
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
初始redis
前言
提示:这里可以添加本文要记录的大概内容:
Redis 是一个 Key-Value 存储系统。和 Memcached 类似,它支持存储的 value 类型相对更多,
包括 string(字符串)、list(链表)、set(集合)和 zset(有序集合)。这些数据类型都支持 push/pop、
add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础
上,Redis 支持各种不同方式的排序。与 memcached 一样,为了保证效率,数据都是缓存在
内存中。区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录
文件,并且在此基础上实现了 master-slave(主从)同步。
提示:以下是本篇文章正文内容,下面案例可供参考
一、redis是什么?
Redis 是一个 Key-Value 存储系统。和 Memcached 类似,它支持存储的 value 类型相对更多,包括 string(字符串)、list(链表)、set(集合)和 zset(有序集合)。这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而这些操作都是原子性的。在此基础上,Redis 支持各种不同方式的排序memcached 一样,为了保证效率,数据都是缓存在内存中。区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave(主从)同步。Redis 是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、
Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。
二、简介什么是key-value
系统按照分布式领域的 CAP 理论(Consistency、 Availability、Tolerance to network Partitions 这三部分在任何系统架构实现时只可能同时满足其中二点,没法三者兼顾)来衡量,传统的关系 。数据库的 ACID 只满足了 Consistency、Availability,因此在 Partition tolerance 上就很难做得好。另外传统的关系数据库处理海量数据、分布式架构时候在 Performance、Scalability、Availability 等方面也存在很大的局限性。Key-Value Store 更加注重对海量数据存取的性能、分布式、扩展性支持上,并不需要传统关系数据库的一些特征,例如:Schema、事务、完整 SQL 查询支持等等,因此在分布式环境下的性能相对于传统的关系数据库有较大的提升
三、为什么使用key—value stroe
每时每刻都有无数的用户在使用它们提供的互联网服务,这些服务带来的就是大量的数据吞吐量 升级服务器性能:一类仍然采用 RDBMS,然后通过对数据库的垂直和水平切割将整个数据库部署到一个集群上,缺点在于它是针对特定应用
。云存储简单点说就是构建一个大型的存储平台给别人用,这也就意味着在这上面运行的应用其实是不可控的。如果其中某个客户的应用随着用户的增长而不断增长时 供应商不了解这个数据自然就没法作出切割。在这种情况下,key-value 的 store 就是唯一的选择了,因为这种条件下的 scalability 必须是自动完成的,不
能有人工干预。。
一方面,是指 Key-Value Store 可以支持极大的数据的存储,
它的分布式的架构决定了只要有更多的机器,就能够保证存储更多的数据。另一方面,是指它可以支持数量很多的并发的查询。对于 RDBMS,一般几百个并发的查询就可以让它很吃力了,而一个 Key-Value Store,可以很轻松的支持上千的并发查询
四、新浪微博实战分析(最广泛使用redis)
第一种是应用程序直接访问 Redis 数据库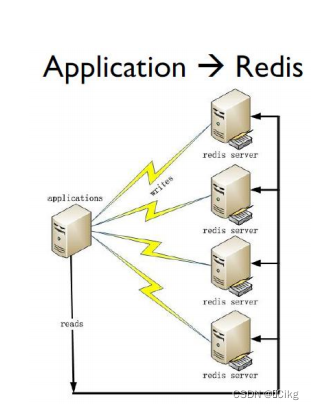
第二种是应用程序直接访问 Redis,只有当 Redis 访问失败时才访问 MySQL

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/129741.html

