJECT ENCODING lst
"ziplist"列表键里面包含的都是1、3、5、10086这样的小整数值,以 及”hello”、”world”这样的短字符串。 另外,当一个哈希键只包含少量键值对,比且每个键值对的键和值 要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使 用压缩列表来做哈希键的底层实现
举个例子:
redis> HMSET profile "name" "Jack" "age" 28 "job" "Programmer"
OK
redis> OBJECT ENCODING profile
"ziplist"压缩列表
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的 连续内存块组成的顺序型(sequential)数据结构。
一个压缩列表可以包 含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值
展现压缩列表的各个组成部分:
![]()
![]()
| 属性 | 类型 | 长度 | 用途 |
| zlbytes | uint32_t | 4字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或计算zlend的位置使用 |
| zltail | uint_32 | 4字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量.程序无须遍历整个压缩列表就可以确定表尾节点的地址 |
| zllen | uint_16 | 2字节 | 记录了压缩列表包含的节点数量:当这个属性的值小于UINT16_MAX(65535)时,这个属性的值就是压缩列表包含节点的数量:当这个值等于UINT16 MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出 |
| entryX | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | uint_8 | 1字节 | 特殊值OxFF(十进制255),用于标记压缩列表的末端 |
图表示例:
·列表zlbytes属性的值为0x50(十进制80),表示压缩列表的总长为 80字节。
·列表zltail属性的值为0x3c(十进制60),这表示如果我们有一个 指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量60,就可以计算出表尾节点entry3的地址
列表zllen属性的值为0x3(十进制3),表示压缩列表包含三个节点


图表示例二:
列表zlbytes属性的值为0xd2(十进制210),表示压缩列表的总长 为210字节。
·列表zltail属性的值为0xb3(十进制179),这表示如果我们有一个 指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量179,就 可以计算出表尾节点entry5的地址。
·列表zllen属性的值为0x5(十进制5),表示压缩列表包含五个节 点。

压缩节点构成
每个压缩列表节点可以保存一个字节数组或者一个整数值,
其中, 字节数组可以是以下三种长度的其中一种:
·长度小于等于63(2 6–1)字节的字节数组;
·长度小于等于16383(2 14–1)字节的字节数组;
·长度小于等于4294967295(2 32–1)字节的字节数组
而整数值则可以是以下六种长度的其中一种:
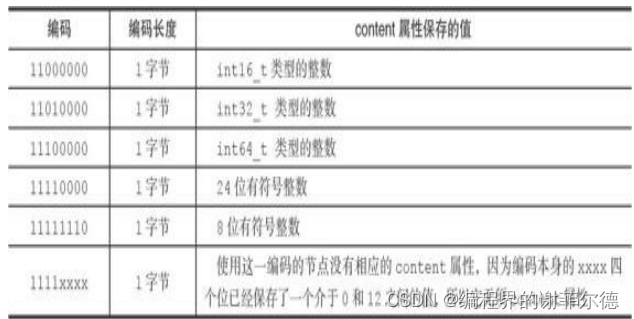
4位长,介于0至12之间的无符号整数;
·1字节长的有符号整数; ·
3字节长的有符号整数;
·int16_t类型整数;
·int32_t类型整数;
·int64_t类型整数。
每个压缩列表节点都由previous_entry_length、encoding、content三 个部分组成
![]()
![]()
解析:
previous_entry_length
节点的previous_entry_length属性以字节为单位,记录了压缩列表中前一个节点的长度。previous_entry_length属性的长度可以是1字节或者5字节:
如果前一节点的长度小于254字节,那么previous_entry_length属性 的长度为1字节:前一节点的长度就保存在这一个字节里面。
·如果前一节点的长度大于等于254字节,那么previous_entry_length 属性的长度为5字节:其中属性的第一字节会被设置为0xFE(十进制值 254),而之后的四个字节则用于保存前一节点的长度(方便遍历)
endcoding
节点的encoding属性记录了节点的content属性所保存数据的类型以 及长度: ·
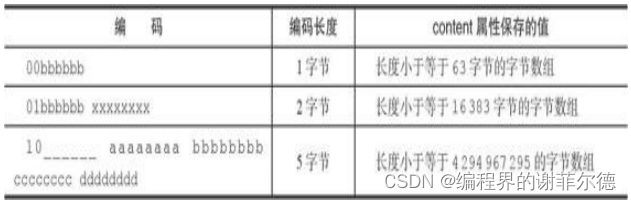
一字节、两字节或者五字节长,值的最高位为00、01或者10的是 字节数组编码:这种编码表示节点的content属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录;
·一字节长,值的最高位以11开头的是整数编码:这种编码表示节 点的content属性保存着整数值,整数值的类型和长度由编码除去最高两 位之后的其他位记录
字节数组编码
整数编码
content:
节点的content属性负责保存节点的值,节点值可以是一个字节数组 或者整数,值的类型和长度由节点的encoding属性决定
编码的最高两位00表示节点保存的是一个字节数组;
·编码的后六位001011记录了字节数组的长度11;
·content属性保存着节点的值”hello world”

连锁更新
每个节点的previous_entry_length属性都记录了前一个节 点的长度:
·如果前一节点的长度小于254字节,那么previous_entry_length属性 需要用1字节长的空间来保存这个长度值。
·如果前一节点的长度大于等于254字节,那么previous_entry_length 属性需要用5字节长的空间来保存这个长度值
现在,考虑这样一种情况:在一个压缩列表中,有多个连续的、长 度介于250字节到253字节之间的节点e1至eN,
![]()
![]()
因为e1至eN的所有节点的长度都小于254字节,所以记录这些节点 的长度只需要1字节长的previous_entry_length属性,换句话说,e1至eN 的所有节点的previous_entry_length属性都是1字节长的
如果我们将一个长度大于等于254字节的新节点new设置为压 缩列表的表头节点,那么new将成为e1的前置节点
![]()
![]()
因为e1的previous_entry_length属性仅长1字节,它没办法保存新节 点new的长度,所以程序将对压缩列表执行空间重分配操作,并将e1节 点的previous_entry_length属性从原来的1字节长扩展为5字节长
现在,麻烦的事情来了,e1原本的长度介于250字节至253字节之 间,在为previous_entry_length属性新增四个字节的空间之后,e1的长度 就变成了介于254字节至257字节之间,而这种长度使用1字节长的 previous_entry_length属性是没办法保存的
因此,为了让e2的previous_entry_length属性可以记录下e1的长度, 程序需要再次对压缩列表执行空间重分配操作,并将e2节点的 previous_entry_length属性从原来的1字节长扩展为5字节长。 正如扩展e1引发了对e2的扩展一样,扩展e2也会引发对e3的扩展, 而扩展e3又会引发对e4的扩展……为了让每个节点的 previous_entry_length属性都符合压缩列表对节点的要求,
程序需要不断 地对压缩列表执行空间重分配操作,直到eN为止。 Redis将这种在特殊情况下产生的连续多次空间扩展操作称之为“连锁更新”(cascade update)
要注意的是,尽管连锁更新的复杂度较高,但它真正造成性能问题 的几率是很低的:
·首先,压缩列表里要恰好有多个连续的、长度介于250字节至253 字节之间的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见;
·其次,即使出现连锁更新,但只要被更新的节点数量不多,就不 会对性能造成任何影响:比如说,对三五个节点进行连锁更新是绝对不 会影响性能的
因为以上原因,ziplistPush等命令的平均复杂度仅为O(N),在实 际中,我们可以放心地使用这些函数,而不必担心连锁更新会影响压缩 列表的性能
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/129598.html

