
目录
前言
在 Redis 中关于缓存雪崩、缓存穿透、缓存击穿、缓存预热是常考的问题,我们不光要知道他的大概,还需要弄清其中的原理,那么接下来在学习他们之前,首先因该先了解什么是缓存~
一、缓存
1.1、程序中缓存是什么样的?
在程序中,没有缓存的时候,调用流程是这样的:
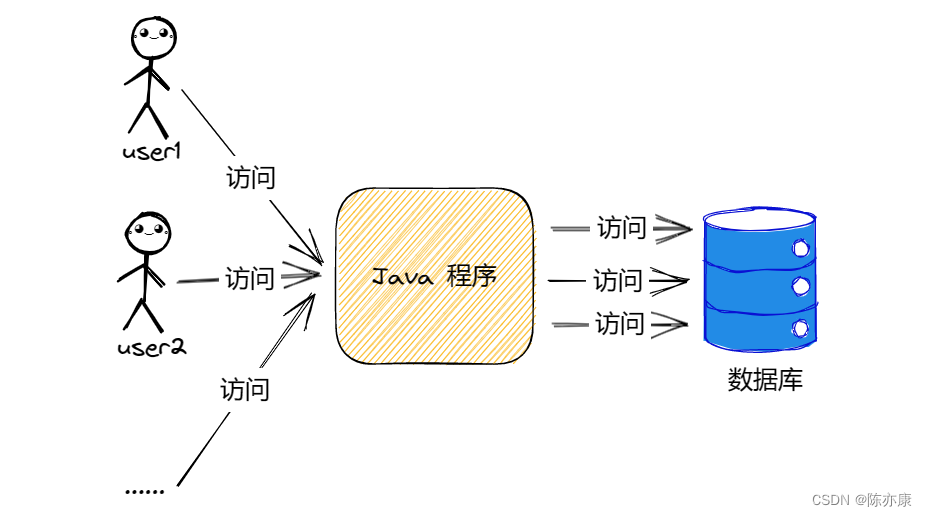
当我们加入缓存以后,程序就会变成以下样子:
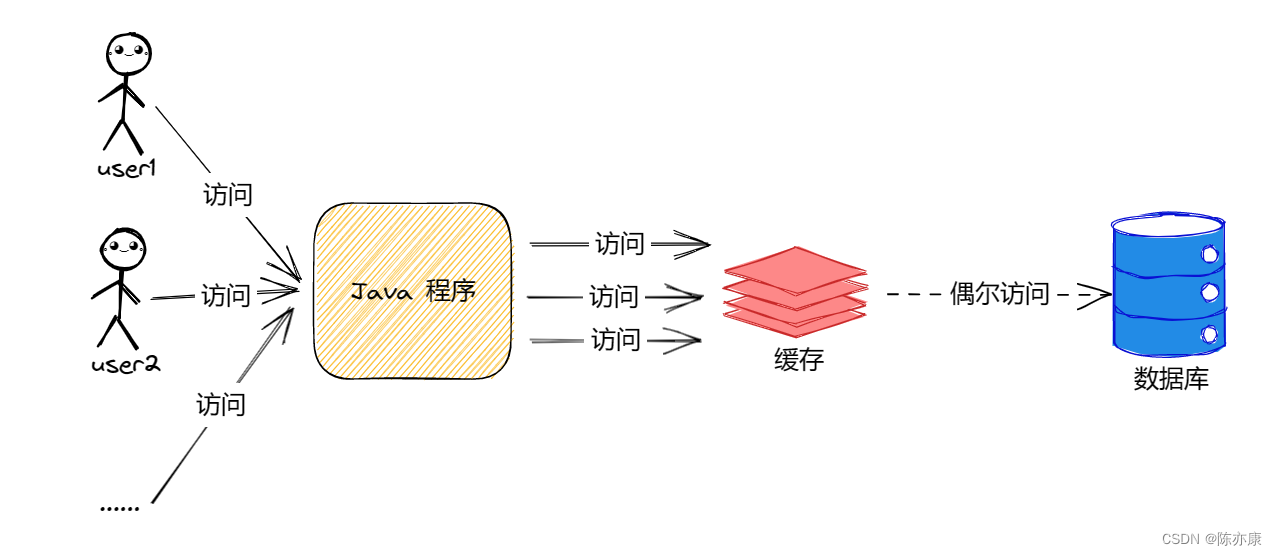
加入缓存之后,程序不糊直接调用书库,而是先调用缓存,当缓存中存在数据就直接返回,当缓存中没有数据才去查询数据库大大降低了数据库的压力,加快了程序响应的速度。
1.2、缓存的优点
相对于数据库而言,缓存的操作性更高效,原因有以下几点:
- 缓存一般使用 key-value 查询数据的,不需要想数据库那样还有查询条件。
- 缓存的数据存储在内存中,而数据库的数据是存储在磁盘中的,内存的操作性能远远大于磁盘。
- 缓存更容易实现分布式部署(一台服务器变成多态相连的服务器集群),而数据库比较难实现分布式部署,缓存的性能更容易平行扩展。
1.3、缓存的分类
缓存可以分为以下两类:
- 本地缓存:也叫单机缓存,也就是说在一台服务器上缓存,因此只适用于当前系统。
- 分布式缓存:用来应用在分布式系统中的缓存。分布式系统就是将一套服务器部署到多台服务器,通过负载(通常是 Nginx)分发将用户的请求按照一定的规则分发到不同服务器上,如下图:

在上图中加入分布式缓存后就变成了下图:

二、缓存特性
2.1、缓存雪崩
2.1.1、雪崩问题
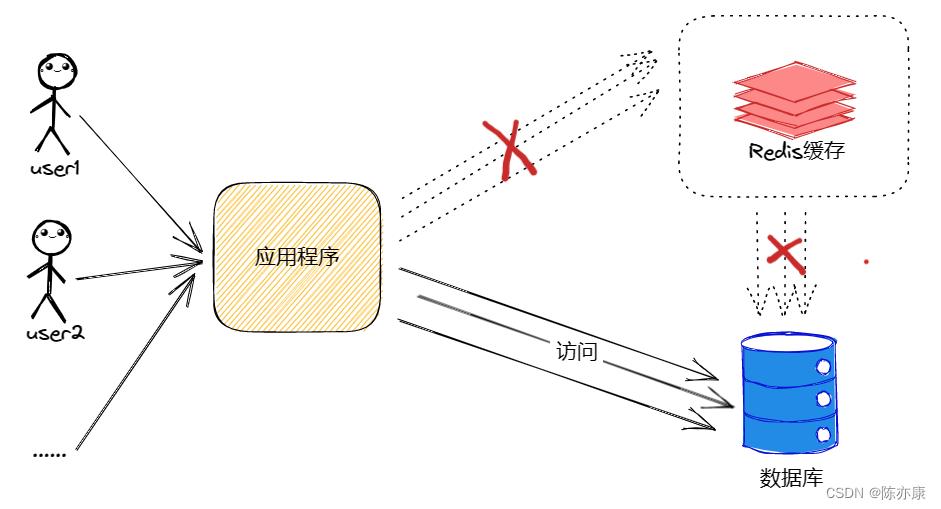
缓存雪崩是指在短时间内大量缓存同时过期,导致大量请求直接查询数据库, 从而对数据库造成巨大压力,严重情况下可能会导致数据库宕机。
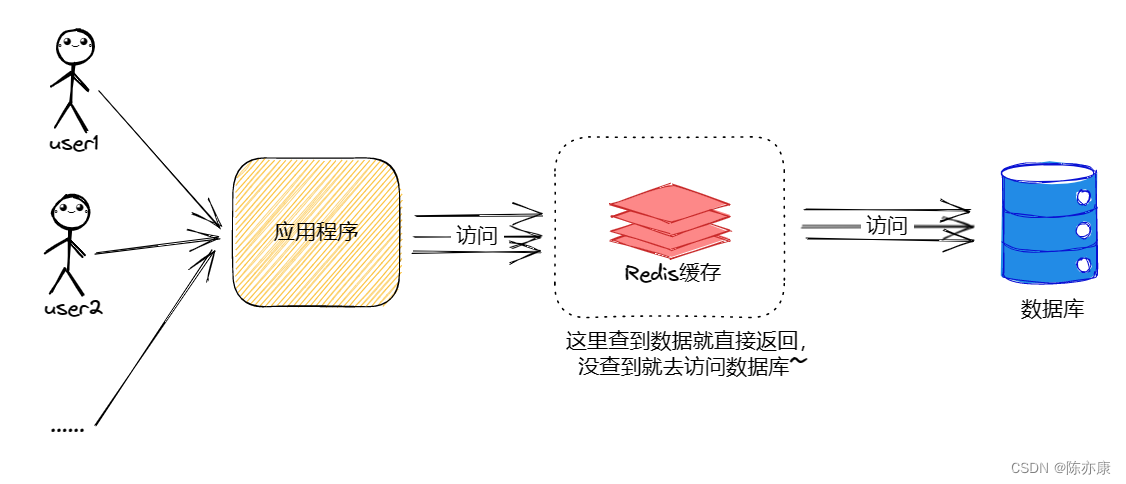
我们来对比一下正常情况与缓存雪崩情况:
正常情况:
雪崩情况:
2.1.2、如何解决缓存雪崩问题
解决方案有以下几种:
- 加锁排队:起到缓冲作用,防止大量请求同时操作数据库,但缺点是增加了系统的响应时间,降低了系统的吞吐量,牺牲一部分用户体验。
- 随机化过期时间:为了避免缓存同时过期,可以设置缓存时添加随机时间,这样就可以极大的避免大量缓存同时失效,如下代码
// 缓存原本的失效时间 int exTime = 10 * 60; // 随机数⽣成类 Random random = new Random(); // 缓存设置 jedis.setex(cacheKey, exTime+random.nextInt(1000) , value); - 设置二级缓存:二级缓存是除了 Redis 本身的缓存,再设置一层缓存,当 Redis 失效后,就先去查询二级缓存,如下图:
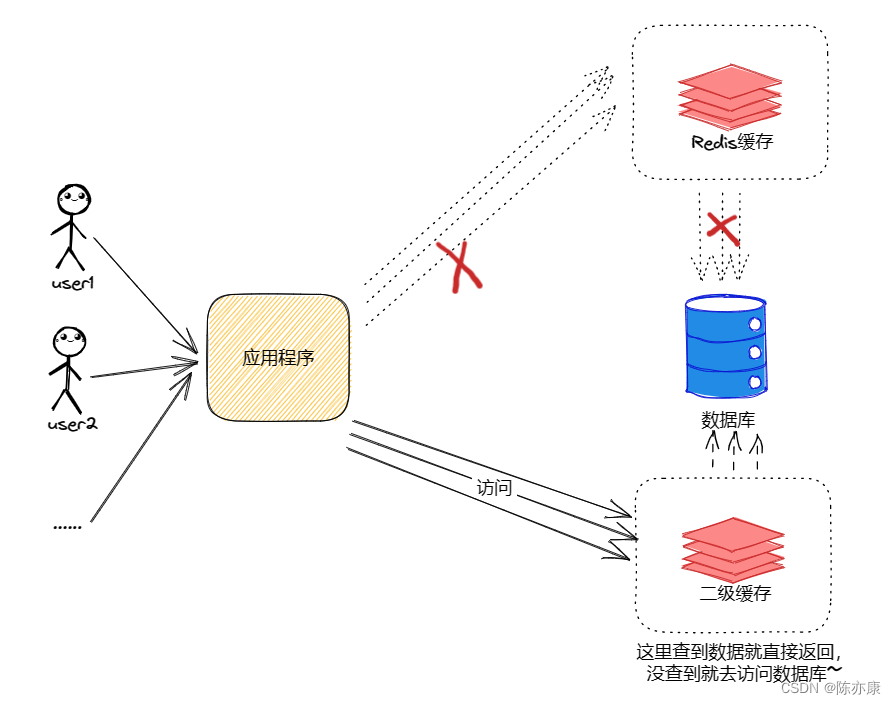

2.2、缓存穿透
2.2.1、穿透问题
缓存穿透是指查询数据库和缓存都无数据,因此每次请求都会去查询数据库,如下图:
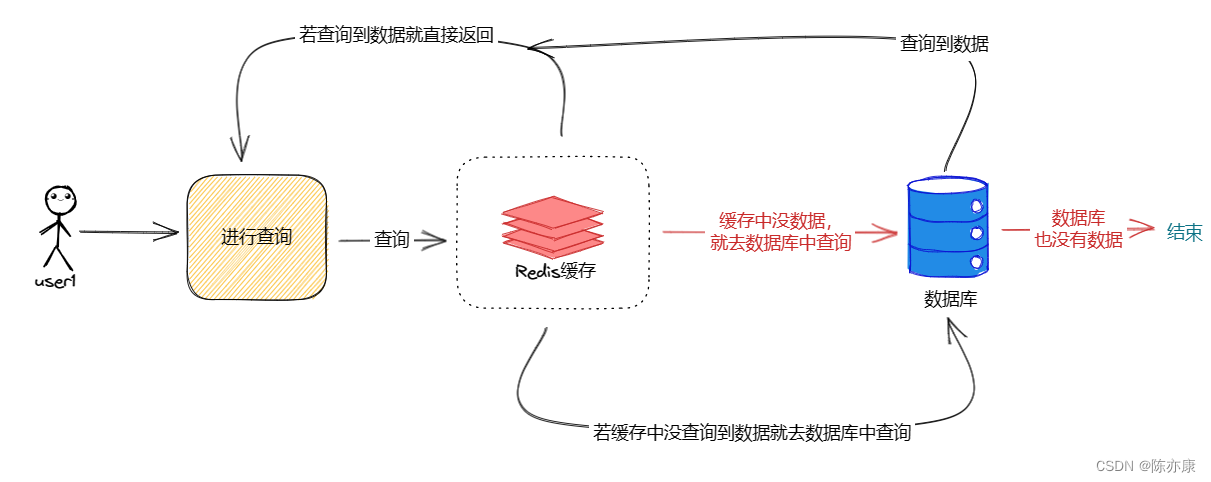
红色表示缓存穿透的执行路径,可以看出缓存穿透会给数据库造成巨大的压力。
如何解决这种问题呢?往下看~
2.2.2、如何解决缓存穿透问题
有以下几种解决方案:
- 缓存空结果:对查询的空结果也进行缓存,如果是集合,可以缓存一个空的的集合,如果是缓存单个对象,可以字段标识来区分,避免请求穿透到数据库。
- 布隆过滤器处理:将所有可能对应的数据为空的 key 进行统一的存放,并在请求前做拦截,避免请求穿透到数据库(这样的方式实现起来相对麻烦,比较适合命中不高,但是更行不频繁的数据)。
2.3、缓存击穿
2.3.1、击穿问题
缓存击穿是指某个经常使用的缓存,在某一个时刻恰好失效了(例如缓存过期),并且此时刚好有大量的并发请求,这些请求就会给数据库造成巨大的压力,如下图所示:
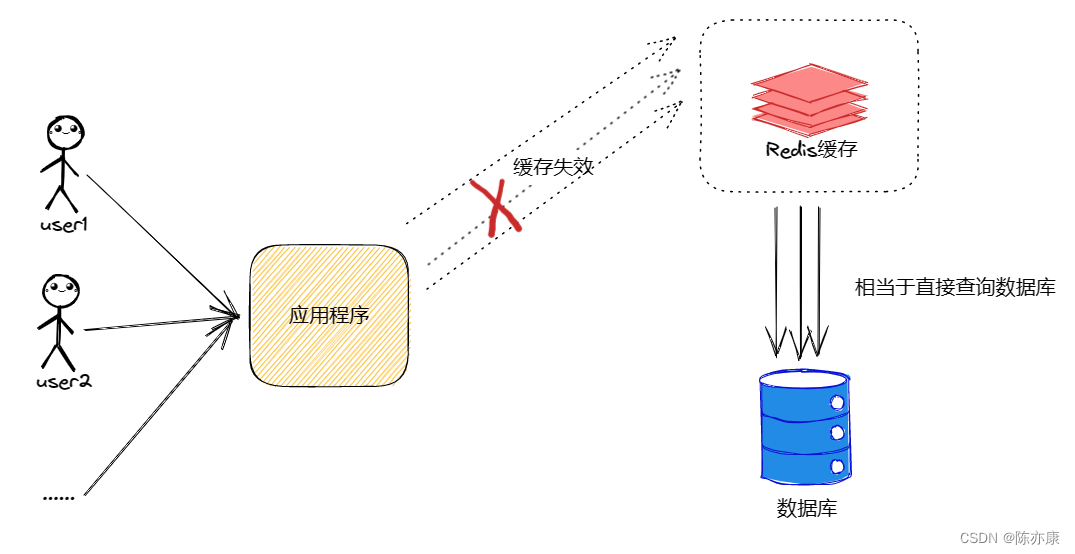
2.3.2、如何解决缓存击穿问题
有以下几种解决方案:
- 加锁排队:和处理缓存雪崩的加锁类似,都是在查询数据库的时候加锁排队,缓存操作请求以此来减少服务器的运行压力。
- 设置永不过时:对于某些经常使用的缓存,我们可以设置为永不过期,这样就能保证缓存的稳定性,但要注意在数据更改后,要及时更新此热点缓存,否则就会造成查询结果误差。
2.4、缓存预热
2.4.1、预热优化机制
缓存预热是一种优化方案,它可以提高用户的使用体验。
缓存预热是指在系统启动的时候,先把查询结果预存到缓存中,以便用户后面查询时可以直接从缓存中读取,节省用户等待时间,示意图如下:
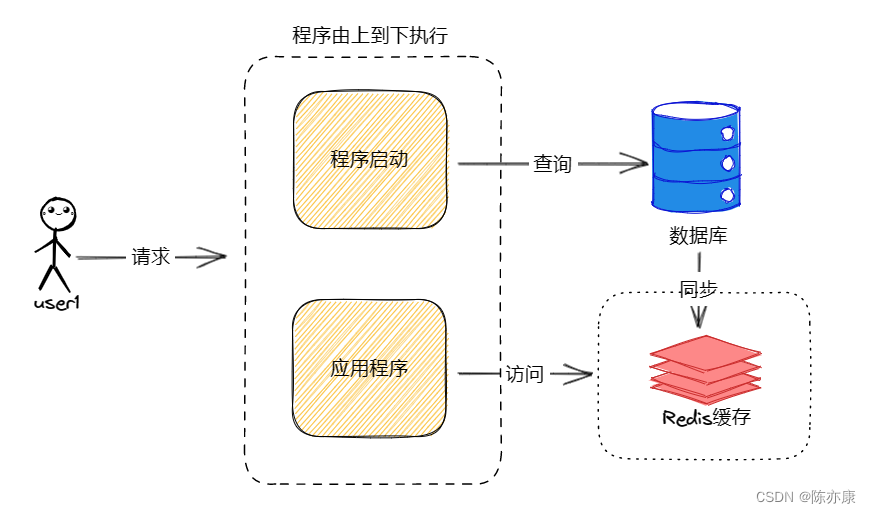
2.4.2、缓存预热实现思路
有以下几种实现办法:
- 把需要缓存的方法写在初始化方法中,让程序启动时自动加载数据并缓存数据。
- 把需要缓存的方法挂在某个页面或是后端接口上,手动触发缓存预热。
- 设置定时任务,定时进行缓存预热。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/130351.html

