
1.hash与红黑树的区别:
权衡三个因素: 查找速度, 数据量, 内存使用,可扩展性,有序性。
hash查找速度会比RB树快,而且查找速度基本和数据量大小无关,属于常数级别;而RB树的查找速度是log(n)级别。并不一定常数就比log(n) 小,因为hash还有hash函数的耗时。当元素达到一定数量级时,考虑hash。但若你对内存使用特别严格, 希望程序尽可能少消耗内存,那么hash可能会让你陷入尴尬,特别是当你的hash对象特别多时,你就更无法控制了,而且 hash的构造速度较慢。
- 红黑树是有序的,Hash是无序的,根据需求来选择。
- 红黑树占用的内存更小(仅需要为其存在的节点分配内存),而Hash事先应该分配足够的内存存储散列表,即使有些槽可能弃用
- 红黑树查找和删除的时间复杂度都是O(logn),Hash查找和删除的时间复杂度都是O(1)。
2.hash的基本知识
哈希表(Hash table,也叫散列表),是根据键值(Key)而直接进行访问的数据结构。也就是说,它通过把键值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key),adr = f(key)。查找时,根据这个确定的对应关系找到给定值key的映射f(key),若查找集合中存在这个记录,则必定在f(key)的位置上。我们把这种对应关系f称为散列函数,又称为哈希函数(Hash).按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表或哈希表(Hash table)。关键字对应的记录存储位置称为散列地址
除留余数法(这是为什么hash的表一般都是素数)
最常用的构造散列函数的方法。对于散列表长为m的散列函数公式为:f(key) = key mod p(p≤m)这种方法不仅可以对关键字直接取模,也可在折叠、平方取中后再取模。**散列表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。
举个例子,哈希函数是H(k)=k Mod m。m=12,k=100,H(100)=4。
而如果m=2k,那么无论k是什么,H(K)的值都是一个0和奇数,也即是说只要奇数槽和0槽被占用,其他的偶数槽都是浪费掉了。如果m=2^r,那么H(k)的值就是k的低r位(化成二进制)。这样造成的后果是某一个槽有很多的关键字。所以来说一般的m取值尽量不要接近2的整数幂,而且还要是质数。
3.解决hash冲突
剩下的主要编程细节是解决冲突。如果当–个元素在插入时与一个已经插入的元素散列到相同的值,那么就产生·个冲突,这个冲突需要消除。解决这种冲突的方法有几种,我们将讨论其中最简单的两种:分离链接法和开放定址法。
3.1分离链接法
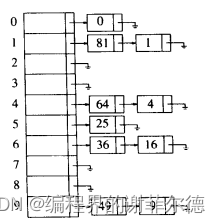
解决冲突的第一种方法通常称为分离链接法(separate chaining),其做法是将散列到同-个值的所有元素保留到一个链表中。可以使用标准库中表的实现方法。如果空间很紧,则更可取的方法是避免使用它们(因为这些表是双向链表,浪费空间)。本节假设键是前10个完全平方数并设散列函数就是hash(x) =.x mod 10(表的大小不是素数,用在这里只是为了简单)。下图:
主要代码
#include<list>
#include<vector>
#include<string>
#include<iostream>
using namespace std;
template <typename T>
class HashTable
{
private:
vector<list<T> > theLists;
int myhash(T x)//对不同类型的数据可以用不同的hash函数
{
return hash(x);
}
int hash(int x)//对int类型的hash函数,在这里hash函数为简单的取余函数
{
return x % theLists.size();
}
int hash(const string key)
{
return key.size()%theLists.size();
}
public:
HashTable(int s = 11){//构造函数,默认初始链表数为11
theLists.resize(s);
}
~HashTable()//析构函数
{
makeEmpty();
}
void makeEmpty()//清空所有链表
{
for(int i = 0;i < theLists.size();i++)
theLists.at(i).clear();
}
bool contain(T x)//查找元素
{
list<int> ali=theLists.at(myhash(x));
list<int>::iterator ir=ali.begin();
for(;ir != ali.end();ir++){
if (*ir == x)
return true;
}
return false;
}
void remove(T x)//删除元素
{
list<int>*ali=&theLists.at(myhash(x));
list<int>::iterator ir=ali->begin();
for(;ir!=ali->end();ir++)
{
if(*ir == x)
{
ir=ali->erase(ir);
}
}
}
void insert(T x)//插入元素
{
theLists.at(myhash(x)).push_back(x);
}
void print()//显示哈希表的元素结构
{
for(int i=0;i<theLists.size();i++){
cout<<"第"<<i<<"条链表:";
if(theLists.at(i).empty())
cout<<"(empty)"<<endl;
else{
list<int>::iterator ir=theLists.at(i).begin();
cout << "[ " << *ir++;
while( ir != theLists.at(i).end())
cout << ", " << *ir++;
cout << " ]" << endl;
}
}
}
void rehash()//再散列
{
vector<list<T> > oldLists=theLists;
theLists.resize(2 * theLists.size() + 1);
for(int j =0;j<theLists.size();j++)
theLists[j].clear();
for(int i =0; i<oldLists.size( );i++)
{
typename list<T>::iterator itr=oldLists[i].begin();
while(itr!=oldLists[i].end())
{
insert(*itr);
itr++;
}
}
}
};
测试程序:
#include"../include/list_hash.hpp"
#include"iostream"
using namespace std;
int main(int argc, char* argv[])
{
HashTable<int> ha;
for(int j = 0;j <= 100;j++)
{
ha.insert(j*j);
}
ha.print();
if(ha.contain(400))
{
cout<<"有"<<endl;
}
ha.remove(400);
if(ha.contain(400))
{
cout<<"有"<<endl;
}
else
{
cout<<"无"<<endl;
}
cout<<endl;
ha.print();
ha.rehash();
cout<<"再散列"<<endl;
ha.print();
return 0;
}开放地址法
1.线性检测
在线性探测中,函数f是i的线性函数,一般情况下f(i) = i。这相当于逐个探测每个单元(使目回绕)来查找出空单元。
缺点一次聚焦:
这样占据的单元也会开始形成一些区块,其结果称为一次聚集(primaryclustering),于是,散列到区块中的任何键都需要多次试选单元才能够解决冲突,然后该键才被添加到相应的区块中。
2.平方检测:
平方探测是消除线性探测中一次聚集问题的冲突解决方法。平方探测就是冲突函数为二次函数的探测方法。流行的选择是f(i)= i2;
对于线性探测,让散列表近乎填满元素是个坏主意,因为此时表的性能会降低。对于平方探测,情况甚至更糟:旦表被填满超过一半,若表的大小不是素数,那么甚至在表被填满–半之前,就不能保证找到空的单元了。这是因为最多只有表的一半可以用做解决冲突的备选位置。
#include <iostream>
using namespace std;
const int HashSize=13;
class HashTable
{
private:
int *hashtable;
public:
//int *hashtable;
HashTable(){
hashtable=new int[HashSize];
if(hashtable==NULL){
cerr<<"hashtable init failed"<<endl;
//exit(0);
}
for(int i=0 ; i<HashSize ; i++)
hashtable[i]=-1;
}
~HashTable(){
delete []hashtable;
}
unsigned HashValue(unsigned value){
int key;
key=(unsigned)(value % HashSize);
if(hashtable[key]!=-1)
return HashValue(key+1);
return key;
}
void HashInsert(unsigned value){
int key=HashValue(value);
hashtable[key]=value;
}
int HashFind(unsigned value){
int key=(unsigned)(value % HashSize);
int i=0;
while(hashtable[key]!=-1 && i++<HashSize){
if(hashtable[key]==value)
return key;
else
key=(key+1)%HashSize;
}
return -1;
}
};版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/129654.html

