
作者:非妃是公主
专栏:《机器学习》
个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩
专栏地址
专栏系列文章

集成学习基础知识
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。
有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning) 等。
集成学习先产生一组“个体学习器” (individual learner) ,再用某种策略将它们结合起来。
集成学习分同质集成和异质集成。同质集成中的个体学习器由相同的学习算法生成,个体学习器称为基学习器;异质集成中的个体学习器由不同的学习算法生成,个体学习器称为组件学习器。
集成学习要显著优于单一个体学习器必须满足两个必要条件:
1)个体学习器之间应该是相互独立的;
2)个体学习器应当好于随机猜测学习器。
满足第2个条件往往比较容易,因为在现实任务中,出于种种考虑,比如希望使用较少的个体学习器,或者是希望重用关于常见学习器的一些经验等,人们往往会使用比较强的个体学习器。
满足第1个条件往往比较困难,个体学习器是为解决同一个问题训练出来的,显然不可能互相独立!事实上,个体学习器的“准确性”和“多样性”本身就存在冲突。一般的,准确性很高之后,要增加多样性就需要牺牲准确性。
因此,如何产生“好而不同”的个体学习器是集成学习研究的核心!
集成学习常用方法
那么,如何在保持个体学习器足够“好”的前提下增强多样性呢?一般的思路是在学习过程中引入随机性,常用方法主要包括:
训练样本扰动

输入属性扰动

输出标记扰动

算法参数扰动

混合扰动

集成学习结合策略


偏差与方差

偏差:学习算法的误差率
方差:在改变数据集后,学习算法误差率的方差
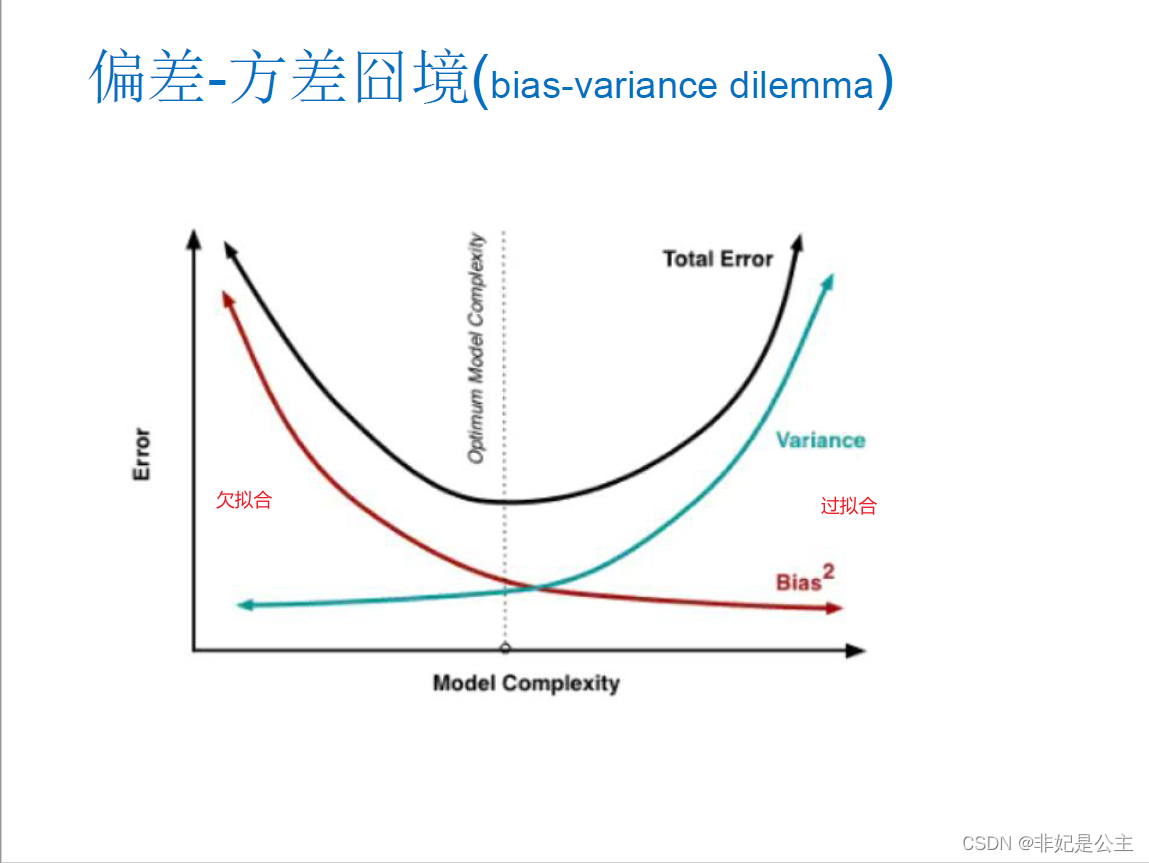
随着模型复杂度的提高,我们可以发现以下特点:
在模型复杂度较低的情况下,偏差是很大的;
而在模型复杂度较高的情况下,方差是很大的;
我们想通过集成学习来实现方差+偏差的最小,即途中虚线的位置。
个人理解:误差较大、方差较小,模型复杂度低,其实就是出现了过拟合;
误差较小、方差较大,模型复杂度高,其实就是出现了欠拟合。
我们要找的就是过拟合和欠拟合之间的某个平衡点。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/130531.html

