
文章目录
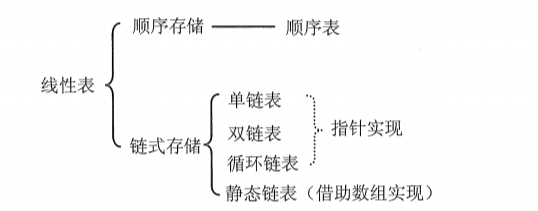
线性表
【知识框架】
一、线性表的定义
线性表(List):零个或多个数据元素的有限序列。
线性表的数据集合为{a1,a2,…,an},假设每个元素的类型均为DataType。其中,除第一个元素a1外,每一个元素有且只有一个直接前驱元素,除了最后一个元素an外,每一个元素有且只有一个直接后继元素。数据元素之间的关系是一对一的关系。

在较复杂的线性表中,一个数据元素可以由若干个数据项组成。在这种情况下,常把数据元素称为记录,含有大量记录的线性表又称为文件
线性表的顺序存储结构
一、顺序表
1、顺序表的基本概念
概念:用一组地址连续的存储单元依次存储线性表的数据元素,这种存储结构的线性表称为顺序表。
特点:逻辑上相邻的数据元素,物理次序也是相邻的。
只要确定好了存储线性表的起始位置,线性表中任一数据元素都可以随机存取,所以线性表的顺序存储结构是一种随机存取的储存结构,因为高级语言中的数组类型也是有随机存取的特性,所以通常我们都使用数组来描述数据结构中的顺序储存结构,用动态分配的一维数组表示线性表。
2、顺序表存储结构
//头文件
#include<stdio.h>
#include<stdlib.h>
#define MAXSIZE 20 //线性表存储空间的初始分配量
#define OK 1 //成功标识
#define ERROR 0 //失败标识
typedef int Status; //Status是函数的类型,其值是函数结果状态代码,如OK等
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
//顺序表数据结构
typedef struct
{
ElemType *elem;
int length;
}SqList;
3、构造一个空的顺序表L
Status InitList(SqList* L){
//构造一个空的线性表L
L -> elem = (ElemType *)malloc(MAXSIZE*sizeof(ElemType));
if(!L -> elem){
return ERROR;
}
L -> length = 0;
return OK;
}
4、顺序表的插入
/*
插入操作
初始条件:顺序表L已存在
操作结果:在L中的第i个位置之前插入新的数据元素e,L的长度加1
*/
Status ListInsert(SqList *L, int i, ElemType e){
int k;
if (L->length == MAXSIZE){ //线性表已满
return ERROR;
}
if (i < 1 || i > L->length+1){ //当i不在范围内时
return ERROR;
}
if (i <= L->length){ //若插入位置不在表尾
for(k = L->length-1;k >= i-1;k--){
L->elem[k+1] = L->elem[k];
}
}
L->elem[i-1] = e; //将新元素插入
L->length++; //长度加1
return OK;
}
5、顺序表的删除
/*
删除操作
初始条件:顺序表L已存在
操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1
*/
Status ListDelete(SqList *L, int i, ElemType *e){
int k;
if(L->length == 0){ //线性表为空
return ERROR;
}
if(i < 1 || i > L->length){ //删除位置不正确
return ERROR;
}
*e = L -> elem[i-1];
if(i < L->length){ //如果删除位置不在最后位置
for(k = i;k < L->length;k++){
L->elem[k-1] = L->elem[k];
}
}
L->length--; //长度减1
return OK;
}
6、获取顺序表某一位置上的元素
/*
获取元素操作
初始条件:顺序表L已存在
操作结果:用e返回L中第i个数据元素的值
*/
Status GetElem(SqList L, int i, ElemType *e){
if(L.length == 0 || i<1 || i>L.length){
return ERROR;
}
*e = L.elem[i-1];
return OK;
}
7、读取顺序表所有元素
/*打印线性表中的所有元素*/
void OutPut(SqList L){
printf("当前顺序表的长度:%d\n", L.length);
for(int i = 0; i < L.length; i++){
printf("%d ",L.elem[i]);
}
printf("\n");
}
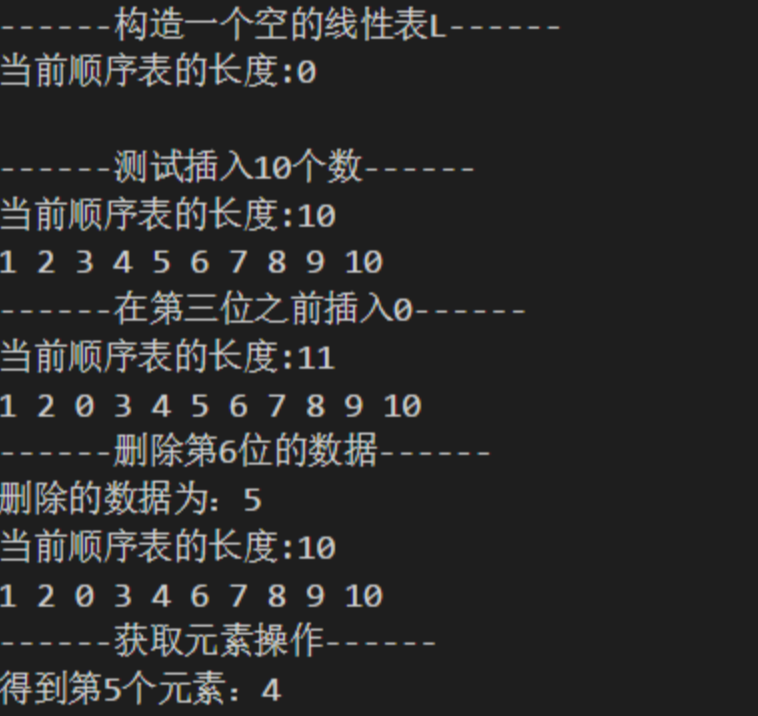
8、运行测试
int main()
{
SqList L;
printf("------构造一个空的线性表L------\n");
InitList(&L);
OutPut(L); //打印结果
printf("------测试插入10个数------\n");
for(int i = 1;i <= 10; i++){
ListInsert(&L,i,i);
}
OutPut(L); //打印结果
printf("------在第三位之前插入0------\n");
ListInsert(&L,3,0);
OutPut(L); //打印结果
printf("------删除第6位的数据------\n");
ElemType e;
ListDelete(&L,6,&e);
printf("删除的数据为:%d\n", e);
OutPut(L); //打印结果
printf("------获取元素操作------\n");
GetElem(L,5,&e);
printf("得到第5个元素:%d", e);
}
运行结果
小结
1、顺序表时间复杂度
从以上代码可以很明显的看出,线性表的顺序存储结果在读、存数据是的时间复杂度是O(1),插入、删除操作的时间复杂度是O(n)。
2、顺序表的优缺点
优点:无须为表中元素之间的逻辑关系而增加额外的存储空间;可以快速的存取表中任一位置的元素。
缺点:插入和删除操作需要移动大量元素;当线性表长度较大时,难以确定存储空间的容量;造成存储空间的“碎片”。
线性表的链式存储结构
一、单链表
1、单链表的基本概念
在链式结构中,除了要存储数据元素的信息外,还要存储它的后继元素的存储地址。因此,为了表示每个数据元素ai与其直接后继元素ai+1之间的逻辑关系,对数据ai来说,除了存储其本身的信息之外,还需要存储一个指示其直接后继的信息(即直接后继的存储位置)。我们吧把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
n个结点(ai的存储映像)链结成一个链表,即为线性表(a1, a2, …, an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。
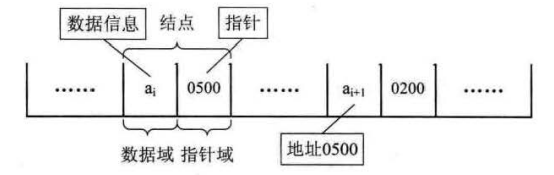
把链表中第一个结点的存储位置叫做头指针。
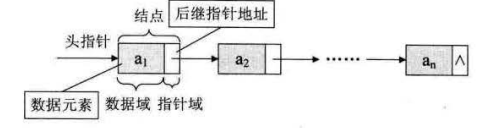
有时为了方便对链表进行操作,会在单链表的第一个结点前附设一个节点,称为头结点,此时头指针指向的结点就是头结点。

空链表,头结点的直接后继为空。
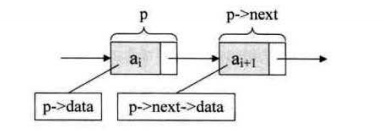
假设p是指向线性表第i个数据元素的指针,p->data表示第i个位置的数据域,p->next表示第i+1个位置的指针域,则第p+i个数据元素可表示为:
2、单链表的存储结构
#define OK 1 //正确标识
#define ERROR 0 //失败标识
typedef int Status; //Status是函数的类型,其值是函数结果状态代码,如OK等
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
/*线性表的单链表存储结构*/
//构造结点
typedef struct Node
{
ElemType data;
struct Node *next;
} Node;
//构造LinkList
typedef struct {
int lenght;
Node *next;
}*LinkList;
3、构造单链表
/*构造一个带头结点的单链表*/
Status InitList(LinkList *L){
//生成一个空的LinkList和一个新结点
LinkList p = (LinkList)malloc(sizeof(LinkList));
Node *q = (Node *)malloc(sizeof(Node)); //头结点
q->next = NULL; //头结点的后继指向null
p->next = q; //头指针指向头结点
p->lenght = 0; //初始长度为0
(*L) = p;
return OK;
}
4、单链表的插入
若将将节点s插入到节点p和几点p->next之间,如下图所示,其核心操作是:
s->next=p->next;
p->next=s;
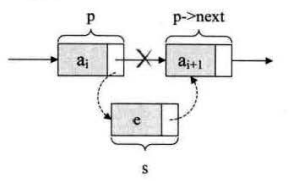
具体代码如下:
/**
* 单链表插入操作
* 初始条件:线性表L已存在
* 操作结果:在L中第pos个位置之前插入新的数据元素e,L的长度增加1
*/
Status ListInsert(LinkList *L, ElemType elem, int pos){
if(pos<1 || pos > (*L)->lenght+1){
return ERROR;
}
//寻找第pos个结点
Node *p = (*L)->next; //头结点
for(int i=1; i<pos; i++){
p = p->next;
}
//生成一个新结点
Node *q = (Node *) malloc(sizeof(Node));
q->data = elem;
q->next = p->next; //将p的后继赋值给q的后继
p->next = q; //将q赋值给p的后继
(*L)->lenght += 1; //链表长度加1
return OK;
}
5、单链表的删除
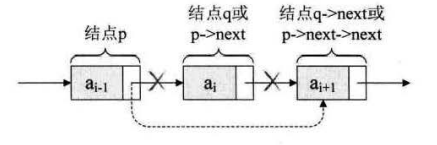
/**
* 单链表删除操作
* 初始条件:线性表L已存在
* 操作结果:删除L的第pos个数据元素,并用e返回其值,L的长度减1
*/
Status ListDelete(LinkList *L, ElemType *elem, int pos){
if(pos < 1 || pos>(*L)->lenght){
return ERROR;
}
//寻找到第pos个结点
Node *p = (*L)->next, *q;
for(int i=1; i<pos; i++){
p=p->next;
}
q = p->next; //要删除的结点
p->next = q->next;
free(q);
(*L) -> lenght -= 1;
return OK;
}
6、清空单链表
/**
* 清空单链表
*/
Status Clear(LinkList *L){
Node *p = (*L)->next->next, *q;
while(p != NULL){
q = p;
p = p->next;
free(q);
}
(*L)->next->next = NULL;
(*L)->lenght = 0;
return OK;
}
7、销毁单链表
/**
* 销毁单链表
*/
Status Destory(LinkList *L){
Node *p = (*L)->next, *q;
while(p != NULL){
q = p;
p = p->next;
free(q);
}
free((*L));
(*L) = NULL;
return OK;
}
8、遍历打印单链表
/*打印单链表表中的所有元素*/
void OutPut(LinkList L){
Node *p=L->next->next ;
for(int i=0;i<L->lenght;i++)
{
printf("%d ",p->data );
p=p->next ;
}
printf("\n");
}
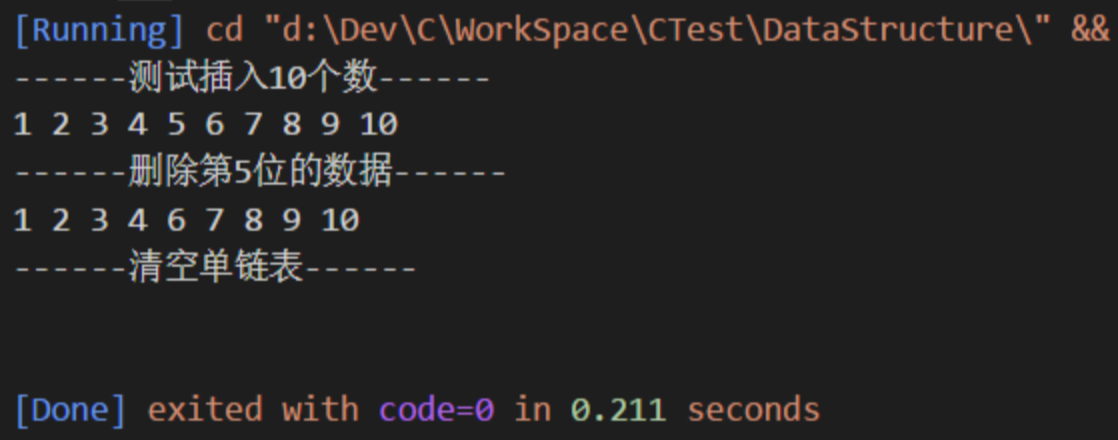
9、测试运行
int main()
{
LinkList L;
//构造单链表
InitList(&L);
printf("------测试插入10个数------\n");
for(int i = 1; i<=10;i++){
ListInsert(&L,i,i);
}
OutPut(L);
printf("------删除第5位的数据------\n");
ElemType elem;
ListDelete(&L, &elem, 5);
OutPut(L);
printf("------清空单链表------\n");
Clear(&L);
OutPut(L);
}
运行结果:
二、静态链表
1、静态链表的基本概念
静态链表,使用数组连描述指针,首先我们让数组的元素都是由两个数据域组成,data和cur。数据域data,用来存放数据元素;游标cur相当于单链表的next指针,存放该元素的后继在数组中的下标。
为了方便插入数据,我们通常会把数组建立得大一些,以便有一些空闲空间可以便于插入时不至于溢出。
#define MAXSIZE 1000 //假设链表的最大长度是1000
typedef struct{
ElemType data;
int cur; //游标(Cursor),为0时表示无指向
} Component,StaticLinkList[MAXSIZE];
另外我们对数组的第一个和最后一个元素作为特殊元素处理,不存数据。通产把未被使用的数组元素称为备用链表。而数组第一个元素,即下标为0的元素的cur存放备用链表的第一个结点的下标;而数组的最后一个元素的cur则存放第一个有数值的元素的下标,相当于单链表中的头结点的作用,当整个链表为空时,则为0。
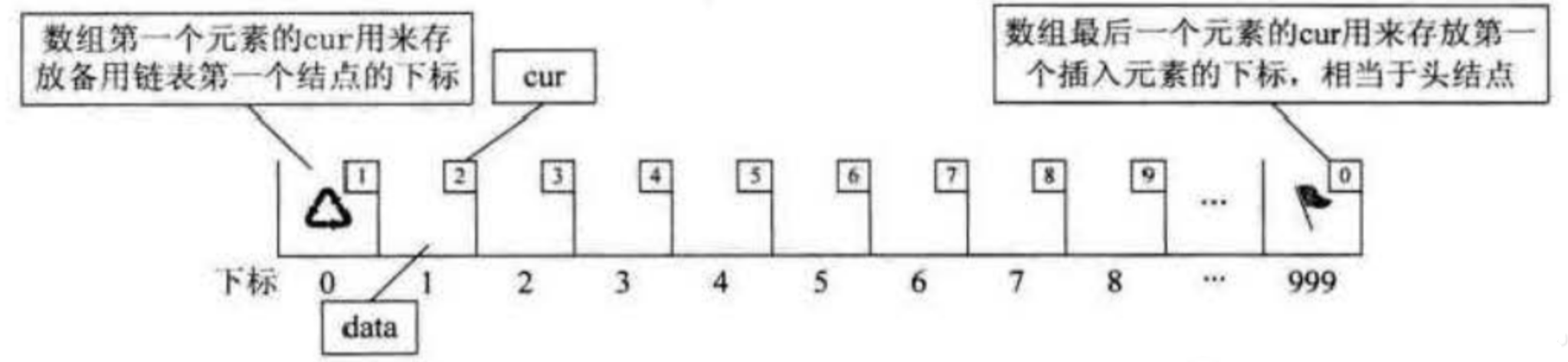
此时图示相当于初始化的数组状态,见下面代码:
/**
* 将一维数组space中各分量链成一备用链表
* space[0].cur为头指针。“0”表示空指针
*/
Status InitList(Component *space){
int i;
for(i=0; i<MAXSIZE; i++){
space[i].cur = i+1;
}
space[MAXSIZE-1].cur = 0; //目前静态链表为空,最后一个元素的cur为0
return OK;
}
在前面的动态链表中,节点的申请和释放分别借用malloc()和free()两个函数来实现。在静态链表中,我们需要自己实现这两个函数。
为了辨明数组中哪些分量未被使用,解决的办法是将所有未被使用过的及已被删除的分量用游标链成一个备用的链表,每当进行插入时,便可以从备用链表上取得第一个结点作为待插入的新节点。
/**
* 申请下一个分量的资源,返回下标
*/
int Malloc_SLL(StaticLinkList space){
int i = space[0].cur; //当前数组第一个元素的cur存的值,就是要返回的第一个备用空间的下标
if(space[0].cur){
space[0].cur = space[i].cur; //把下一个分量用来做备用
}
return i;
}
/**
* 将下标为k的空闲节点收回到备用链表
*/
void Free_SSL(Component *space, int k){
space[k].cur = space[0].cur; //把第一个元素cur值赋值给要删除的分量cur
space[0].cur = k; //把要删除的分量下标赋值给第一个元素的cur
}
2、静态链表的插入操作
例如如果我们需要在“乙”和“丁”之间,插入一个“丙”,操作如图所示:
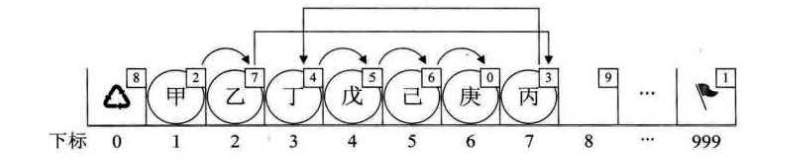
用代码实现如下:
/**
* 得到静态列表的长度
* 初始条件:静态列表L已存在。操作结果:返回L中数据元素的个数
*/
int ListLength(StaticLinkList L){
int j = 0;
int i = L[MAXSIZE-1].cur;
while(i){
i = L[i].cur;
j++;
}
return j;
}
/**
* 在L中第i个元素之前插入新的元素e
*/
Status ListInsert(Component *L, int i, ElemType e){
int j,k,l;
k = MAXSIZE - 1; //注意k首先是最后一个元素的下标
if(i<1 || i>ListLength(L) + 1){
return ERROR;
}
j = Malloc_SLL(L);
if(j){
L[j].data = e; //将数据赋值给此分量的data
for(l=1; l<= i-1; l++){
k = L[k].cur; //找到第i个元素之前的位置
}
L[j].cur = L[k].cur; //把第i个元素之前的cur赋值给新元素的cur
L[k].cur = j; //把新元素的下标赋值给第i个元素之前元素的cur
return OK;
}
return ERROR;
}
3、静态链表的删除操作
用代码实现如下:
/**
* 删除在L中第i个数据元素e
*/
Status ListDelete(Component *L, int i){
int j,k;
if(i<1 || i>ListLength(L)+1){
return ERROR;
}
k = MAXSIZE - 1;
for(j=1; j<=i-1; j++){
k = L[k].cur; //找到第i个元素之前的位置
}
j = L[k].cur;
L[k].cur = L[j].cur;
OUTPUT(L);
Free_SSL(&L, j);
return OK;
}
三、循环链表
1、循环链表的基本概念
将单链表中终端节点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。
循环链表带有头结点的空链表如下图所示:
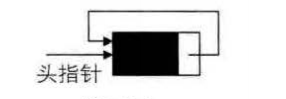
对于非空的循环链表则如下图所示:

2、仅设尾指针的循环链表
上述仅设头指针的循环链表有一个弊端,我们可以用O(1)的时间访问第一个节点,但对于最后一个节点,却需要O(n)的时间,于是就有了仅设尾指针的循环链表。
如下图所示:

从上图可以看到,终端节点用尾指针rear指示,则查找终端节点是O(1),而开始节点,其实就是rear->next->next,其时间复杂度也是O(1)。
举个程序的例子,要将两个循环链表合成一个表时,有了尾指针就非常简单了。比如下面的这两个循环链表,它们的尾指针分别是rearA和rearB。
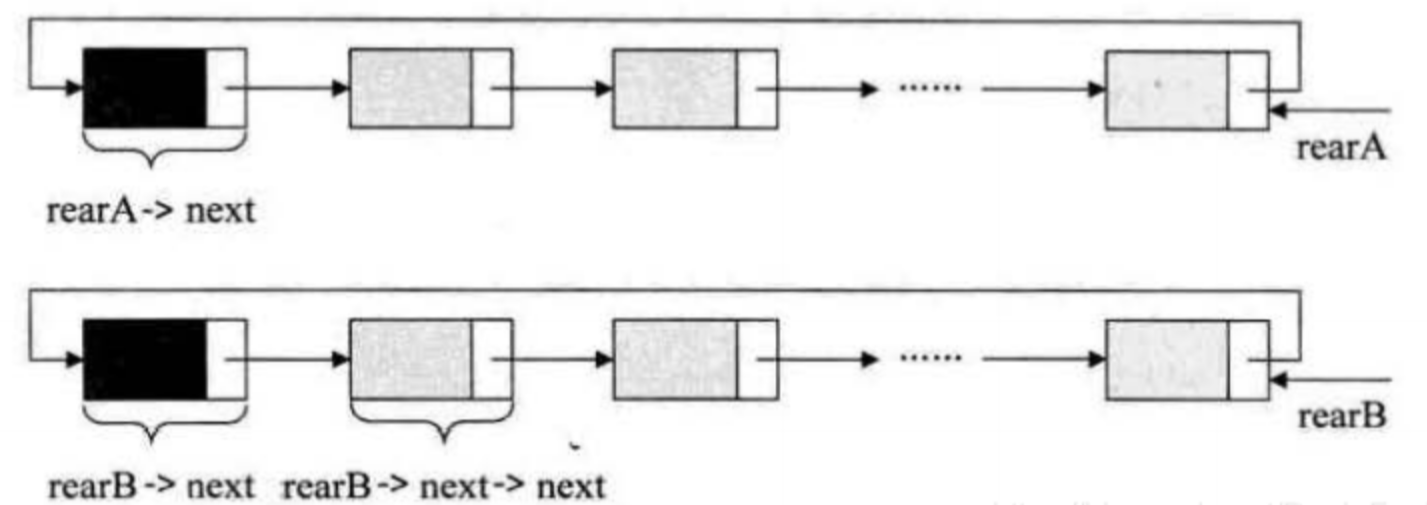
要想把它们合并,只需要如下操作即可:
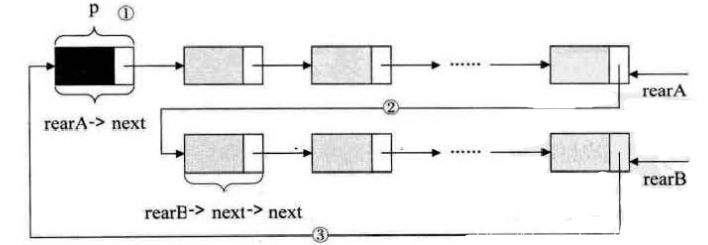
//第一步:保存A的头结点
p = rearA->next;
//第二步:将本是指向B表的第一个节点(不是头结点)赋值给rearA->next
rearA->next = rearB->next->next;
//第三步:将原A表的头结点赋值给rearB->next
rearB->next=p;
//释放p
free(p);
四、双向链表
1、双向链表的基本概念
双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
/*双向链表存储结构*/
typedef struct DulNodse{
ElemType data;
struct DulNode *prior; //直接前驱指针
struct DulNode *next; //直接后继指针
} DulNode, *DuLinkList;
双链表示意图如下所示:

双向链表中,对于链表中的某一个结点p,它的后继的前驱以及它的前驱的后继都是它自己,即:
p->next-prior = p = p->prior-next
2、双向链表的插入操作
在双链表中p所指的结点之后插入结点*s,其指针的变化过程如下图所示:
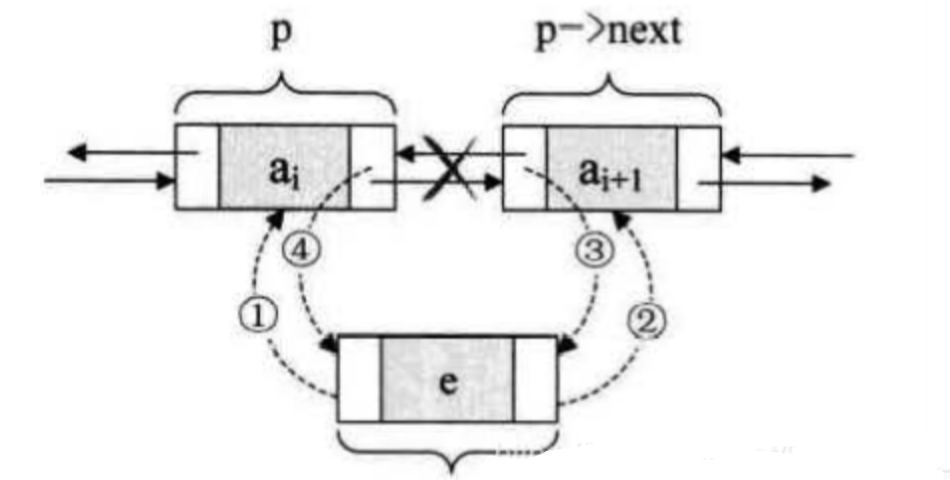
插入操作的代码片段如下:
//第一步:把p赋值给s的前驱
s->prior = p;
//第二步:把p->next赋值给s的后继
p->next = p->next
//第三步:把s赋值给p->next的前驱
p->next->prior = s;
//第四步:把s赋值给p的后继
p->next = s;
3、双向链表的删除操作
如果要删除q结点,只需下面两步:
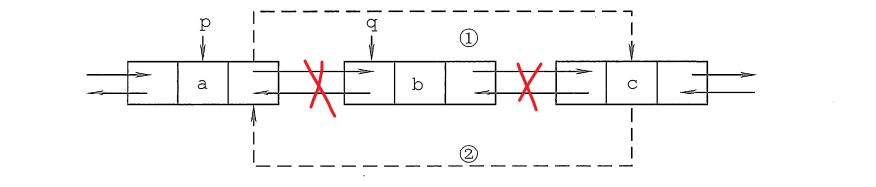
代码片段如下:
//第一步
p->next = q->next;
//第二步
q->next->prior = p;
free(q);
总结
一、顺序表和链表的比较
1、存取(读写)方式
顺序表可以顺序存取,也可以随机存取,链表只能从表头顺序存取元素。例如在第i个位置上执行存或取的操作,顺序表仅需一次访问,而链表则需从表头开始依次访问i次。
2、逻辑结构与物理结构
采用顺序存储时,逻辑上相邻的元素,对应的物理存储位置也相邻。而采用链式存储时,逻辑上相邻的元素,物理存储位置则不一定相邻,对应的逻辑关系是通过指针链接来表示的。
3、查找、插入和删除操作
对于按值查找,顺序表无序时,两者的时间复杂度均为O(n);顺序表有序时,可采用折半查找,此时的时间复杂度为O(log2n)。
对于按序号查找,顺序表支持随机访问,时间复杂度仅为O(1),而链表的平均时间复杂度为O(n)。顺序表的插入、删除操作,平均需要移动半个表长的元素。链表的插入、删除操作,只需修改相关结点的指针域即可。由于链表的每个结点都带有指针域,故而存储密度不够大。
4、空间分配
顺序存储在静态存储分配情形下,一旦存储空间装满就不能扩充,若再加入新元素,则会出现内存溢出,因此需要预先分配足够大的存储空间。预先分配过大,可能会导致顺序表后部大量闲置;预先分配过小,又会造成溢出。动态存储分配虽然存储空间可以扩充,但需要移动大量元素,导致操作效率降低,而且若内存中没有更大块的连续存储空间,则会导致分配失败。链式存储的结点空间只在需要时申请分配,只要内存有空间就可以分配,操作灵活、高效。
二、在实际中应该怎样选取存储结构呢?
1、基于存储的考虑
难以估计线性表的长度或存储规模时,不宜采用顺序表;链表不用事先估计存储规模,但链表的存储密度较低,显然链式存储结构的存储密度是小于1的。
2、基于运算的考虑
在顺序表中按序号访问a1的时间复杂度为O(1),而链表中按序号访问的时间复杂度为O(n)因此若经常做的运算是按序号访问数据元素,则显然顺序表优于链表。
在顺序表中进行插入、删除操作时,平均移动表中一半的元素,当数据元素的信息量较大且表较长时,这一点是不应忽视的;在链表中进行插入、删除操作时,虽然也要找插入位置,但操作主要是比较操作,从这个角度考虑显然后者优于前者。
3、基于环境的考虑
顺序表容易实现,任何高级语言中都有数组类型;链表的作是基于指针的,相对来讲,前者实现较为简单,这也是用户考虑的一个因素。
总之,两种存储结构各有长短,选择哪一种由实际问题的主要因素决定。通常较稳定的线性表选择顺序存储,而频繁进行插入、删除操作的线性表(即动态性较强)宜选择链式存储。
注意:只有熟练掌握顺序存储和链式存储,才能深刻理解它们各自的优缺点。
参考资料
1、严蔚敏、吴伟民:《数据结构(C语言版)》
2、程杰:《大话数据结构》
3、王道论坛:《数据结构考研复习指导》
4、托马斯·科尔曼等人:《算法导论》
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/132158.html

